c言語もよく忘れる言語なので、忘れガチなところだけチートシートを作りました。
char *a[]の意味するところ
最も基本ですが、メモリのイメージがしっかりできていないとエラーが出まくったりします。
どこで使われているか?
Cの教科書なんかによくでてくる、微妙にわかったようなわからないようなmainの引数でもつかわれています。
#include <stdio.h>
int main(int argc,char *argv[]) {
printf("argc=%d \n",argc);
for (int i=0;i<argc;i++){
printf("argv[%d]=%s\n",i,argv[i]);
}
return 0;
}
実行結果
mainという名前でコンパイルした場合、ターミナルやコンソールからコマンドライン引数を適当に与えます。例えば
./main a b c
とすると、実行結果は
argc=4
argv[0]=./main
argv[1]=a
argv[2]=b
argv[3]=c
となります。

char *a[]={"abc","xy"} の分解
c言語で主なメモリ領域は以下の4つになります。
コード領域
データ領域
ヒープ領域
スタック領域
文字列リテラルはコンパイラによってデータ領域に割り当てられます。
たとえばデータ領域を1000番地からとして、文字列"abc"が1000番地、'xy'が1100番地に割り付けられていると仮定します。
aがmainのなかで使われるなら、スタック領域に割り当てられます。それをたとえば100番地とします。
①a まずaは変数名で、当然ですがこれが主役です
②a[] aの両脇に*と[]があります。[]のほうが優先度が高いので、変数aは配列です
③*a[] その配列の中身はポインタです
④char *a[] ポインタの指す先は文字型です
繰り返しますが配列aが100番地、文字列"abc"が1000番地、'xy'が1100番地に割り付けられているとしたら

シンプルなプログラムで実際のメモリイメージを確認してみましょう。
#include <stdio.h>
int main(void) {
const char *a[]={"abc","xy"} ;
printf("%p %p %p\n",a,a[0],&a[0]);
printf("%p %p %p\n",a,a[1],&a[1]);
return 0;
}
replitでの結果です。
https://replit.com/@bkh4149/memoriPei-Zhi-a
ただし実際のアドレスは実行ごとに毎回変わります
リアルなメモリイメージ


アクセス方法
配列はポインタ(配列の先頭アドレス)なので*や**を使ってもアクセスします
先程のコードを少し変化させると
#include <stdio.h>
int main(void) {
const char *a[]={"abc","xy"} ;
printf("%p %p %p\n",a,a[0],&a[0]);
printf("%p %p %p\n",a,a[1],&a[1]);
printf("%p\n",*a); //←ここ追加
printf("%x\n",**a); //←ここ追加
return 0;
}
こうなります。(アドレスは毎回変わります)
0x7ffd7e375710 0x402004 0x7ffd7e375710
0x7ffd7e375710 0x402008 0x7ffd7e375718
0x402004
61
aは配列なので、単にaとだけ書くと&a[0]のアドレスになっています。その中身が*aで値はここでは0x402004です。
そのポインタが指し示す先(**a)に0x61(アスキーコードの'a')が入っています。
2次元配列との違い
char *ar[]={"abc","def","gh"};
とかくと2次元配列のような気がしますが、これはポインタ配列と言って2次元配列とは異なります。
ちなみに2次元配列は
int ar[3][4];
のような形で、この場合はint型(4バイト)のデータが連続して並んだ形になっています。
先頭アドレスが0x1000番地なら以下の図のようになります。
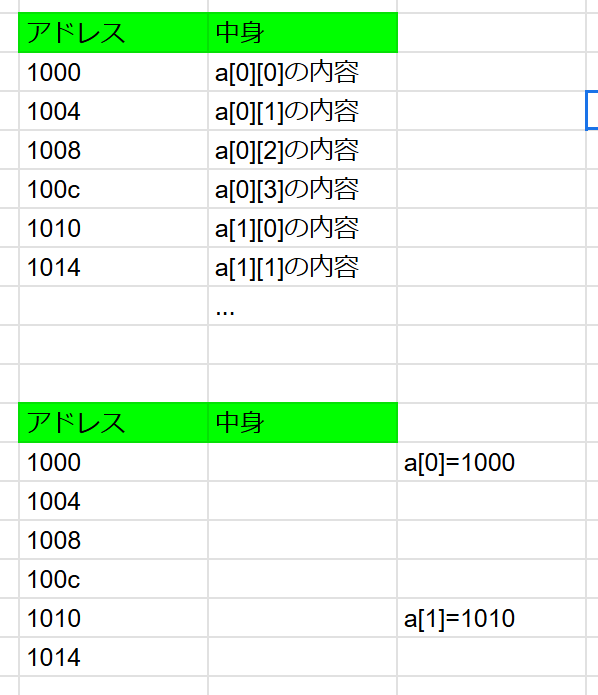
たとえばar[1][2]=100とすると、当たり前ですがar[1][2]のなかにint型のデータである100が入ります。ここで1次元めのar[0]やar[1]が何を指すかというと、行の先頭アドレスです。2次元目が4x4=16バイトなので、先頭アドレスが0x1000番地とすると
ar[1]=0x1010になります。
実際のコードで確認すると以下のようになっていました。

