まえがき
ローカルPCやクラウドのインスタンス上で、データを分析したり、機械学習モデルを作ったりする。
データサイエンティスト(DS)や機械学習エンジニアと呼ばれる職業だ。
そんな私のこれまでの悩みが、モデル作るところまではできるが、非エンジニアが気軽に触れられる形でのリリースができない(やったことがない)。
仕事では、一緒に働く仲間としてMLOpsエンジニアがいるため、モデル作成までしてDockerfileまで書いたら渡すとか、FastAPIのコードだけ書いてサービングはお任せするという役割分担ができてしまう。
プロダクトレベルのものを作る際は、保守やセキュリティの面でも知識のある人が担当した方がいいので至極当然なのだが、データサイエンティストもデモのリリースくらいは自力でやれるようになりたい。
この記事はそんな要望を満たすものです。
対象読者と学べるサービス
- APIやデモアプリをリリースしたい人
- 「インスタンス上で作業するだけ」から脱却したい人
最低限のセキュリティ担保のために、以下のものにも触れます。
- Secret Manager
- IAM(Identity and Access Management)
- OAuth2.0
- IAP(Identity-Aware Proxy)
- ファイアウォール ルールによるIP制限
この段階では知らない単語だらけでも構いません。
本編
実際の運用にはterraformを使った設定管理が楽ですが、ここではとっつきやすいようにWebUIでの設定で済むように説明をしています。
Streamlitアプリを特定のユーザーのみが触れるようにする
PythonのWebUIといえば、StreamlitやGradioがあります。
本格的なプロダクトであれば、PythonでUIを書くのはイマイチですが、デモアプリであれば十分です。
このセクションでは、Cloud RunとApp Engineを使ったデプロイ方法を紹介します。
どちらも、サーバーレスなサービスで、アクセスが増えたときのオートスケールにも対応しています。
公式でも比較がありますが、ここではstreamlitアプリのサービング観点で比較をします。
| 特徴 | Cloud Run | App Engine |
|---|---|---|
| 最小インスタンス数を0にできる | ⭕ | △(standard環境のみ) |
| IP制限 | ❌(単体では不可) | ⭕ |
| WebSocket対応 | ⭕ | △(flex環境のみ) |
| Googleグループでのアクセス管理 | ❌(単体では不可) | ⭕ |
※2025/4/11現在、まだPreview版ですがCloud RunにもIAP設定が追加されたためGoogleアカウントによるアクセス管理が簡単になりました。
App Engineには、standard環境とflex環境の2つがあります。
StreamlitはWebSocketを使ったアプリであるため、flex環境が必須なのですが、そうなるとインスタンスを最低1つ起動しておく必要があり、常に費用がかかります。
その代わり、IP制限を楽に設定できるため、社内ネットワークからのみアクセスを許可したいニーズに簡単に応えられます。
Cloud Runは、最小インスタンス数をゼロにしておけば、使っていない間インスタンスを止めておけるので、費用面でお得に思えます。
一方で、セキュリティ面はCloud Run単体で担保するのが難しく、IP制限をするにはロードバランサ(https通信だとドメインの発行も必要)を立て、Cloud ArmorでIP制限をしなければいけません。(こうなると、ロードバランサは常に起動することになるため、システム全体で見ると最低1台は常にインスタンス起動していることになる。)
アプリケーション側(Streamlit側)でユーザー認証を挟むことは簡単ですが、認証画面までは誰でもアクセスできるため、DDoS攻撃を受けると常にインスタンスが起動してしまうリスクがあります。
ではどちらを使うといいのか?
たくさんのアプリをデプロイしたいケースでは、ロードバランサを1台立てて、Cloud Runを使うのが良いと思います。
1つのアプリをリリースするケースでは、セキュリティと費用と手間のトレードオフで考えるべきでしょう。
StreamlitのようなWebアプリではなく、FlaskやFastAPIによるAPIであれば、standard環境で動くので、IP制限をしたければAppEngineがおすすめです。
Cloud Runを使う場合
先ほど説明したとおり、Cloud RunでIP制限をかけるにはやや複雑な設定が伴うので、ここでは簡単な認証をStreamlit側で行い、デプロイする方法を紹介します。
StreamlitとOAuth2.0を使って、Googleアカウントの特定の企業ドメインだけを許可する実装を紹介します。
今回使用するソースコード+α:
追加でBASIC認証とIPアドレス認証のアプリ側での実装も載せてせてます。
ソースコード等の準備
pythonのパッケージ管理にはuvを使ってます。
uv init
uv add google-auth-oauthlib google-cloud-secret-manager python-dotenv streamlit
必要になるパッケージをaddしておきます。
用意するファイルの紹介。
-
app.py: メインコード。ここにリリースしたいアプリのコードを書く -
src/-
oauth.py: OAuth2.0で認証をするためのコード- OAuth2.0: Googleアカウントなどでログインし認証できるやつ
-
secret.py: Secret Managerからキーやパスワードを取得するコード- Secret Manager: GoogleCloudでパスワード管理できるサービス
-
-
Dockerfile: コンテナにまとめるための記述ファイル -
.env: ローカル用環境変数の定義 -
.gcloudignore: デプロイ時にアップロードしたくないファイルを記載
import streamlit as st
from src.oauth import login
def main():
login() # 認証
# 認証済みの場合、メインアプリの画面を表示
st.title("メインアプリ画面")
st.write("ここにログイン後のアプリコンテンツを表示します。")
if __name__ == "__main__":
main()
app.py内でログイン画面を呼び出して、ログイン通過したユーザーだけが、メインアプリへ到達できるようなコードになっています。
import streamlit as st
from google_auth_oauthlib.flow import Flow
import google.auth.transport.requests
import google.oauth2.id_token
import requests
import os
from .secret import get_secret
from dotenv import load_dotenv
# ローカル用
load_dotenv()
PROJECT_ID = os.getenv("PROJECT_ID")
OAUTH2_CLIENT_ID = os.getenv("OAUTH2_CLIENT_ID")
OAUTH2_CLIENT_SECRET = os.getenv("OAUTH2_CLIENT_SECRET")
REDIRECT_URL = os.getenv("REDIRECT_URL")
client_config = {
"web": {
"client_id": get_secret(PROJECT_ID, OAUTH2_CLIENT_ID),
"client_secret": get_secret(PROJECT_ID, OAUTH2_CLIENT_SECRET),
"redirect_uris": [REDIRECT_URL],
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://oauth2.googleapis.com/token",
