はじめに
Elasticsearch には日本語を形態素解析してくれる 公式プラグイン が存在します。
長い日本語の文章からキーワードをいい感じに抜き出してくれてとても便利なのですが、単語だけのデータとか短い日本語は苦手なようで、うまくいかないことがあります。
たとえば、「サイトウ」さんみたいに漢字が「斉藤」とか「斎藤」とか「齋藤」とか何種類かある場合は全然マッチしてくれません。
kuromoji_readingform token filter で全部カナに変換しておくことである程度吸収できるのですが、これを使うときはあらかじめ kuromoji_tokenizer でトークンごとに分けておく必要があります。
検索ボックスに何をを入力するか考えてみてほしいのですが、こういう検索をするのは珍しいと思います。

私ならこうします。

検索ワードの切れ目は自分で決めたい人が多いのではないのでしょうか。
つまり、
あらかじめ kuromoji_tokenizer でトークンごとに分けておく必要があります。
のせいで
Elasticsearch 日本語検索 自作プラグイン
こうなってほしい検索クエリは
Elasticsearch 日本語 検索 自作 プラグイン
みたいに区切れて、検索対象が多い場合はゴミデータばかり上位に出てきてしまいます。
もうひとつ、日本語を入力するときはいきなり 漢字 で入力せずに かな で入力してから変換しますよね?
これだと漢字に変換するまで期待した検索結果が出ないので、サジェストとかインクリメンタルサーチには使えません。
前置きが長くなりましたが、この辺を解決しようという話です。
Elasticsearch の analyzer について
Elasticsearch では 検索ワード と 検索対象ドキュメント は analyzer を通して検索しやすい形に変換してからマッチングに使用します。
詳しいことは公式ドキュメントに書いてありますが、ざっくりまとめると3つの要素で構成されていて
- char_filter (character filter)
- tokenizer
- filter (token filter)
