目次
1.はじめに
2.参照論文
3.要約
4.論文内容
5.最後に
1. はじめに
こんにちは、LLM Advent Calendar 2023 12日目の記事を担当するtiger_bigriverです。
先日、ChatGPTがリリースされてから1周年が経ち、この1年で本当に様々なことがあったと思います。
このタイミングで、オープンソースLLMがChatGPTにどこまで追いついているのかを確認できる論文をご紹介します。
論文の内容と合わせて、私の方でも調べた情報を追記した記事となります。
2. 参照論文
『ChatGPT's One-year Anniversary: Are Open-Source Large Language Models Catching up?』
URL:https://arxiv.org/abs/2311.16989
3. 要約
ChatGPTは2022年末にリリースされ、AI業界に大きな変革をもたらした。人間のフィードバックに基づく学習により、幅広いタスクに対応可能な大規模言語モデル(LLM)を実現し、これにより学界と産業界でのLLMへの関心が高まった。
クローズドソースのLLM(例:OpenAIのGPT、AnthropicのClaude)が一般に優れているが、オープンソースのLLMも特定のタスクで同等かそれ以上の成果を示しており、これは研究とビジネスの両面で重要な意味を持つ。この研究はChatGPTの成功を詳細に概観し、オープンソースLLMの成果を検証している。
4. 論文内容
4-1. ChatGPTの成功と影響
2022年11月30日にChatGPT3.5がリリースされ、 わずか1週間で100万ユーザーに達した。2023年1月には1億人のアクティブユーザー数を記録している。
ChatGPTの成長は「TikTok」や「Instagram」よりもはるかに速い。TikTokとInstagramがアクティブユーザー数1億人に到達するのに要した時間は、それぞれ9カ月と2年半である。
ChatGPT on track to surpass 100 million users faster than TikTok or Instagram: UBS
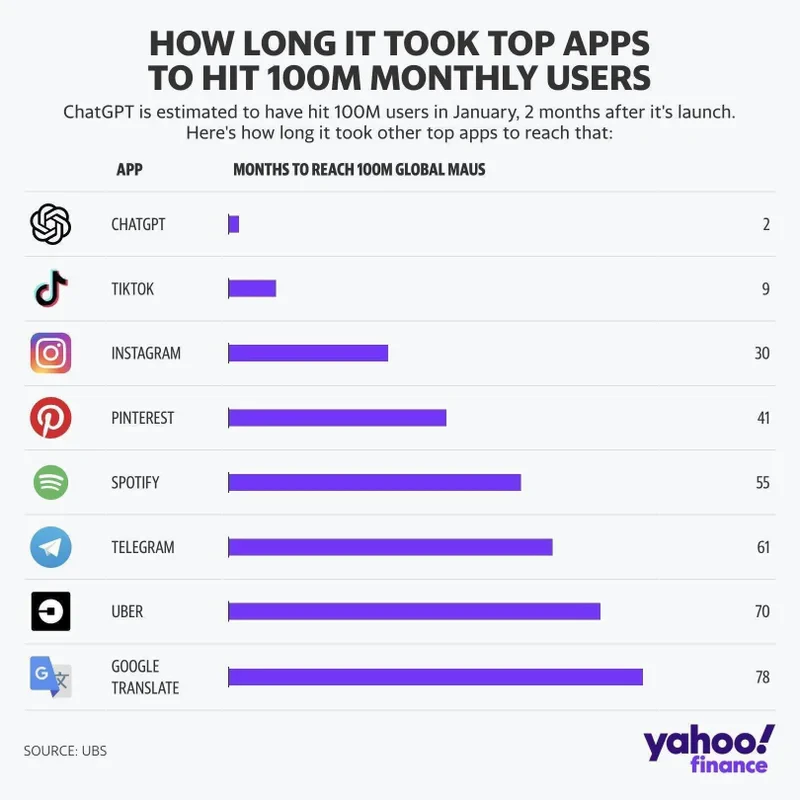
しかし、ChatGPTはオープンソースではなく、その技術的詳細はほとんど知られていない。そのため、社会的リスクの評価が困難であり、性能の変動やサービスの中断などの問題も指摘されている。
合わせて読みたい記事
オープンAIのCEO解任に関する騒動について
4-2. オープンソースモデルの発展
オープンソースLLMはこれらの問題を解決する可能性があり、近年はその性能差が縮まっているが、依然としてクローズドソースLLMに遅れをとっている。
現時点では、オープンソースLLMのLlama-2やFalconが、OpenAIのGPT3.5(ChatGPT)、GPT-4、AnthropicのClaude2、GoogleのBard3などのクローズドソースLLMに比べて遅れをとっているが、その差は少しずつ埋まっていっている。
