はじめに
MVTec ADとはCVPR2019で公開された外観検査にフォーカスした異常検知データセットです。
- データセット:MVTEC ANOMALY DETECTION DATASET
- 論文:MVTec AD – A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection

Qiitaでも本データセットを用いた論文の紹介記事や検証記事が投稿されています1。またこのデータセットは産業界にも浸透し、MVTec ADを用いた評価結果をプレスリリースで見かけるようになりました2。
このようにデータセット公開後、画像異常検知のデファクトスタンダートとなったMVTec ADですが、今年その改訂版となる論文が公開されたのはご存じでしょうか?
- The MVTec Anomaly Detection Dataset: A Comprehensive Real-World Dataset for Unvsupervised Anomaly Detection(International Journal of Computer Vision 2021)
本稿ではこの2つの論文をベースにMVTec ADで使用される評価指標をひも解いていきたいと思います。
また指標の解説とあわせて本評価に関連する私のエピソードも紹介したいと思います。
2つのAUROC
MVTec ADの主要な評価指標と精度の推移は下記のLeaderboardから確認できます。
このLeaderboardに登録されている主な評価指標は「Detection AUROC」と「Segmentation AUROC」。AUROCは異常検知のような2値分類タスクにおいてメジャーな評価指標で、以下で紹介されているようにFPRとTPRをプロットすることで得られるROC曲線下の面積を指します。
TPR(True Positive Rate): 陽性(異常)を正しく陽性と判定した確率
FPR(False Positive Rate): 陰性(正常)を誤って陽性と判定した確率
AUC(Area Under the Curve): グラフの曲線より下の部分の面積。値が1に近いほど判別能が高い

それではこの2つのAUROCに関する私のエピソードを紹介し、これらがどのような特徴を有しているかを説明します。
エピソード:AUC0.96も出ないんだけど?
Auto Encoderベースの異常検知アルゴリズムを検討していた私はMVTec ADを用いて性能評価を行いました。論文のベンチマークとなっているAuto Encoderを試しましたが、Resultに記載されているAUCには遠くおよびません。Screwにいたっては論文:0.96に対して0.6程度しか得られませんでした![]()
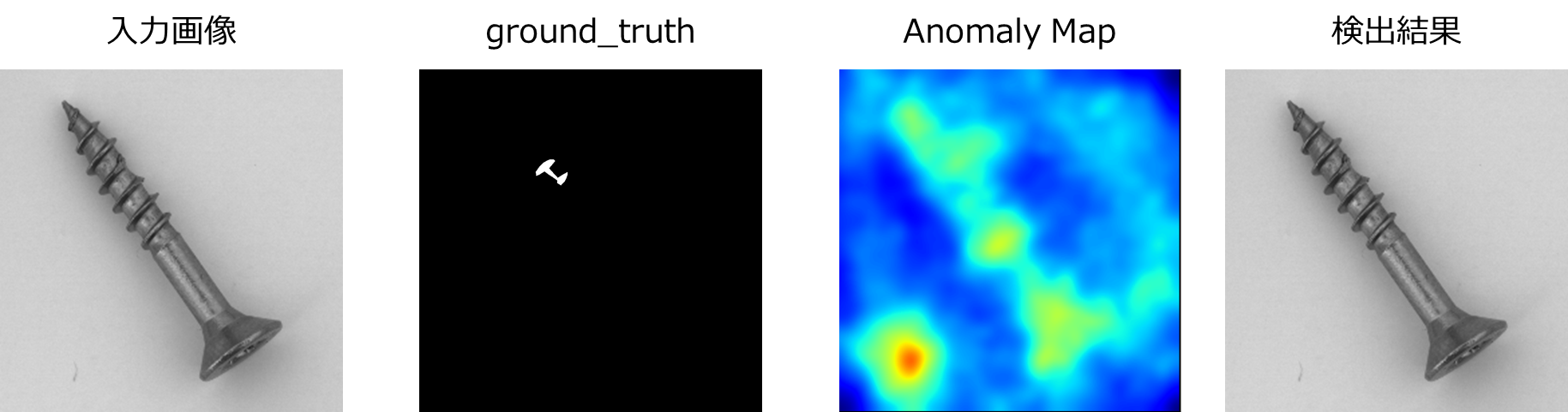
下記はその時の出力画像とanomaly mapです。
Screwというよりは『釘』って感じの画像が再構成されています。

この結果を受けて実装が間違っているのか?学習が上手くいってないのか?などの見直しを進めました。しかしそれらしい原因は見つかりません。そんな中、論文を見返したときに見つけた下記の文言に気づき真相が判明しました。
We define the true positive rate as the percentage of pixels that were correctly classified as anomalous across an evaluated dataset category. The false positive rate is the percentage of pixels that were wrongly classified as anomalous.
