はじめに
スケーリングポリシーの挙動を手っ取り早く確認する方法として、擬似的なメトリクスを使う方法を紹介します。
経緯
動的スケーリングに関するドキュメントを一通り読んだので、実際にどのような挙動になるのかをマネージドサービス上で確かめてみたいと思いました。しかし、アプリケーションの特性上、検証環境で本番環境と同等の負荷状況を再現するのが難しい状態でした。
そこで、CloudWatch のカスタムメトリクスに本番環境のメトリクスと同等の時系列データを投稿することで、本番環境の様子を擬似的に再現してみる方法を試してみました。
手順
ステップ1: 疑似メトリクスの取得
本番環境のメトリクスの時系列を aws-cli で取得し、テキストファイルに変換します。
この例では、カスタムメトリクス: SidekiqTotalBusyProcessPercentage の値を期間 2019-07-21T12:00:00 〜 2019-07-21T14:00:00 にわたって 60 秒ごとの平均値を取得しています。
パラメータの指定方法は参考資料 [1] 参照。
$ aws cloudwatch get-metric-statistics \
--profile production \
--namespace Dummy \
--metric-name DummyMetrics \
--start-time 2019-07-21T12:00:00 \
--end-time 2019-07-21T14:00:00 \
--period 60 \
--statistics Average \
--dimensions Name="Service",Value="Sidekiq" Name="Stage",Value="prd" \
| jq -r '.Datapoints[] | [ .Timestamp ,.Average ,.Unit] | @csv' \
| sort -t ',' -k 1 \
| awk -F, '{print $2}' \
> metrics.dat
$ head -3 metrics.dat
10.5
20
34
ステップ2: 検証環境の構築
参考資料 [2], [3] を参考にして、検証環境を構築します。
- オートスケーリンググループの作成
- スケーリングポリシーのアタッチ
今回、ポリシータイプは TargetTrackingScaling を指定しました。
{
"TargetValue": 90.0,
"CustomizedMetricSpecification":
{
"MetricName": "DummyMetrics",
"Namespace": "Dummy",
"Statistic": "Average",
"Unit": "Percent"
}
}
TargetTrackingScaling ポリシーを作成すると、それぞれスケールアウトとスケールインのトリガとなる CloudWatch アラーム自動的に作成されます。
$ aws autoscaling put-scaling-policy --policy-name dummy40-target-tracking-scaling-policy \
--auto-scaling-group-name sidekiq-autoscale-test --policy-type TargetTrackingScaling \
--target-tracking-configuration file://config.json \
--estimated-instance-warmup 60 \
--profile test
{
"PolicyARN": "arn:...",
"Alarms": [
{
"AlarmName": "TargetTracking-sidekiq-autoscale-test-AlarmHigh-...",
"AlarmARN": "arn..."
},
{
"AlarmName": "TargetTracking-sidekiq-autoscale-test-AlarmLow-...",
"AlarmARN": "arn..."
}
]
}
ステップ2: 疑似メトリクスを検証環境に投稿する
以下のようなシェルスクリプトを用意し、ステップ1で取得したメトリクスを 60秒間隔で検証環境 に投稿します。
#!/bin/bash
AWS_PROFILE=test
SLEEP_SECOND=60
DATA_FILE=${1:-metrics.dat}
if [ ! -e $DATA_FILE ]; then
echo "No datafile $DATA_FILE exists."
exit 1
fi
function gen_current_timestamp() {
TIMESTAMP=$(env TZ=UTC date '+%Y-%m-%dT%H:%M:%S')
echo -n $TIMESTAMP
}
function send_metrics() {
timestamp=$1
value=$2
aws cloudwatch put-metric-data \
--profile ${AWS_PROFILE} \
--namespace Dummy \
--metric-data MetricName="DummyMetrics",Timestamp="${timestamp}",Value=${value},Unit="Percent"
}
function main() {
for value in $(cat $DATA_FILE); do
timestamp=`gen_current_timestamp`
echo "send metrics at $timestamp: $value"
send_metrics $timestamp $value
sleep $SLEEP_SECOND
done
}
main
$ chmod +x put_metrics.sh
$ ./put_metrics.sh metrics.dat
send metrics at 2019-07-25T14:58:06: 10.5
...
ステップ4: AutoScalingGroup のインスタンス数の変化を確認する
メトリクスの時系列
CloudWatch Metrics のコンソールからスケーリングポリシーにしたがってインスタンス数が変動する挙動を確認できます。

インスタンス数の時系列

注意すること
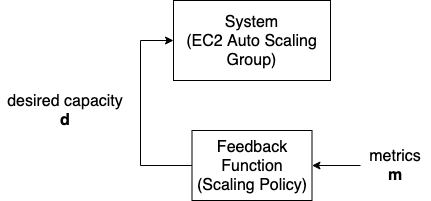
ここで紹介している方法は、あくまで「擬似的なメトリクスの時系列」をスケーリングポリシーの一方的に入力として与えているだけです。
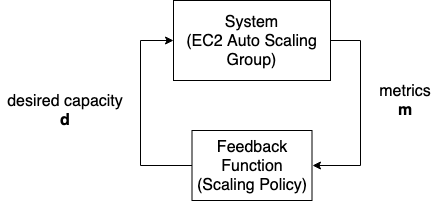
実際のシステムの状態をもとに計測したメトリクスに基づいてスケーリングする場合は、インスタンス数の増減にともなってメトリクスの時系列が変化します(いわゆる、制御工学における「フィードバックループ」)。このシミュレーションではこの効果を考慮していないことに注意してください。
参考: 制御系としての違い
AutoScaling Group を制御系とみたときの回路図
今回のシミュレーションの回路図
まとめ
- 擬似的なメトリクスに基づいてスケーリングさせることで、スケーリングポリシーの大まかな挙動を確認できる
- この方法は、インスタンス数の増減によるトリクスの時系列への影響は考慮していないことに注意
参考資料
- https://docs.aws.amazon.com/cli/latest/reference/cloudwatch/get-metric-statistics.html
- https://docs.aws.amazon.com/ja_jp/autoscaling/ec2/userguide/as-scaling-target-tracking.html
- https://docs.aws.amazon.com/ja_jp/autoscaling/ec2/userguide/as-scaling-simple-step.html
- http://htnosm.hatenablog.com/entry/2015/09/23/090000 - CloudWatchメトリクスの取得と集計方法を参考にさせていただきました。