実際に、オープンソースLLMは、すでに一部の標準ベンチマークでGPT-3.5-turboよりも優れたパフォーマンスを発揮している。
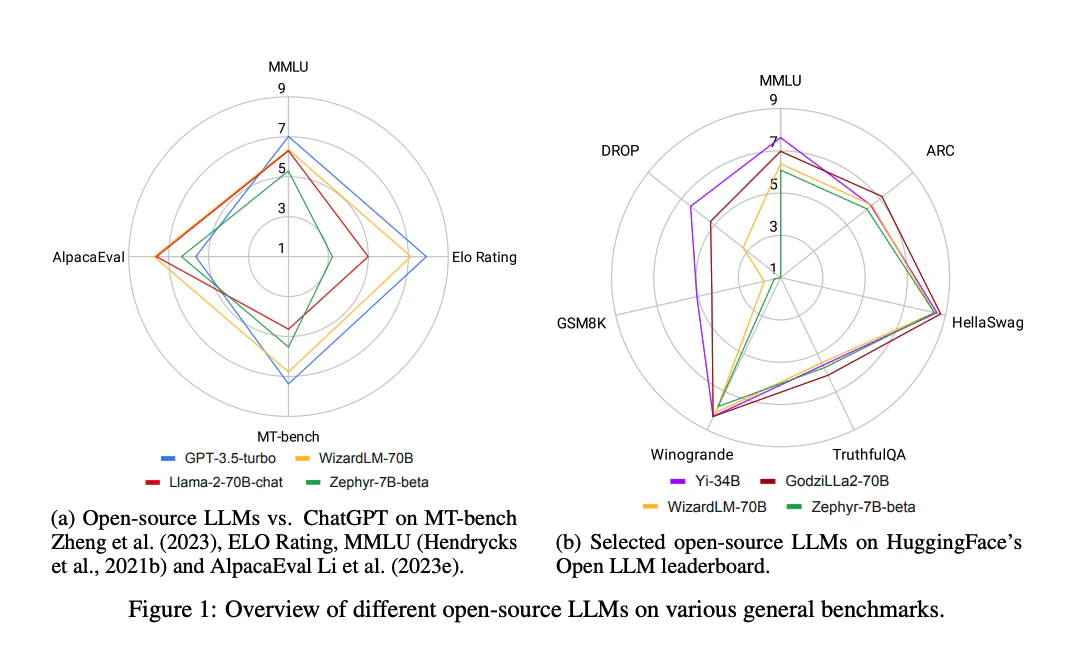
調査対象になったオープンソースLLM。
青いボックスは特定のデータセット、オレンジのボックスはオープンソースLLMを示す。
LLMの開発タイムライン。下側がクローズドソースLLMで、上側がオープンソースLLM。

4-3. LLMのトレーニング手法と評価分野について
LLMはインターネットのテキストデータに基づいて大規模な自己教師あり事前トレーニングを行い、その後、ファインチューニングによって特定のタスクに適応する。
ファインチューニングの手法には、インストラクションチューニングや人間のフィードバックを利用する強化学習(RLHF)、AIフィードバックからの強化学習(RLAIF)などがある。
また、事前トレーニングされたLLMに新たな事前トレーニングを追加することで、さらに性能を向上させることも可能。
LLMの評価には、質問応答や論理推論、特定のアプリケーション(QAや要約など)に関連する多様なベンチマークが使用されている。
4-4. オープンソースLLM vs ChatGPT
さまざまなベンチマークを通じて、LLMの一般的な能力、エージェント能力、問題解決と論理的推論能力、長いコンテキストを扱う能力、特定のアプリケーションに対する能力が評価されている。
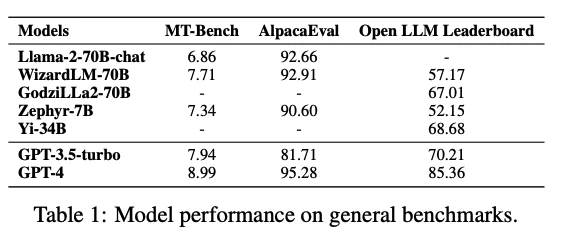
これらのベンチマークでは、GPT-4が一般的に最高のパフォーマンスを示しているが、いくつかのオープンソースLLMも良い結果を示している。
例えば、Llama-2-chat-70BはAlpacaEvalで92.66%の勝率を達成し、GPT-3.5-turboを上回っている。
また、モデル間での問題解決と論理的推論能力、長いコンテキストを扱う能力も比較されており、特定のベンチマークでGPT-4に匹敵するかそれを上回るパフォーマンスを示しているモデルもある。
一般能力のベンチマークでのモデルパフォーマンス:
LLMの一般的な能力を評価するためのベンチマークでの各モデルのパフォーマンス。
GPT-4が全般的に高いパフォーマンスを示しており、オープンソースのモデル(例えばLlama-2-70B-chat)も競争力があるが、GPT-4には及ばないことが示されている。
エージェント能力のベンチマークでのモデルパフォーマンス:
エージェントとしてのLLMの能力を評価するためのベンチマークでの各モデルのパフォーマンス。
GPT-4はこれらのタスクで優れたパフォーマンスを示しており、他のモデルも一部のタスクで競争力があるが、全体的にはGPT-4に劣る結果が見られる。

問題解決と論理的推論のベンチマークでのモデルパフォーマンス:
数学問題解決やプログラミング問題などでの各モデルのパフォーマンス。
GPT-4は論理的推論と問題解決の両方で高いパフォーマンスを示しており、オープンソースモデルも一部のタスクでは競争力を持っているが、全般的にはGPT-4に劣っている。

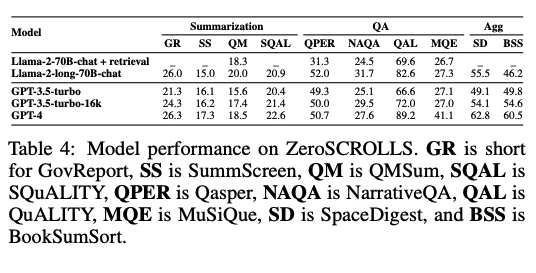
