Watsonから少し浮気して、今回はMicrosoft Custom Vision
普段はWatson関係の仕事や登壇が多くて、2年ほど前、IBM Watson関係の勉強会で「Watson Visual Recognitionを使って寿司ネタを判定してみた」ってのを作って何度か登壇時のネタに使ってました。(ネタセッションだけに「寿司ネタ」っていう発想)
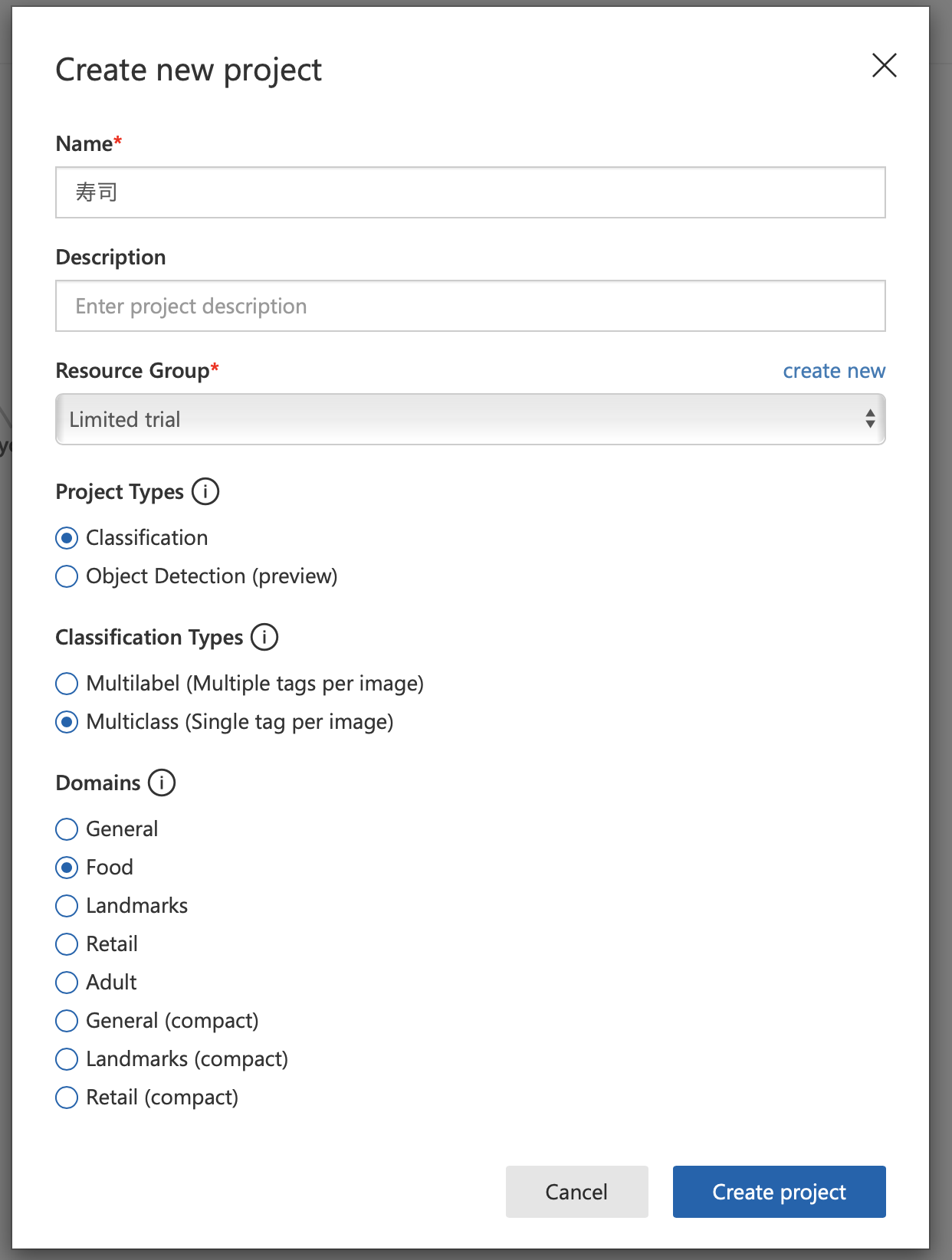
その後各社が独自の画像認識モデルを作れるサービスを相次いでリリース。Microsoftさんもすっかりベータも取れてCustom Visionがいい感じに使えるというので、全く同じ学習データでモデルを作成してみました。
