2018年8月のバージョンからPowerBIDesktopでPythonが利用できるようになりました。
Python周りの提供機能としてはデータ描画、データ取得の2つ用意があるようです。
今回はデータ取得について使い方を確認し、利用用途を考えてみます。
pythonは3.7を利用します。
機能の概要
データ取得機能はpandasのデータフレームをそのままPowerBIのテーブルとして使うことが出来る機能です。
テーブルとして読み込めばそのままリレーションを設定したり、メジャーを定義したりと、他のテーブル全く同等の扱いが出来ます。
使い方
公式ドキュメントを見ればだいたいわかります。ここではvenvを使ってみます。
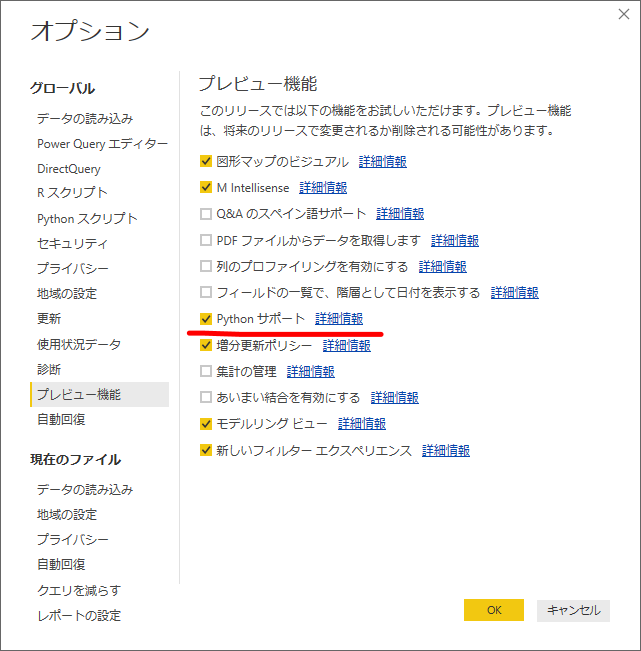
オプション機能を有効化
ファイルタブ>オプション>プレビュー機能からPythonサポートをオンにします。この操作は初めて利用する時だけ必要で、PowerBIDesktopの再起動を要求されます。
仮想環境の準備
PowerBIで利用するためにはライブラリ(pandas, matplotlib)のインストールを要求されます。
他のPythonプロジェクトの環境に影響しないように、ここは個別に環境を作ります。venvを使っていますが、もちろんvirtualenvを使っても構いません。
python -m venv venv
venv\scripts\activate
pip install pandas matplotlib
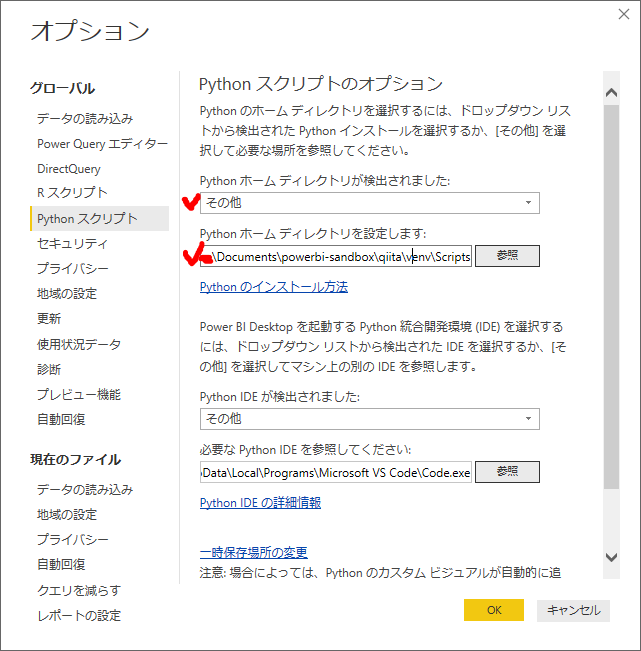
ファイルタブ>オプション>pythonスクリプトから、ホームディレクトリを設定します。
先程作成したvenv\scriptsフォルダを指定します。この選択画面、パスがコピペできないので参照からフォルダまで選びましょう。
スクリプトの記述
"データを取得"メニューから、その他>Pythonを選択します。スクリプトを書くフォームが現れるので、スクリプトを書きましょう。ここは完全にPythonの世界です。
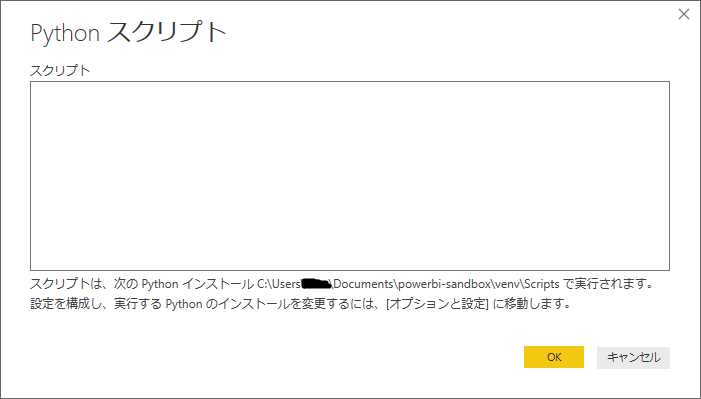
データフレームを変数として定義して、OKとします。
import pandas as pd
df_tokyo = pd.read_csv("C:\\Users\\ユーザー名\\Documents\\powerbi-sandbox\\qiita\\data1_tokyo.csv")
するとスクリプト内で生成したデータフレームの変数がそのままテーブルとして読み込まれます。
