TL;DR
深層強化学習による教師なし映像要約に関する論文1を読んで楽しそうだったので、実際に手元で試してみました。
最終的に「ハシビロコウ カエルに逃げられる(NHKクリエイティブ・ライブラリー)」などの動画から、以下のような結果が得られます。
元動画では、30秒ほど完全に固まったままだったハシビロコウもこの通り!

論文概要
Deep Reinforcement Learning for Unsupervised Video Summarization with Diversity-Representativeness Reward (AAAI 2018)
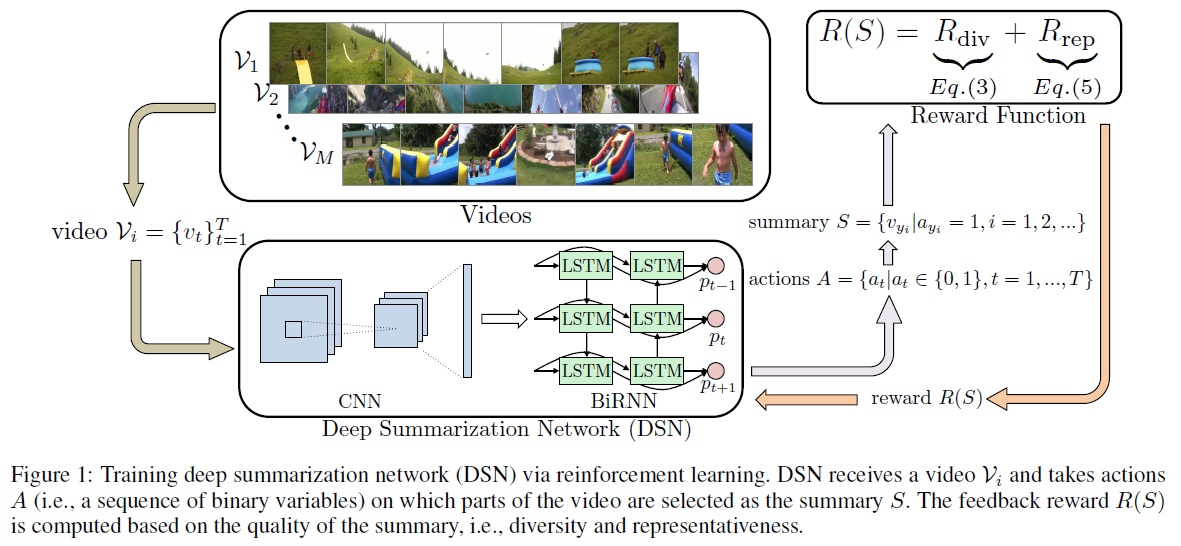
-
多様性と代表性を重視するような報酬設計をした強化学習を用いて、
- 多様性:他フレームとの類似度が低いほど報酬を大きく
- 代表性:画像特徴空間上に割り当てた各クラスタの中心に近いほど報酬を大きく
- 映像の各フレームを要約に含める確率を出力するニューラルネット (GoogLeNet + BiRNN) を学習し、
- 教師データ要らずで映像要約 (Video Summarization) を行う手法
です。
具体的なアルゴリズムなどにご興味をお持ちの方は、論文本体 (arXiv) をご覧ください。
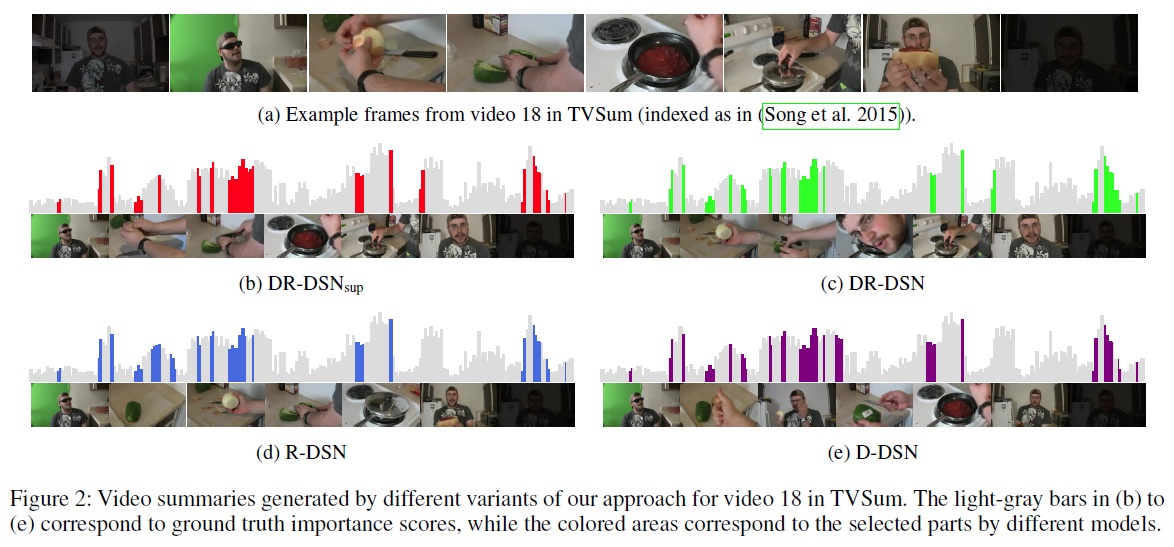
上の棒グラフにおいて、グレー部分の高さは要約する上で人間が重要だと考えた度合い、色付き部分は要約として自動的に切り出された箇所を表します。
4つの手法2で細かい差異は見られるものの、いずれも人間の感覚に近しい要約をできていることがわかります。
試してみる
実行環境
- OS: Ubuntu 16.04 LTS
- GPU: NVIDIA GeForce GTX 1080 Ti
- Python 仮想環境: Anaconda 4.5.2
- for TensorFlow: Python 3.6.2 / TensorFlow 1.9.0
- for Theano: Python 2.7.14 / Theano 0.9.0
使用する OSS プロジェクトの都合上、Python 2.x/3.x 両方の実行環境が必要となることに注意してください。
以降の説明では、下記のように表記を使い分けることとします。
$ python -> Python 2.x
$ python3 -> Python 3.x
1. 準備
Python やら git やら ffmpeg やらの実行環境は、構築済みの前提です。
まず、必要な OSS プロジェクトと学習済みモデルをローカルにダウンロードしておきます。
# vsumm-reinforce
$ git clone https://github.com/KaiyangZhou/vsumm-reinforce
$ cd vsumm-reinforce
$ wget http://www.eecs.qmul.ac.uk/~kz303/vsumm-reinforce/datasets.tar.gz
$ tar -xvzf datasets.tar.gz
$ wget http://www.eecs.qmul.ac.uk/~kz303/vsumm-reinforce/models.tar.gz
$ tar -xvzf models.tar.gz
$ cd ..