最後の下2桁がa0,b0のように16バイト離れて配置されているのがわかると思います。
const char* 型
以下のパターンも突然出てくるとドギマギしてしまいがちなのではないでしょうか?
#include <stdio.h>
const char* getMessage() {
return "Hello from WebAssembly!";
}
int main(void) {
const char *c;
c=getMessage();
printf("%s\n", c);
return 0;
}
以下の問題にすぐに答えられたら、スルーしてください
①なぜ char *c;ではなくて const char *c;なのか
②getMessage()は何をかえすのか
回答
①getMessage()関数の中で文字列リテラルを使っています。文字列リテラルはデータセグメントに格納され、実行時に変更することはできません。そのため、返されるポインタは const char* 型であり、これは変更不可能な文字列を指すことを意味します。
char *c ではなく const char *c を使用するのは、この不変性を尊重するためです。constを付けることで、このポインタを通じて文字列を変更することができないことを明示しています。
② getMessage() は const char* を返し、これは文字列リテラル "Hello from WebAssembly!" の先頭アドレスを指しています。const char* が変更不可能な文字へのポインタである理由は、関数が文字列リテラルを直接変更することを防ぐためです。
#include <stdio.h>
const char* getMessage() {
return "Hello from WebAssembly!";//文字列の先頭アドレスを返す
}
int main(void) {
const char *c;
c=getMessage(); // 先頭アドレスを cに代入
printf("%s\n", c); // 文字列を出力
return 0;
}
フォーマット指定方法
printf()関数やscanf()関数の中で使用されます。
以下にいくつかの基本的なフォーマット指定子を示します。
整数:
%d : 符号付き10進数整数
%i : %dと同じ
%u : 符号無し10進数整数
%o : 符号無し8進数整数
%x : 符号無し16進数整数 (小文字)
%X : 符号無し16進数整数 (大文字)
浮動小数点数:
%f : 小数点形式
%e : 指数形式 (小文字)
%E : 指数形式 (大文字)
%g : %fと%eの中から短い方
%G : %fと%Eの中から短い方
文字と文字列:
%c : 単一文字
%s : 文字列
ポインタ:
%p : ポインタ
これらのフォーマット指定子の前には幅、精度、フラグを指定することができます。たとえば、%08dは8桁の10進数を0でパディングします。
また、printf()関数では可変引数を使って複数の変数を出力することができます。以下に一例を示します。
int a = 5;
float b = 3.14f;
printf("整数: %d, 浮動小数点数: %.2f\n", a, b); // 整数: 5, 浮動小数点数: 3.14
以上がC言語の基本的なフォーマット指定方法になります。他にも細かいオプションがありますので、必要に応じてマニュアルやドキュメンテーションを参照してください。
フォーマット指定自体は文字列なのでこんな書き方もできます
#include <stdio.h>
int main(void) {
char a[]="%d\n"; //文字列配列
int b=3;
printf(a,b); //ここに注目!
return 0;
}
型について
型は値の範囲とメモリ使用量を決定します。
整数型:
| 型 | bit | 概要 | 符号 |
|---|---|---|---|
| char | 8 | キャラクタを格納 | 符号付きまたは符号なし |
| int | 32 | 整数 | 符号付き |
| short | 16 | intよりも小さい整数 | 符号付き |
| long | 32/64 | intよりも大きな整数 | 符号付き |
| long long | 64 | 非常に大きな整数 | 符号付き |
これらの型は、"unsigned"キーワードを前置することで、符号無し(つまり、非負)のバリエーションを作成できます。
浮動小数点型:
float: 単精度浮動小数点数を格納します。通常、32ビットで6-7桁の精度です。
double: 倍精度浮動小数点数を格納します。通常、64ビットで15-16桁の精度です。
long double: 拡張精度浮動小数点数を格納します。大抵のシステムでは80ビット以上です。
その他の型:
void: 値を持たず、戻り値または引数のない関数の型指定に使われます。
_Bool: 論理値(真または偽)を格納します。
ポインタ型:
メモリアドレスを格納します。
