今回は、前回の記事で圧縮したデータを解凍するアルゴリズムについて解説して行きます。
前回の記事:javascriptで連長圧縮してみた。
“連長圧縮”という圧縮処理を経た文字列を、解答していくわけですが、前回同様に、
はじめに例をお見せします。
まずは例から。。。
自作のローカルページに「3A5B-2CD2E-2FG」と入力すると、前回の記事で圧縮処理をかけた「AAABBBBBCDEEFG」というオリジナルの文字列が表示されます。
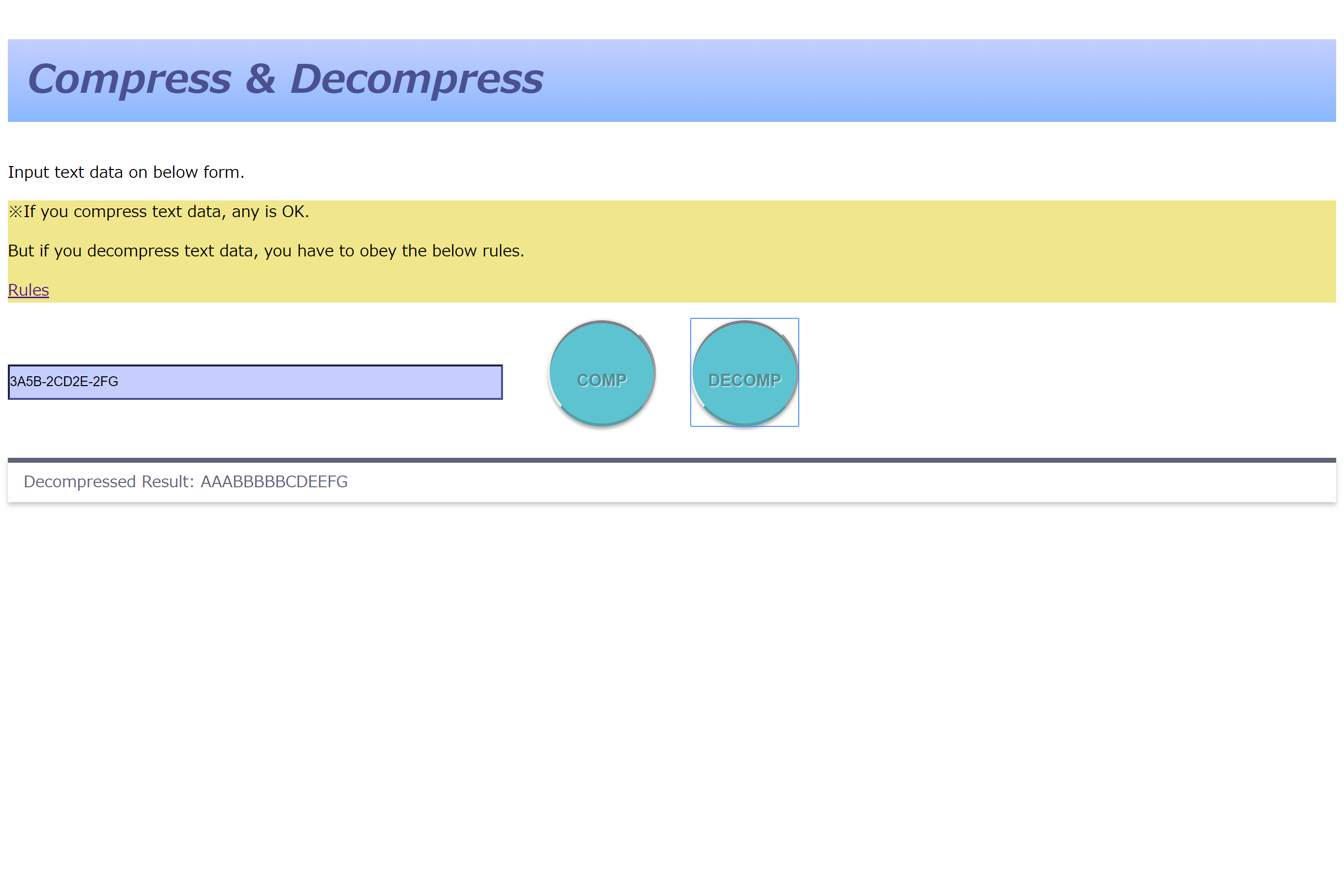
正の数字は連続の文字の回数を表しているので、その回数分、文字を連続して出力します。
(ex. 3A → AAA(解凍)となるわけです!)
負の数字は不連続文字の数を表しており、その回数分、不連続の文字を続けて出力します。
(ex. -5CDEFG → CDEFG(解凍)となり、解凍後の方が情報量が少ないですね...笑)
やはり、「連続する文字が多い」という特性を持った情報でないと、効果を発揮する場面が無さそうですね。
解凍のアルゴリズム(JavaScript)
function doDecompress(charData){ //連長圧縮に対する復号処理
var decompressedText = []; //解凍結果を格納する場所
var minusFlag = false; //連続か不連続かの状態を決定する
var countStock = 0; //文字の数を数えるようの変数
var preNumStock = []; //前回までの文字のストック(2桁以上に対応)
for(i=0;i<charData.length;i++){
if(charData[i]=="-"){ //マイナスの符号を検知
minusFlag = true;
}
else if(charData[i].match(/[a-z]/gi)){ //アルファベットを検知
if(minusFlag==true){ //不連続だったら
countStock = parseInt(preNumStock.join(""));
for(j=0;j<countStock;j++){
decompressedText.push(charData[i+j]); //不連続の文字の回数出力
}
i = i + countStock - 1; //ループを次の状態まで飛ばす
minusFlag = false; //諸々初期化しとく
preNumStock = [];
countStock = 0;
}else{ //連続だったら
countStock = parseInt(preNumStock.join(""));
for(j=0;j<countStock;j++){
decompressedText.push(charData[i]); //連続の回数分、同じ文字を出力
}
preNumStock = []; //諸々初期化しとく
countStock = 0;
}
}else{ //数字だったら
countStock = parseInt(charData[i]); //int型に変換
preNumStock.push(countStock); //2桁以上の場合に備えて保持しておく
}
}
var resultText = decompressedText.join(""); //配列を文字列に変換
document.getElementById("show_result").textContent = "Decompressed Result: " + resultText;
}
注意すること
デコーダーにおいて一番私が躓いたのは、1文字ずつ調べるが故に、普通にやってたら2桁以上の数字に対応できない!という点でした。笑
そのためpreNumStockという配列を用意し、数字をどんどん貯め、アルファベットが始まった段階で初期化して2桁以上に対応しました。
真価を発揮するとき。。。
連長圧縮は、2進数のように情報の種類がAとBの2種類しかない場合に、かなり圧縮率を高く出来ます! → かつ1種類の文字が長く連続している場合には、圧縮率が高くなります。
またランレングス圧縮は白黒(情報の種類が2つのみ)のファクシミリの情報を読み取る際などに用いられているようです。
「ABBBBABABAAAAAA」という文字列があるとしましょう。最初にAが来ることを前提とすると、
「-1,4,-4,6」というふうに数字だけで表せます。
このように数字からなる情報だけで、オリジナルの文字列を解読出来ちゃいますね!
最初の文字がAかBかを決定するだけで、あとは数字のみで表せてしまうのです。(デコード出来る圧縮を可逆圧縮というそうです。)