}
}
def get_google_flow():
flow = Flow.from_client_config(
client_config=client_config,
scopes=[
"openid",
"https://www.googleapis.com/auth/userinfo.email",
"https://www.googleapis.com/auth/userinfo.profile",
],
redirect_uri=client_config["web"]["redirect_uris"][0],
)
return flow
def login():
if "authenticated" not in st.session_state:
st.session_state.authenticated = False
if st.session_state.get("authenticated"):
return
# ログイン画面
st.title("Google認証")
if "code" not in st.query_params:
flow = get_google_flow()
auth_url, _ = flow.authorization_url(prompt="consent")
st.page_link(auth_url, label="Googleでログインする")
else:
code = st.query_params["code"]
flow = get_google_flow()
flow.fetch_token(code=code)
credentials = flow.credentials
request_session = requests.Session()
token_request = google.auth.transport.requests.Request(session=request_session)
try:
id_info = google.oauth2.id_token.verify_oauth2_token(
credentials.id_token, token_request, client_config["web"]["client_id"]
)
# たとえば、特定のメールドメインに限定したい場合は以下のようにチェックできます
allowed_domains = ["example.jp"]
user_email = id_info.get("email", "")
if not any(user_email.endswith("@" + domain) for domain in allowed_domains):
st.error("このアカウントではログインできません。")
st.stop()
# ここで認証されたユーザー情報(例:メールアドレスなど)を利用できます
st.success(f"ログイン成功!ようこそ、{id_info.get('email')}さん")
# 認証に成功したので、セッションステートに反映し画面を切り替え
st.session_state.authenticated = True
st.query_params.pop("code")
st.rerun()
except ValueError as e:
st.error("トークンの検証に失敗しました。")
st.error(e)
st.stop()
ログイン画面と認証を行っているコードです。
この例では、Googleログインしたメールアドレスを取得し、そのGoogleのアドレスがexample.jpというドメインを持つユーザーのみを許可しています。
特定のメールアドレスだけを許可するようにも変更可能です。
読み込んでいる環境変数の説明は後述します。
from google.cloud import secretmanager
def get_secret(project_id, secret_id, version_id="latest"):
"""Secret Managerからパスワードを取得する
Args:
project_id (str): Google Cloud プロジェクト ID
secret_id (str): シークレットの ID
version_id (str): シークレットのバージョン (デフォルトは "latest")
"""
# クライアントの初期化
client = secretmanager.SecretManagerServiceClient()
# シークレットのパスを作成
name = f"projects/{project_id}/secrets/{secret_id}/versions/{version_id}"
# シークレットのアクセス
response = client.access_secret_version(name=name)
# ペイロードの取得
payload = response.payload.data.decode("UTF-8")
return payload
Secret Managerにアクセスするための関数を定義しています。
FROM python:3.11-slim
RUN apt-get update
RUN apt-get install -y tzdata locales
RUN locale-gen ja_JP.UTF-8
ENV TZ=Asia/Tokyo
ENV LANG=ja_JP.UTF-8
ENV LANGUAGE=ja_JP:ja
RUN pip install --upgrade pip
RUN pip install uv
COPY uv.lock pyproject.toml ./
RUN uv sync
COPY src src
COPY app.py app.py
CMD ["uv", "run", "streamlit", "run", "app.py", "--server.port", "8080"]
Dockerfileの一例です。Dockerfileなしでもデプロイできますが、パッケージ管理などを考えるとあったほうが楽に思えます。
PROJECT_ID="プロジェクトID"
OAUTH2_CLIENT_ID="oauth2-client-id"
OAUTH2_CLIENT_SECRET="oauth2-client-secret"
REDIRECT_URL="http://localhost:8501"
ローカル用の環境変数の設定ファイルです。
パスワードはSecret Managerにあり、ここに直接パスワードを書くわけじゃないので、最悪python内にハードコードでも大丈夫です。
(最初パスワード管理をSecret Managerを使わずに環境変数で管理していたのを、よりセキュアにしました。)
.env
.venv
__pycache__/
*.pyc
.git
アップロードしたくないファイルを指定しています。重い.venvやパスワードを載せる可能性のある.envファイルは、アップロードしないようにします。
OAuth 2.0の設定
- OAuth 2.0 から「クライアントを作成」
- 「認証済みのリダイレクトURI」に http://localhost:8501 を設定
- 後でデプロイ後に生成されたアドレスも記載します
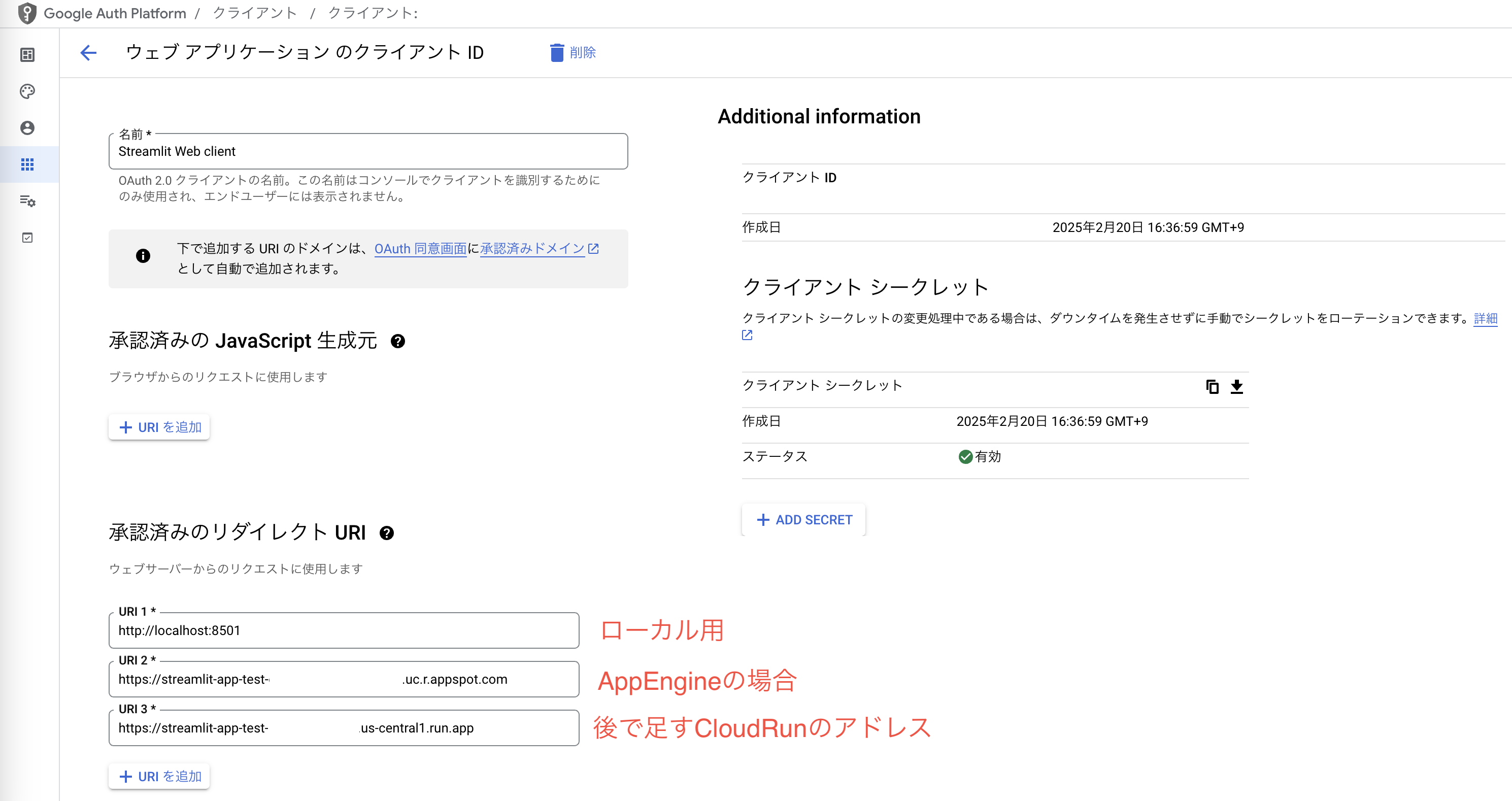
「クライアントを作成」するとIDとパスワードが生成されるので、これをシークレットマネージャーに登録します。
gcloud secrets create oauth2-client-id --replication-policy="automatic" --data-file=<(echo -n "ここにキーを書く")
gcloud secrets create oauth2-client-secret --replication-policy="automatic" --data-file=<(echo -n "ここにキーを書く")
もしくはWebUIのSecret Managerから登録しても構いません。