環境準備
うーん、ここ書くのめんどくさいですよね。Microsoft Azureのアカウント作った上で、https://azure.microsoft.com/ja-jp/services/cognitive-services/custom-vision-service/ から「はじめる」ってやるだけです。それだけ。
Custom Vision Serviceの特徴
Watsonと比べた場合の感想になります。
- プロジェクト名・クラス名に日本語が使えるのが嬉しい
- プレビューだけど物体認識モデルも作れる
- マルチラベル(例えば、「寿司」でかつ「中トロ」など)と、マルチクラス(いわゆる分類機)が選べる
- 強化学習であるので、元のモデルのドメインを選べる
- ちゃんと学習結果の精度を数字で出してくれる。
この辺りが嬉しいなー。
必要な画像枚数もWatson Visual Recognitionと同様に少なく、今回は16−7枚ずつ入れました。Watsonの時と同じです。
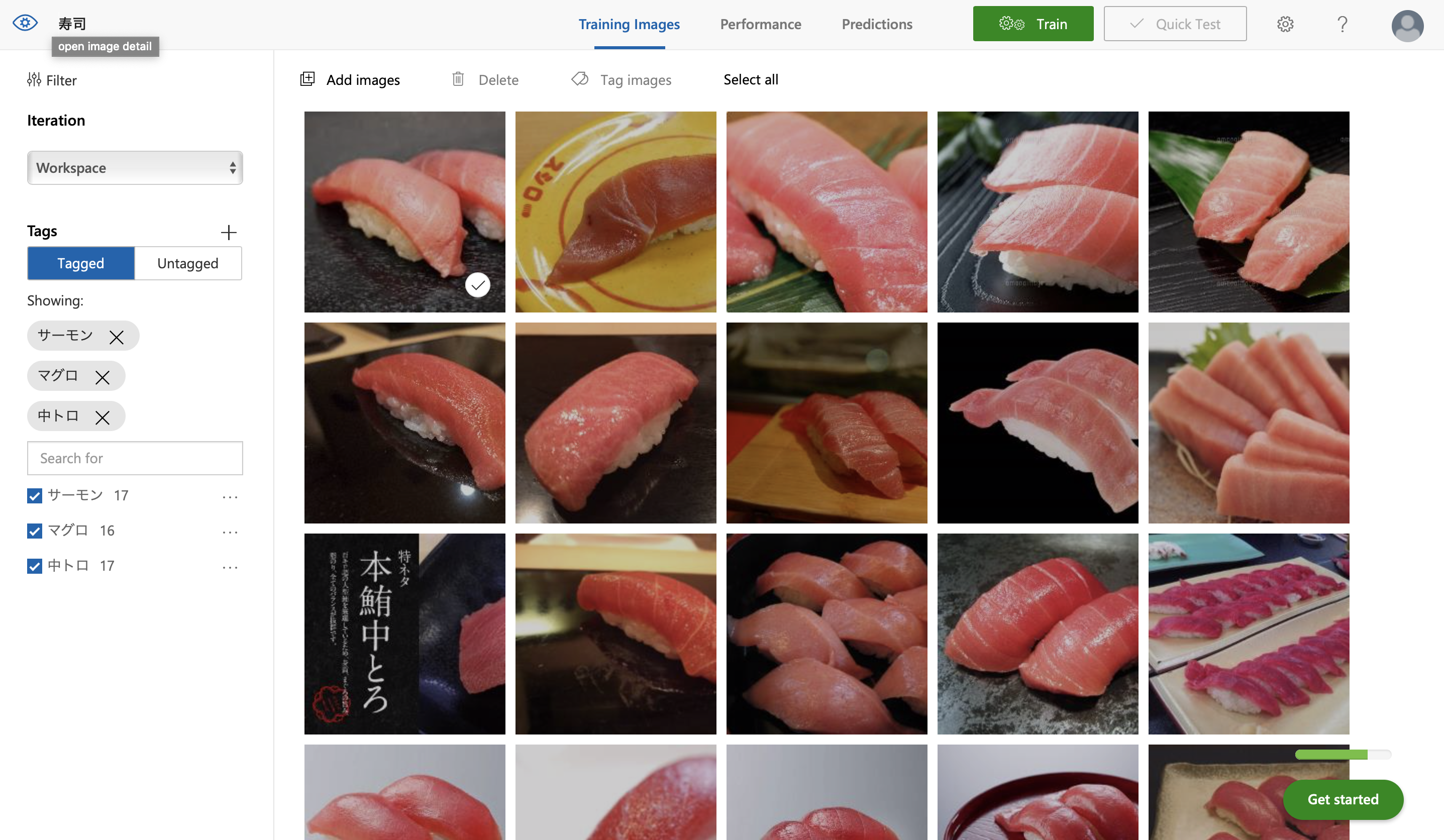
学習データ
