概要
日本の町丁データをe-statでダウンロード出来る。それはいいけど町丁データが細かすぎる場合がある。
例えば、渋谷1丁目、2丁目、3丁目の代わりに「渋谷」だけでいい場合があります。この場合があるからNightleyで町丁データから町域データを作りました。
画像1はグレーで町丁、青で町域が表示されます。
画像1:町丁(グレー)と町域(青)
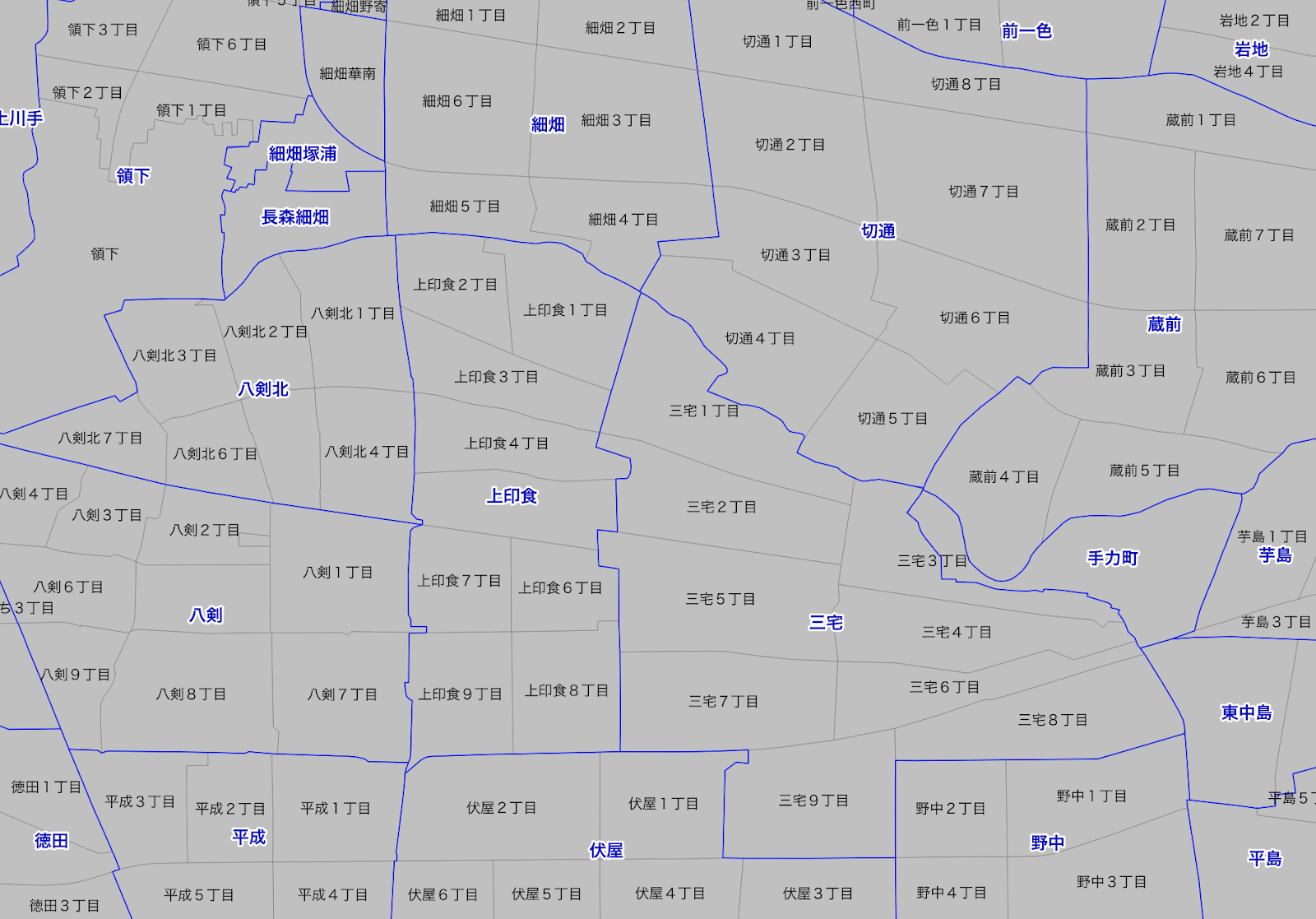
