作業環境
Jupyter Notebook(6.1.4)を用いて作業を進めた。
各versionはpandas(1.1.3), mojimoji(0.0.11)である。
やりたいこと
データ分析の学習の中で「2021/8/16」のような日時のデータを取り扱った。分析のためにまずintやstrになっているデータ型をdatetime型へ変換してから差分を計算するなどを行ったので、その変換方法をまとめておく。
取り扱うデータ
まずはExcelで下のようなデータを準備してみた。

この時点で素直に表示設定を日付にしてから保存するのが間違いなく楽だが、今回はPythonを使って加工する方法を考えたいのでこのままdate.csvとして保存した。Jupyter Notebookを開いてファイルを読み込み表示してみたところ、予想通り次のような形になった。
import pandas as pd
df = pd.read_csv('date.csv', encoding='shift-jis')
print(df.dtypes)
# -->date object
# temp float64
# dtype: object
df
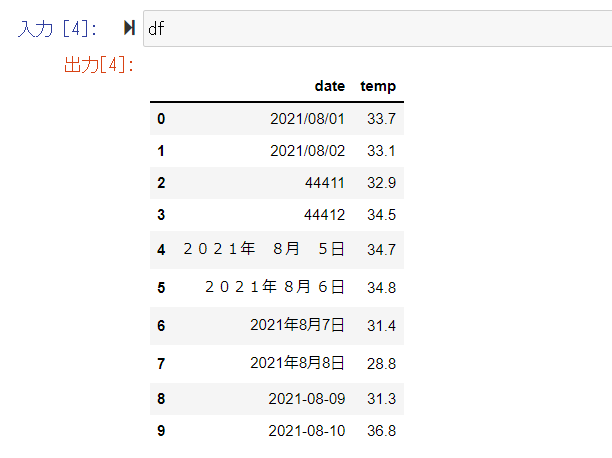
このdate列を2021-08-01の形のdatetime型に変換する。
datetime型に変換
変換の方法は次の順番で行った。
- 数値データから
datetime型に変換する - 漢字入りの文字データから
datetime型に変換する - 文字データから
datetime型に変換する
数値データからdatetime型に変換する
astype('str')でstr型に変換し、isdigit()で数値のみのフラグを立ててto_timedeltaでdatetime型における基準日からの増分へと変換、基準日を足して結果を確認する。
flag_digit = df['date'].astype('str').str.isdigit()
pd.to_timedelta(df.loc[flag_digit, 'date'].astype('float'), unit='D') + pd.to_datetime('1900/01/01')
# --->
# 2 2021-08-05
# 3 2021-08-06
# Name: date, dtype: datetime64[ns]
結果をみると、3,4行目が変換されているが、ExcelとPythonでは基準日からの数え方に違いがあるので2日分ずらさなければならない。コードに-2を加えてDigitとして保存する。
Digit = pd.to_timedelta(df.loc[flag_digit, 'date'].astype('float') - 2, unit='D') + pd.to_datetime('1900/01/01')
漢字入りの文字データからdatetime型に変換する
次に数値データ以外の部分を変換しようとすると次のような結果になった。
Str = pd.to_datetime(df.loc[~flag_digit, 'date'])
# ---> Unknown string format: 2021年 8月 5日
どうやら1,2行目はこれで変換できるようだが、5行目の全角・空白入り・漢字表記のコンボで引っかかってしまったらしい(ちなみにpd.to_datetime(1900/01/01)は変換できたので全角が必ずしもだめなわけではなさそう)。まずは全角と空白入りを解決する。全角から半角への変換はmojimojiを使用した。
import mojimoji
df['date'].apply(lambda s: mojimoji.zen_to_han(s))
# --->
# 0 2021/08/01
# 1 2021/08/02
# 2 44411
# 3 44412
# 4 2021年 8月 5日
# 5 2021年 8月 6日
# 6 2021年8月7日
# 7 2021年8月8日
# 8 2021-08-09
# 9 2021-08-10
Name: date, dtype: object
5,6行目が半角になっていることが確認できた。またreplaceを使ってスペースも削除しておく。
df['date'] = df['date'].apply(lambda s: mojimoji.zen_to_han(s))
df['date'] = df['date'].str.replace(' ', '')
漢字表記についてはto_datetime()の第二引数にformat='%Y年%m月%d'を指定することで変換ができるので、漢字部分にのみフラグを立てて変換を行いたい。これには正規表現を用いる。私があまり詳しくないので動作確認を行った。なお漢字の範囲はかなり広めにとっている。
import re
# コンパイル
kanji_check = re.compile('[\u2E80-\u2FDF\u3005-\u3007\u3400-\u4DBF\u4E00-\u9FFF\uF900-\uFAFF\U00020000-\U0002EBEF]+')
print(kanji_check.search('これは漢字'))
# ---> <re.Match object; span=(3, 5), match='漢字'>
# マッチングオブジェクトが返される。これはif文の中でbool値として判定される
if kanji_check.search('こんにちは'):
print('漢字が入っている')
else:
print('漢字が入っていない')
# ---> 漢字が入っていない
if kanji_check.search('今日は'):
print('漢字が入っている')
else:
print('漢字が入っていない')
# ---> 漢字が入っている
これを用いてフラグを作り変換、Kanjiに保存した。
flag_kanji = []
for date in df['date']:
if kanji_check.search(date):
flag_kanji.append(True)
else:
flag_kanji.append(False)
Kanji = pd.to_datetime(df.loc[flag_kanji, 'date'], format='%Y年%m月%d日')
文字データからdatetime型に変換する
最後に残りの行を変換してStrに保存する。
Str = pd.to_datetime(df.loc[~(flag_digit | flag_kanji), 'date'])
ここまでで保存したものをconcatで結合して結果を確認する。
df['date'] = pd.concat([Digit, Kanji, Str])
df

無事に変換できた!