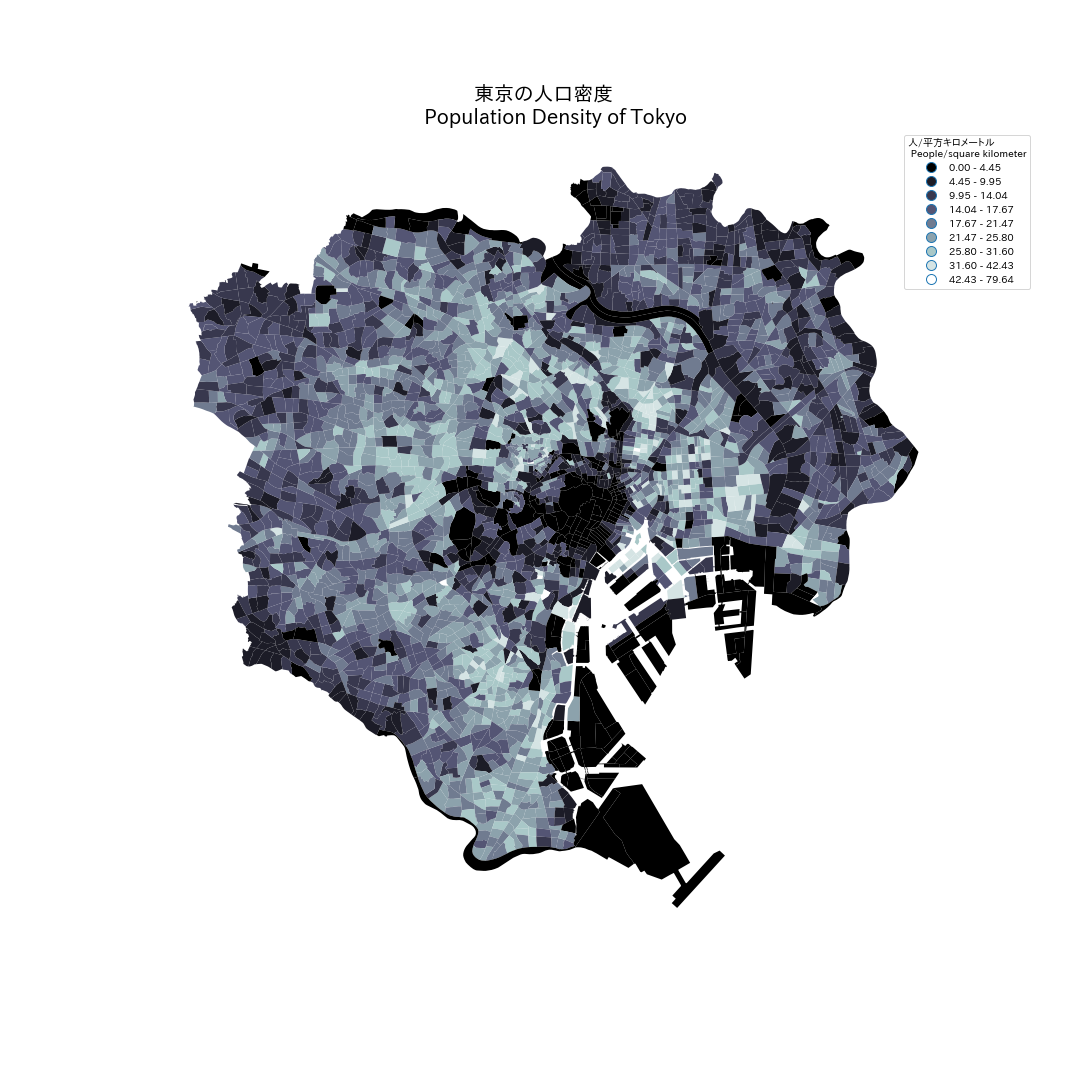
最近pythonで地図を使って見てる。僕はプロなんか全くないけど今まで作り方法を書きます。このポストの結果は東京の人口密度の地図です。
データを取ります
東京の堺と人口データをe-statから取れます。e-statは日本政府のデータポータルです。この**リンク**からシェープファイル形式でデータをダウンロードできる。僕にとってシェープファイルを使うことが嫌いからgeojsonに変換する。変換は必要じゃないけどmapshaperというツールで便利にできる。シェープファイルに比べたらgeojsonの利点は:
- 一つのファイルだけです。
- 「properties」の名前は文字の数が限らない。
- 自分でファイルを見ったら情報が分かってくる。
- geojsonはjavascriptの種類だからweb可視化をすればこれはいいフォーマット。
シェープファイルからgeojsonに変換する・(必要じゃない。シェープファイルが嫌い人のため)