町域データなら三宅1丁目、2丁目じゃなくて、全体の三宅で地理情報データを解析出来ます。
****注意!町域 ≠ 郵便番号エリア ****
町丁から町域に変化させる手順
残念ですけど町域の数字なんか全然ありません。そのため、手順がなかなか難しいです。町丁の名前を使う方法しかありません。都道府県によって町丁の名前システムがぜんぜん違うから変化スクリプトにルールと例外がいっぱいあります。
基本的に6つの表記があります。
- 「丁目」
- 「区」
- 「号」
- 「字」
- 最後の数字
- 「(例)」
表記ごとにルールを作りまして、QGISのField CalculatorにSQLを実行しました。
表記1:「丁目」

上記は4つのルールの説明です。「丁目」の前と後の文字によって違うルールを作りました。
表記2:「区」
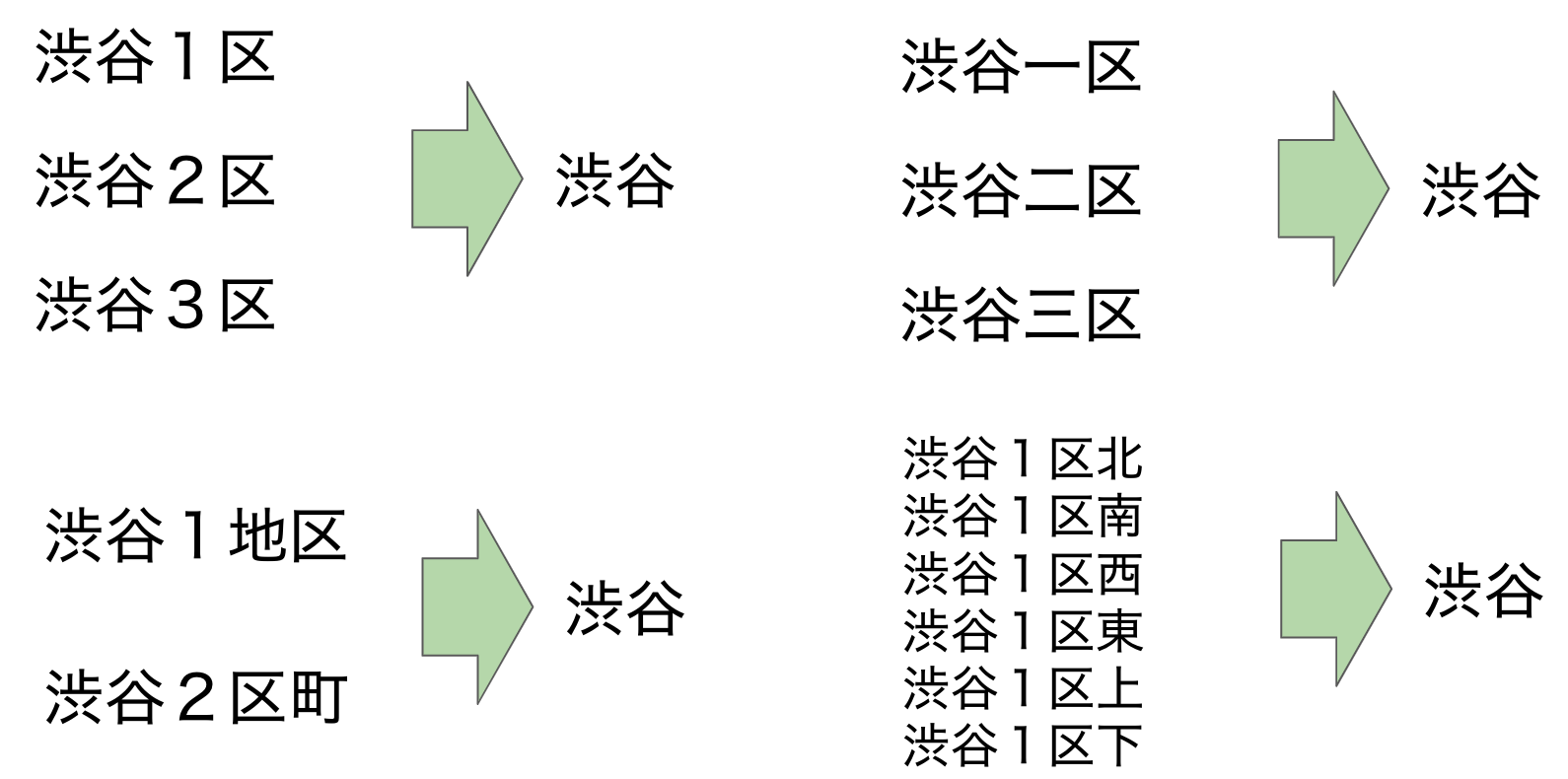
上記は4つのルールの説明です。「区」の前と後の文字によって違うルールを作りました。
表記3:「号」