ローカルでの動作確認
ここまでの設定が済んでいれば、まずはローカルで動作確認できます。
uv run streamlit run app.py
で起動すると、ログイン画面が現れます。

ローカルでは自分のGoogleアカウントの権限が使われるのでgcloud auth loginとgcloud auth application-default loginが済んでいれば、正常に実行できるはずです。


Cloud Runへのデプロイ
いよいよCloud Runを使うときが来ました。
環境変数を指定しつつCloudRunにデプロイします。
gcloud run deploy streamlit-app-test --region "us-central1" --source . \
--set-env-vars PROJECT_ID=プロジェクトID,OAUTH2_CLIENT_ID=oauth2-client-id,OAUTH2_CLIENT_SECRET=oauth2-client-secret \
--max-instances 2 --memory 1Gi
これを実行すると、ソースコード一式がアップロードされ、Cloud Buildが走り、streamlit-app-testというアプリ名でCloud Runにリリースされます。
(Allow unauthenticated invocations to [streamlit-app-test] (y/N)?はyと答えます。URL自体へのアクセスは誰でもできるようになります。)

Cloud Buildの権限まわりでデプロイに失敗する場合は、IAM画面から、Cloud Buildで使っているサービスアカウントに権限を付与しましょう。
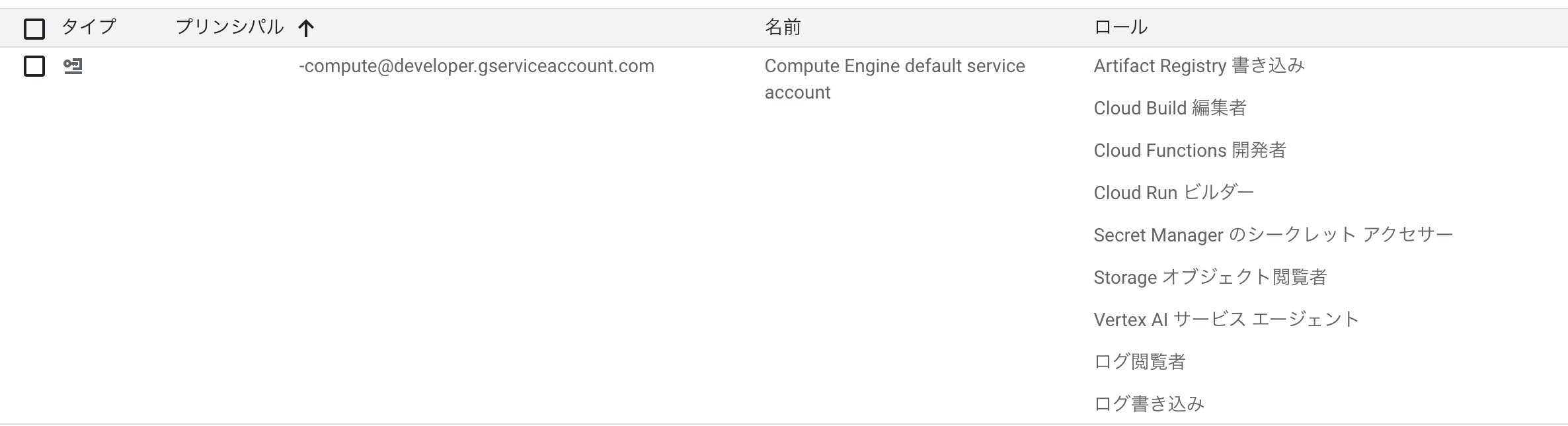
(他サービス用にあとから権限追加したものもあるので、この画像は最小限の権限ではありません)
または、サービスアカウントをビルド用・実行用に作成をして、デプロイ時に以下のようなオプションで指定できます。
--build-service-account=projects/{project}/serviceAccounts/cloud-build-sa@{project}.iam.gserviceaccount.com \
--service-account=cloud-run-sa@{project}.iam.gserviceaccount.com
生成されたURLを確認したら、OAuth 2.0の「認証済みのリダイレクトURI」に記載します。
また、CloudRunのデプロイされたアプリページからyamlの設定ファイルを編集して、環境変数REDIRECT_URLを追記します。
env:
- name: OAUTH2_CLIENT_ID
value: oauth2-client-id
- name: OAUTH2_CLIENT_SECRET
value: oauth2-client-secret
- name: REDIRECT_URL
value: ここに生成されたアドレスを書く
- name: PROJECT_ID
value: プロジェクトID
もしくは環境変数を設定して再デプロイしても構いません。
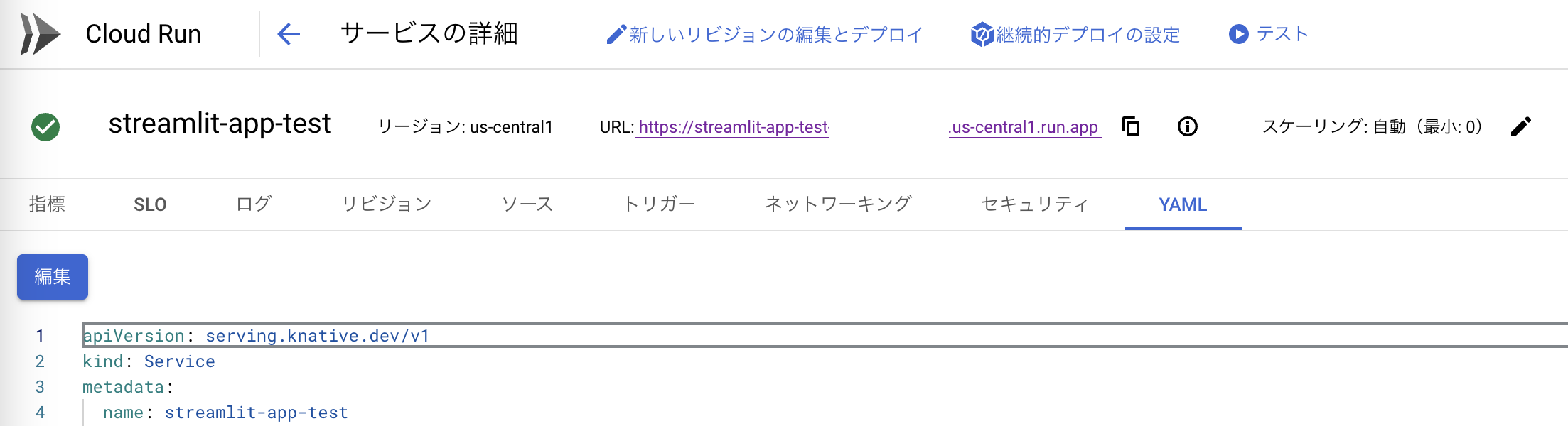
以上の設定が済んだら、アプリのURLにアクセスして無事アクセスできることを確認します。
Cloud Runを実行するサービスアカウントがSecret Managerに権限が無い場合は、IAMからSecret Managerの権限を付与しましょう。(Secret Managerのシークレット アクセサー)
SecretManagerの他にも、Vertex AIのサービスをアプリ内から利用する場合はその権限を与える必要があります。
どうだったでしょうか?
認証まわりを付け加えたせいでややこしさが増えていますが、CloudRunにデプロイするだけなら、pythonコードとDockerfileを用意してgcloud run deployを実行するだけでなので簡単でしたね。
App Engineを使う場合
IP制限だけできればいい場合、先ほど実施したOAuthの設定やログイン画面が不要になるので、Cloud Runより楽です。
もちろん先程のコード一式をそのまま使っても大丈夫です。(IP制限とアプリ側認証の2重になる)
App Engineでは、Google Cloudプロジェクトの最初デプロイは、必ずdefaultという名前のものをリリースしなければいけません。
streamlitアプリをdefaultとしてデプロイするのは気持ち悪いので、APIデプロイの練習も兼ねて、まずはflaskの簡単なAPIをデプロイしておきます。
defaultアプリのデプロイ
これまでとは別のフォルダで作業をしてください。
用意するもの:
-
app.py: flaskで書いたAPI -
app.yaml: デプロイするための設定ファイル -
requirements.txt: 必要なパッケージの記載
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello() -> str:
return "Hello World!"
if __name__ == "__main__":
# ローカル用
app.run(host="127.0.0.1", port=8080)
Hello Worldが返ってくるだけのAPIです。
runtime: python39
entrypoint: gunicorn -b :$PORT app:app
デプロイの設定ファイルです。最小インスタンスゼロにできるstandard環境の書き方です。
flask
gunicorn
上記ファイルを用意したら、次のコマンドでデプロイします。
gcloud app deploy

デプロイ後に生成されたアドレスにアクセスして確認してHello Worldが表示されるか確認します。

デプロイ時に表示されるサービスアカウントがIAMになければ、IAMページから自分で作成して、Cloud Buildなどの必要な権限をあたえる。
IP制限
AppEngineのWebUIにアクセスし、「ファイアーウォール」から許可する/拒否するIPアドレスを記載する。
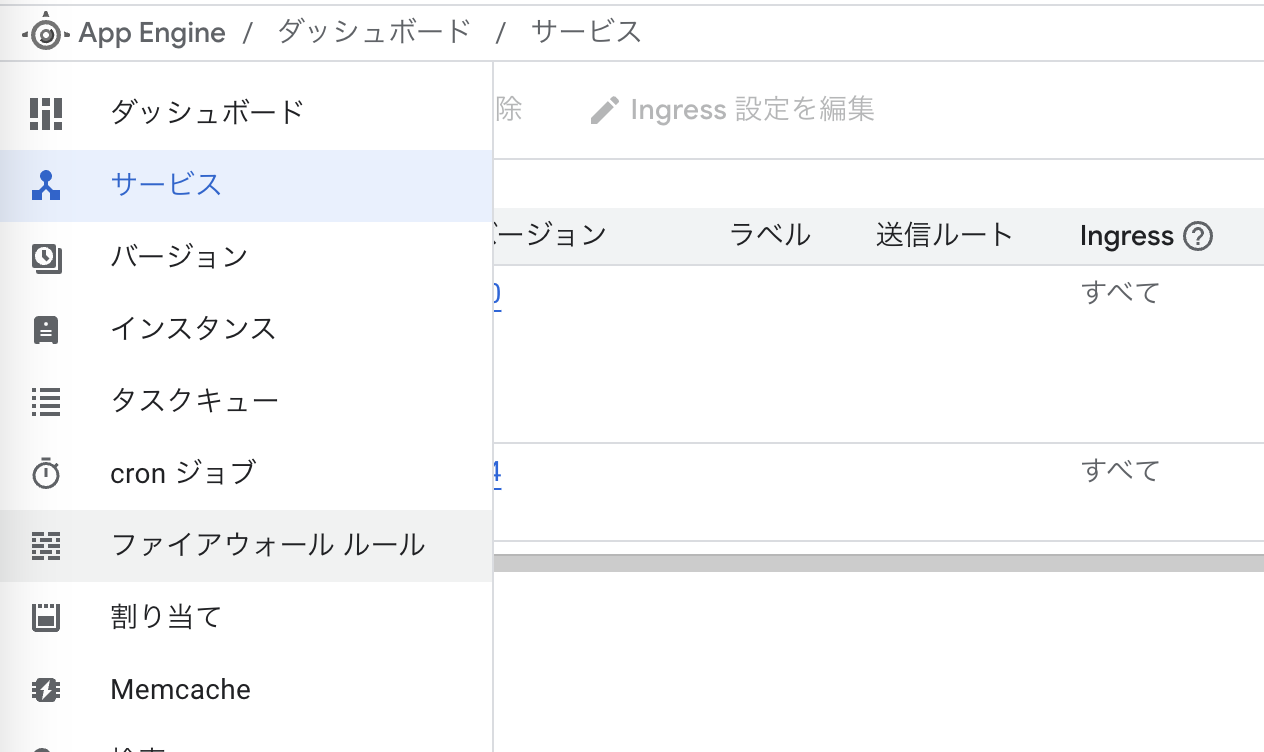