長いコンテキストモデリング能力のベンチマークでのモデルパフォーマンス:
長いコンテキストを扱う能力を評価するためのベンチマークでの各モデルのパフォーマンス。
GPT-4は長いコンテキストを扱う能力においても高いパフォーマンスを示している。オープンソースモデルは一部のタスクでGPT-4に匹敵するが、一貫してGPT-4を上回ることはない。
ホールセーションベンチマークでのモデルパフォーマンス:
LLMが誤った情報を生成する傾向を評価するためのベンチマークでの各モデルのパフォーマンス。
GPT-3.5-turboとGPT-4がホールセーション評価で高いパフォーマンスを示しており、他のモデルはこれらに比べて劣る結果が見られる。これは、GPTシリーズが誤情報の生成を抑制する能力に優れていることを示唆している。

4-5. LLMの進化と課題
モデルパラメータの拡大と事前トレーニングの改善がLLM開発の主流を形成していることが述べられている。
ChatGPTの影響でGoogleやAnthropicが類似のモデルを開発し、RLHFの改善が進行中である。
LlamaベースのオープンソースLLMが注目され、特定のベンチマークでGPT-3.5-turboを上回る事例もあるが、安全性の面ではGPTモデルが依然として優れている。
トレーニングプラクティス、データ汚染、アライメントの問題も指摘されている。
開発動向:
LLMの開発は、モデルパラメータの拡大や小規模モデルの事前トレーニング戦略改善に焦点を当てて進展している。
ChatGPTの登場により、GoogleのBardやAnthropicのClaudeなどが登場し、RLHFの改善に向けた研究が進行中。
MetaによるLlamaシリーズのリリースにより、オープンソースLLMの研究が盛んになっている。
成果の要約:
Llama-2-chat-70Bは一部のベンチマークでGPT-3.5-turboを上回るものの、他の多くでは後れを取っている。
LlamaベースのオープンソースLLMは、特定のドメインやタスクでGPTモデルを上回ることがある。
また、GPT-3.5-turboやGPT-4はAI安全性の面で依然として強力だが、RLHFの民主化によるオープンソースLLMの改善が期待されている。
ベストプラクティス:
LLMのトレーニングには複雑でリソース集約的なプラクティスが含まれる。データの収集と前処理、モデル設計、トレーニングプロセスなどが重要。
効率的な推論のための新しい方法も開発されている。
潜在的な問題点:
データ汚染、非公開開発のアライメント、基本能力における継続的な改善の難しさなどが指摘されている。
5. 最後に
ChatGPTのリリースから1周年経ったということで、オープンソースLLMとクローズドLLMの比較に関する論文を紹介させていただきました!
現時点ではまだGPT-4が優勢でしたが、オープンソースLLMの発展により、世の中がさらに便利で素早くなり、本当の意味で「豊かな」時代が来てほしいなと感じました。
[宣伝]
私の所属する株式会社エクスプラザでは、LLMの事業を展開しております。
毎週金曜にその週に起きた最新のLLMニュースまとめも発信しておりますので、ぜひご確認ください!