の順で処理されます。
それぞれ char_filter は文字列全体の変換、 tokenizer はトークンに区切る処理、 filter はそれぞれのトークンごとに変換を行います。
ここで注目したいのは character filter の結果が tokenizer に入るという点です。
kuromoji_readingform token filter は token_filter で全段の tokenizer には kuromoji_tokenizer しか使えませんが、これを character filter で使えれば自由にトークンを区切ることができます。
漢字→カナ変換プラグイン
ということで、同じことを考える人はいるはず!!と思って探してみたのですが見つからなかったので漢字→カナ変換プラグインを自作しました。
プラグイン開発には Elasticsearch 公式の elasticsearch-analysis-kuromoji を参考にしました。
インストール
Docker で Elasticsearch を用意してプラグインをインストールします。
$ docker run --name=es -p9200:9200 -d elasticsearch:5.6.5
9b8458e2c86d1990aca9ef64a8111d0d169aac8524a88737c020db855f00c3e8
$ docker exec es bin/elasticsearch-plugin install https://github.com/bgpat/elasticsearch-analysis-japanese/releases/download/v0.0.1/elasticsearch-analysis-japanese-es5.6.5.zip
-> Downloading https://github.com/bgpat/elasticsearch-analysis-japanese/releases/download/v0.0.1/elasticsearch-analysis-japanese-es5.6.5.zip