これだけでIP制限ができてしまいます。
先ほどデプロイしたdefaultアプリにアクセスして確認してみましょう。
ファイアーウォールの設定はAppEngine内の全アプリ共通なので、一度だけ設定すればOKです。
AppEngineへのデプロイ
defaultとはフォルダを分けてください。
用意するもの:
-
app.py: streamlitアプリ -
app.yaml: デプロイ設定ファイル Dockerfile
runtime: custom # Docker使う場合
env: flex
entrypoint: uv run streamlit run app.py --server.port $PORT --server.headless true
env_variables: # 環境変数
STREAMLIT_SERVER_HEADLESS: "true"
PROJECT_ID: "プロジェクトID"
OAUTH2_CLIENT_ID: "oauth2-client-id"
OAUTH2_CLIENT_SECRET: "oauth2-client-secret"
REDIRECT_URL: デプロイしてから生成したアドレスを記載して再デプロイする
# 環境変数にパスワードを記録する場合、`env_variables:`のブロックごと別のファイルに書き出してgitignoreに入れておくことができる
# includes:
# - env_variables.yaml
service: streamlit-app-test
automatic_scaling:
min_num_instances: 1 # flexだと0を指定できない
max_num_instances: 2
flex環境を使ったAppEngineの設定ファイルです。
WebSocketを使うアプリやDockerを使う場合はflex環境を指定する必要があります。
最初に注意を書いた通り、flex環境では最小インスタンスが1になってしまい0にできません。
(ちなみにstandard環境でstreamlitアプリを動かすように試行錯誤してみましたが、どうやってもうまく動きませんでした)
serviceを指定しないと、defaultにデプロイされ、先ほどのFlaskアプリが上書きされるので注意です。
上記ファイルを準備したら、同じディレクトリで次のコマンドを打ってデプロイします。
gcloud app deploy
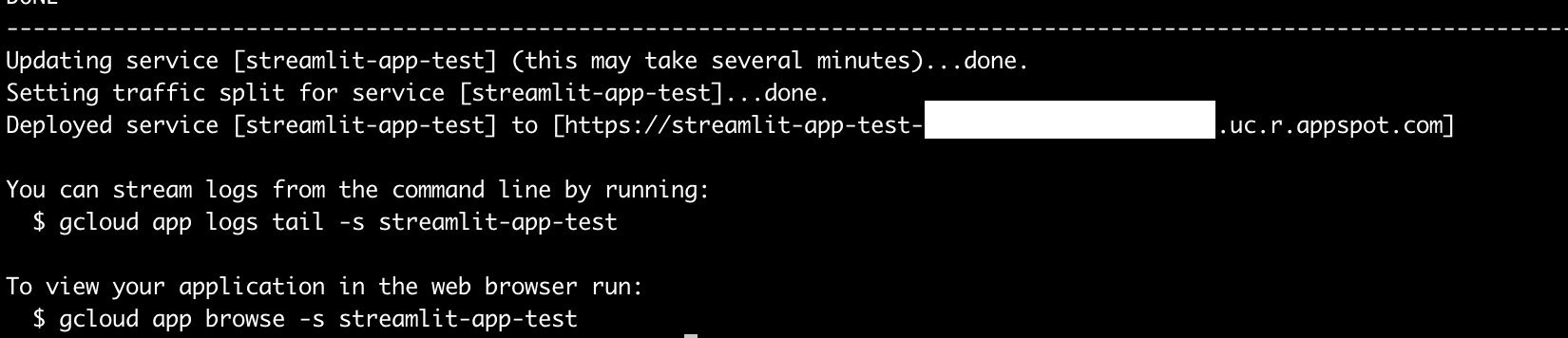
生成されたアドレスにアクセスして動作を確認できます。
(OAuth2.0を指定している場合は、生成されたURLを環境変数に設定して再デプロイ、および、OAuth2.0の「認証済みのリダイレクトURI」への記載が必要です。)
アプリ内でSecret ManagerやVertexAI等にアクセスする場合には、IAMからAppEngineのサービスアカウントに権限を付与します。
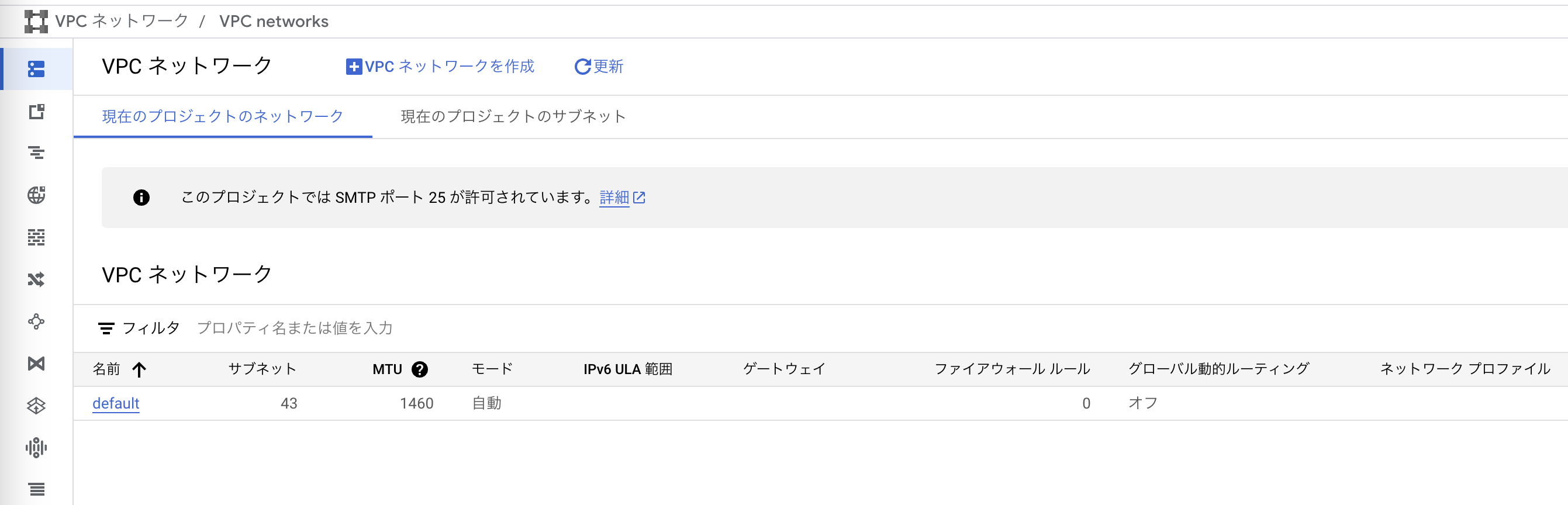
プロジェクトにまだVPC(Virtual Private Cloud)が設定されていない場合は、デプロイ時にエラーが出ると思います。
VPCネットワーク設定が必要なので、WebUIに沿ってクリックしていき、VPCネットワークにdefaultを立てましょう。
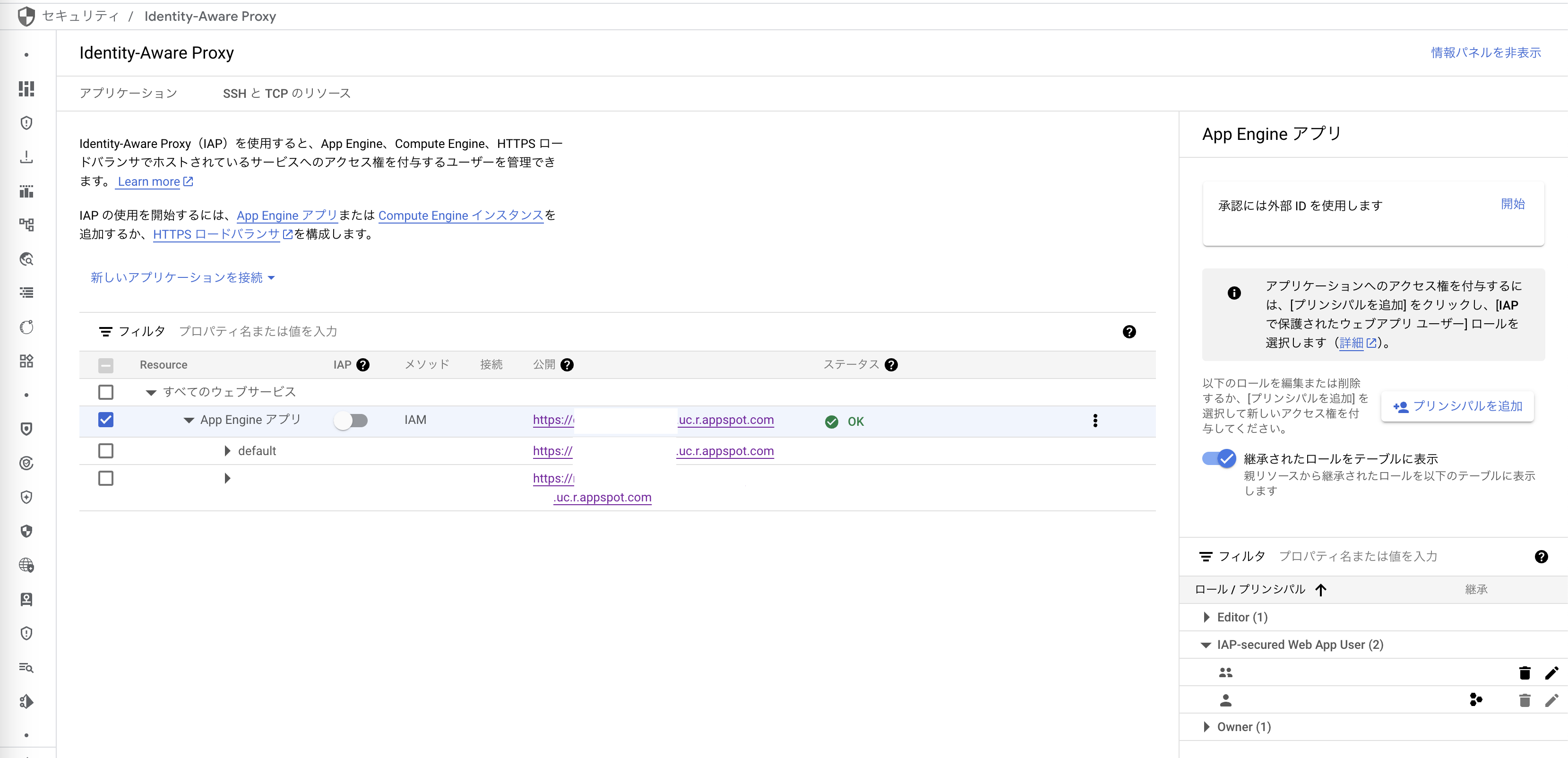
アクセスを特定のGoogleアカウント・グループに絞る
IAP(Identity-Aware Proxy)からAppEngineのIAPを有効にして、クリックした右側のペインから「プリンシパルを追加」で「IAP-secured Web App User」のロールを追加することで、ユーザーを絞れます。
MLモデルを学習するジョブを投げたい
GCE(Compute Engine)のインスタンス上で作業しているとき、学習が終わったら自動的にインスタンス止めたいと思ったことはありませんか?
いよいよインスタンス上での作業から卒業する時です。
ここではVertexAI Custom JobsとVertexAI Pipelinesの2つの方法を紹介します。
| 特徴 | VertexAI Custom Jobs | VertexAI Pipelines |
|---|---|---|
| お手軽さ | ⭕(DockerイメージあればOK) | △(やや複雑) |
| 用途 | 単純な処理向け | 複雑な処理向け |
| 失敗箇所のわかりやすさ | △(ログを見に行く必要がある) | ⭕ |
前処理→学習→評価くらいの処理であればどちらでも良いと思います。
処理が分岐したり増えていって複雑さが増す場合はpipelinesがオススメです。
追記: もっと軽いジョブの場合は、インスタンス起動時間が短いCloud Run Jobsがオススメです。
VertexAI Custom Jobs
テンプレート:
利用の流れ:
- Dockerイメージをビルドする
- jobを投げる
Cloud Build