シェープファイルからgeojsonに変換する時に僕は「mapshaper」という便利なwebツールを使う。mapshaperにいって、ダウンロードされた東京データの全部のファイルをアップロードする。そして「Import」ボタンをクリックして。
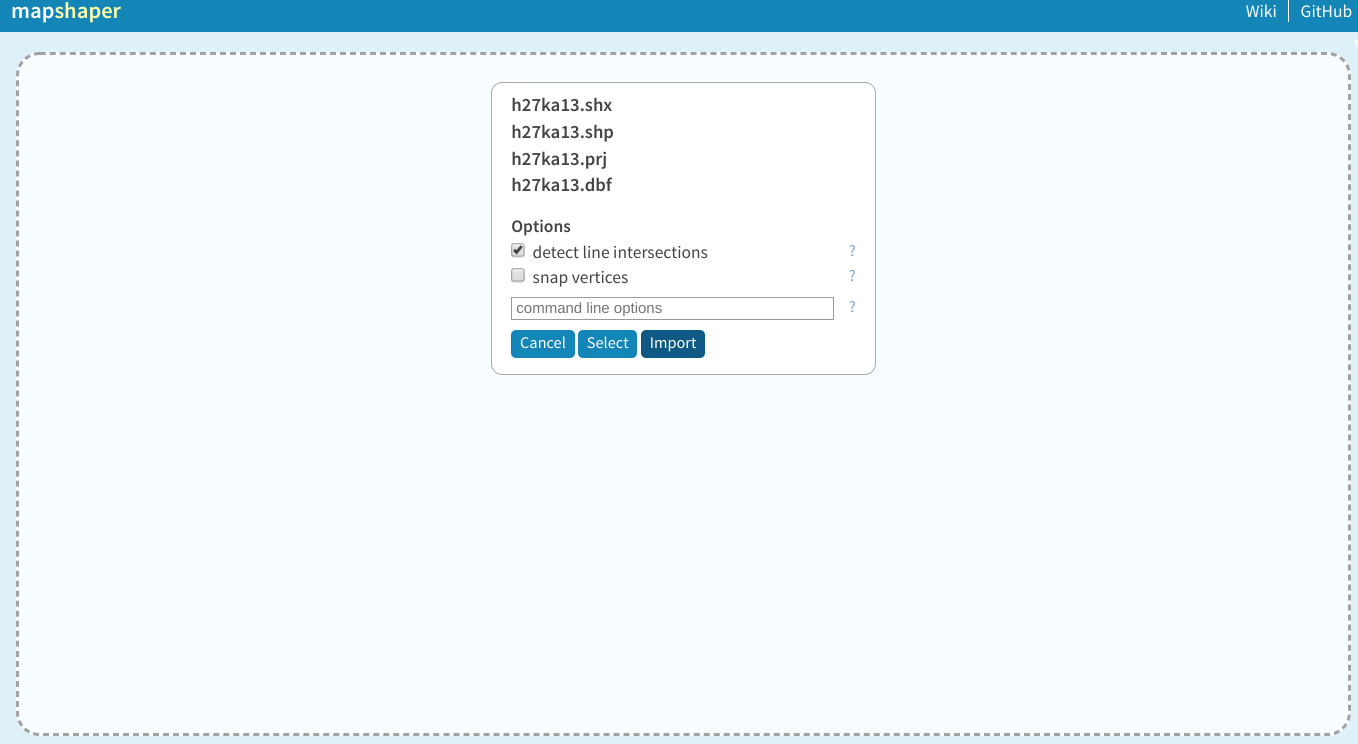
「Import」をクリックしてからこの下イメージを見ているはず。
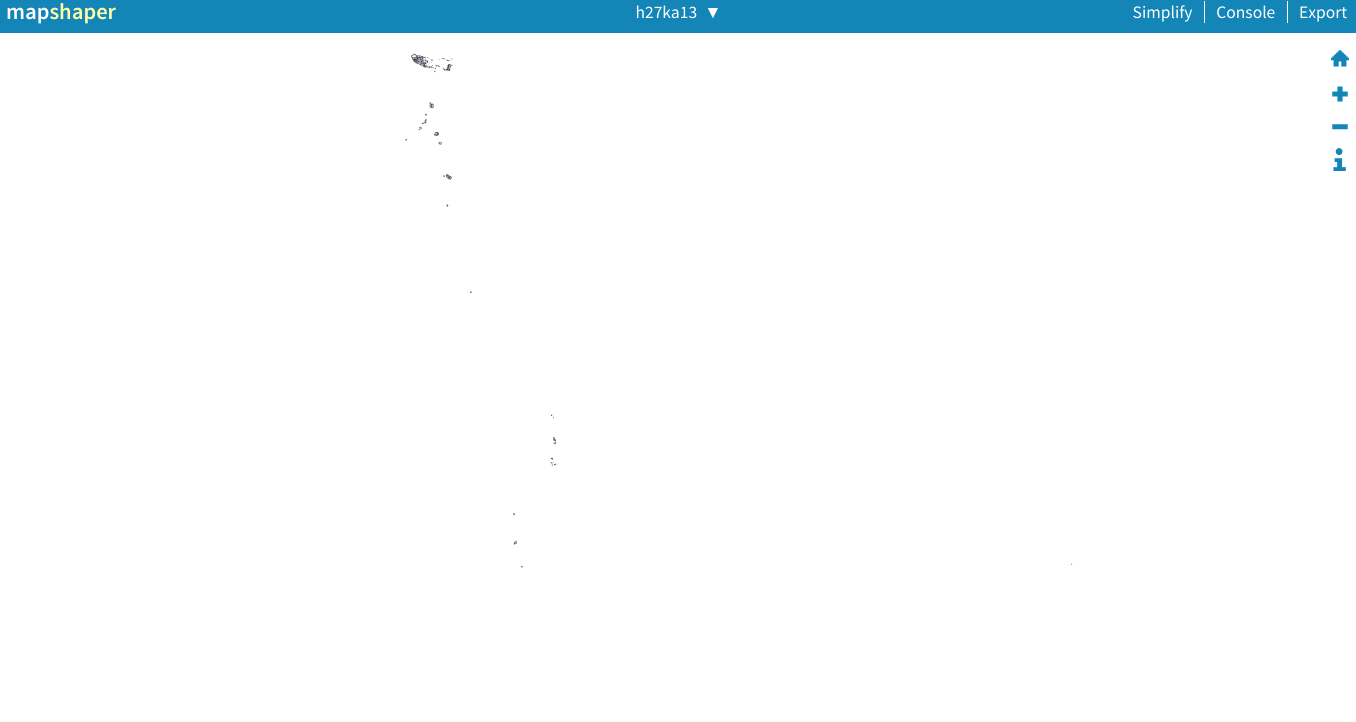
ええ?それは東京か?なんでそんなちっちゃいのか?と思っているかもしれない。これはたしかに東京。あまりわからないけど東京の中にこの小さくて、遠い島がある。pythonでこの島を削除をするから気にしないで。一番上の形状を拡大したら東京の形が現れる。
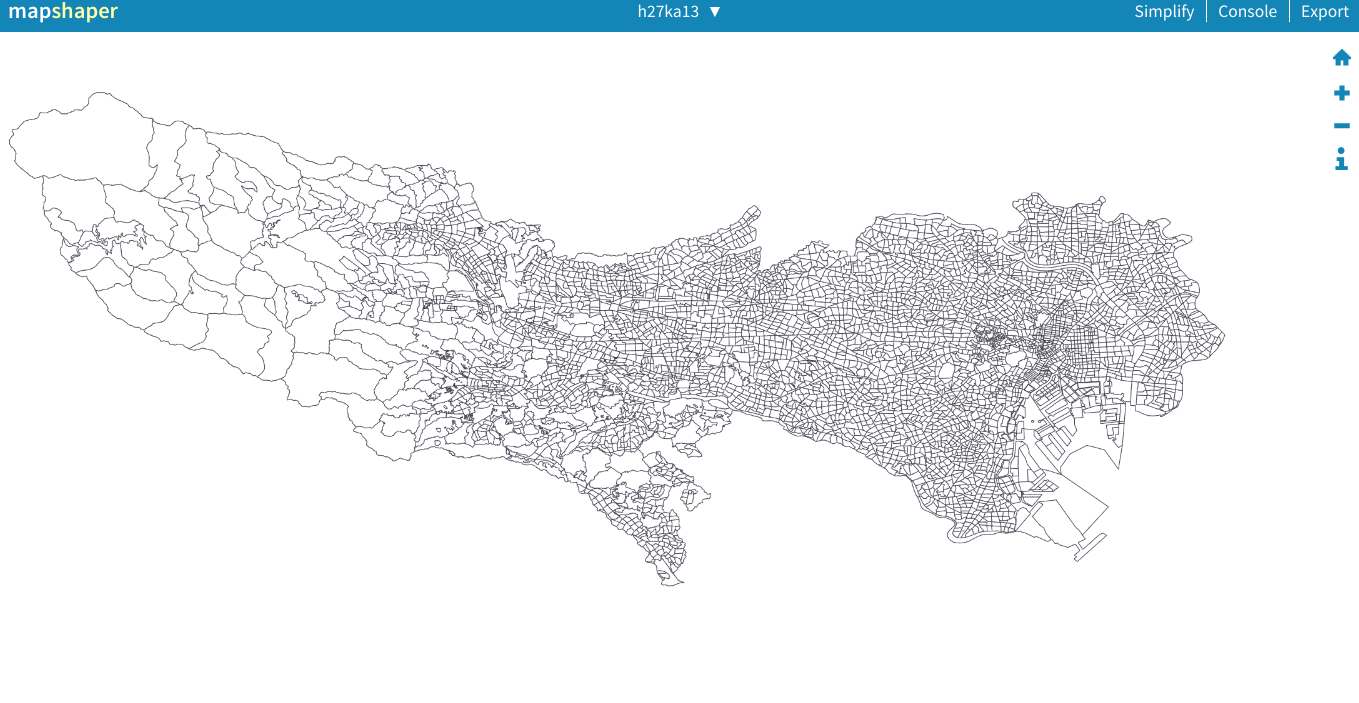
