MaxClients / MaxRequestWorkers に関する言及
Apache の MaxClients / MaxRequestWorkers の適正値に関する言及を時系列にまとめた。敬称略。
他に重要な言及をしているWebページがあればお知らせください。
2002/07/23 一志達也(TIS株式会社)
ApacheによるWebサーバ構築(16):Apacheパフォーマンス・チューニングの実践 (2/2) - @IT
プロセス数を制限するためのディレクティブが「MaxClients」である。このディレクティブには、同時に接続できるクライアント(厳密にはセッション)の数を指定する。
...略...
abで同時接続数を上げながら、CPUやメモリの状態、abが示すパフォーマンスの推移を調査する。それに伴ってMaxClientsの値も上げながら、飽和点を探る作業を行うのだ。
リファレンスの参照以外で初めて MaxClients の適正値に言及している記事。
まだ具体的な基準は示されていないものの、どのように適正値を探るのかについて触れている。
2003-05-23 Eric Cholet and Stas Bekman
Practical mod_perl: 10.1.1. Calculating Real Memory Usage
従って、Webサーバーに使用できる Total_RAM MB の合計 RAM を持つマシンで同時に実行できる Min_Shared_RAM_per_Child MB の最小共有メモリーサイズを持つ子プロセスの最大数を計算する(そして最大プロセスサイズを知る)式は、
となります。これは以下のように書き換えることが出来ます。
なぜなら、分母は実際には子プロセスの非共有メモリーの最大許容量だからです。
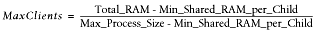

最大子プロセス数を計算する方法が具体的に述べられている。
2003-10-18 竹迫良範(株式会社ドリーム・アーツ)
[『mod_perl における C10K Problem』Shibuya.pm テクニカルトーク#4] (http://shibuya.pm.org/slides/200310/takesako.ppt) ※pptファイル
MaxClients とメモリ消費量の関係式
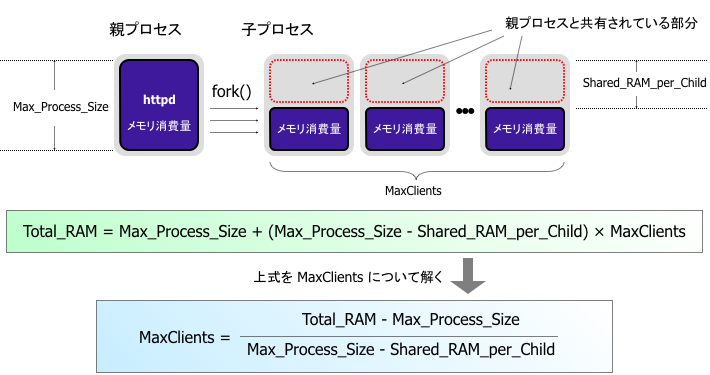
Practical mod_perl で説明されている内容が図式化されている。
2003-12-05 宮内はじめ
PC関係のメモ - MaxClients の適正値を求める / 画像(静的コンテンツ)用サーバ
Apache の最大メモリ消費量=MaxClients×子プロセスのメモリ消費量+親プロセスのメモリ消費量なのでまずは「子プロセスのメモリ消費量」と「親プロセスのメモリ消費量」を求める。
httpd の SIZE が「親プロセスのメモリ消費量」、SIZE − SHARE(親プロセスと共用している部分) が「子プロセスのメモリ消費量」になる
日本語で計算式が提示されている。
2006-02-01 ばびー(id:babie)
Apache + mod_perl - MaxClients の値に注意 - babie steps
MaxClients は「総メモリサイズ / Apache 子プロセス1つのメモリサイズ」(ドンブリ勘定)にする。
スライドにある Apache の Shared_RAM_per_Child (子プロセスの共有メモリ量)ってどうやってわかるんだろ?