私は画像単位でAUCを算出したのに対して、論文はピクセル単位で評価を行っていました。そのため結果がかみ合わなかったのです。
この画像単位で算出したAUCがDetection AUROC、ピクセル単位で算出したAUCがSegmentation AUROCに該当します。次にそれぞれの指標の特徴を説明します。
Segmentation AUROC
Segmentation AUROCはPixel-level AUCとも呼ばれています。
算出方法はシンプルで以下のように、算出したAnomaly MapとGround Truthのmask画像を1次元化し、sklearnの関数に入力することで算出できます。
from sklearn.metrics import roc_auc_score
flatten_gt_masks = gt_masks.flatten()
flatten_anomaly_maps = anomaly_maps.flatten()
pixel_level_auc = roc_auc_score(flatten_gt_masks, flatten_anomaly_maps)
下記がそれぞれのROC曲線をプロットした結果です。
DetectionとSegmentationでROC曲線が大きく乖離していることがわかります。
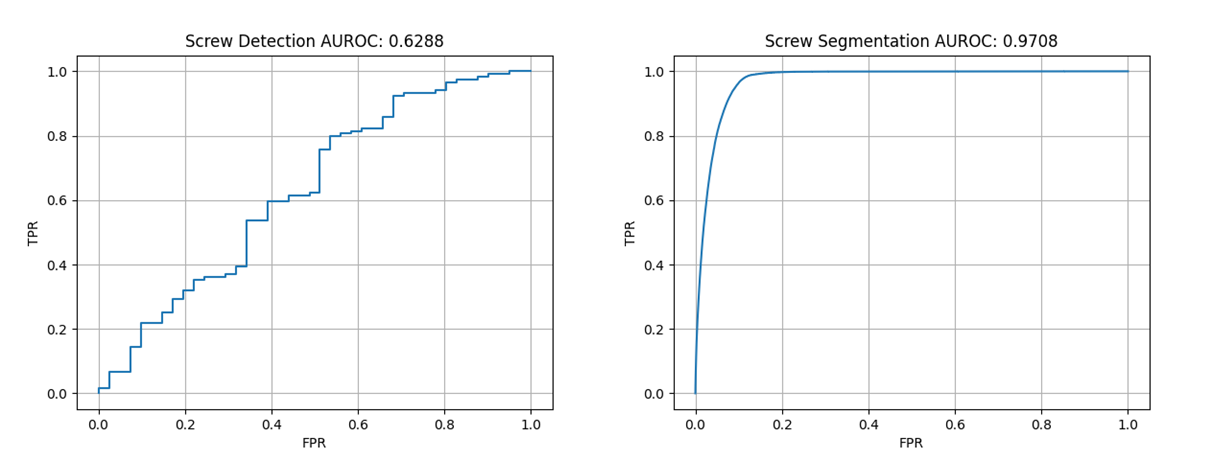
この乖離の要因として背景の存在があります。先の結果は異常検知の性能としてはまだまだですが、ピクセル単位で見た場合には、面積の大きい背景領域にはきちんと低い異常度を示すことができています。結果として欠陥検知の成否にかかわらず、背景領域と検査対象を区別するのみで9割強のスコアを稼ぐことが可能になります。
AUCが高い値を示すからといって検査に有効とは限らない、を象徴する事例です。
Detection AUROC
Detection AUROCはImage-level AUCとも呼ばれています。
本指標は画像単位で検出性能を評価することで得られるROC曲線下の面積を指します。もともとのMVTec AD論文には記載されていない評価指標ですが、検査現場では見逃し数(False Negative)や過検出数(False Positive)といったサンプル単位で効果を見積もることが多いため、多くの論文が本指標を用いた評価を行っています。
画像の異常度算出は、画像から直接異常度を算出する方式と、算出したanomaly mapの最大値を異常度とする方式があります。この画像ごとのanomaly socreとラベル情報を用いてAUCを算出します。
from sklearn.metrics import roc_auc_score
# anomaly_mapの最大値を画像の異常度とする場合
anomaly_scores = anomaly_maps.reshape(anomaly_maps.shape[0], -1).max(axis=1)