[=================================================] 100%
-> Installed elasticsearch-analysis-japanese
比較対象に analysis-kuromoji もインストールしておきます。
$ docker exec es bin/elasticsearch-plugin install analysis-kuromoji
-> Downloading analysis-kuromoji from elastic
[=================================================] 100%
-> Installed analysis-kuromoji
プラグインが有効になるのは次回起動時なので再起動します。
$ docker restart es
es
検証
analyzer の動作を確認するための API があるのでこれを使います。
(curl コマンドだと JSON を書くのが大変なので Insomnia で検証しています)
デフォルト設定
何も指定しないときは standard analyzer になります。
Standard Tokenizer + Lower Case Token Filter の組み合わせで英文をいい感じに正規化してくれます。
もちろん日本語には対応していないのでこうなります。
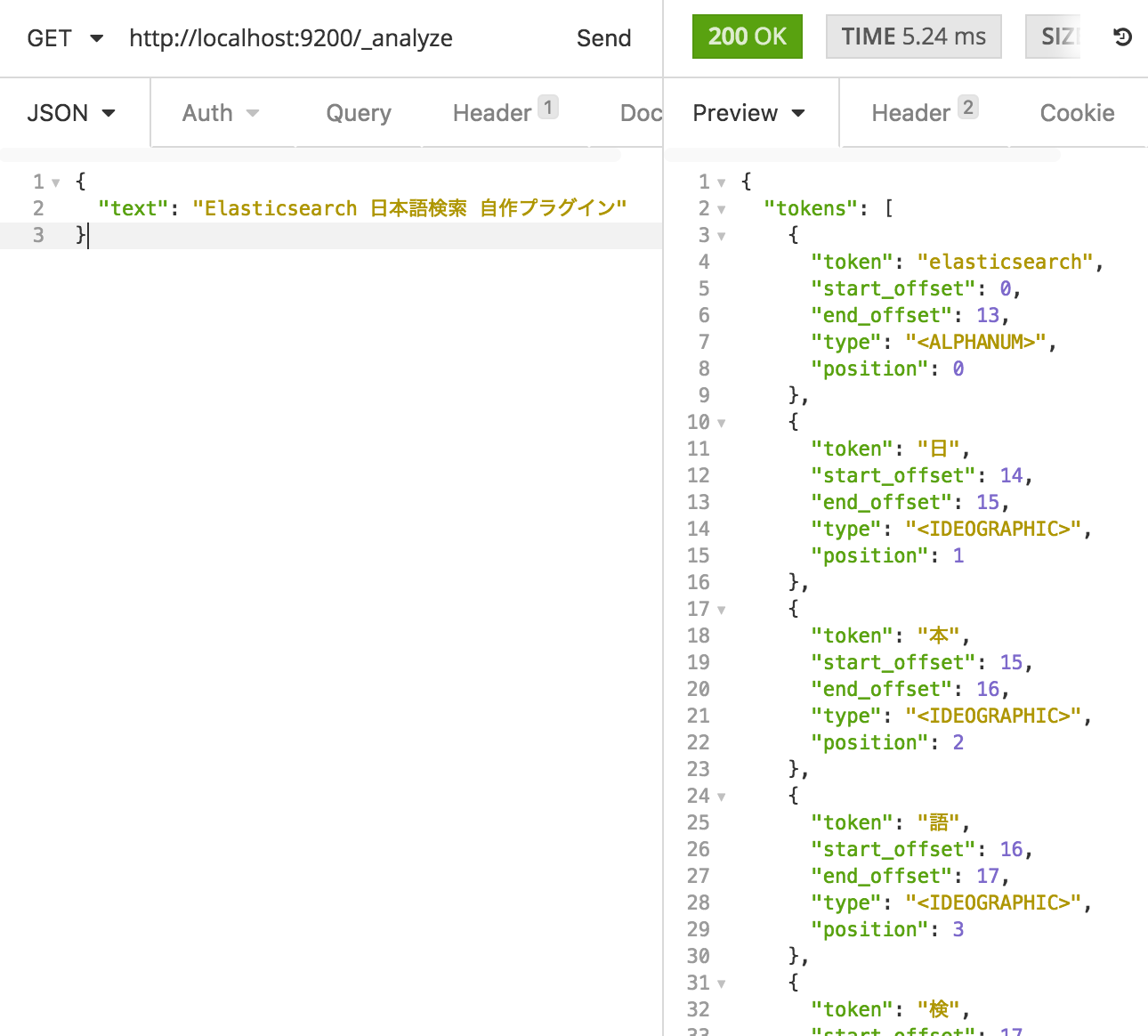
kuromoji analyzer
kuromoji analyzer を使ってみます。
日本語の文章をいい感じに正規化してくれます。

検索対象ドキュメントとしてはまだいい(?)かもしれませんが、検索ワードでこれだと困ります。
kuromoji_tokenizer + kuromoji_readingform token filter
今度は kuromoji analyzer をバラして kuromoji_readingform token filter でカナに変換します。
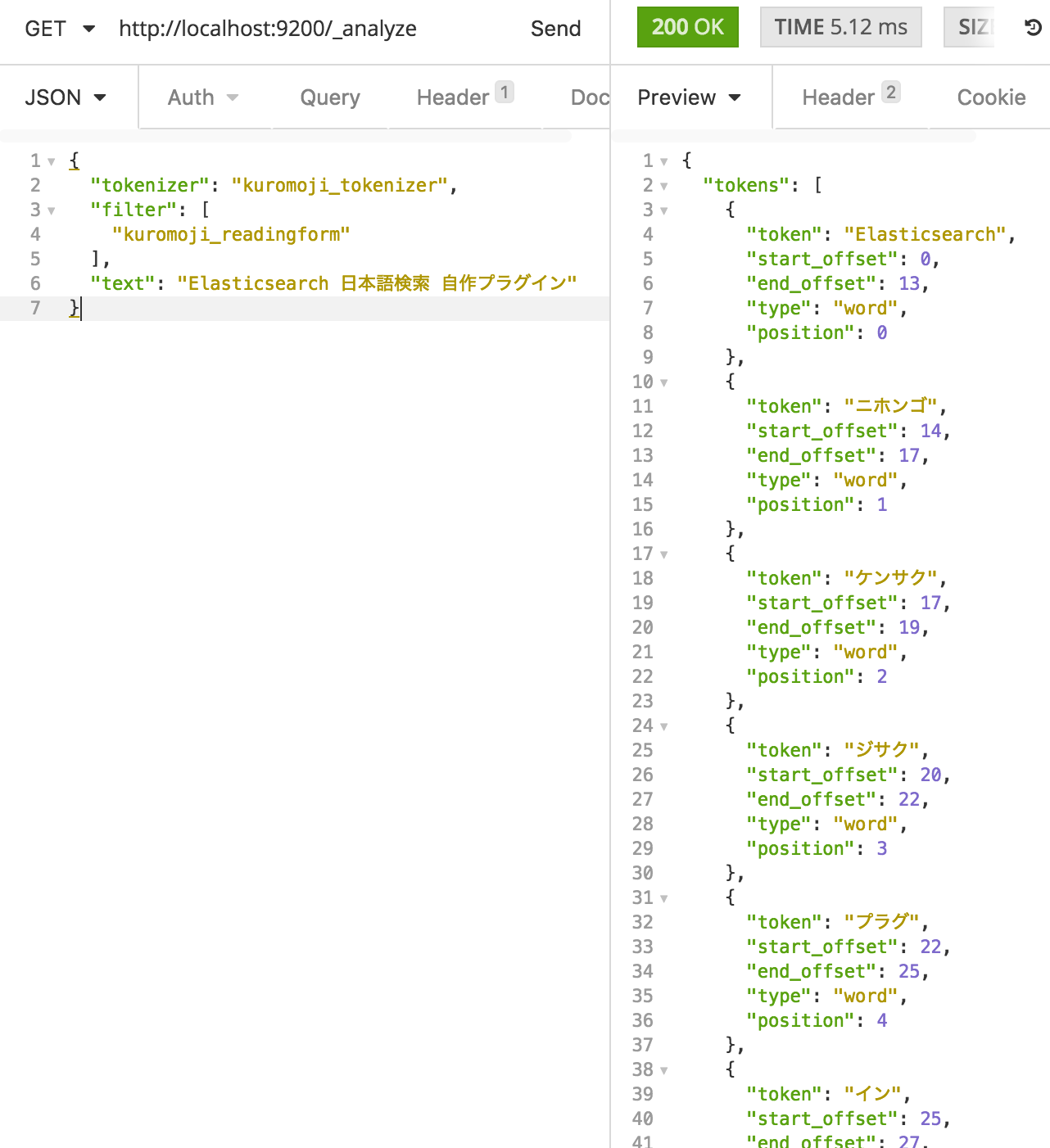