すべてのポインタ型は同じサイズですが、指しているデータの型は異なります。
また、C言語ではこれらの基本型を組み合わせて構造体(struct)、共用体(union)、列挙型(enum)などの複合データ型を定義することもできます。
C言語のプログラムエリア
主なメモリ領域は4つ
コード領域
データ領域
ヒープ領域
スタック領域
テキスト領域(またはコード領域):
実行コード(コンパイルされたマシンコード)が保存されます。 通常、読み取り専用として扱われ、プログラム実行中に書き換えられることはありません。
データ領域:
静的な生存期間を持つ変数が格納されます。この領域はさらに二つに分けられます。
- 初期化済みデータ領域: 初期値が設定されているグローバル変数や静的変数が格納されます
- BSS (Block Started by Symbol) 領域: 初期値が設定されていない、または0で初期化されるグローバル変数や静的変数が格納されます。プログラム開始時に、この領域の変数は通常0またはNULLポインタで初期化されます
ヒープ領域:
動的に確保されるメモリ(malloc、calloc、reallocなどで確保)。ヒープはメモリの低位アドレスから高位アドレスへ向かって確保します。
スタック領域:
関数の呼び出し時に使用されるローカル変数、関数への引数、戻り値のアドレスなどが格納されます。
* 関数が呼び出されるたびにスタックフレームが積まれ、関数が終了すると解放されます
* 一般的に、メモリの高位アドレスから低位アドレスに向かって確保されていきます(「成長する」と表現されます)
リファレンスとデリファレンス
& リファレンス アドレスを取る操作,中身からアドレスをたどっている
* デリファレンス 中身を取る操作、アドレスから中身をたどっている
サンプル
#include <stdio.h>
struct A { int x; int y; };
int main(){
int a=99;
int * b;
b=&a;
}
ここで理解を深めるために以下のようなことを考えてみます
&a : 変数aのアドレス
b : aのアドレスを持つポインタ
*b : bが指すアドレス(=a)の中身(値)
&(*b) : bをデリファレンス(その結果a)、それのアドレスなので、aのアドレス
*(&a) : aのアドレスからaを取得(=aの値)
*(&(*b)) : bをデリファレンスしa、そのaのアドレスをリファレンスするのでaの値
&(*(&a)) : aのアドレスをデリファレンスしてa、さらにそのアドレス
*(*(&b)) : bのアドレスをデリファレンスしてa、その値
この結果はどうなるでしょうか、具体的には以下のコードの結果を予想してみてください
#include <stdio.h>
struct A { int x; int y; };
int main(){
int a=99;
int * b;
b=&a;
printf("&a=%p a=%d\n",&a,a);
printf("*b=%d b=%p &b=%p\n",*b,b,&b);
printf("&(*b)=%p\n",&(*b));
printf("*(&a)=%d\n",*(&a));
printf("*(&(*b))=%d\n",*(&(*b)));
printf("&(*(&a))=%p\n",&(*(&a)));
printf("*(*(&b))=%d\n",*(*(&b)));
}
答え合わせ
&a=0x7ffff2f24d9c a=99
*b=99 b=0x7ffff2f24d9c &b=0x7ffff2f24da0
&(*b)=0x7ffff2f24d9c
*(&a)=99
*(&(*b))=99
&(*(&a))=0x7ffff2f24d9c
*(*(&b))=99
ダブルポインタでmallocを使うサンプル
死ぬほどややこし話
最初に以下のコードがサラッと読める人は即returnで帰ってくださいw
#include <stdio.h>
#include <stdlib.h>
void f(int **x)
{ *x = malloc(5);
(*x)[0] = 1234;
}
int main()
{
int *a = NULL;
f(&a);
printf("@main *a=%d a=%p &a=%p\n", *a, a, &a);
free(a);
return 0;
}
コードをみて void f(int **x)でなんで*が2つなの? とか
*x = malloc(5);の部分はふつう x = malloc(5);書くのでは? とか
(*x)[0] = 1234;ってなによ?
と思った人はcontinueで読んでみてください。
死ぬほどややこし話の解説
とりあえずmainの
int *a = NULL;
f(&a);
までは大丈夫かと思います
以下の丸数字は仮想のアドレスでステップバイステップで説明します
たとえばint *a = NULL;では
①aの居場所を1000番地とすると値はNULLなので1000番地に0が入る