image_level_auc = roc_auc_score(gt_labels, anomaly_scores)
こちらの指標は先のSegmentation AUROCとは異なる課題があります。下記にその例を示します。
以下の検出結果は、背景のゴミに高い異常度を示しており、肝心の欠陥領域を検出することができていません。しかしanomaly mapの最大値を画像の異常度とした場合には、本サンプルは見逃しではなく正解として扱われます。
このように本指標は検出した箇所が欠陥領域を外した場合でも、誤って正解に換算されてしまう可能性があります。
以下にそれぞれの課題をまとめます。Segmentation AUROC、Detection AUROCともに異常検知性能を測るのに有効な指標ですが、一長一短あることがうかがえます。
Segmentation AUROC:面積の影響を大きく受ける
Detection AUROC:検出箇所が欠陥領域を外していても正解として扱われる可能性がある
Per-Resion Overlap
先の課題を鑑みて新たに提唱された評価指標がPer-Resion Overlapです。
先ほどSegmentation AUROCの説明では背景面積の話をしましたが、この指標は背景だけでなく欠陥の大きさにも左右されます。たとえばHazelnutの欠陥は下記のように欠陥種類やサンプルによって大きく異なります。欠陥サイズのばらつきが大きいときに、Segmentation AUROC評価をすると欠陥の大きなサンプルにスコアが引っ張られてしまいます。このようにピクセルレベルの評価手法は、小さい欠陥を見逃したとしてもそれが評価値に現れづらくなります。

そこでMVTec AD論文の著者らはピクセルや画像単位で評価するのでなく、欠陥領域ごとに評価を行うPer-Resion Overlap(PRO)を考えました。
PROの定義とその特徴
下記にPROの算出式とイメージ図を示します。PROは各ピクセルを独立して扱わずに、ground truthの連結成分3ごとでの性能を平均化した指標です。$\frac{\left|P_{i} \cap C_{i, k}\right|}{\left|C_{i, k}\right|}$は欠陥領域ごとのTPRを指しており、このTRPを平均した値がPer-Resion Overlap(PRO)となります。
$$
\mathrm{PRO}=\frac{1}{N} \sum_{i} \sum_{k} \frac{\left|P_{i} \cap C_{i, k}\right|}{\left|C_{i, k}\right|}
$$
$N$: 評価データセットに含まれる欠陥領域の総数
$P_{i}$: 閾値に対して異常と予測したピクセルの集合
$C_{i, k}$: ground truth画像${i}$の連結成分${k}$に対して異常とマークしたピクセルの集合
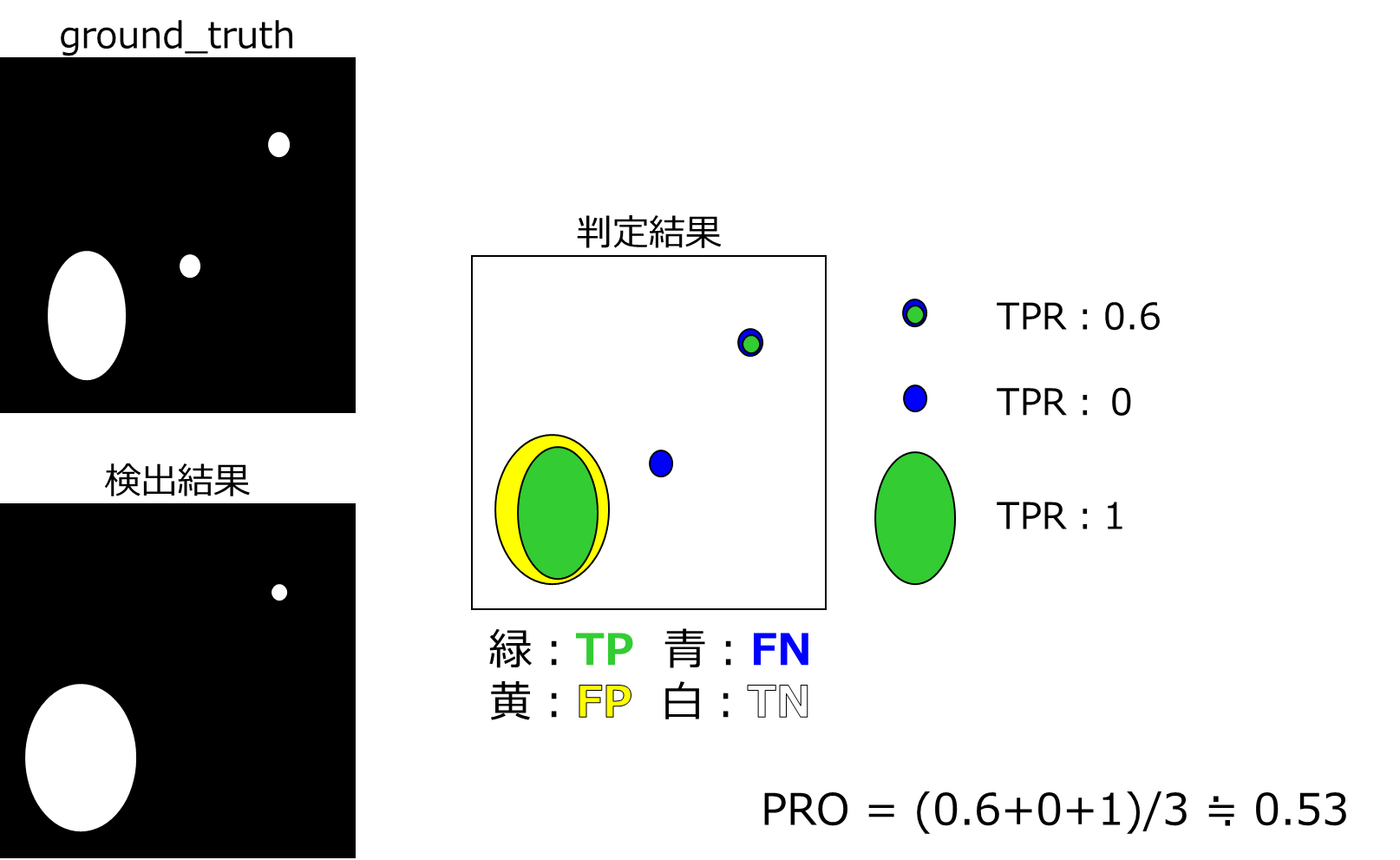