Dockerイメージのビルドにはローカルでもいいのですが、せっかくなのでCloud Buildを紹介します。
次のような設定ファイルを用意します。
substitutions: # 引数で後から置換する
_IMAGE: region-docker.pkg.dev/project_id/bucket/image
_TAG: latest
steps:
- name: "gcr.io/cloud-builders/docker"
args: ["build", "-t", "${_IMAGE}:${_TAG}", "-t", "${_IMAGE}:latest", "."]
# 複数のタグをpushする場合はpushを明示的に書かないとエラーになる
- name: "gcr.io/cloud-builders/docker"
args: ["push", "${_IMAGE}:${_TAG}"]
- name: "gcr.io/cloud-builders/docker"
args: ["push", "${_IMAGE}:latest"]
images: # ビルドに成功した場合に、Container Registry に自動的に push されるイメージ
- "${_IMAGE}:${_TAG}"
- "${_IMAGE}:latest"
options:
logging: CLOUD_LOGGING_ONLY
latestと任意のタグをつけてpushするコードになっています
Cloud Buildの実行は次のように実施します。
PROJECT=プロジェクト名
REGION=asia-northeast1
IMAGE=$REGION-docker.pkg.dev/$PROJECT/パス/名前
TAG=`date +"%Y%m%d%H%M%S"`
gcloud builds submit --config cloudbuild.yaml --project=$PROJECT --async --substitutions=_IMAGE=$IMAGE,_TAG=$TAG
タグは現在の時刻でつけてます。
--asyncオプションはビルド中にもターミナルが使えるのでおすすめです。
Cloud Buildから状況を確認できます。
ジョブを投げる
gcloudコマンドかライブラリのgoogle.cloud.aiplatformを利用して投げることができます。
こんな感じでジョブを投げれます。
PROJECT=プロジェクト名
REGION=asia-northeast1
IMAGE=$REGION-docker.pkg.dev/$PROJECT/パス/名前
DISPLAY_NAME=ジョブ名`date +"%Y%m%d%H%M%S"`
CONFIG_FILE_PATH=custom-job-config.json
cat << EOF > $CONFIG_FILE_PATH
{
"workerPoolSpecs": [
{
"machineSpec": {
"machineType": "n1-standard-4",
"acceleratorType": "NVIDIA_TESLA_T4",
"acceleratorCount": 1
},
"replicaCount": "1",
"diskSpec": {
"bootDiskType": "pd-ssd",
"bootDiskSizeGb": 100
},
"containerSpec": {
"imageUri": "$IMAGE",
"command": ["uv", "run", "inv", "train"]
}
}
]
}
EOF
gcloud ai custom-jobs create --project=$PROJECT --region=$REGION --display-name=$DISPLAY_NAME --config=$CONFIG_FILE_PATH
マシンスペックと使用するイメージ、実行コマンドを指定して投げるだけです。
投げたジョブはVertexAI→トレーニング→カスタムジョブから確認できます。
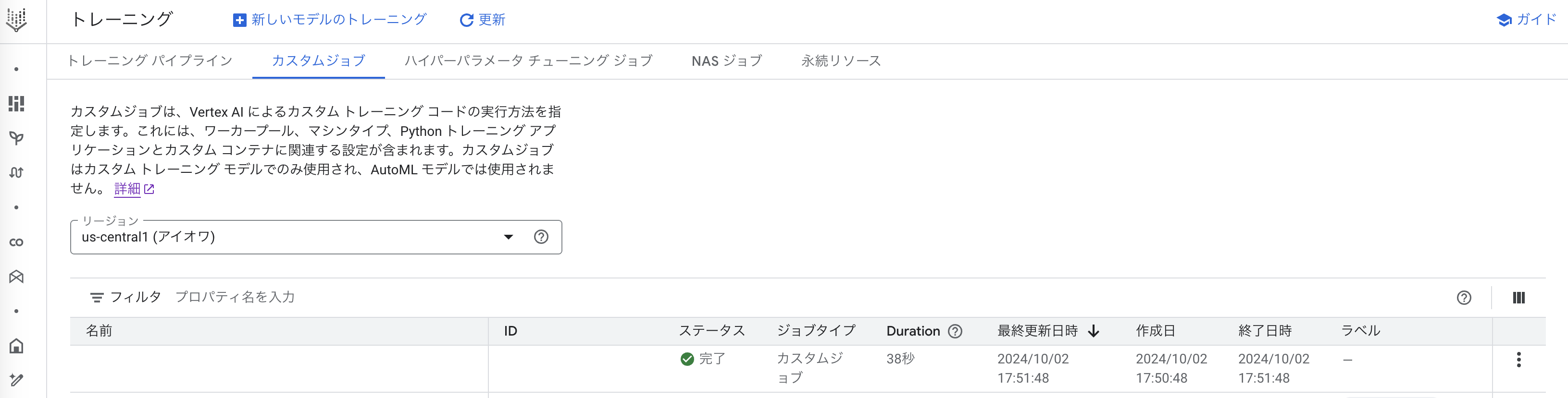
これだけです。
注意点としては、学習した結果は何もしないと失われてしまうので、pythonコード内で学習が終わったら、モデルをCloud Storageに、推論結果をBigQueryに保存などしておくことが必要です。
事前に保存する用のバケットやテーブルを作っておきましょう。
インスタンス上での作業と比べたときの利点は、
- 並列に設定を変えたジョブを投げられる
- 学習が終了したら勝手にインスタンスを終了してくれる
ことです。
VertexAI Pipelines
テンプレート:
利用の流れ:
- Dockerイメージの作成
uv run inv cloud-build - パイプラインのビルド(jsonが出力される)
uv run inv build-pipeline - パイプラインの実行
uv run inv run-pipeline
実行するとこんな感じで確認できます。