次はエクスポートです。右上である「Export」のボタンをクリックして、geojsonのオプションを選んで、そしてもう一度「Export」をクリックする。geojson形式で東京データがダウンロードされる。
pythonのgeopandasでデータを整理する
やっとpythonを使い始める。このポストのために「jupyter lab」か「jupyter notebook」を使うことをお勧めする。こんなデータ整理と可視化をする時「jupyter lab」と「jupyter notebook」はとても便利。僕はjupyter labを使う。
はじめに必要なパケージをimportする。この前にこのパケージをpipかcondaでインストールをしなければいけない。
%matplotlib inline #これはjupyterを使うことだけ必要
import geopandas as gpd
import matplotlib.pyplot as plt
import matplotlib
次はgeopandasでgeodataframeにgeojson形式データを読み込み:
tokyo = gpd.read_file("あなたのファイル")
# 例
tokyo = gpd.read_file("data/tokyo.geojson")
データはgeopandasのgeodataframeに格納されました。geodataframeを使用しているので.plotを使って便利にデータを見れる。
tokyo.plot()
出力は下:
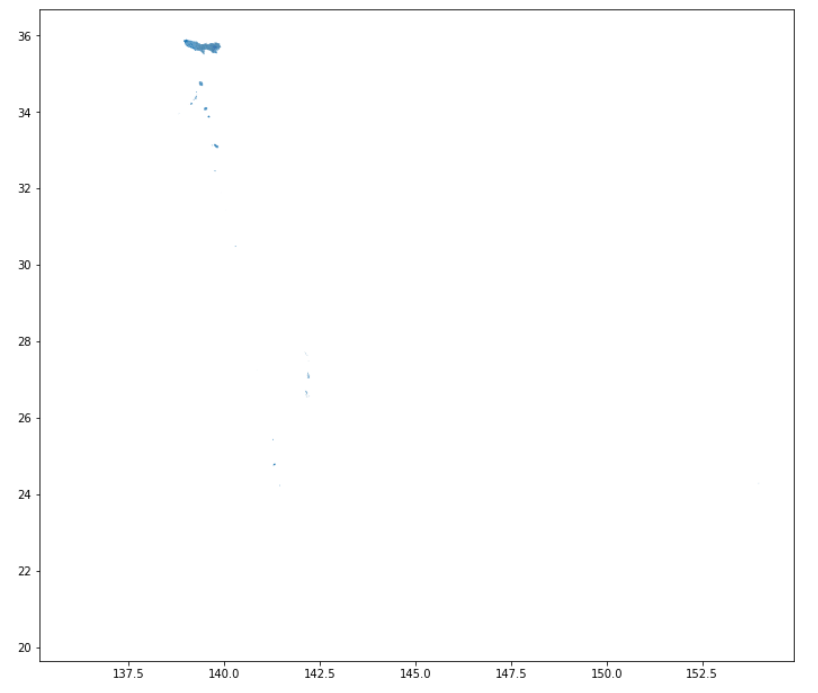
mapshaper同じように、東京自体は小さくて、島がいっぱいある。ちょっと整理しましょう。
島を削除するように「SITYO_NAME」がない列だけを保持して:
filter = tokyo["SITYO_NAME"] == ""
tokyo_l = tokyo[filter]
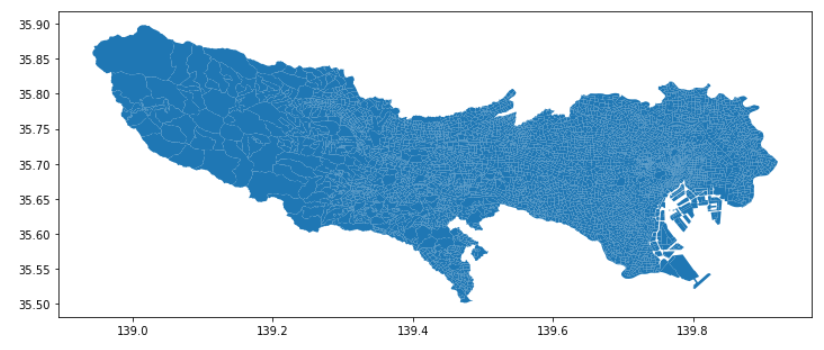
そして、水だけ含まれているポリゴンを削除する。
# このデータではHCODEが8154の場合、水だけ含まれている。
tokyo_nw = tokyo_l[tokyo_l.HCODE != 8154]