Per-Resion Overlap: 小さな異常の検出が大きな異常の検出と同等に重要である場合において有用
PROの算出式をコードに書き下すと以下のようになります4。skimageのregionpropsを利用し、個々のregionを分割することでTPRを算出します。
import numpy as np
from numpy import ndarray
from skimage import measure
def calc_pro(binary_maps: ndarray, gt_masks: ndarray):
pros = []
for binary_map, gt_mask in zip(binary_maps, gt_masks):
for region in measure.regionprops(measure.label(gt_mask)):
axes0_ids = region.coords[:, 0]
axes1_ids = region.coords[:, 1]
tp_pixels = binary_map[axes0_ids, axes1_ids].sum()
pros.append(tp_pixels / region.area)
return np.array(pros).mean()
# 2値化処理(segmentation)
binary_maps = np.zeros_like(anomaly_maps, dtype=np.bool)
binary_maps[anomaly_maps <= threshold] = 0
binary_maps[anomaly_maps > threshold] = 1
pro = calc_pro(binary_maps, gt_masks)
Area under the PRO curve
PROを用いることで欠陥サイズの影響を受けることなく、検出性能を測ることが可能となりました。しかし本指標は閾値を決定した上でないと算出することができません。そこでROC曲線と同様に閾値を振ってPRO曲線を作成しそのAUCを算出することで性能を測ります。
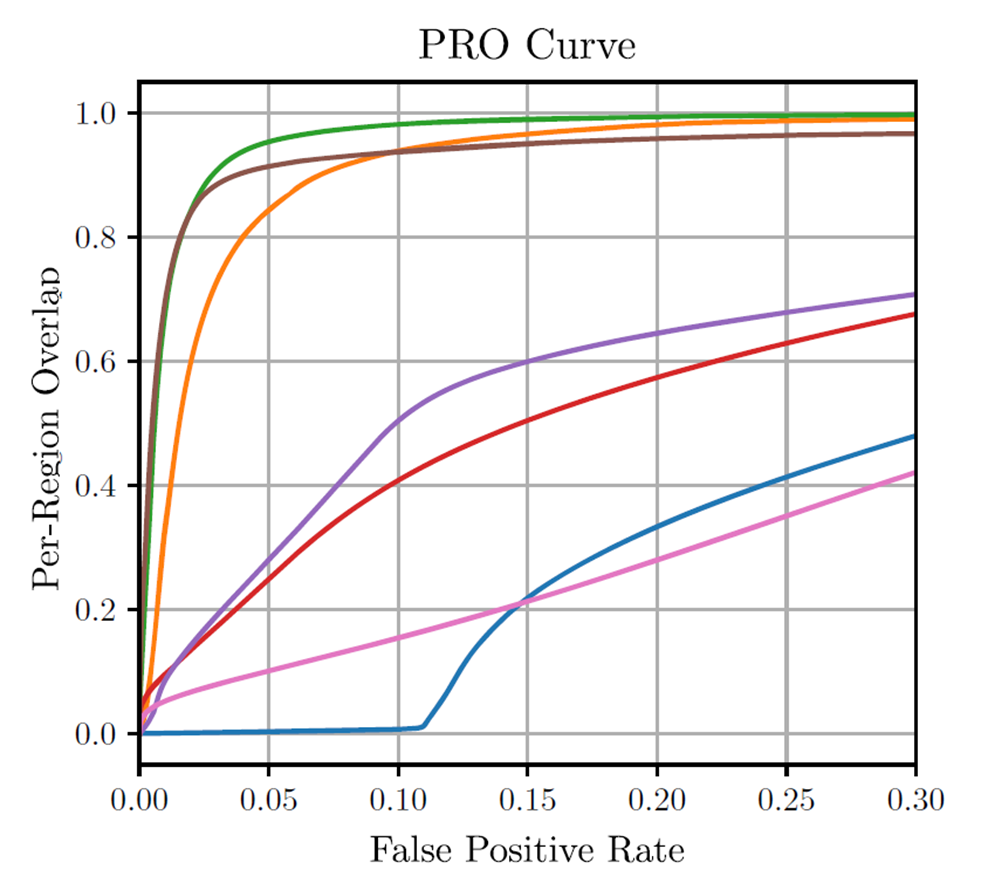
このAUCについて、論文では以下のようにFPR30%以下で算出するのを推奨しています。これは異常領域が画像の大きさに比べて非常に小さいためです。誤検出率が大きい場合、実際の異常領域のピクセルよりも大幅に大きくなり、セグメンテーションとしての意味をなさなくなってしまいます。
算出コードではこの閾値をどれくらい細かく刻むかのパラメータを設定した上、30%PRO面積を算出します。
import numpy as np
from numpy import ndarray
from skimage import measure
from sklearn.metrics import auc
import pandas as pd
from tqdm import tqdm
