修士の頃にやってた研究に関する論文を先週投稿しました。この記事ではそれに関して簡単にまとめます。
論文とコード
追記:Knowledge-Based Systemsに採択されました、パチパチ。
TL;DR
- テーブルデータの特徴量とGumbel-Softmaxから得た重みとの内積で各画素値を計算
- CNNにぶっ込む
- 予測誤差に加えてテンプレ画像との二乗誤差も取り勾配法でEnd-to-End学習
- XAI手法によって重要な特徴量をわかりやすく可視化する
背景
テーブルデータ×深層学習って、結構研究されてますよね。調べるといろいろ出てきますね。TabNetとか、Transformer使ったやつとか。サーベイ論文もあります。私は半年前まで大学院生だったのですが、M2の夏くらいからはここら辺を調べてました。それで、テーブルデータの画像化×CNNに絞った文脈で調べると、既存手法はどれもテーブルデータの画像化とCNNの学習を別々で行っていました。また、特にモデルの説明性に関する議論もなされていませんでした。そこで私は、テーブルデータの画像化とCNNの学習を一気に行うEnd-to-Endモデルを提案すること&モデルの説明性に着目しました。

手法
超シンプルです。論文のFigure3が全てです。各画素の値を、特徴量ベクトルとアテンションの重みベクトルとの内積で表してCNNに入れるだけです。超シンプル。
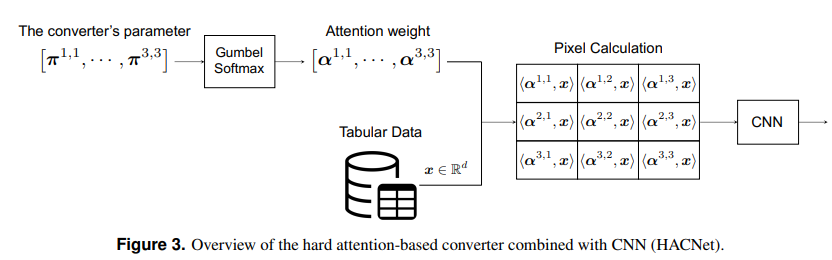
んで、それでもいんですが、アテンションの重みをワンホットにします。ワンホットにしたい理由は、特徴選択の組み込み&説明性の向上です。ワンホットにするために、Gumbel-Softmaxを用います。Gumbel-Softmaxについては、私が書いためちゃくちゃわかりやすいこの記事を参照してください。
画像を作成後、CNNにいれます。予測誤差を計算します。それに加えて、クラスごとに用意したテンプレ画像と作成された画像の二乗誤差を計算します。以下のようなイメージです。正解ラベルがクラス1のデータに対しては、人間が予め用意したアルファベットAとの二乗誤差を取るイメージです。正則化係数をλ、loss=予測誤差+λ×二乗誤差として、アテンションの重みを決めるパラメータ$\pi$とCNNのパラメータを勾配法で同時に学習します。

結果
精度
精度に関しては、まあ、既存の手法(テーブルデータの画像化&CNN)よりは良いよねって感じです。最先端のモデルとか、そもそも勾配木と比べるとどうなのかといえば、多分負けるでしょうね👍

説明性(ここで言う説明性は、専門家の方は違和感を覚えるかもしれません)
出来上がった画像の例は以下です。かわいいですね。

このモデルのポイントは、テーブルデータを画像化しているということです。つまり、画像認識系のXAI手法使えます。クラス1~5それぞれをアルファベットA~Eと対応させていたので、もしモデルがAに近い画像を作った場合、予測はクラス1に近いはずです。Figure2の一番左の画像Aに対して、Integrated Gradientsをあててみましょう。Integrated Gradientsの説明は、これが良いですね。
例えば、こんな結果が得られます。

クラス1に関する重要な特徴量はここに乗っているでしょう。きっと、きっとね。
院生のころ、Vue.jsでなんちゃってWebアプリを作ったりもしました。できた画像をVAEで潜在空間に落として、「あなたの健康状態がどの程度悪くなったか」なんてのを可視化できます。
まとめ
- テーブルデータを画像化し、CNNを学習するEnd-to-Endのモデルを提案しました。
- 予測誤差に加えて、テンプレート画像との二乗誤差も加えてみました。
- 画像認識系のXAI手法使って、可視化してみました。
今後の展望として、例えば、マウスカーソルを画像のある画素にあてると、その特徴量が何かをポップアップするとかすると、良いのではないでしょうか。
この記事では書きませんでしたが、論文には特徴選択に関する考察もあるのでぜひ!
2年間、大した成果は出なかったし、これが何に役に立つかわかりませんが、先行研究を調べ、新しいことを提案・実験・考察し、なんちゃって論文を書き、それを発信することで研究の領域をどのベクトルでもよいので広げるという体験ができました。指導教員の白川先生、そして研究室のメンバーに厚く御礼申し上げます、ありがとうございます!