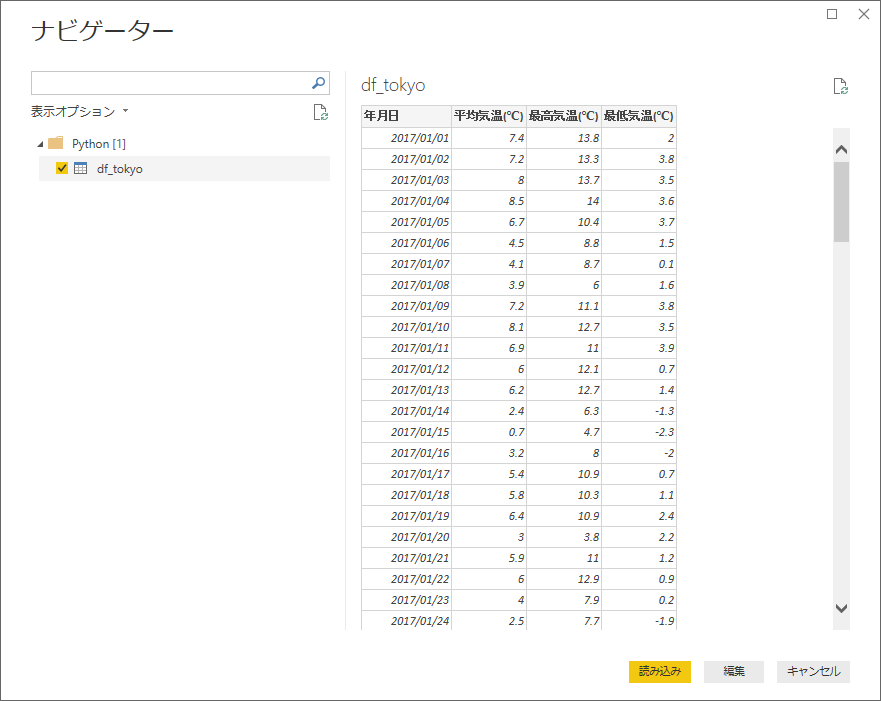
クエリエディタ上ではこのようになります。データフレームがテーブルとして認識されています。
あとは、他のデータと同様に扱えます。
試しにデータを2つスクリプト内で読み込んでみます。
import pandas as pd
df_tokyo = pd.read_csv("C:\\Users\\ユーザー名\\Documents\\powerbi-sandbox\\qiita\\data1_tokyo.csv")
df_osaka = pd.read_csv("C:\\Users\\ユーザー名\\Documents\\powerbi-sandbox\\qiita\\data1_tokyo.csv")
2つ読み込まれました。
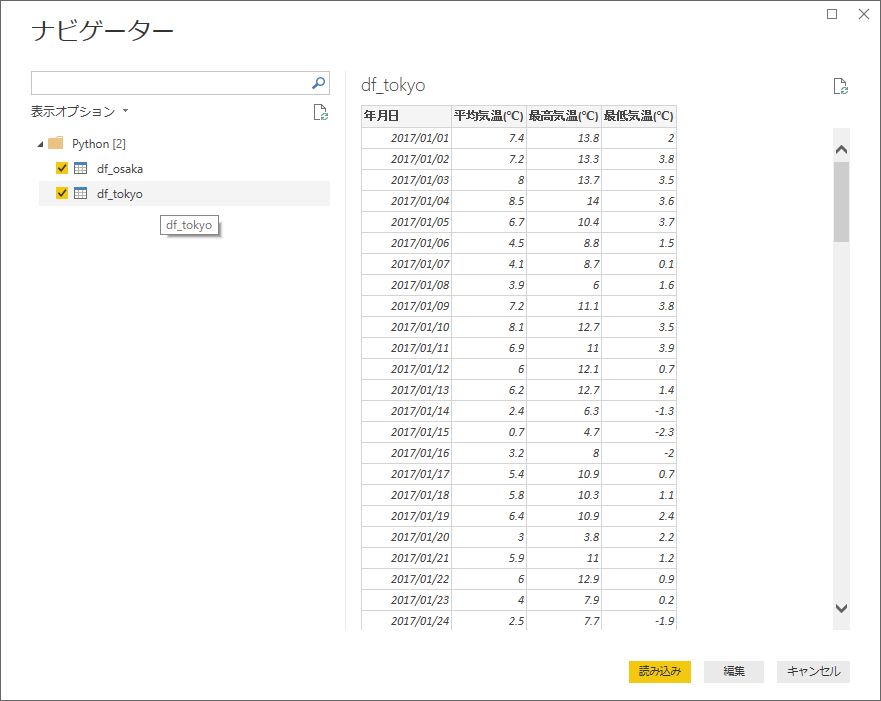
利用用途
データ取得がPython経由でできるようになるとどうなるのか考えてみました。
- pandasでの分析資産をそのまま利用できる
- PowerQuery(M言語)はロードに徹し、Python側でデータ加工という運用ができる。
- pandas(numpy)のデータ読み込みパフォーマンスを享受できる。
といったことが期待できます。
pandasでの分析資産がある方は、おそらくそのままPowerBIにコードをコピペすれば、描画部分だけPowerBIを使うことができるようになるでしょう。移行も楽そうです。でも、描画機能はPython側でも結構充実しています。IPythonやjupyterなどでインタラクティブに分析できる強みが移行によって少なくなるので、そこまで移行するインセンティブは無いかもしれません。もともとO365やPowerBIが導入されている場合、結果の共有をPowerBI経由にするのはありでしょう。
データ加工についてはPowerQueryの機能とかぶる部分が多いです。Pythonを使うシーンで特に有用と思われるのが、コネクタが無く、WebAPIを直接叩いてデータを取得するような場合です。一応PowerBIにもWebから取得する機能がありますが、コードをバージョン管理出来る分、pythonを使ったほうが管理は楽でしょう。
requestsやbeautiful soupなどを使ったスクレイピングの資産も使うことができます。
https://docs.microsoft.com/ja-jp/power-bi/desktop-tutorial-importing-and-analyzing-data-from-a-web-page