def calc_pro_auc(anomaly_maps: ndarray, gt_masks: ndarray, num_th: int = 500):
df = pd.DataFrame([], columns=["pro", "fpr", "threshold"])
binary_maps = np.zeros_like(anomaly_maps, dtype=np.bool)
gt_masks = gt_masks.squeeze().astype(np.bool)
min_th = anomaly_maps.min()
max_th = anomaly_maps.max()
delta = (max_th - min_th) / num_th
for thred in tqdm(np.arange(min_th, max_th, delta)):
# 2値化処理(segmentation)
binary_maps[anomaly_maps <= thred] = 0
binary_maps[anomaly_maps > thred] = 1
# PRO算出
pro_score = calc_pro(binary_maps, gt_masks)
# FPR算出
inverse_masks = ~gt_masks
fp_pixels = np.logical_and(inverse_masks, binary_maps).sum()
fpr = fp_pixels / inverse_masks.sum()
df = df.append({"pro": pro_score, "fpr": fpr, "threshold": thred}, ignore_index=True)
# 正規化 FPR from 0 ~ 1 to 0 ~ 0.3
df = df[df["fpr"] <= 0.3]
df["fpr"] = df["fpr"] / df["fpr"].max()
pro_auc = auc(df["fpr"], df["pro"])
return pro_auc
まとめ
最後に各指標の定義とその特徴をまとめます。
| 定義 | 特徴 | |
|---|---|---|
| Segmentation AUROC | ピクセル単位で算出したROC曲線下の面積 | ○容易に算出が可能 △欠陥や背景のサイズの影響を受けやすい |
| Detection AUROC | 画像単位で算出したROC曲線下の面積 | ○実検査の評価とマッチしやすい △欠陥領域を外した場合でも正解として扱われる可能性がある |
| Per-Resion Overlap | 欠陥領域ごとに算出したTPRの平均値 | ○欠陥サイズの影響を受けずに検出性能を測ることができる △他の評価指標と比べてマイナーな指標 |
今回紹介した私のエピソードは「ものさしが揃ってはじめて比較ができる」「評価指標を理解しないと正しく性能を測れない」を実感する事例でした。評価指標の理解は性能評価の根幹をなすものだと思うので、本稿が指標理解の一助なれば幸いです。