Pythonによるデータ処理: pandasの基礎
これまでデータ分析の際に使ってきたpandasの基本機能を紹介する.
Pythonの機械学習テンプレートはこちら.
前準備
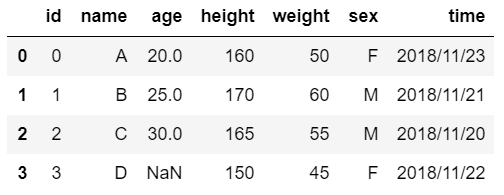
今回対象とするサンプルデータ.
id,name,age,height,weight,sex,time
0,A,20,160,50,F,2018/11/23
1,B,25,170,60,M,2018/11/21
2,C,30,165,55,M,2018/11/20
3,D,,150,45,F,2018/11/22
importするパッケージ
import numpy as np
import json
import pandas as pd
pandasの基本機能
以下の処理は, 順番に実行されているものとして, pandasの基本機能の使用例を書いていく.
実際に実行したい方はこちら (github).
実行結果を見たい人はこちら.
csvロード
df = pd.read_csv("data.csv")
indexの設定
df = df.set_index("id")
"id"の列をindexとして設定する.
mapによる要素置換
df["sex"] = df["sex"].map({"F":0, "M":1})
map関数に辞書を入れるとその通り置換される.
日付の処理
df["time"]=pd.to_datetime(df["time"])
日付の型へ変更.
mapで各要素へ任意の処理
df['day'] = df['time'].map(lambda x: x.day)
df['weekday'] = df['time'].map(lambda x: x.weekday())
map関数のは, 関数も入力できる. ここでは, lambda式で記述.
NaNの数集計
df.isna().sum()
各列でのNaNの数を得る. isna()でNaNのTrue/False行列が得られる.
NaNを埋める
df["age"] = df["age"].fillna(df["age"].mean())
この例では, NaNを平均で埋めている.
要素アクセス
df.loc[0, "name"] = "A"
indexが0で, 列が"name"の位置へアクセスする.
文字列の標準化
df["name"] = df["name"].str.normalize("NFKC")
文字列を標準化できる. この例では, AがAになる. 詳細はこちら.
列名の変更
df.columns = [c.upper() for c in df.columns]
df.columnsに直接, 列名のリストを渡すだけ.
onehot特徴の追加
onehot = lambda target, num: np.eye(num,dtype=int)[target]
df[["weekday_"+str(i) for i in range(7)]] = pd.DataFrame(onehot(df["WEEKDAY"], 7))
weekdayをonehotしてみた例.
データフレーム同士の連結
df = pd.concat([df, pd.DataFrame([[1,2],[3,4],[5,6],[7,8]], columns=["x", "y"])], axis=1)
axis=1では, 横方向の結合. axis=0で, 縦方向の結合.
それぞれmatlabでいうところの, [A,B]と[A;B].
列追加
df["z"] = [1,2,3,4]
1列追加するだけなら, 任意の列名に直接リストを代入するだけでよい.
条件による抜き出し
df[df["SEX"]==1]
性別が1のユーザを抽出.
転置
df.T
向きを変えて表示.
データフレームの各要素に対する任意の処理
df[["xx","yy"]] = df[["x","y"]].applymap(lambda x: x*x)
mapのデータフレーム版がapplymap.
列削除
del df["x"]
df = df[[c for c in df.columns if not c=="y"]]
df = df.drop("z", axis=1)
delやdropでも消せるし, 必要な列だけを選ぶということで削除を実現することもできる.
辞書へ変換
df.to_dict()
集計処理
df.groupby(["SEX"]).mean()
性別でグループ分けして, 平均をみる.
mean()以外に, count(), max(), min()など.
種類の確認
df["SEX"].unique()
性別の種類(集合)を確認.
結合
week = pd.DataFrame([[0,"月"],[1,"火"],[2,"水"]],columns=["WEEKDAY","曜日"])
df = pd.merge(df, week, on="WEEKDAY", how="left")
SQLでいうところのLEFT JOIN.
on: 2つのデータフレームで比較する列
how: 結合方法. left, right, inner, outer
2つの表の列名が違うものをキーに結合したい場合は, left_on=, right_on=を代わりに使う.
csvで保存
df.to_csv("__result__.csv",index=False)
jsonで保存
df.to_json("__result__.json")
jsonロード
df = pd.read_json('__result__.json')
# 表形式で表現できない場合のjsonのロード
f = open('__result__.json', 'r', encoding="utf-8")
dic = json.loads(f.read())
f.close()
jsonファイルもpandasでロード可能.
表形式で表現できない場合, json.loadsを使う.
縦形式へ変換
df=df.melt(id_vars=["NAME", "AGE"], value_vars=["xx","yy"], var_name="xx or yy", value_name="square")
ロングフォーマットへ変換できる.
横形式へ変換
df=df.pivot(index='NAME', columns='xx or yy', values=['square'])