当然、 kuromoji analyzer のときとほとんど変わりません。
whiltespace tokenizer + kuromoji_readingform token filter
欲しかった whiltespace tokenizer でのスペース区切りと kuromoji_readingform token filter でのカナ変換です。

空白区切りにはなっていますが、カナ変換が機能していません。
whitespace tokenizer + katakana_transform
whitespace tokenizer と自作プラグインの katakana_transform です。

欲しかった機能が実現できました。
ついでに試してみます。
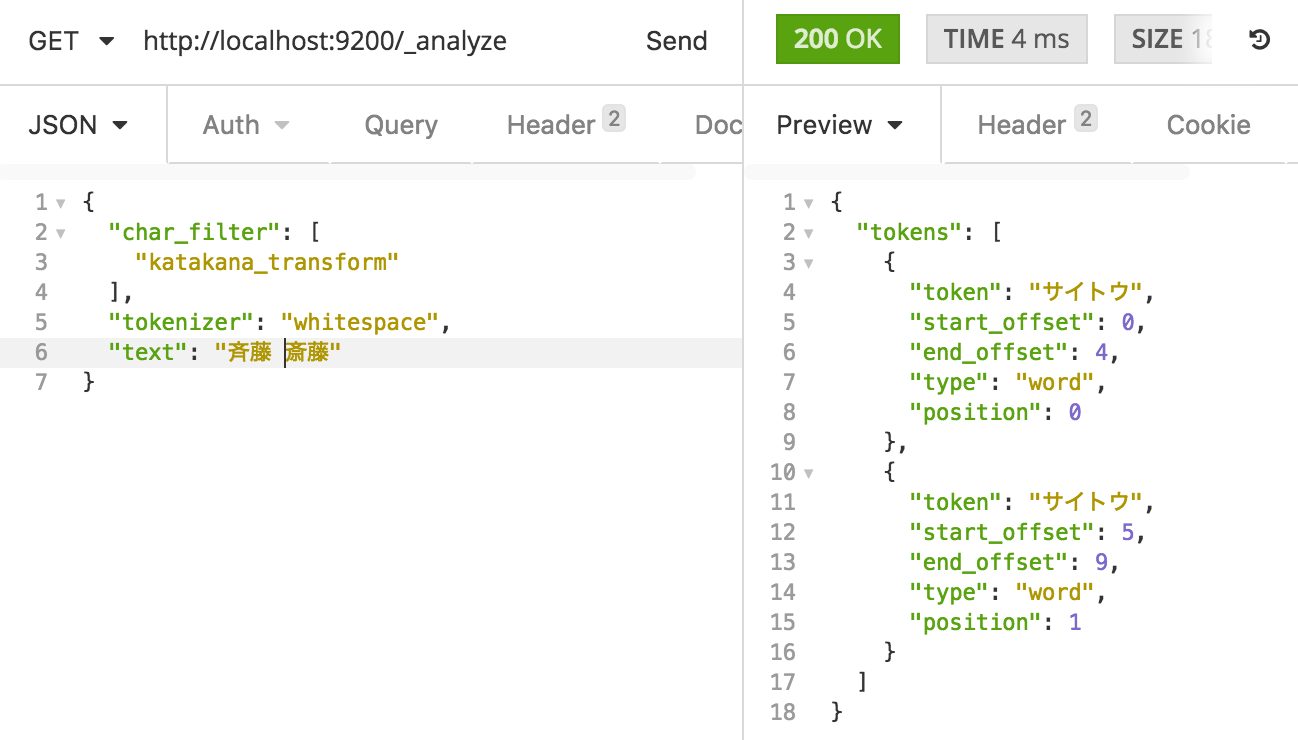
これで「サイトウ」さんの漢字がうろ覚えでも検索できるようになりました。
実用例
今回開発したプラグインは http://syllabus.kstm.cloud/ で使っています。
(検索対象のドキュメントには所属する大学のシラバスを用いました)
自作プラグインの他に、ローマ字入力の途中でもインクリメンタルサーチできるよう icu_normalizer でカナ→ローマ字変換を行っています。
また、検索速度を上げるために edge-ngram tokenizer で対象ドキュメントをインデクシングしています。(prefix は正規表現を使っているので遅いとか)
一応 kuromoji analyzer でもインデックスを作っているので、完全一致したときは必ず上位に出てきます。
コードは https://github.com/kstm-su/es-syllabus-web に置いてあります。
まとめ
tokenizer を制限しない__カナ変換プラグイン__で自分好みの日本語検索をする仕組みを紹介しました。
カナ変換のアルゴリズム上 ipadic-neologd にある単語しかできないためまだ満足とはいえませんが、大体のケースには対応できるのでは?と思います。