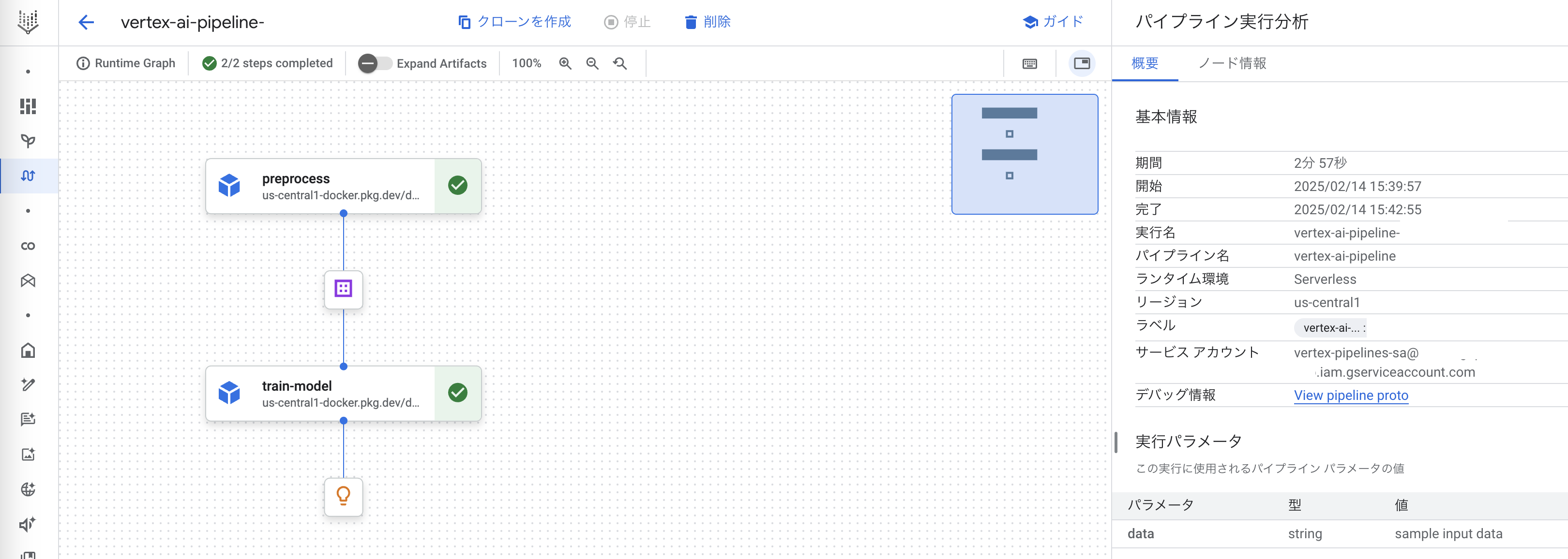
失敗すると失敗したコンポーネントが赤になるので、エラー箇所がわかりやすいわけです。
パイプラインの説明
先程のような画像のパイプラインをpythonのKFP(Kubeflow Pipelines)で記述します。
from kfp import compiler
from kfp.dsl import pipeline, Output, Input, Artifact, ContainerSpec, container_component, PIPELINE_JOB_RESOURCE_NAME_PLACEHOLDER
def compile_pipeline(image: str, output_path: str):
@container_component
def preprocess_component(
project_id: str,
dataset_path: str,
output_data: Output[Artifact],
run_id: str = PIPELINE_JOB_RESOURCE_NAME_PLACEHOLDER,
):
return ContainerSpec(
image=image,
command=["uv", "run", "python", "-m", "src.component.preprocess"],
args=[
f"--project_id={project_id}",
f"--run_id={run_id}",
f"--dataset_path={dataset_path}",
f"--output_path={output_data.path}",
],
)
@container_component
def train_component(
project_id: str,
input_data: Input[Artifact],
output_data: Output[Artifact],
run_id: str = PIPELINE_JOB_RESOURCE_NAME_PLACEHOLDER,
):
return ContainerSpec(
image=image,
command=["uv", "run", "python", "-m", "src.component.train"],
args=[
f"--project_id={project_id}",
f"--run_id={run_id}",
f"--input_path={input_data.path}",
f"--output_path={output_data.path}",
],
)
@pipeline(name="vertex-ai-pipeline")
def vertex_ai_pipeline(project_id: str, data: str):
preprocessed_data = preprocess_component(
project_id=project_id,
dataset_path=data,
)
trained_model = train_component(
project_id=project_id,
input_data=preprocessed_data.outputs["output_data"],
)
# trained_model.after(preprocessed_data)
# キャッシュを無効に
preprocessed_data.set_caching_options(False)
trained_model.set_caching_options(False)
compiler.Compiler().compile(
pipeline_func=vertex_ai_pipeline,
package_path=output_path,
)
kfpの説明
- コンポーネントの型
-
Output: コンポーネントの出力を表す型- 引数に存在している特殊な表記法だが、パイプライン内で実体化するときには何も入力しない
-
.pathで書き込むべきパスが得られる - コンポーネント内でファイルを出力するとその情報が格納される
- ここで書き込んだ内容はGCSに保存される
-
Input: 他コンポーネントのOutputを受け取る型-
.pathで読み込むべきパスが得られる
-
-
PIPELINE_JOB_RESOURCE_NAME_PLACEHOLDER: 実行しているジョブのIDを取得できる便利なプレースホルダー- 実行に対してユニークなIDが得られるので便利
-
- パイプラインの記述
- コンポーネントを呼び出すと処理が走ることを意味する
- デフォルトでは全て並列で実行されるが、
afterで指定した時や、前のコンポーネントの出力を次のコンポーネントが使うときは自動で後続タスクとして定義される
- パイプラインのビルド
-
compiler.Compiler().compileを実行するとコンパイル結果がjsonで出力される
-
設計思想
- パイプライン
pipeline.pyには、各コンポーネントの具体実装を書かない- import周りで失敗することがあったため
- 構造がjsonで吐かれることを思うとここを重くしないほうがよい
-
uv run pythonでDockerに含めたコードを呼ぶだけにする
- 設定ファイルは
invoke.yamlに書いておく- パイプラインビルド時に変数で渡して反映できる
- 各コンポーネントは
argparseで情報を受け取る
パイプラインの実行
パイプランを実行するにはgoogle.cloud.aiplatformのPipelineJobを使ってジョブを投げます。
job = aiplatform.PipelineJob(
project=project,
location=c.config.region,
display_name="vertex-ai-pipeline",
template_path=c.config.pipeline_json,
pipeline_root=f"gs://{project}-vertex-pipelines",
parameter_values={"project_id": project, "data": "sample input data"},
)
job.submit(service_account=f"vertex-pipelines-sa@{project}.iam.gserviceaccount.com")
先程パイプラインをビルドして生成されたjsonを与えています。
(オプション)Cloud Functionsでパイプラインの実行
自分のタイミングでモデルを学習しているだけのユースケースだと不要だが、モデルを定期更新するようなケースでは、パイプラインの実行をクラウド上からも行える必要がある。
そんなときに使えるのがCloud Functionsです。
ローカルで実行していたパイプライン実行の関数部分を切り出してCloud Functionsにデプロイしておきます。
用意するファイル:
-
main.py: 実行したい関数が記載されたpythonファイル -
requirements.txt: 使うパッケージを書く - (パイプラインをビルドして出力されたjson)
デプロイはgcloud functions deployで可能です。
gcloud functions deploy デプロイ名 \
--project プロジェクトID \
--runtime python311 \
--trigger-http \
--entry-point=main \
--source=./cloud_function/ \
--service-account=Functionsのサービスアカウント \
--build-service-account=CloudBuildに使うサービスアカウント \
--memory 512Mi \
--set-env-vars 環境変数の設定
動作確認としてローカルからCloudFunctionsを実行するには、curlでリクエストを投げることで可能です。
定期実行したい場合はCloud Schedulerを設定することで実現できます。
おまけ
GoogleCloud以外の完全におまけな話。
RenderでStreamlitアプリを公開する
Renderは、ウェブアプリケーションやAPIなどをデプロイ・ホスティングするためのクラウドプラットフォームです。
StreamlitのデプロイやFastAPIのデプロイができます。
カスタムドメインの設定もできるため、もしカスタムドメインを購入済みであれば、Cloudflareと連携してアクセス制限もできると思います。
今回は、無料プランでお試ししてみます。
(ドメインを持っていないので、アクセス制限するにはCloudRunのときと同じようにアプリ側で実施することになります。)
流れ
- githubレポジトリにコード一式をpushする
-
app.pyとrequirements.txtが最小構成
-
- Renderからレポジトリを選択してデプロイ
2025年3月現在の無料プラン
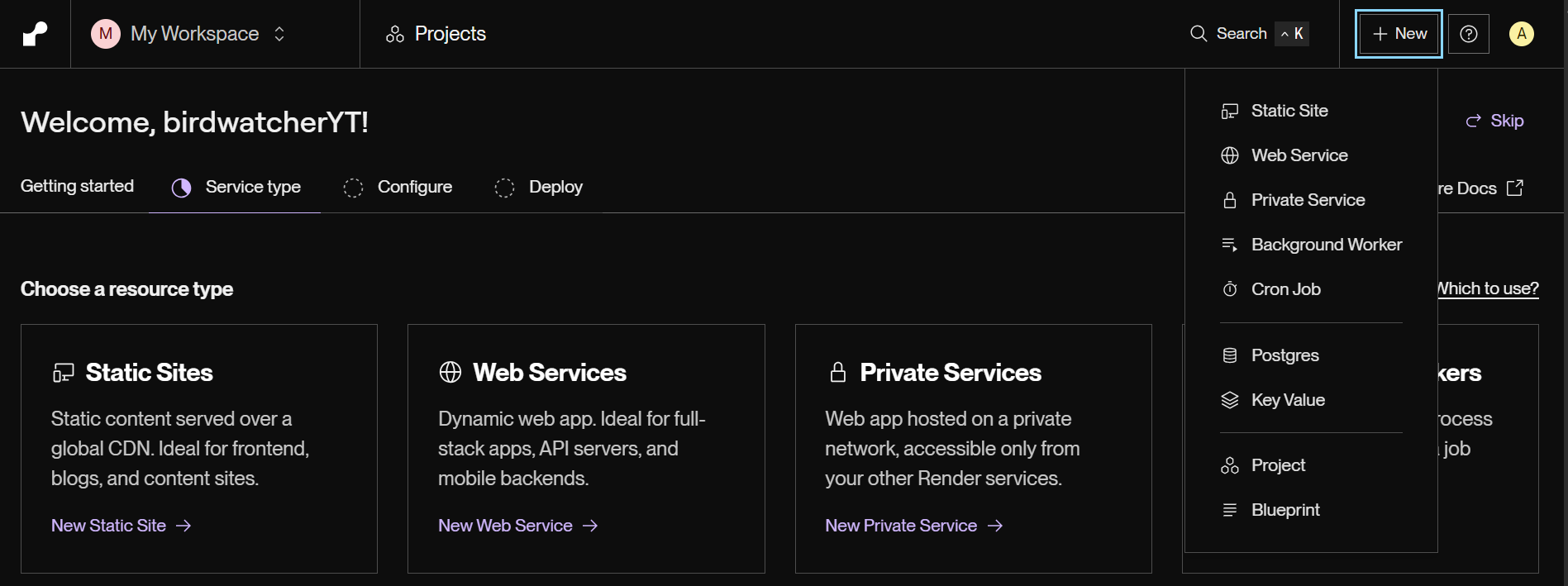
「+New」から「Web Service」を選択
レポジトリの選択(privateレポジトリも選べる)