今回はWeb検索で出てきたお寿司の画像を放り込みました。ちょっと個人的には炎上案件だったので、「とろ」と「サーモン」を学習させました。枚数は16−7枚。手元にあった2年前の画像です。決して執筆時点で話題になってる人のことじゃありません。
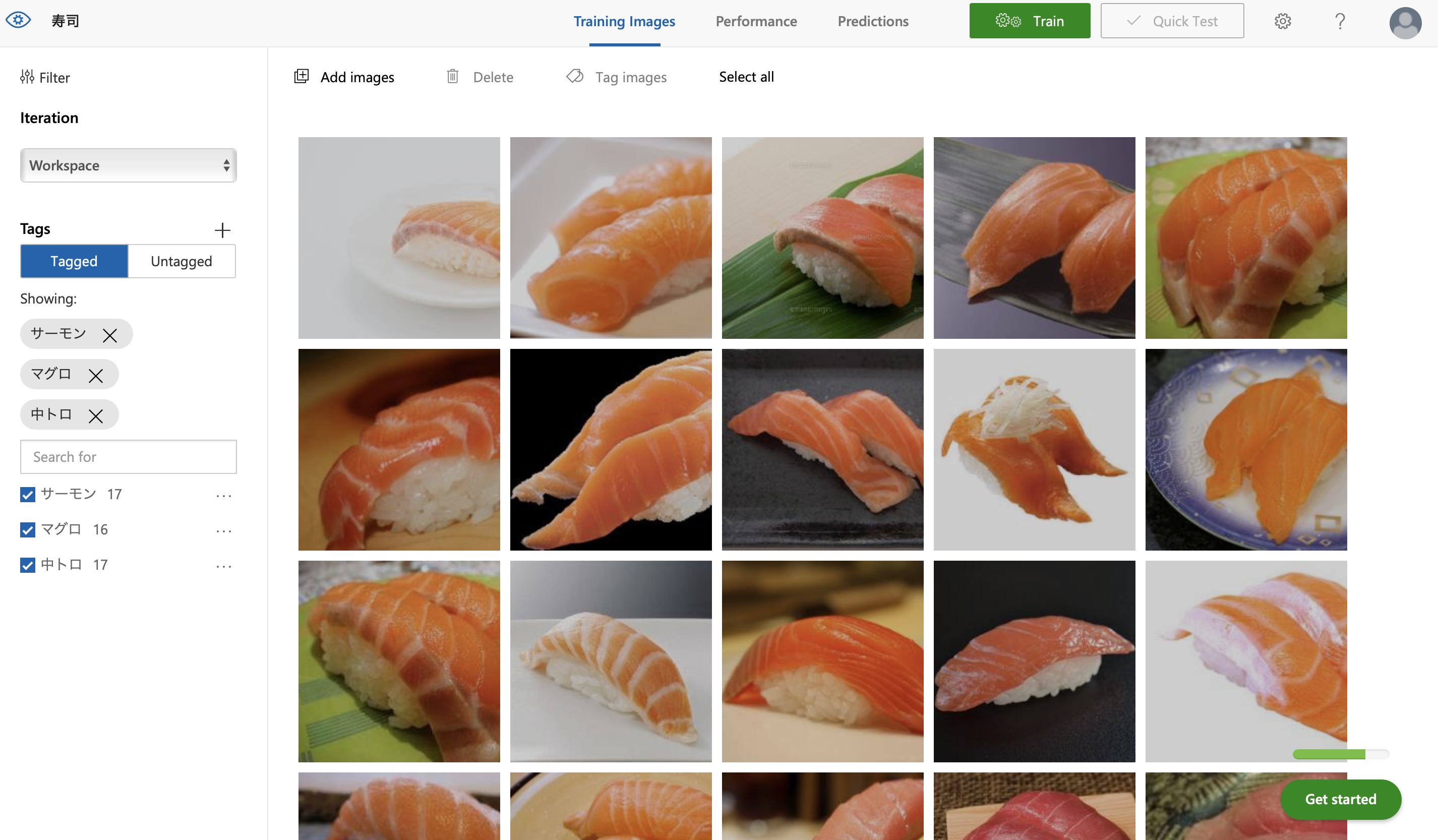
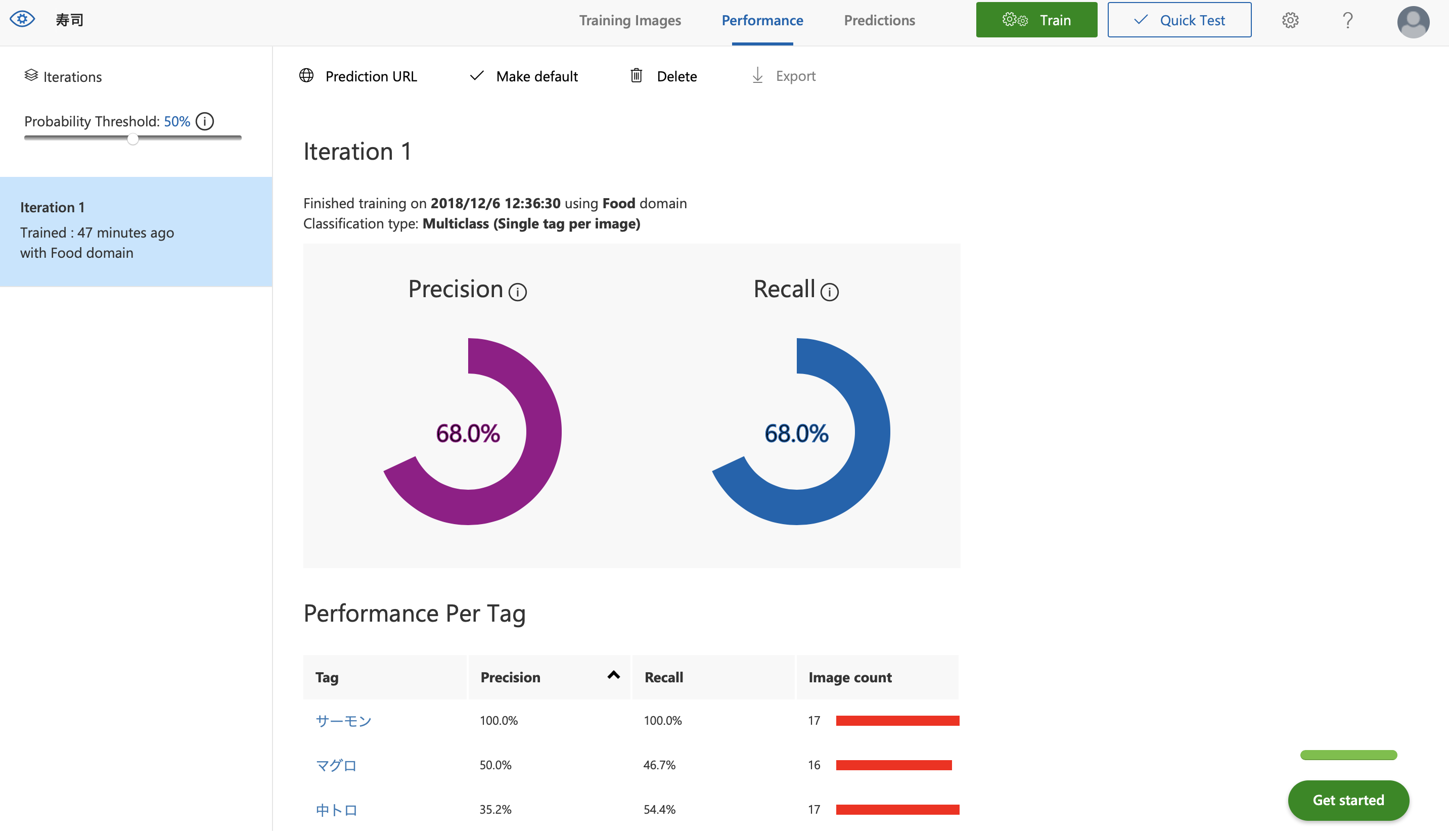
学習時間速い!!ちゃんと精度表示される
何より学習が早い!「Train」と押したらすぐできちゃった。
そして前述の通り、認識率がちゃんと数字で出てくるのがえらい、、、いや、それ普通だろうよ。うん。
今回枚数も少ないため非常に精度が低い感じになってますが、「やってみた」なのでOKとします。