上記は2つのルールの説明です。「号」の前の文字によって違うルールを作りました。
表記4:「字」
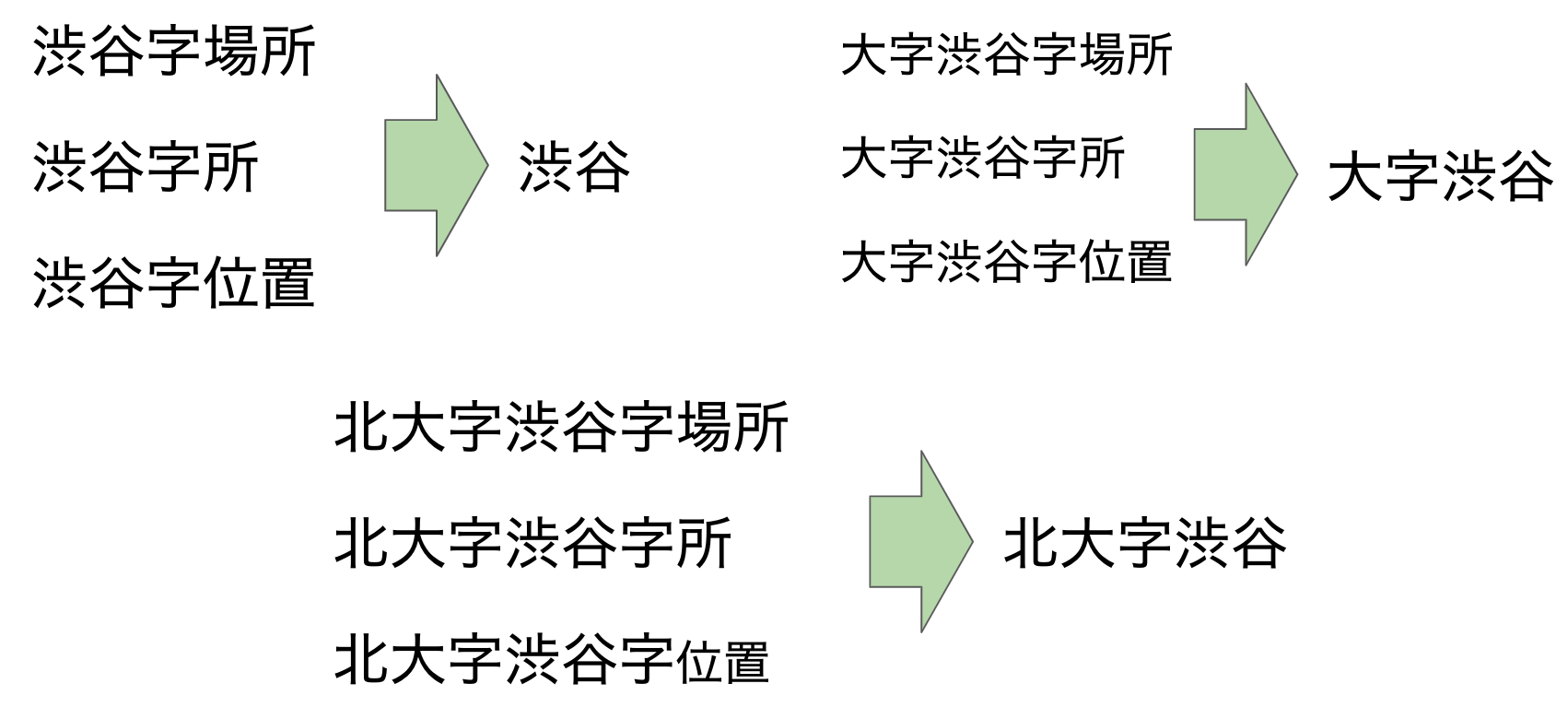
上記は3つのルールの説明です。「字」の前と後の文字によって違うルールを作りました。
表記5:最後の数字
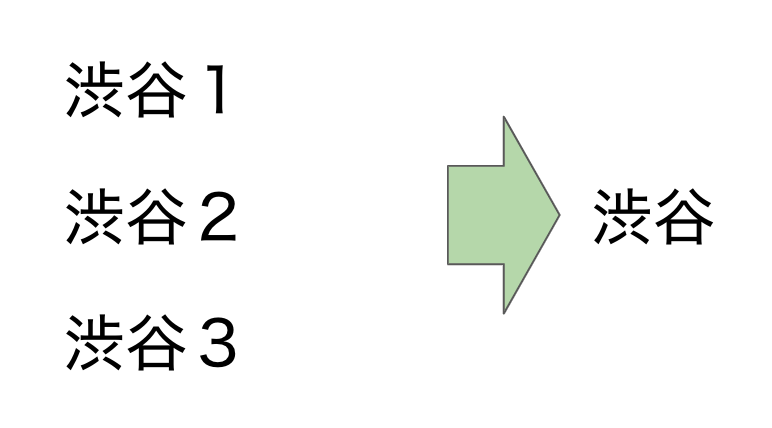
上記は1つのルールの説明です。最後の文字は数字なら、消します。
表記6:「(例)」