(Streamlit Community Cloudでは、organizationも含むgithub全体へのアクセス権を求められ、個別の設定ができないように思えましたが、Renderでは個別の設定ができるのがいいですね。)
設定
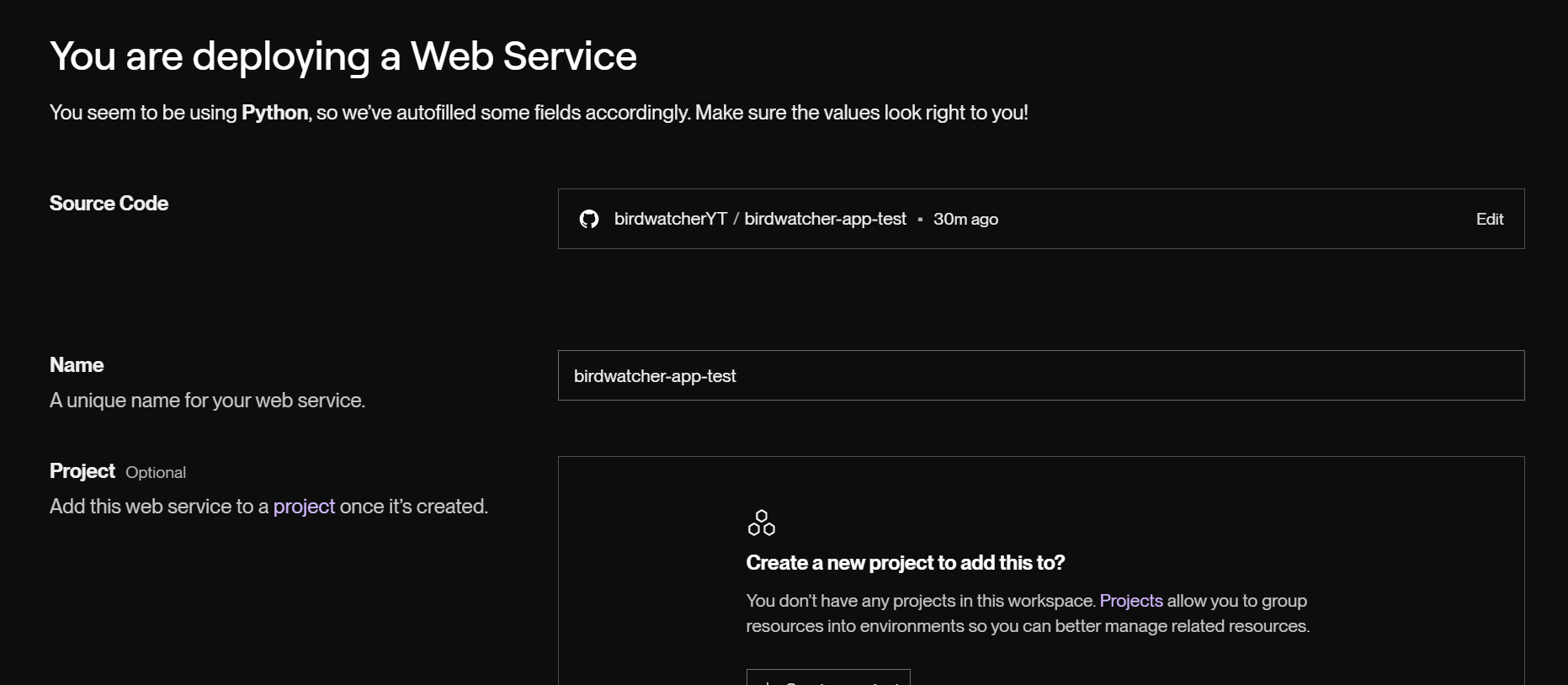
ほとんどは自然に埋まっていました。
- Language: Python3
- Branch: main
- Build Command:
pip install -r requirements.txt - Start Command:
streamlit run app.py --server.port $PORT --server.address 0.0.0.0
フリープランを選ぶ
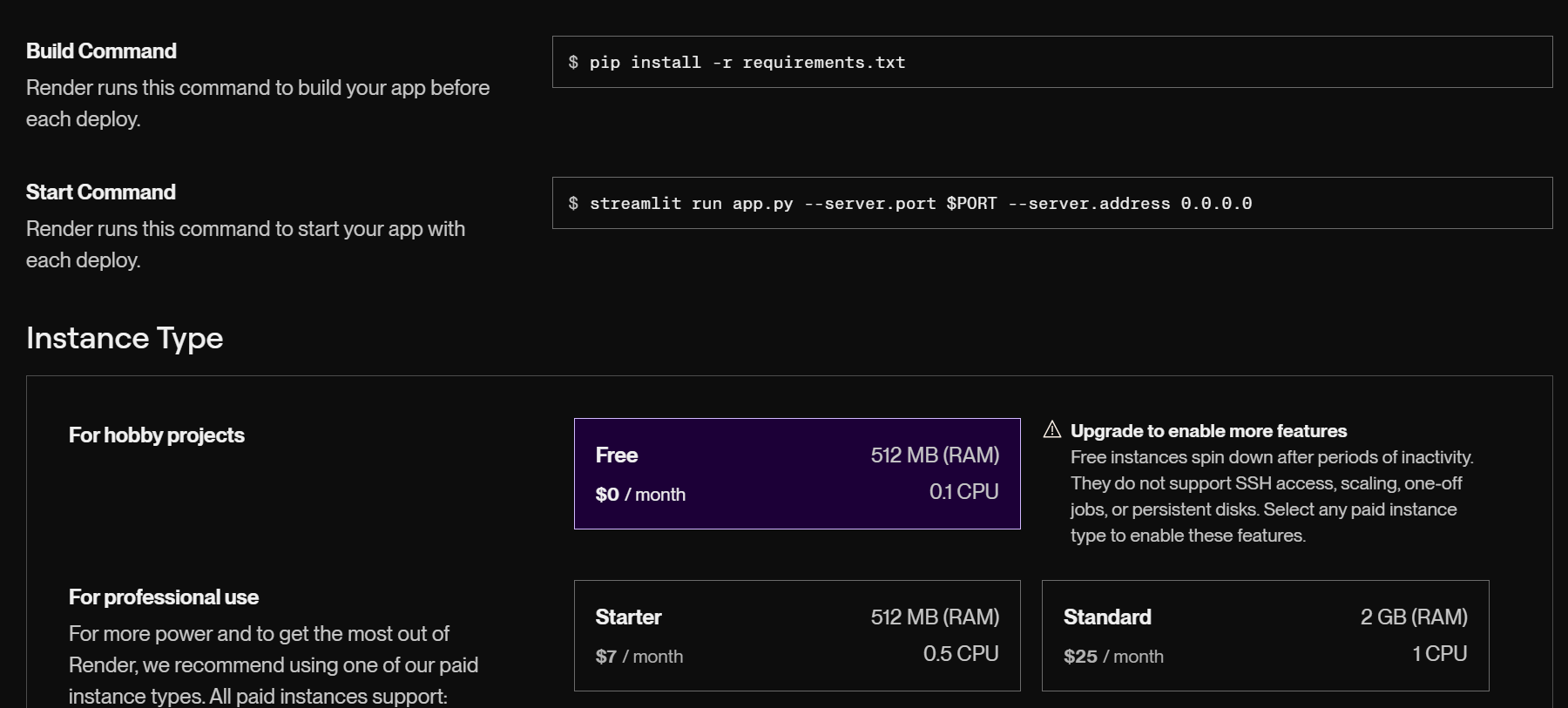
環境変数の設定