tokyo_nw.plot()
地図投影法を変換する
この地図にとって地方面積の関係があるデータが表示されるから面積が正しく示されるのは大切です。だからランベルト正積方位図法の投影法に変換を使う。僕はこんな規模のためにランベルト正積方位図法をよく使う。東京の中心に置くランベルト正積方位図法に変換しましょう。
# tokyo_crsのなかで投影法の情報が書いてある。
tokyo_crs = {'proj': 'laea', 'lat_0': '35.6895', 'lon_0': '139.6917', 'elipse': 'WGS84', 'datum': 'WGS84', 'units': 'm', 'no_defs': True}
tokyo_prj = tokyo_nw.to_crs(tokyo_crs)
tokyo_prj.plot()
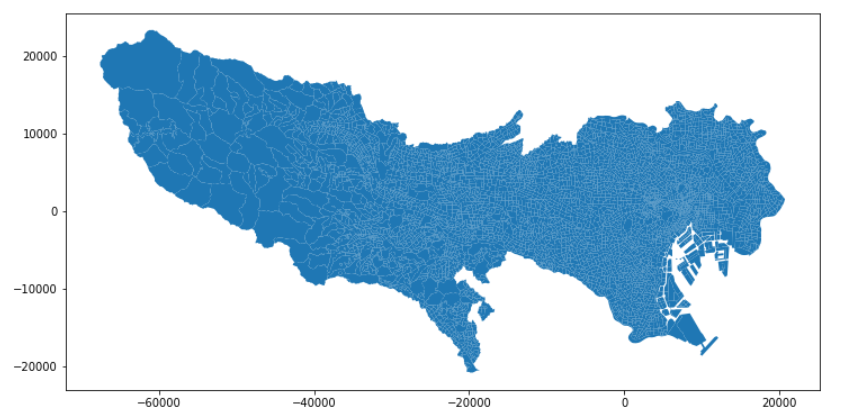
形の違いを気が付ける?