という感じで、わかりやすくするため仮のアドレスをでっち上げて解説していきます(あとで本物のアドレスを出します)。一応、ヒープエリアが3000番地、main関数のスタックが1000番地、サブ関数fのスタックフレームが2000番地としてます
②f(&a); 関数fには1000が渡される
#include <stdio.h>
#include <stdlib.h>
void f(int **x)
{ // ③xの居場所を2000番地とすると、2000番地に1000が入る。x=1000,&x=2000である
*x = malloc(5);
// ④mallocで3000番地以降にエリア確保、5バイト
// ⑤その3000という値が*xにはいる、xの値は1000だが、*xはその中身なので1000番地に3000が入る
// ここ要注意、ポインタ宣言とmallocをあわせてよく int *x=malloc(5);と書くが、意味がぜんぜん違う!
// *x = malloc(5);での*xは宣言じゃない! xの中身を指すのだ!
(*x)[0] = 1234; //⑥(*x)が先頭アドレス、シンタクスシュガーをはずすと *((*x)+0)=1234
// ⑥まず((*x)+0)は(3000+0),*((*x)+0)は*(3000)、*(3000)=1234は3000番地の中に1234が入る
printf("@sub **x=%d *x=%p x=%p &x=%p\n", **x,*x, x, &x);
// **x=1234 *x=3000 x=1000 &x=2000
// →⑦関数終了、スタックフレーム(2000番地の1000)は消えるがヒープ(3000番地の値1234)と呼び出し元(1000番地の3000)の値は残る
}
int main()
{
int *a = NULL; // ①1000番地とする 値はNULL=0
f(&a); // ②関数には1000が渡される
// →⑦関数終了、2000番地の1000は消えるが3000番地の値と1000番地の3000という値は残る
printf("@main *a=%d a=%p &a=%p\n", *a, a, &a);
// ➇ *a=1234、a=3000、&a=1000
free(a);
// ⑩ 3000番代のエリアの開放
return 0;
}
③関数側で引数xの番地を2000番地としたので、そこに1000が入る

