概要
2017/12~2018/01にかわいいフリー素材集 いらすとやの専用検索サービスを作っていました。
完成後、いらすとやの中の人とコンタクトを取り許可をいただけたのでいらすとや検索(公認ファンサイト)として先日公開しています。
この記事の目的
- AWSは従量課金なので使うときは料金が爆発しないか不安だけど、構成次第ではVPS 1つ借りるよりよほど安いよと伝えたい
- 既存サイトのデータを継続的にcrawlingして提供するサービスの典型例として共有
- せっかくサービス作ったのでもっとみんなに使ってほしい・・・
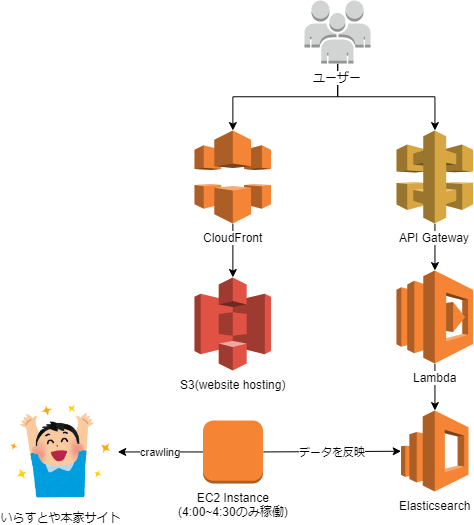
システム構成図
運用コスト
月約4,000円程度。実際には90%がElasticsearch Service(ES)のためのEC2インスタンスで、それ以外は400円と激安。

技術スタック
使った技術を書き出しました。詳細は僕が説明するよりそれぞれの記事や解説を見たほうが良いと思います。
しかし、書き出していてこれ全部一人で理解・把握しないといけない現代のwebエンジニアは大変だなと思いました。
- AWS系
- EC2
- CloudFront
- S3(website hosting)
- API Gateway
- Lambda
- Amazon Elasticsearch
- CloudFormation(およびSAM)
- Route53
- 開発系
- クライアント
- JavaScript(ECMAScript 2015)
- webpack
- vue.js
- vue-router
- bootstrap
- babel
- サーバサイド
- lambda + API gateway
- terraform(後に不要とわかりCloudFormationへ置き換え)
- Python 3.6
- sam-local
- クロウラー
- python3.6
- scrapy
- requests
- クライアント
構成の理由と補足
- Client(ブラウザ)からElasticsearchへ直接クエリを投げたかったのだが、Elasticsearchは普通に公開するとWriteなREST APIもフルオープンになってしまうのでAPI gatewayとLambdaで泣く泣くsearchだけできるようにフィルタ
- Elasticsearchは2018年現在代替が存在しない、検索エンジンとしては僕が知る限りベストプロダクトなのでコストは高いが採用
- サーバサイドでスクリプティングをしていないため、vue.jsとvue-routerを使ったjavascriptコードはS3 website hostingで完結して提供できる。これでサーバサイドでEC2 Webサーバを使う必要がなくなりその部分のコストが100円以下に
- 検索データは本家サイト様をcrawlingして収集。ただし一度集めたあとは差分のみ参照するようにしているので、1日に1度 追加された素材のページ+3リクエストのみの負荷しか与えていない
- crawlingはpythonのscrapyがベストソリューションだった。本当はlambdaでやれればよかったが5分で終わらないため、1日の決まった時間帯のみインスタンスを立ち上げcronでcrawlingを実行してElasticsearchへ反映、後に自動終了するようにしている
- この部分はFargateやAWS Batchでもっとスマートにできれば最高
- crawlingに使えるライブラリは最初Rubyで使えるものの中から選択してコードを書いていたが保守状態が良くなく機能も貧弱でバグが多かった。思い切ってcrawlerとして評判の高いpythonのscrapyにしたが思った以上によく、言語変更しただけの甲斐があった。最終的に自分の書いたコードは50行以下になった。
- apacheやnginxのようなリッチウェブサーバが使えない以上vue-routerのサーバサイドスクリプティングはできない。なのでSEO的にはちょっと減点されるらしいが、コストパフォーマンス優先ゆえ一旦妥協