もうちょっとデータを掃除する
東京のgeodataframeをちょっと見てみましょう。
tokyo_prj.head()
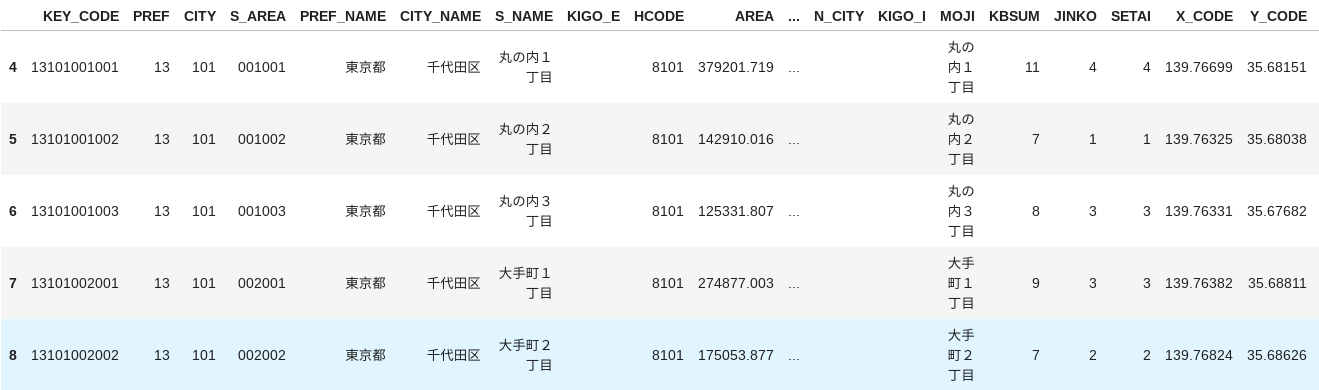
propertiesのカラムがいっぱいある。ちょっと狭めましょう。
# このカラム(geojsonのproperties)だけ保持する。
tokyo_f = tokyo_proj[['KEY_CODE', 'CITY_NAME', 'S_NAME', 'GST_NAME', 'AREA', 'JINKO', 'SETAI', 'geometry']]
JINKOとAREAを使って、POP_DENSITY(Population Density=人口密度)のカラムを作る。そしてメーテルからキロメーテルを変換する。