x=1000 , &x=2000である
④ malloc(5);
mallocでヒープエリアの3000番地に5バイト確保
ここまでのイメージを図解するとこうなります(丸数字が対応しています)

⑤*x = malloc(5);
3000という値が *xにはいる。xの値は1000だが、*xはその中身なので1000番地に3000が入る
! ここ要注意、ポインタ宣言とmallocをあわせてよく int *x=malloc(5);とかくのですがが、意味がぜんぜん違います!
int *x=malloc(5);//ポインタ宣言とmallocの合せ技
*x = malloc(5);//*xは宣言じゃない!*xはxの中身(デリファレンス)です。
重要なのでもう一度いいますが、*xはxのデリファレンス(中身)なので1000番地に3000が入る

⑥ (*x)[0] = 1234;
シンタクスシュガーをはずすと *((*x)+0)=1234
まず((*x)+0)は(3000+0)、それのデリファレンスは*(3000)、
*(3000)=1234は3000番地の中に1234が入る

ここでxについて一旦整理しておきます。
- &x:xの居場所 = 2000番地
- x :xの値 = 1000(メインから受け取った値)
- *x:xの指す番地の中身 = 3000
- **x:xの指す番地の中身が指す番地の中身 = 1234
printf(" **x=%d *x=%p x=%p &x=%p\n", **x,*x, x, &x);
この結果は **x=1234 *x=3000 x=1000 &x=2000

⑦関数終了、スタックフレーム(2000番地の1000)は消える。
ヒープ(3000番地の値1234)と呼び出し元(1000番地の3000)の値は残るので、main関数ではこれらをつかってヒープにアクセスできる。
ここまでのイメージを図解するとこうなります(丸数字が対応しています)