# GoogLeNet for Image Classification
$ git clone https://github.com/conan7882/GoogLeNet-Inception-tf
$ cd GoogLeNet-Inception-tf
$ wget https://www.dropbox.com/sh/axnbpd1oe92aoyd/AADJaXakFvqOH8sXkdu6guHta/googlenet.npy
$ cd ..
# Kernel Temporal Segmentation
$ wget http://pascal.inrialpes.fr/data2/potapov/med_summaries/kts_ver1.1.tar.gz
$ tar -zxvf kts_ver1.1.tar.gz
また、以下のようなフォルダ構成になっているものとして、要約したい動画ファイル(ここでは hashibiro.mp4)を data/original/ 以下に配置しておきます。
+- vsumm-reinforce/
+ +- datasets/
+ +- extra_tools/
+ + +- videos2frames.sh
+ +- vsum_test.py
+ +- summary2video.py
+- GoogLeNet-Inception-tf/
+ +- examples/
+ + +- inception_pretrained.py
+ +- googlenet.npy
+- kts_ver1.1/
+ +- demo.py
+- data/
+- original/
+ +- hashibiro.mp4
+- frames/
+- summarized/
2. フレーム画像への変換
次に、動画ファイルをフレーム画像に変換します。
vsumm-reinforce/extra-tools/video2frames.sh をエディタで開き、以下のように入力する動画ファイル (path_to_videos/*.avi)とフレーム画像の出力フォルダ (path_to_frames) のパスを指定します。
- for f in path_to_videos/*.avi
+ for f in ../../data/original/hashibiro.mp4
do
echo "Processing $f file..."
# take action on each file. $f store current file name\
basename=$(ff=${f%.ext} ; echo ${ff##*/})
name=$(echo $basename | cut -d'.' --complement -f2-)
echo $f
- mkdir -p path_to_frames/"$name"
- ffmpeg -i "$f" -f image2 path_to_frames/"$name"/%06d.jpg
+ mkdir -p ../../data/frames/"$name"
+ ffmpeg -i "$f" -f image2 -qscale:v 2 ../../data/frames/"$name"/%06d.jpg
done
このとき、ffmpeg コマンドで qscale:v オプションをつけると、出力するフレーム画像の品質を調整できます。
(参考:How can I extract a good quality JPEG image from an H264 video file with ffmpeg?)