# POP_DENSITYを作る。
tokyo_pd = tokyo_f.assign(POP_DENSITY=tokyo_f.JINKO/tokyo_f.AREA)
# メートルからキロメートル。
tokyo_pd['POP_DENSITY'] = (tokyo_pd['POP_DENSITY'] * 1000)
tokyo_pd.head()

最後にmatplotlibで地図を作りましょう!
matplotlib.rc('font', family='TakaoPGothic')
f, ax = plt.subplots(figsize=(15, 15), subplot_kw={'aspect': 'equal'})
tokyo_pd.plot(column='POP_DENSITY', scheme='Fisher_Jenks', k=9, cmap="bone", ax=ax, legend=True)
leg = ax.get_legend()
leg.set_bbox_to_anchor([0.2, 0.4])
ax.set_axis_off()
ax.set_title('Population Density of Tokyo', fontsize=20)
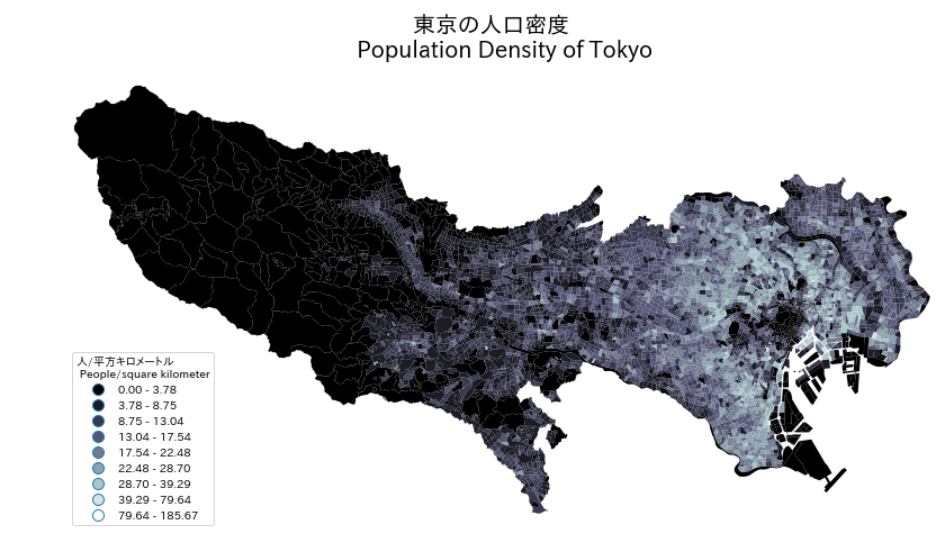
よしゃ!東京の人口密度地図を作りました!僕のmatplotlibの能力が低いからもっといいキャプションをできる読者さんがいたら僕を教えてください!または、何かがわからなかったら聞いてくれね。
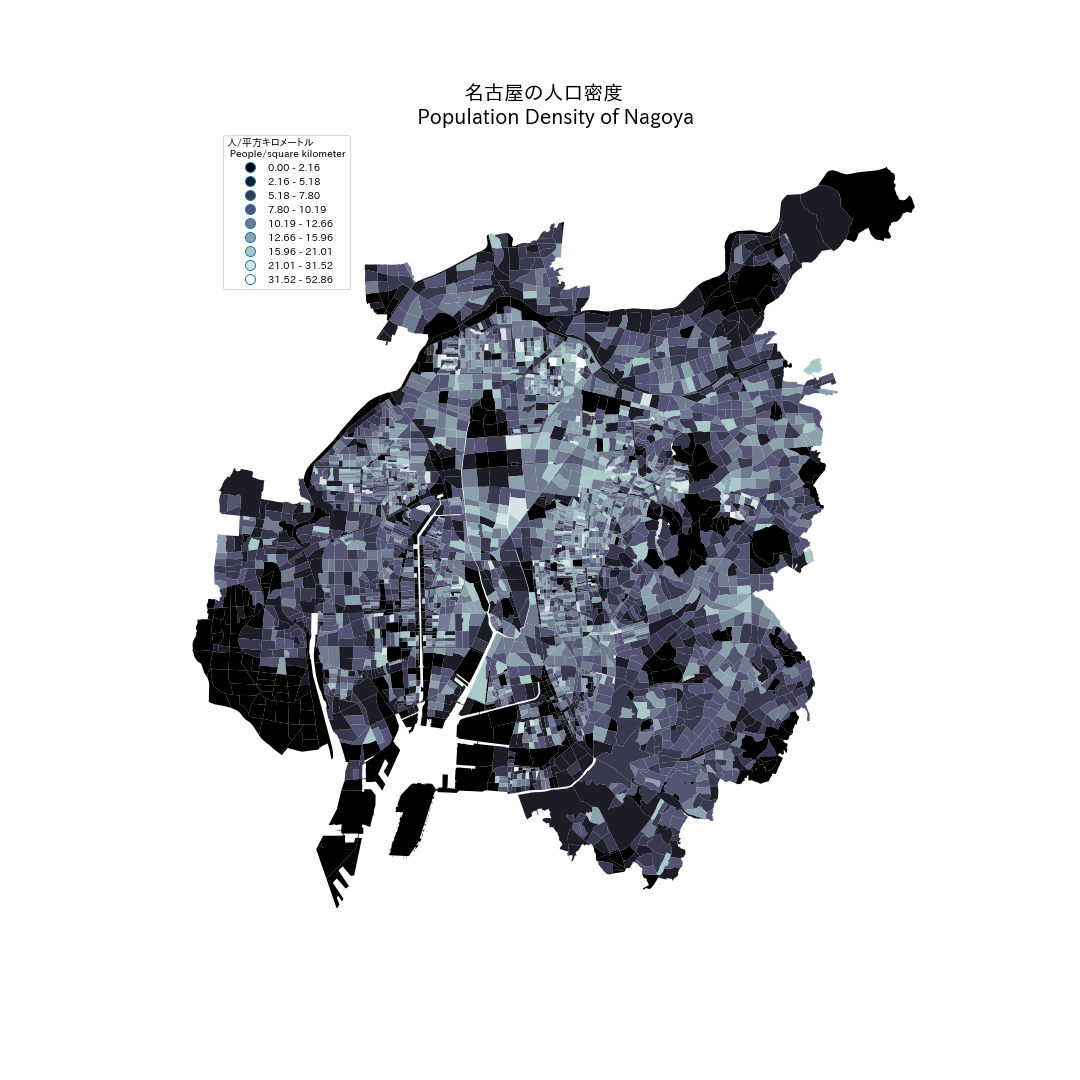
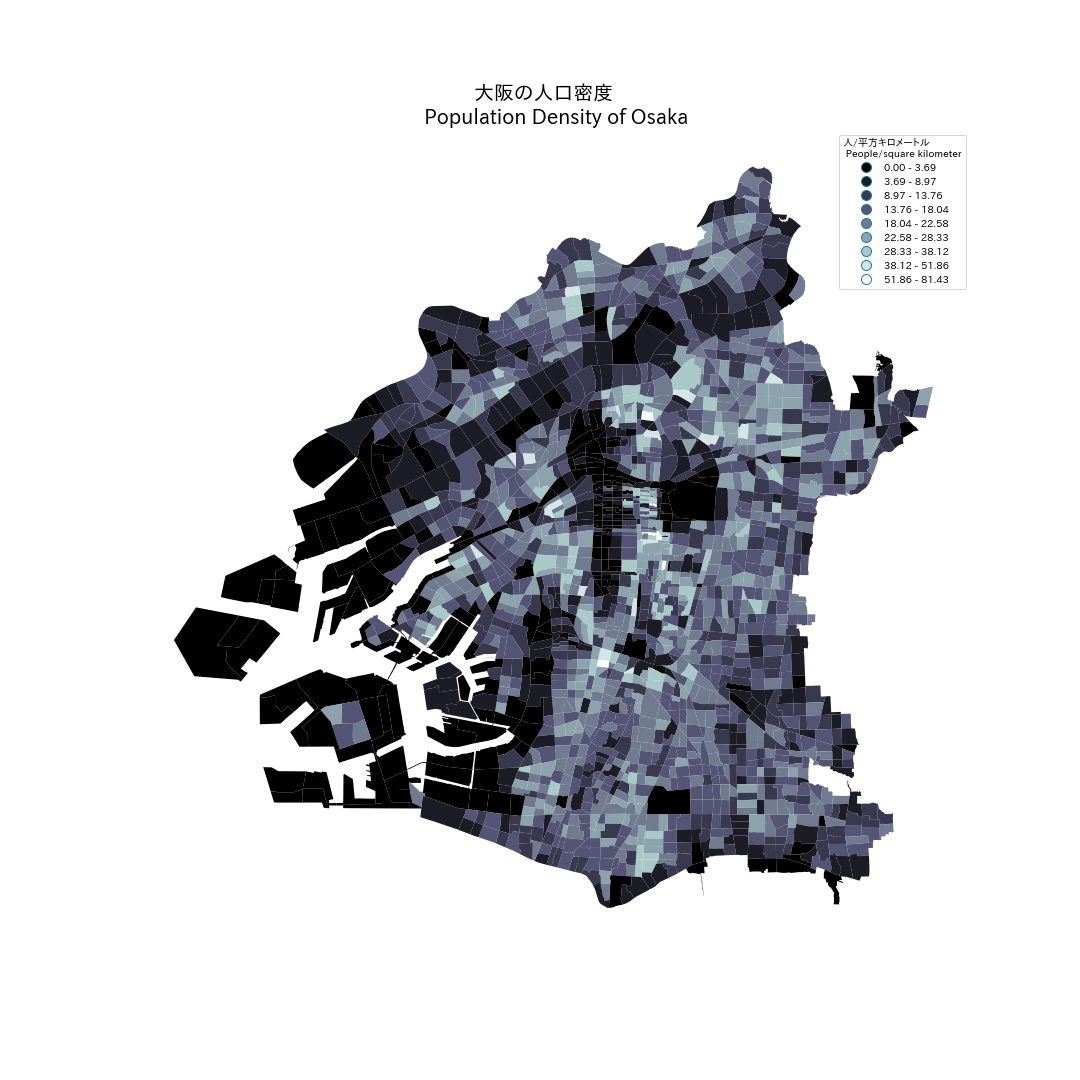
他のちず
したに同じ方法で作られた大阪と名古屋と東京23特別区の地図がアップロードする。