リアルな値で検証
WSL(ubuntu)での値は以下の通り
@sub **x=1234 *x=0x7ffff4b5d2a0 x=0x7ffffc361fb0 &x=0x7ffffc361f88
@main *a=1234 a=0x7ffff4b5d2a0 &a=0x7ffffc361fb0
wslだとヒープエリアとスタックエリアが近いのでわかりにくいのでreplitでやってみました。結果は以下のようになりました
@sub **x=1234 *x=0x55aa2ad792a0 x=0x7ffffd6b5398 &x=0x7ffffd6b53a0
@main a=1234 a=0x55aa2ad792a0 &a=0x7ffffd6b5398
これだとヒープが0x55....でスタックが0x7f....と離れているのでわかりやすいですね。
ひつこいですが、続けます。
まずxとaの値が同じになっています。仮想番地で3000としたやつ(=mallocで取得したヒープエリア)
xと&aも同じになっています。呼び出し元(=aのアドレス)仮想番地で1000としたやつです。
構造体配列は配列なのか構造体なのか
配列です。インスタンスがずらっとならんだ配列。要素1つ1つが構造体インスタンスです。
なんで構造体配列はアローじゃなくてドットを使うのか
たとえば
struct A {int x;int y};
struct A A1[3];
とすると、A1は構造体配列だが、A1[0]やA1[2]はそれぞれが1つのインスタンスで、実データを持っています。
A1はそれらインスタンスの配列。このようにインスタンスのときは.(ドット)でアクセス、たとえばA1[2].x(A1[2]->xではない)
ルール:インスタンスのメンバにアクセスするときはドット
ポインタのメンバにアクセスするときはアロー
配列名A1はC言語のコードの中では&A1[0]と同じ値(アドレス)になるが、本来の意味や型は異なります。A1はインスタンスの配列、&A1[0]はその先頭アドレス
ポインタとして宣言したときはアロー
たとえば struct A* A2;これだけだと構造体の中身が確保されていないので
A2=A1;とします。A2は、ポインタなのでアローでアクセス
A2->x;
サンプル
#include <stdio.h>
struct A { int x; int y; };
int main(){
struct A A1[3] = {0}; // 構造体インスタンスが3つ連続している
A1[2].x = 22; // インスタンスには.でアクセス
struct A* A2; // A2は構造体ポインタ型
A2 = A1; // 先頭アドレスを代入(A2 = &A1[0]と同じ意味)
A2->x = 99; // これはA1[0].x = 99 と同じ
for (int i=0; i<3; i++){
printf("%d ", A1[i].x); // 99 0 22
}
}
疑問:このサンプルでなんで最初に99がでるのか?
回答
最初に表示されるのはA1の先頭のインスタンス(A1[0])のxメンバ、すなわちA1[0].x。
A2 = A1;(A2はA1[0]のアドレス)としたので、A2->x は A1[0].x と同じになる。
だからA1[0].xにはいっている99が表示されます。
詳細(A1[0].xとA2->xが同じになる理由)
① A2->x
シンタックスシュガーを外す
② (*A2).x
A2 = A1なので
③ (*A1).x
A1は配列名。Cでは配列名は先頭アドレスに自動変換される。A1 = &A1[0]なので
④ (*(&A1[0])).x
*と&は相殺されるので(注)
⑤ A1[0].x
注)
&は「アドレスを取得」(Cでは「リファレンス」と呼ぶこともある)
*は「デリファレンス」(アドレスから実体を取得)
と&を連続して使うと相殺される((&A1[0])はA1[0]と同じ)
(void**)&bufferにびびった
たとえば以下のようなコードです。
(void**)&bufferってなに?
int my_allocate(size_t size, void **out) { ②
void *p = malloc(size); ③
if (!p) return -1; // 失敗
*out = p; // ④
return 0; // 成功
}
int main() {
char *buffer;①
if (my_allocate(100, (void**)&buffer) == 0) {
⑤
}
}
(void**)&bufferといっても**voidは型を変えるだけの話です。
その影にある引数&で渡しているほうが大きな意味をもちます。
いつものように実アドレスを強引に割り当てて話を進めていきます。
① たとえばbufferのアドレスが5000番地、64bitPUとすると
&buffer = 5000
5000: [ ???? ] // buffer(値は不定だが 8バイト確保 )
② int my_allocate(size_t size, void **out) {
これにより void型のダブルポインタ変数の場所が確保される
それを4000番地とすると、5000が引数として渡ってくるので
&out = 4000
4000: [ 5000 ] // out == &buffer
5000: [ ???? ] // buffer まだ不定
③ void *p = malloc(size);
ヒープが3000番地,pのアドレスが4008番地とすると
heap:
3000: [ ........ ] // 100 bytes
&p = 4008
4008: [ 3000 ] // p == 3000
&out = 4000
4000: [ 5000 ] // out == &buffer
5000: [ ???? ]
④ *out = p;
outの指すところ(=5000番地)にpの値3000が入るので
heap:
3000: [ ........ ]
4000: [ 5000 ] // out
4008: [ 3000 ] // p
5000: [ 3000 ] // buffer == 3000 に更新
⑤関数から戻ると
heap:
3000: [ ........ ] // freeされるまで残る
5000: [ 3000 ] // main の buffer が保持
以下おまけ(備忘録):関数と#include



