はじめに
AWS Bedrock を使ってナレッジベースを構築する際、AWS Aurora をベクトルデータベースとして活用することができます。
Aurora に保存されるデータの形式について調べる機会があったのですが、一度調べただけでは忘れてしまいそうだったので、今後のために接続方法やクエリでのデータ確認方法を備忘録としてまとめて残します。
重要なところだけ
- 自動作成された Aurora への接続情報は、Bedrock > ナレッジベース >対象のナレッジベースにある。
-
select chunks, custommetadata from bedrock_integration.bedrock_knowledge_base LIMIT 5で欲しいデータは取得できる。
接続&クエリ
クエリを実行するまで、少し躓いたのでその手順を確認します。
その後、実際にクエリをしてデータを見るまでをゴールとします。
使用するリソース
- Bedrock KnowledgeBase
- Amazon Aurora PostgreSQL Serverless
※リソースはすでに作成済みであることを前提に進めます。
※ナレッジベース作成の際に自動作成されたAurora を対象とします。
接続する

- マネジメントコンソールの検索ボックスで「aurora and rds」と検索します。
- 「Aurora and RDS」を選択します。

- サイドバーから「クエリエディタ」を選択します。
- 各値を入力します。すべて、ナレッジベース作成の際に自動で作られているのでコピペするだけでOKです。
- クラスター:対象のクラスターを選択します。下の画像のクラスタ APNに含まれています。
- データべースユーザー名:「Secrets manager APN と接続する」を選択します。
- Secrets manager APN:下記画像の「認証情報シークレットARN」の値をコピペします。
- データベースの名前:Bedrock_Knowledge_Base_Cluster
- すべて入力すると「データベースに接続します」を選択します。
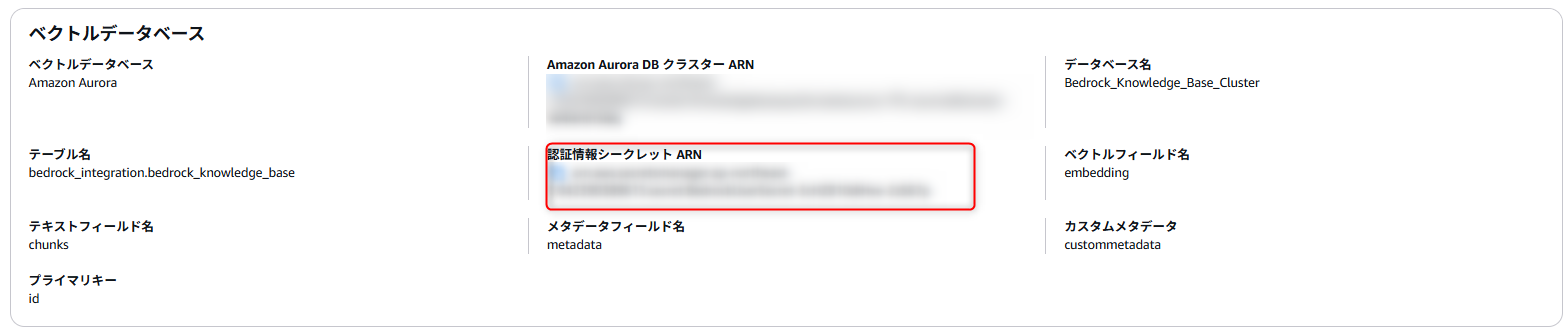
- この画面は、Bedrock > ナレッジベース >対象のナレッジベースを選択すると少し下の方に現れます
クエリする