テストしてみる
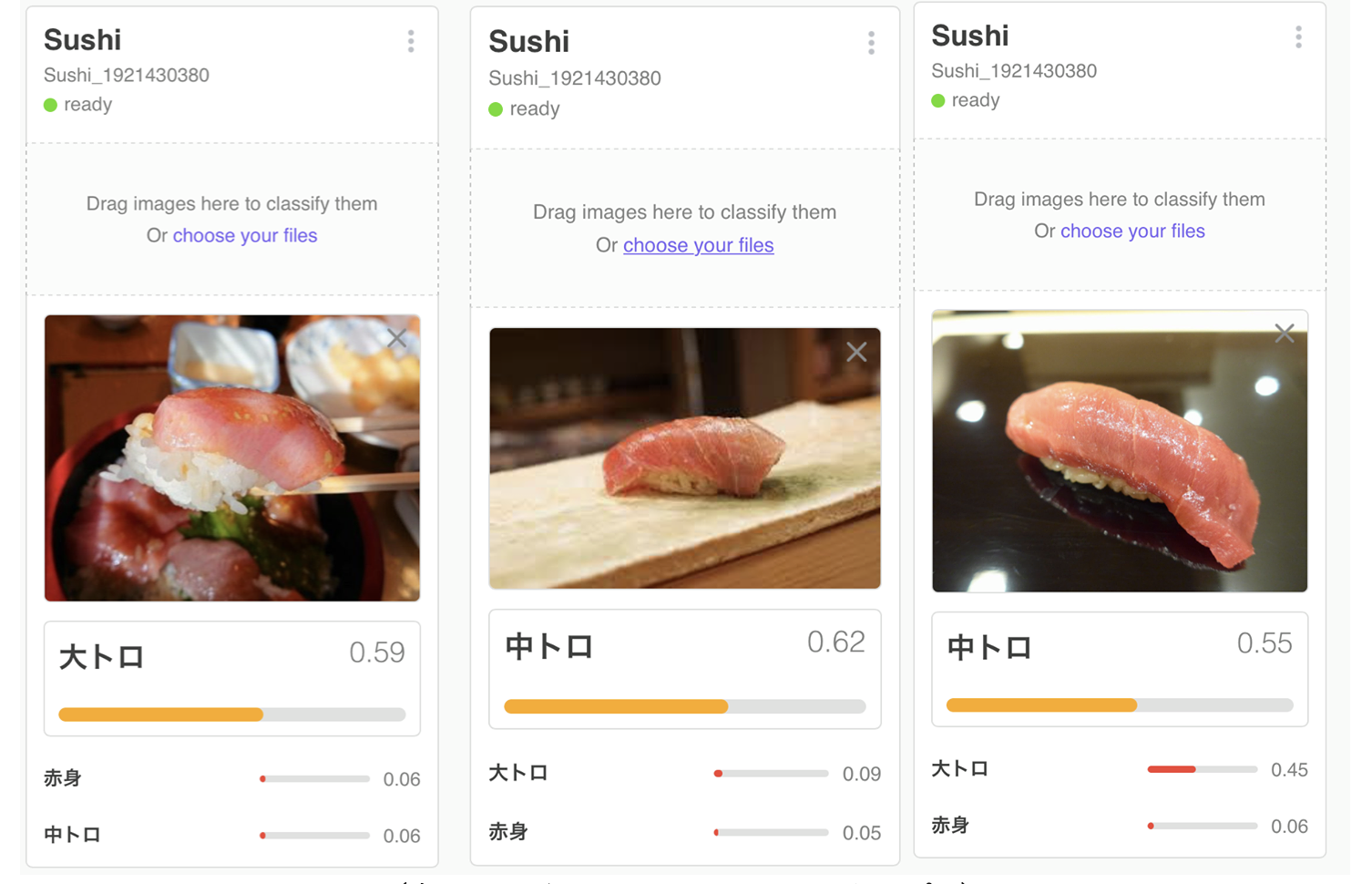
Webの画像では学習データに入ってるかもしれないので、別件セミナーの登壇前に回転寿司のお店に入ってネタ写真を撮ってきたので、それでテストしてみます。ちなみに、回転寿司と書いてあるのに、ネタの名前が書いてあるふだが回っているだけのシュールなお店でした。

結果!
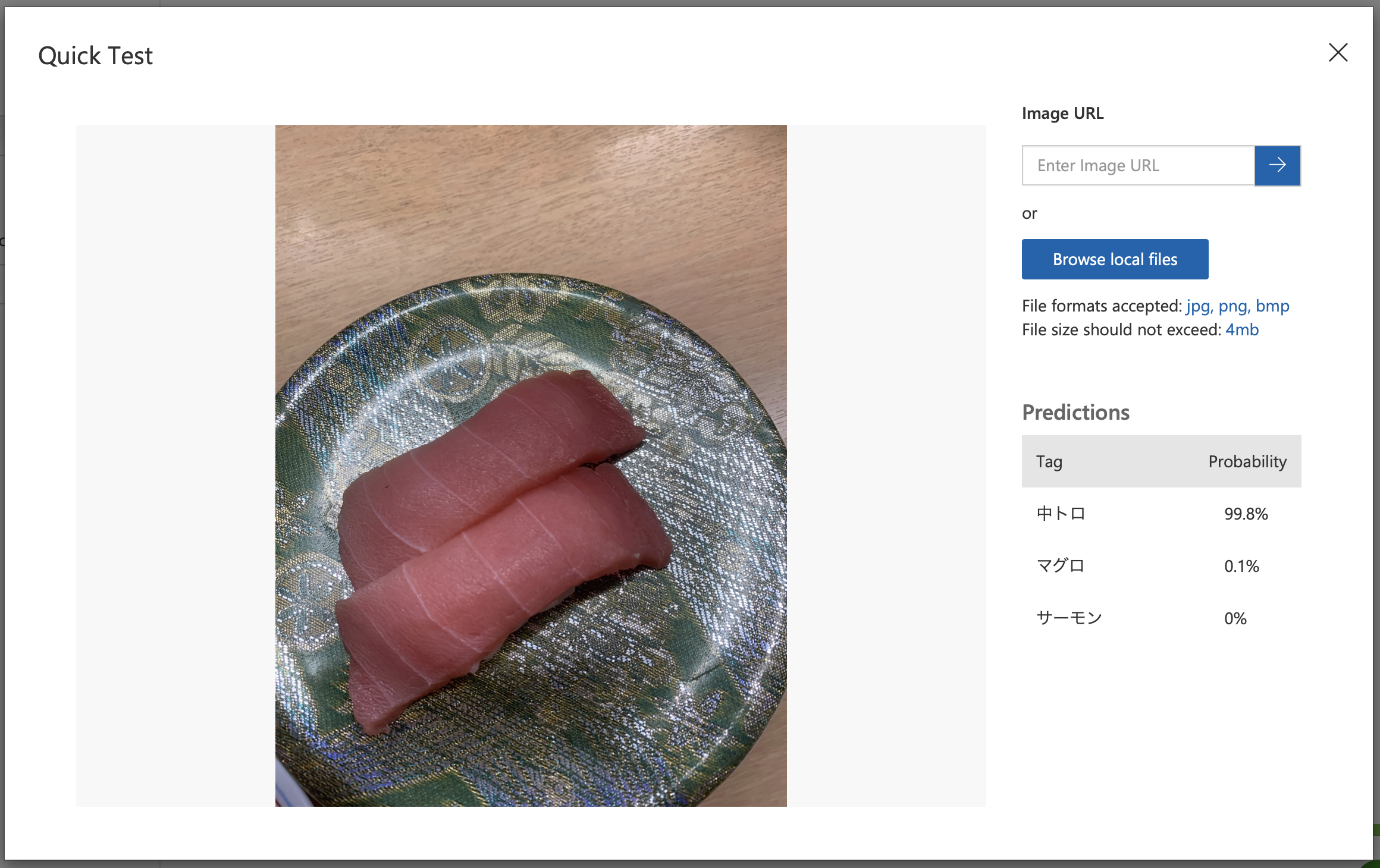