データ読み込みパフォーマンスについては、どうでしょう?pandasは普通に使って結構早いですし、pythonからデータ取得するときStringIOモジュールなどを使って極力ファイルにしないことで速くできる可能性はあります。これはPCのスペックやネットワークにも結構左右されるので一概には言えないですが。
参考までに、手元でawsのathenaを使っているので、ODBCのコネクタに代わってpythonでPowerBIにデータをロードしてみる実験をしてみました。コネクタはこれです。
https://docs.aws.amazon.com/athena/latest/ug/connect-with-odbc.html
awsに関してはboto3を使います。
https://aws.amazon.com/jp/sdk-for-python/
pythonでは、認証周り、ポーリングなど多少面倒な部分はありましたが、通常10分以上かかっていたロードを2分ほどで完了することができました。(データの量は80万件×数列。内容は数字とタイムスタンプテキスト、PCはWin10, core i5-7300u メモリ8G)
あくまで参考です。
改善ポイント
いろいろ可能性あるPython機能ですが、改善してほしいポイントもあります。
まず、PowerBI側のpythonを書く画面が貧弱でここでコードを書くイメージはあまり持てません。IDEを指定する欄はあるものの、データ取得時はフォームがぽんと1つ出るだけです。(行番号ぐらいせめて出してくれるといいのですが。)
PowerBI上でpythonをあまり書かなくていいようにpython側をパッケージしショートハンドを提供する作戦は取れそうです。基本的には、他で書いたコードをコピペすることになるでしょう。
また、使い方のところで少し触れましたが、仮想環境の切り替えは非常に面倒です。
オプション画面に行っていちいち切り替える必要があります。もう少しスムーズになると助かりますね。
(anacondaとか入れていると、このあたりそもそも切り替えない人が多いのでしょうか?使ったことが無いのでちょっとわからないですが)
まとめ
最終的にDataFrameになっていればテーブルとして扱うことができるのは、個人的には非常にわかりやすく、画期的な機能だと思っています。PowerBIDesktopの強みは様々なデータソースをpbixファイル上で同じように扱うことができることだと思っています。データ取得方法の選択肢の1つとして覚えておくといいかもしれません。