最新のコミットから自動デプロイする設定もありました。
デプロイ中

デプロイ完了後、アクセスするとstreamlitアプリが表示されました。
無料かつ個人でアプリをリリースするならRenderは良い選択肢に入ると思いました。(クレカの登録も不要なので安心)
GoogleCloudにも無料枠がありますが、DDoS攻撃を受けたときにお金が発生する可能性があるので、アプリ側での制限ではなく、ちゃんとアクセス自体を制限する必要があります。
しかしそうなると、ロードバランサを立ててドメイン購入 または AppEngineのflex環境+ファイアーウォール となりますが、どちらもコストが発生します。
GoogleCloudで完全無料を保証するのは難しいと思いました。
Google Apps Script(GAS)でWebアプリを作る
pythonを絡まず、GAS(実質ほぼjavascript)で済む場合はこれも選択肢になりうる。
LLMを叩くだけのアプリを作ってみました:

<!DOCTYPE html>
<html>
<head>
<title>テキスト生成アプリ</title>
</head>
<body>
<h1>プロンプトを入力してください</h1>
<textarea id="prompt" rows="4" cols="50"></textarea><br>
<button onclick="generateText()">テキスト生成</button>
<div id="result"></div>
<script>
function generateText() {
const prompt = document.getElementById('prompt').value;
console.log(prompt);
google.script.run.withSuccessHandler(displayResult).generateText(prompt);
}
function displayResult(generatedText) {
console.log(generatedText);
document.getElementById('result').innerText = generatedText;
}
</script>
</body>
</html>
function doGet() {
return HtmlService.createTemplateFromFile('index').evaluate();
}
function generateText(prompt) {
Logger.log(prompt);
// APIキーをスクリプトプロパティに設定(セキュリティのため)
const apiKey = PropertiesService.getScriptProperties().getProperty('GOOGLE_API_KEY');
if (!apiKey) {
throw new Error('APIキーが設定されていません。');
}
// モデル名
const model = 'gemini-1.5-flash'; // または他のモデル名
// リクエストURL
const url = `https://generativelanguage.googleapis.com/v1beta/models/${model}:generateContent?key=${apiKey}`;
// リクエストボディ
const data = {
"contents": [{
"parts": [{ "text": prompt }]
}]
};
Logger.log(data);
// オプション
const options = {
'method': 'post',
'contentType': 'application/json',
'payload': JSON.stringify(data)
};
// APIリクエスト
const response = UrlFetchApp.fetch(url, options);
Logger.log(response);
const result = JSON.parse(response.getContentText());
Logger.log(result);
// レスポンスからテキストを抽出
if (result.candidates && result.candidates.length > 0) {
return result.candidates[0].content["parts"][0].text;
} else {
Logger.log(result); // エラーログ
return 'テキスト生成に失敗しました。';
}
}
APIキーのような漏れたら困る情報は「プロジェクトの設定」→「スクリプト プロパティ」に指定する事ができる。

コードからは、次のように取得できます。
const apiKey = PropertiesService.getScriptProperties().getProperty('GOOGLE_API_KEY');
デプロイ手順を画像で説明します。
- デプロイ→新しいデプロイ

- 設定→ウェブアプリ

- アクセスを承認

- Advanced→Go to プロジェクト名 (unsafe)から進める


- 「開発者を信頼する場合のみ続行してください」という警告ですが、自分が開発者なのでそのまま進めます
- URLが発行され、ウェブアプリとしての動作を確認できる
AppsScriptへのアクセスは、GoogleアカウントやGoogleグループでアクセスできるユーザーを制限できます。(GoogleスプレッドシートやGoogleドキュメントの共有と同じ)
スプレッドシートとのリンクが簡単なので、スプシを簡易DBとして利用できるので、本当に簡単なアプリなら使えるときがあるかも。
あとがき
自分が入社当時、飛び交う知らない単語が飛び交っていた。「CloudRun?Functions?」「デプロイって何?」「パイプラインって何?」って感じだったが、時間が経つにつれ、自分が実装しなくとも関わる機会が増え、言葉と概念くらいは知っている状態から、自力じゃなくても一部を実装する機会を経て、ついに自力で実装する経験をしてみました。
GoogleCloudの各サービス、思った以上に簡単にデプロイできるし、便利だと感じました。
そうは言っても、未だにKubernetesやネットワーク・セキュリティ周りは触るのが怖いです。
生成AIの普及によって、エンジニアリング面も学びやすくなったと感じました。
ChatGPTとエラーなどをやりとりしながら学んでいき、古い情報や非推奨な方法はWeb検索も併用して解決していく。
とっつきにくそうなterraformは、ChatGPTに書いてもらうことで書き方を学べることができました。
いろんなやり方をGPTが基本的に教えてくれますが、それでも実際今回のようにやってみないとわからないポイントも多かったので、経験したからこその本記事が役立つことを祈っています。
参考
- Streamlit with Google Cloud: Hello, world!
-
Streamlit with Google Cloud: Firebase 認証
- パスワードとメールアドレスによる認証を作りたければ、firebaseが使える
-
Streamlit Authenticator を使ってログイン画面を用意
- 一応Streamlit側でもパスワードとメールアドレスによる認証があるらしいが、ユーザー増えたときの対応が面倒かも?
- StreamlitでGoogle OAuth2.0を使った認証を行う
-
Google OAuth2でログインしたユーザーがGoogleグループのメンバーかチェックする(Python,Streamlit)
- Streamlit内でGoogleグループに属しているか確認する方法もあるみたい
-
Cloud Runサービスを「認証が必要」に設定したらブラウザからアクセスできなくなった
- CloudRun単体でアクセス制限しようと試行錯誤していたときに出会った記事
- CloudRunへのアクセスをIAMで制限しても、StreamlitのようなWebからのアクセスでは自動で認証画面に飛ばないので、ロードバランサなどの設定が必要になるようだ