おー、トロ サーモン 共にちゃんと認識してくれています。Webの画像は横から撮った写真が多いのですが、実際寿司屋で写真を撮ると上からでほぼネタしか見えないことになるので、注意が必要です。
iOS Core MLへのエクスポート
最近のこの手のサービスはCoreMLへのエクスポートというビジネスモデルぶっ壊し兼ねない機能を備えているのですが、どうやら、ベースモデルのドメイン選択で「compact」となっているものしかエクスポートできないそうです。ということで、「General(compact)」を選択し直して再度学習してみました。
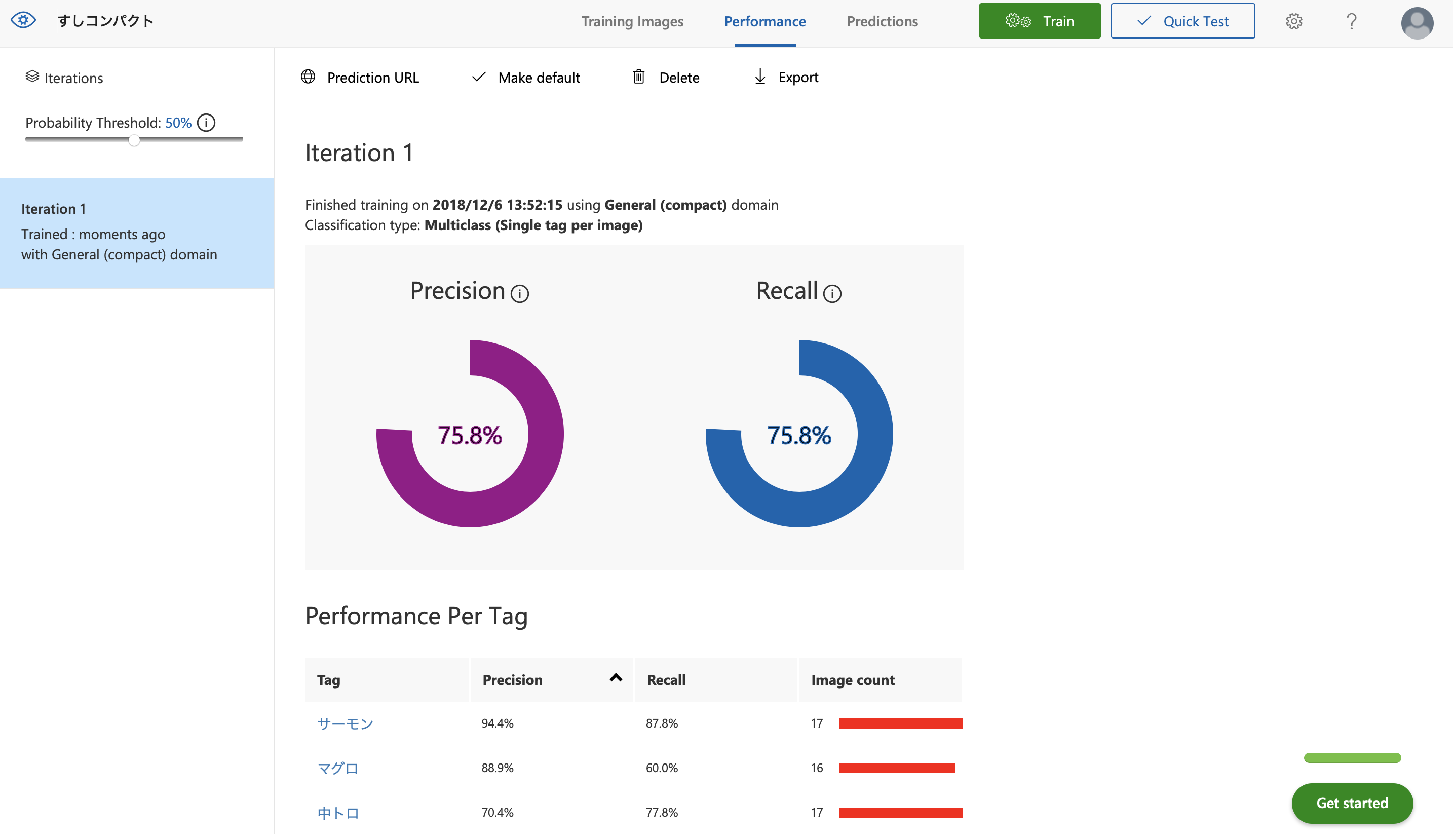 少しだけ精度が上がってる。なんで?