修正したシェルスクリプトを実行すると、data/frames/ 以下にフレーム画像が格納されたサブフォルダが作成されます。
$ cd vsumm-reinforce/extra-tools
$ ./videos2frames.sh
3. 画像特徴量の抽出
要約箇所の推定には、ニューラルネット (GoogLeNet) で抽出した画像特徴量を用います。
GoogLeNet の学習済みモデル (googlenet.npy) は、 www.deeplearningmodel.net からダウンロード可能だったようですが、現在はリンク切れになっているみたいです。
そのかわり(?)に GoogLeNet の TensorFlow 実装の作者である Qian Ge さんが上記のコピーを公開してくださっているので、ありがたく使わせてもらいましょう。
GoogLeNet-Inception-tf/examples/inception_pretrained.py をコピーし、以下のように修正して feature_extraction.py という名前で保存します。
...
+ import h5py
+ import src.models.layers as L
...
- PRETRINED_PATH = '/home/qge2/workspace/data/pretrain/inception/googlenet.npy'
- DATA_PATH = '../data/'
+ PRETRINED_PATH = '../googlenet.npy'
+ DATA_PATH = '../../frames/hashibiro/'
+ DATASET_PATH = '../../vsumm-reinforce/datasets/eccv16_dataset_hashibiro_google_pool5.h5'
IM_CHANNEL = 3
...
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
+ dataset = h5py.File(DATASET_PATH, 'w')
+ video_name = FLAGS.data_path.split('/')[-2]
+ features = np.empty((1, 1024), dtype=np.float64) # Put dummy
while image_data.epochs_completed < 1:
# read batch files
batch_data = image_data.next_batch_dict()
# get batch file names
batch_file_name = image_data.get_batch_file_name()[0]
# get prediction results
- pred = sess.run(test_model.layers['top_5'],
+ feature = sess.run(L.global_avg_pool(test_model.layers['inception_out']),
feed_dict={test_model.image: batch_data['image']})
- # display results
- for re_prob, re_label, file_name in zip(pred[0], pred[1], batch_file_name):
- print('===============================')
- print('[image]: {}'.format(file_name))
- for i in range(5):
- print('{}: probability: {:.02f}, label: {}'
- .format(i+1, re_prob[i], label_dict[re_label[i]]))
+ features = np.concatenate((features, feature))
+ dataset.create_dataset('{}/features_origin'.format(video_name), data=features[1:])
+ dataset.close()
...
feature_extraction.py を実行すると、フレーム画像の特徴量が並んだ HDF5 ファイル (vsumm-reinforce/datasets/eccv16_dataset_hashibiro_google_pool5.h5) が得られます。
(参考:HDF5フォーマットに関するメモ書き)
$ cd GoogLeNet-Inception-tf/examples
$ python3 feature_extraction.py
4. シーンの推定
vsumm-reinforce/datasets/readme.txt を見ると、要約箇所を推定するには、あらかじめ動画をシーン (Temporal Segment) ごとに分割しておく必要があるようです。
ここでは、論文に倣って Kernel Temporal Segmentation (KTS) と呼ばれるテクニックによりシーンの切り替えポイントを推定します。
LEAR チームが公開している kts_ver1.1/demo.py をもとに、HDF5 ファイルにシーンの切り替えポイントを追加する segment.py を作成します。
import numpy as np
from cpd_auto import cpd_auto
import h5py
DATASET_PATH = "../vsumm-reinforce/datasets/eccv16_dataset_hashibiro_google_pool5.h5"
SAMP_RATE = 15 # sampling rate (fps)
N_CHANGE_POINTS = 30 # the number of change points
if __name__ == "__main__":
dataset = h5py.File(DATASET_PATH, "r+")
for video_name in dataset.keys():
X = dataset[video_name]["features_origin"][...]
n = X.shape[0]
K = np.dot(X, X.T)
cps, scores = cpd_auto(K, N_CHANGE_POINTS, 1)
print "Estimated: (m=%d)" % len(cps), cps
cps = np.concatenate(([0], cps))
cps = np.concatenate((cps, [n]))
# Update dataset
features = np.array([frame for i, frame in enumerate(X) if i % SAMP_RATE == 0], dtype=np.float64)
change_points = np.array([[cps[i], cps[i + 1] - 1] for i in range(cps.shape[0] - 1)], dtype=np.int64)
n_frames = np.array(n, dtype=np.int64)
n_frame_per_seg = np.array([(p[1] - p[0] + 1) for p in change_points], dtype=np.int64)
picks = np.array([(i * SAMP_RATE) for i in range((n - 1) // SAMP_RATE + 1)], dtype=np.int64)
key = dataset[video_name]
dataset.create_dataset(key + "/features", data=features)
dataset.create_dataset(key + "/change_points", data=change_points)
dataset.create_dataset(key + "/n_frames", data=n_frames)
dataset.create_dataset(key + "/n_frame_per_seg", data=n_frame_per_seg)
dataset.create_dataset(key + "/picks", data=picks)
dataset.close()
segment.py を実行すると、先ほど作成した HDF5 ファイルにシーンの切り替えポイント (change_points) の他、要約箇所の推定に必要な項目が追記されます。
$ cd kts_ver1.1
$ python segment.py
5. 要約箇所の推定
要約箇所の推定に必要な準備が整ったので、実際に推定を行ってみましょう。
vsumm-reinforce/vsum_test.py をコピーし、以下のように修正して vsum_gen.py という名前で保存します。
...