strの7つ道具 string.h

関数とポインタ

ポインタと配列

コンパイルのオプション

fgetsとscanf

Makeの基本

スタックとキューの実現方法
超シンプル版ゼロから考えた原人的スタック
苦手意識高い系な人間が、書いたコードです
#include <stdio.h>
struct Stack{
int top;
int stk[30];//スタックは30個分
};
void showStk(struct Stack S){
int top=S.top;
printf("@showStk top=%d \n",top);
for (int i=top-1;i>=0;i--){
printf("i=%d stack=%d\n",i,S.stk[i]);
}
}
int main(void) {
int pop;
struct Stack S1;//push
S1.top=0;
showStk(S1);
S1.stk[S1.top]=11;//push
S1.top +=1;
showStk(S1);
S1.stk[S1.top]=22;//push
S1.top +=1;
showStk(S1);
S1.stk[S1.top]=33;//push
S1.top +=1;
showStk(S1);
S1.top -=1; //pop
pop = S1.stk[S1.top];
showStk(S1);
S1.stk[S1.top]=44;//push
S1.top +=1;
showStk(S1);
S1.top -=1; //pop
pop = S1.stk[S1.top];
showStk(S1);
printf("end\n");
return 0;
}
chatGPTによる修正版
上をchatGPTにコードレビューしてもらったところ、大量の修正点をあげていただきました。pushやpopを関数化して、スタックはポインタ渡しに変更してくれました。
#include <stdio.h>
#define MAX_SIZE 30 // Define stack size as a constant
struct Stack{
int top;
int stk[MAX_SIZE];
};
void push(struct Stack *S, int value){
if(S->top == MAX_SIZE){
printf("Stack overflow\n");
return;
}
S->stk[S->top] = value;
S->top += 1;
}
int pop(struct Stack *S){
if(S->top == 0){
printf("Stack underflow\n");
return -1; // return -1 or another specific value to indicate underflow
}
S->top -= 1;
return S->stk[S->top];
}
void showStk(struct Stack S){
int top = S.top;
printf("@showStk top=%d\n", top);
for (int i = top-1; i >= 0; i--){
printf("i=%d stack=%d\n", i, S.stk[i]);
}
}
int main(void) {
int popValue;
struct Stack S1;
S1.top = 0;
push(&S1, 11);
showStk(S1);
push(&S1, 22);
showStk(S1);
push(&S1, 33);
showStk(S1);
popValue = pop(&S1);
showStk(S1);
push(&S1, 44);
showStk(S1);
popValue = pop(&S1);
showStk(S1);
printf("end\n");
return 0;
}
さすがきれい、まあでもスタックの仕組みは捉えたきがします。
キューの実現 リングバッファ使用 chatGPT版
#include <stdio.h>
#define MAX_SIZE 5 // Define queue size as a constant
struct CircularQueue {
int items[MAX_SIZE];
int front, rear;
};
// Initializing the queue
void initializeQueue(struct CircularQueue *q) {
q->front = q->rear = -1;
}
// Check if the queue is full
int isFull(struct CircularQueue *q) {
if ((q->rear + 1) % MAX_SIZE == q->front) {
return 1;
}
return 0;
}
// Check if the queue is empty
int isEmpty(struct CircularQueue *q) {
if (q->front == -1) {
return 1;
}
return 0;
}
// Adding elements to the queue
void enqueue(struct CircularQueue *q, int element) {
if (isFull(q)) {
printf("Queue is full!\n");
return;
}
if (isEmpty(q)) {
q->front = q->rear = 0;
} else {
q->rear = (q->rear + 1) % MAX_SIZE;
}
q->items[q->rear] = element;
}
// Removing elements from the queue
int dequeue(struct CircularQueue *q) {
int data;
if (isEmpty(q)) {
printf("Queue is empty!\n");
return -1;
}
data = q->items[q->front];
if (q->front == q->rear) {
q->front = q->rear = -1;
} else {
q->front = (q->front + 1) % MAX_SIZE;
}
return data;
}
// Function to display the elements of queue
void display(struct CircularQueue *q) {
int i = q->front;
while (i != q->rear) {
printf("%d ", q->items[i]);
i = (i + 1) % MAX_SIZE;
}
printf("%d\n", q->items[i]);
}
int main() {
struct CircularQueue q;
initializeQueue(&q);
enqueue(&q, 1);
enqueue(&q, 2);
enqueue(&q, 3);
enqueue(&q, 4);
display(&q);
dequeue(&q);
display(&q);
enqueue(&q, 5);
display(&q);
dequeue(&q);
display(&q);
dequeue(&q);
display(&q);
dequeue(&q);
display(&q);
enqueue(&q, 6);
display(&q);
enqueue(&q, 7);
display(&q);
enqueue(&q, 8);
display(&q);
enqueue(&q, 9);
display(&q);
enqueue(&q, 10);
display(&q);
return 0;
}
実行結果は以下の通り、これもきれいなコードですなー
1 2 3 4
2 3 4
2 3 4 5
3 4 5
4 5
5
5 6
5 6 7
5 6 7 8
5 6 7 8 9
Queue is full!
5 6 7 8 9