少しだけ精度が上がってる。なんで?
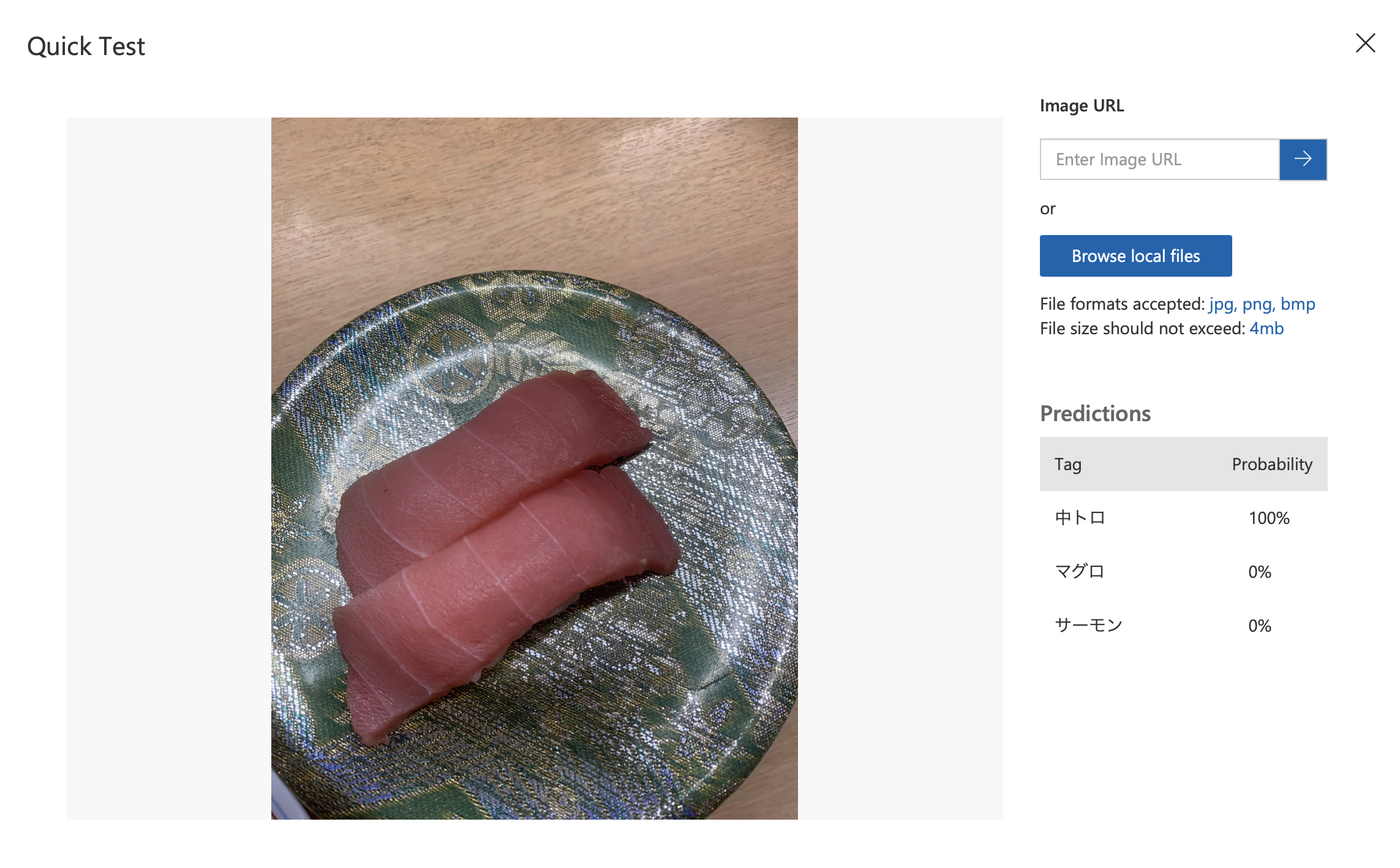
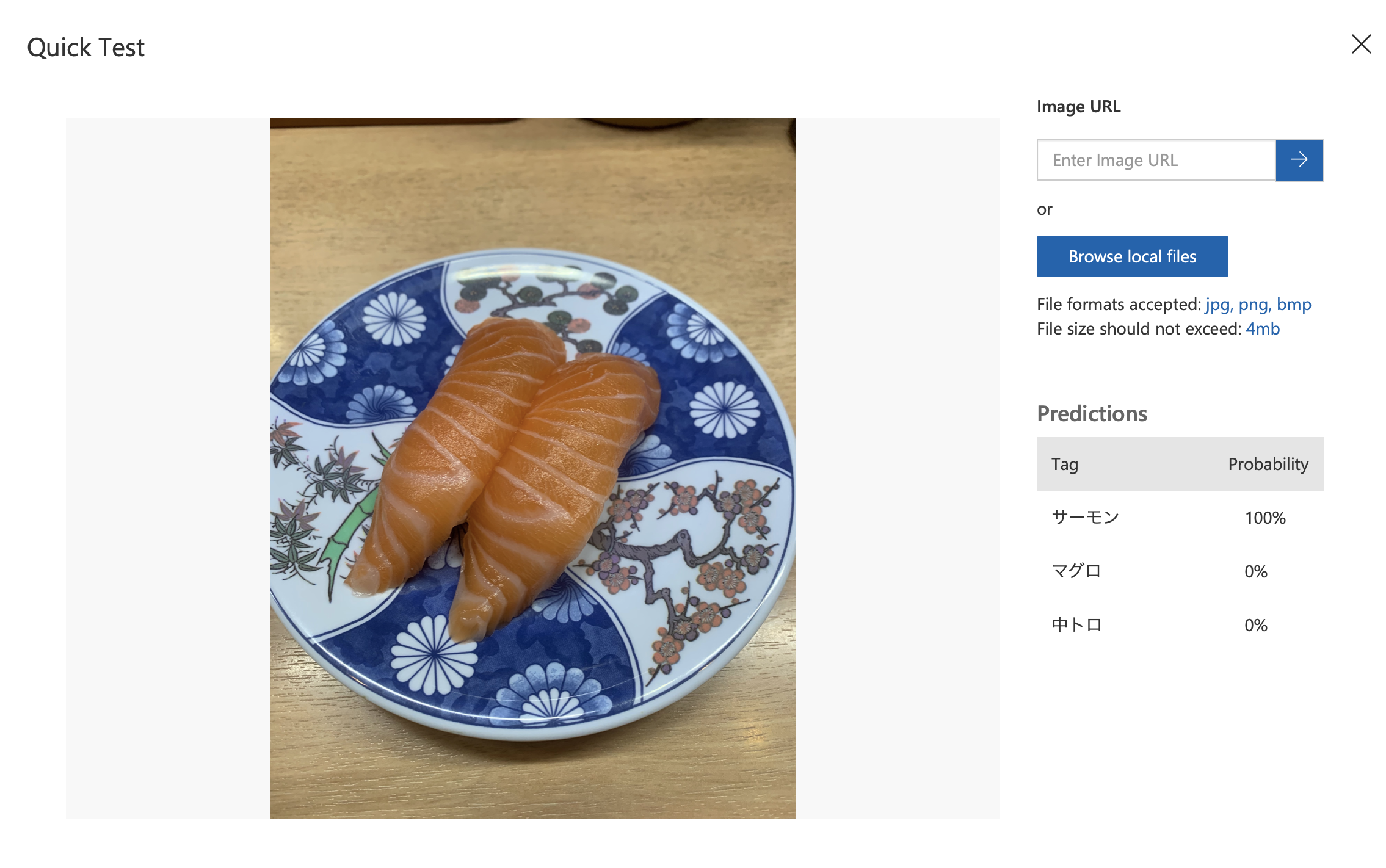 結果はやはり良好。
結果はやはり良好。
Exportを選ぶと、CoreML以外にも、TensorFlowのモデルやONNXフォーマット(といってもこれはWindows ML用かな?)あとDockerのイメージができるのでそのまま環境が作れます。

感想
Microsoft さんのサービスはいい感じに仕上がってて、なんか画像認識案件があったら使ってみたいなー。あと物体認識はこのあと試してみたいなーと思います。