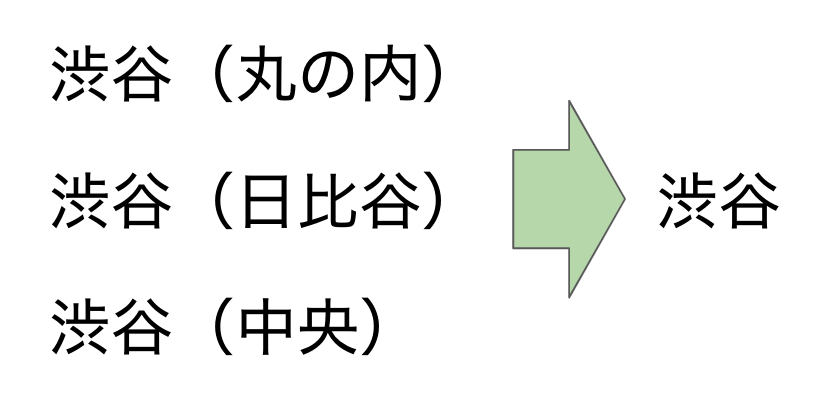
上記は1つのルールの説明です。括弧の中に文字があれば、消します。
訂正
上記のルールを実行してからいろいろな問題が残りました。
市区町村によって、町丁の名前は数字が二つ以上あるかもしれません。
例えば:
惣高瀬町1, 2, 3
下方上畝1, 2, 3
その場合に数字とコンマを全て消します。
結果:
惣高瀬町
下方上畝