_DTYPE = theano.config.floatX
+ _PROPORTION = 0.10 # proportion to leave as a summary
...
- assert eval_dataset in ['summe', 'tvsum']
assert os.path.isfile(model_file)
...
logger.info('loading %s data' % (eval_dataset))
h5f_path = 'datasets/eccv16_dataset_' + eval_dataset + '_google_pool5.h5'
- dataset = h5py.File(h5f_path, 'r')
+ dataset = h5py.File(h5f_path, 'r+')
...
- # save output results to h5 file
- h5_res = h5py.File(osp.join(log_dir, 'result.h5'), 'w')
...
- machine_summary = vsum_tools.generate_summary(probs, cps, n_frames, nfps, positions)
+ machine_summary = vsum_tools.generate_summary(probs, cps, n_frames, nfps, positions, _PROPORTION)
- user_summary = dataset[key]['user_summary'][...]
- fm,prec,rec = vsum_tools.evaluate_summary(machine_summary, user_summary, eval_metric)
- fms.append(fm)
- precs.append(prec)
- recs.append(rec)
- if verbose: logger.info('video %s. fm=%f' % (key, fm))
# save results for each test video
- h5_res.create_dataset(key + '/score', data=probs)
- h5_res.create_dataset(key + '/machine_summary', data=machine_summary)
- h5_res.create_dataset(key + '/gtscore', data=dataset[key]['gtscore'][...])
- h5_res.create_dataset(key + '/fm', data=fm)
+ dataset.create_dataset(key + '/machine_summary', data=machine_summary)
-
- h5_res.close()
-
- mean_fm = np.mean(fms)
- mean_prec = np.mean(precs)
- mean_rec = np.mean(recs)
logger.info('========================= conclusion =========================')
logger.info('-- recap of model options')
logger.info(str(model_options))
- logger.info('-- final outcome')
- logger.info('f-measure {:.1%}. precision {:.1%}. recall {:.1%}.'.format(mean_fm, mean_prec, mean_rec))
elapsed_time = time.time() - start_time
logger.info('elapsed time %.2f s' % (elapsed_time))
logger.info('==============================================================')
dataset.close()
...
vsum_gen.py を実行すると、これまでの HDF5 ファイルに推定された要約箇所が追記されます。
(参考:Theano Configuration — Theano 0.9.0 documentation)
$ cd vsumm-reinforce
$ THEANO_FLAGS='floatX=float32,device=cuda0' python vsum_test.py -model models/model_tvsum_reinforceRNN.h5 -d hashibiro
6. 要約動画の生成
最後に、先ほど推定した要約箇所をもとに動画ファイルを生成します。
vsumm-reinforce/summary2video.py を用いると、冒頭に載せたような要約動画を簡単に生成することができます。
コマンドラインオプションの説明は、vsumm-reinforce/summary2video.py のソースコード内に記載されています。
$ cd vsumm-reinforce
$ python summary2video.py -p datasets/eccv16_dataset_hashibiro_google_pool5.h5 -d ../data/frames/hashibiro/ -i 0 --fps 30 --save-dir ../data/summarized/ --save-name hashibiro.mp4 --width 640 --height 360
感想
この記事を執筆するにあたり、いろいろな動画で映像要約を試してみましたが、面白い(直感的にわかりやすい)結果となる動画を選定するのに苦労(?)しました。
要約として切り出す基準があくまで画像特徴量ベースであるため、必ずしも人間の感性と一致するわけではありません。
例えば、フィギュアスケートにおける技の難度なんてものは一切考慮されないので、ジャンプを飛び終えたところだったり、結果発表待ちのシーンが切り出されたり3します。
また、想定するシーン数(kts_ver1.1/segment.py の N_CHANGE_POINTS)をはじめとする諸々のハイパーパラメータも結果に影響を与えるため、機械学習のおかげで楽になったんだかなってないんだかよくわからなくなりますね、、、
-
Kaiyang Zhou, Yu Qiao and Tao Xiang, "Deep Reinforcement Learning for Unsupervised Video Summarization with Diversity-Representativeness Reward," Association for the Advancement of Artificial Intelligence (AAAI) 2018. ↩
-
4つとも論文内で提案されている手法で、左上から「教師ありver」「教師なしver」「代表性のみを考慮したver」「多様性のみを考慮したver」です。 ↩
-
多様性の観点でいえば正しい推定になるので、あらかじめ入力する動画の範囲を演技中のみにトリムしておくなどの工夫が必要でしょう。 ↩