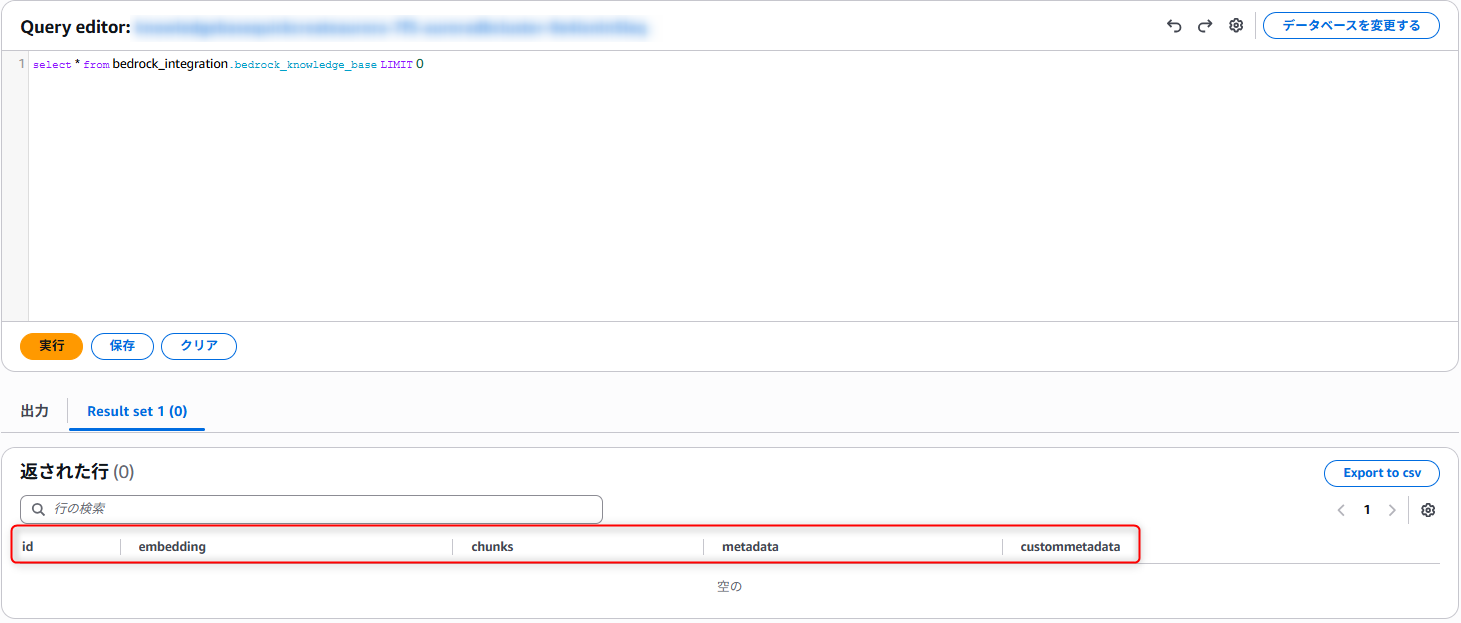
- クエリエディタが開きます。
- まずは、どんな列があるのか確認したいので下記を実行します。
- 結果を見ると、idとemmbeddingとmetadataは重要なデータは入っていなさそうですので、他2つだけ見ていきます。
select * from bedrock_integration.bedrock_knowledge_base LIMIT 0
select chunks, custommetadata from bedrock_integration.bedrock_knowledge_base LIMIT 1
- クエリエディタに上記を貼り付け実行します。
- 下記のようなデータが表示されます。
| chunks | custommetadata |
|---|---|
| question: 勤怠管理システムで打刻を忘れた場合はどうすればよいですか?, answer: 人事システムにログイン後、「勤怠修正申請」メニューから該当日を選択し、正しい出退勤時刻を入力して申請してください。承認者による承認後に勤怠データが修正されます。緊急の場合は直属の上司に連絡してください。 | {"ID":"faq_001","Tags":"人事システム, 勤怠管理, タイムカード","Status":"Active","Category":"勤怠管理","LastUpdatedDate":"2025-01-15","x-amz-bedrock-kb-source-uri":"hogehoge","x-amz-bedrock-kb-data-source-id":"hogehoge"} |
chunks にはテキスト形式で、custommetadata にはJSONB形式でデータが入っています。
ちなみにこのデータソースのファイルはCSVで、メタデータファイルを設定しています。
そのため、chunks 列にはメタデータファイルで指定したCSVの列の値がそのまま入っています。(文字数が多いとチャンク処理される場合もある。)
csutommetadata 列にはメタデータファイルで指定したCSVの列がJSONの中に格納されます。
さいごに
無事 Aurora に対して接続し、クエリを実行することができました。
こういうものは頻繁に触らないと忘れてしまうので、外部に記録しておくのは大事かもしれないですね。
参考