その後、町丁の名前の最後の残っている文字は下記リストが似合ったら、その文字消します。
・
,
、
(
第
例外
残念ながら上記の手順をするでも例外があります。一つずつに変更しなければなりません。
下記はルール実行の後例外の名前と変更された名前です。
-----------------------↓例外↓---------------------------------------↓変更↓--------------------------
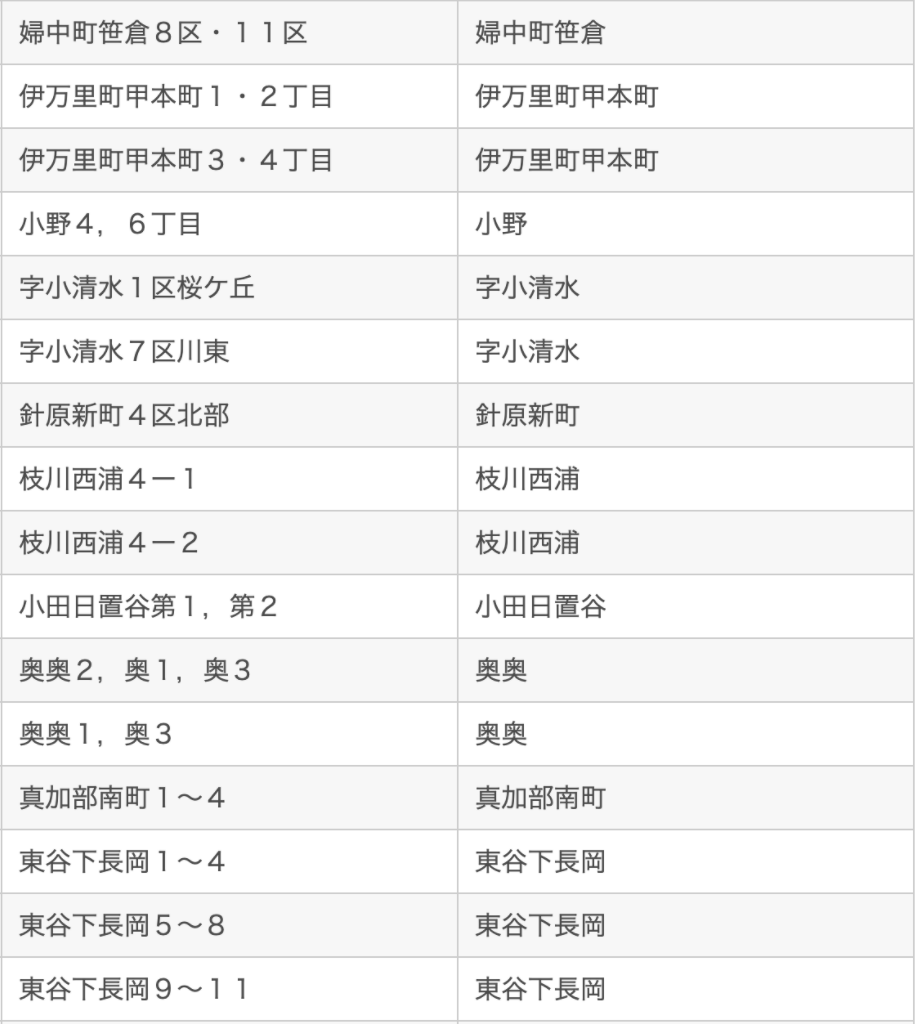
結果
青い線は町域と表示して、細くてグレー線は町丁と表示します。
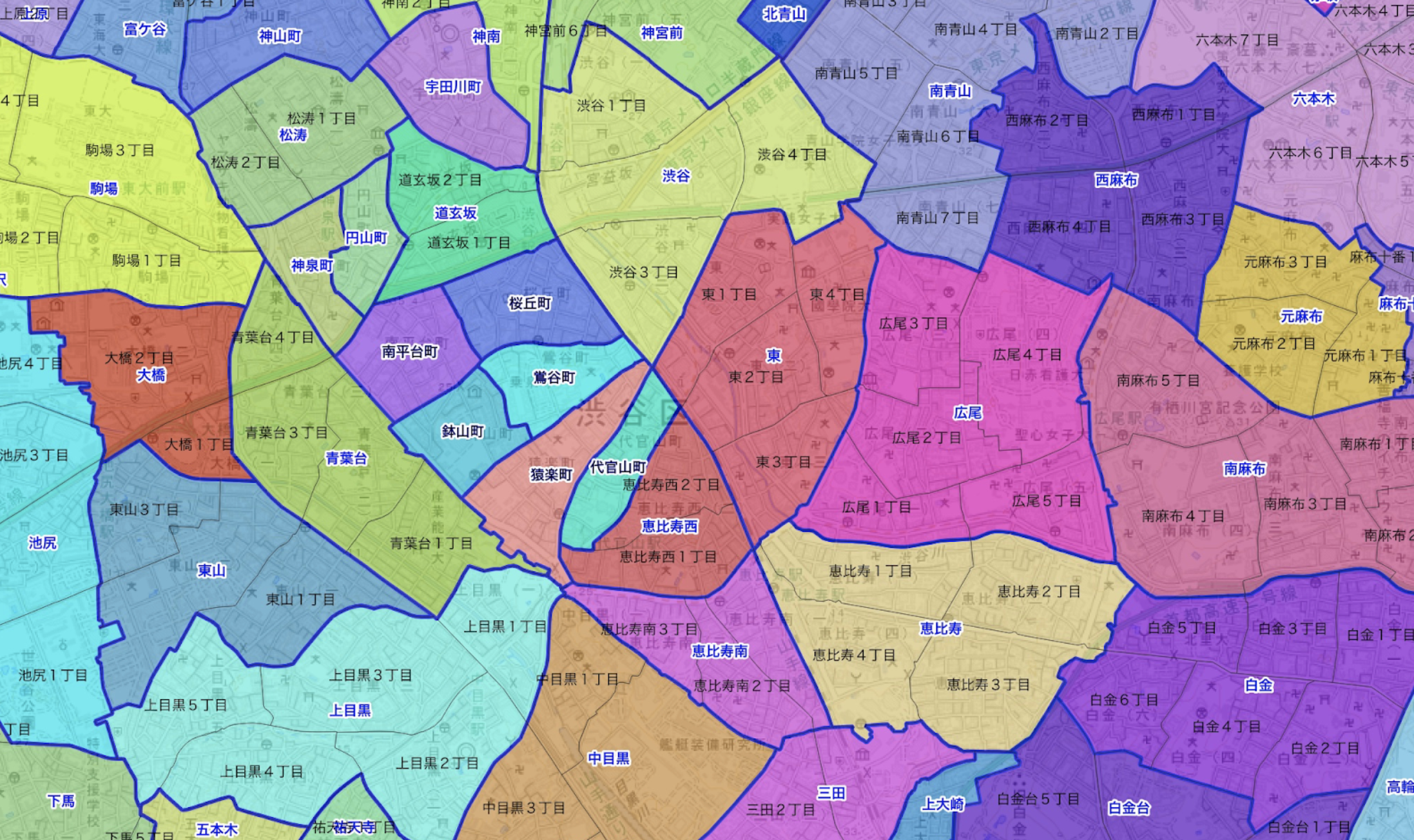
全ての結果は理想じゃありません。例えば町域が分離の場合があります。
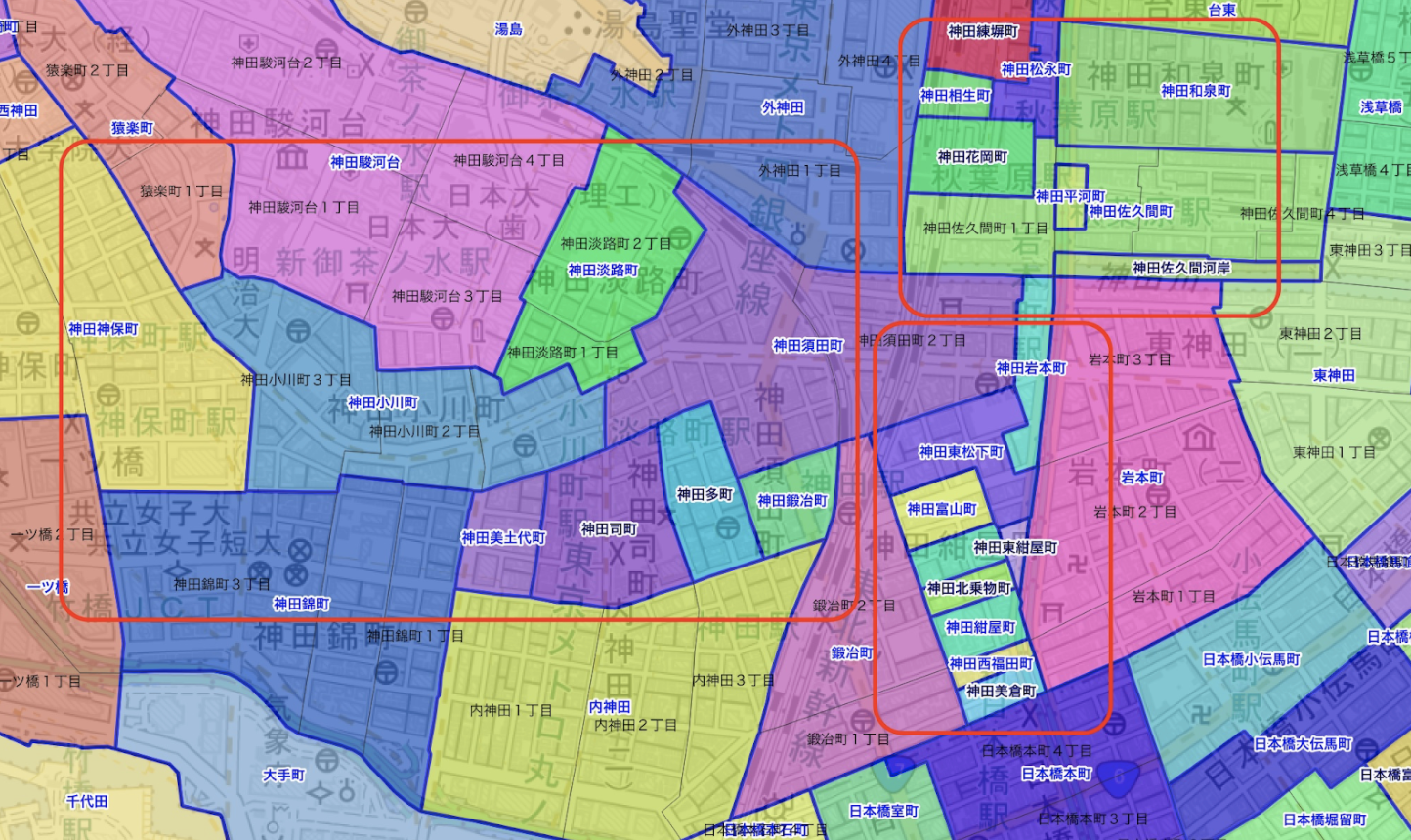
札幌でかなり細くて長い町丁があります。この種類の名前は条で終わります。条に関係ルールを実行しようとしたけど悪い結果がありました。条は町丁の名前のなかに最後だけじゃなくて色々な位置にあるから消したらナンセンスの名前が作られました。
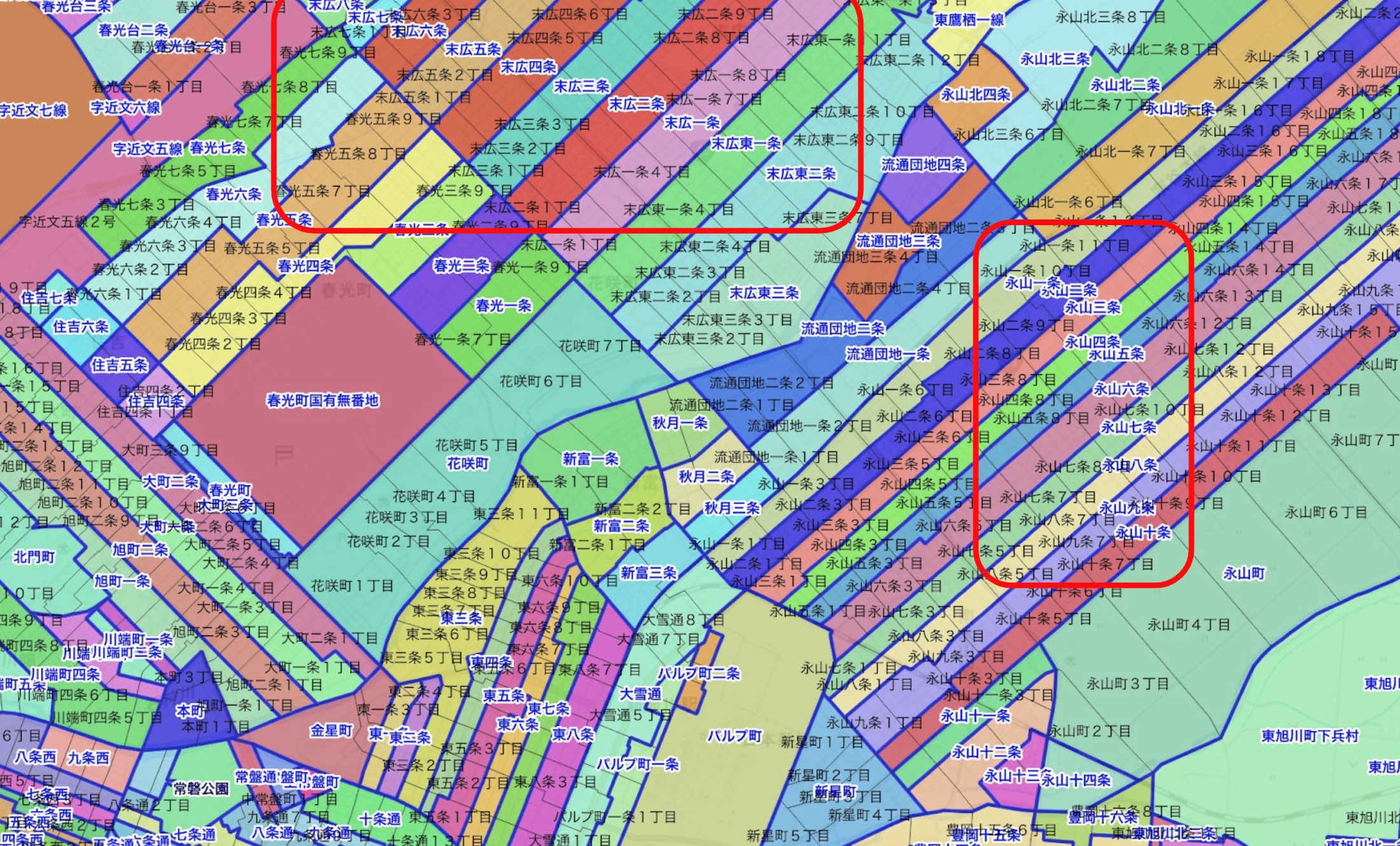
これは理想じゃないけど原因は町域の形だから仕方がありません。
結論
この手順は完璧じゃありません。気がつかない例外まだあるかもしれません。さらにQGISのSQLは複雑でした。でも町域ポリゴンが必要な場合、この手順は最高だと思います。