Shared RAM per Child は RSS - SHARE. 正確に知りたければ GTop を使うと良いです。
しばらく間が空いた後、再び MaxClients について言及されるきっかけとなっている。
id:naoya がコメントで GTop について触れている。
2006-02-02 kounoike
共有されてるメモリ領域は/proc/$pid/smapsで取れます。
・forkする前に確保したメモリ領域は共有される→shared_dirtyになる
・forkした後にその領域に書き込みを行うとコピーされる→private_dirtyになる
・forkした後に確保した領域は共有されない(当たり前)→shared/privateにならない(多分)
sharedに入ってる間は実際のメモリは消費されることが無く,privateになるときに改めて確保されるみたいです。
共有メモリが /proc/$pid/smaps で取得できると言及される。
子プロセス1つ辺りのメモリ消費量を,「Max_Process_Size - Shared_RAM_per_Child」として計算
2007-07-08 Shunsuke Shiina (Yutuki)
MaxClientsの値 = (サーバの総RAM量 - 親Apacheプロセス消費メモリ量) / 子Apacheプロセス一個の消費メモリ量また同時に以下の計算式を満たしていた方が良い。
子Apacheプロセス一個の消費メモリ量 x MaxClientsの値 + 親Apacheプロセス消費メモリ量 < サーバの総RAM量
2007-10-24 Moodle
パフォーマンス - MoodleDocs ※日付はオリジナルの英語版による
MaxClients ディレクティブを正しく設定してください。 次の公式を使用して設定値を計算してください (予備のメモリ領域を残すため、利用可能なメモリの 80% を使用します):
MaxClients = 利用可能な合計メモリ * 80% / Apache プロセスの最大メモリ使用量Apache プロセスのメモリ使用量は通常 10MB です。一般的な経験則として、MaxClients の値を取得するには、利用可能なメモリ容量を 10MB で割ってください。Apache プロセスの最大メモリ使用量を見つけるには、シェルコマンドの結果より値を読み取ってください:
# ps -ylC httpd --sort:rss
経験則として MaxClients 適正値計算のための分子に「利用可能なメモリの 80%」が提示される。
また Apache プロセスの最大メモリ使用量を判断するためのコマンドが提示される。
2008-02-12 伊藤直也 (id:naoya)
Linux のプロセスが Copy on Write で共有しているメモリのサイズを調べる - naoyaのはてなダイアリー
例えば mod_perl の場合、MaxClients の設定に共有領域のサイズを考慮する必要があります。
プロセスのメモリ空間中の CoW で共有されている領域がどの程度あるかを計測する方法を調べてみたのですが、...略... /proc/PID/smaps を調べれば良いということがわかりました。
この smaps にある各領域のサイズのうち、Shared_Clean と Shared_Dirty のサイズを集めて合計すれば、そのプロセスが他プロセスと共有しているメモリのサイズがわかります。
Perl には Linux::Smaps という /proc/PID/smaps のデータをプログラマブルに扱えるモジュールがあります。これを使って、共有領域のサイズを調べる簡単なスクリプトを作りました。
shared_memory_size.pl#!/usr/bin/env perl use strict; use warnings; use Linux::Smaps; @ARGV or die "usage: %0 [pid ...]"; printf "PID\tRSS\tSHARED\n"; for my $pid (@ARGV) {
my $map = Linux::Smaps->new($pid);
unless ($map) {
warn $!;
next;
}
printf
"%d\t%d\t%d (%d%%)\n",
$pid,
$map->rss,
$map->shared_dirty + $map->shared_clean,
int((($map->shared_dirty + $map->shared_clean) / $map->rss) * 100)
}
> 引数に与えられた PID のプロセスの、共有領域サイズを調べて表示します。
初めてスクリプトによる MaxClients の計算の基礎が提示される。
Linux::Smaps を利用するため手軽さに欠けるが、大半の関連記事で参照される著名な記事となる。
### 2008-04-09 (id:hideden)
[mod_perlで親プロセスとのCopy on Writeな共有メモリを増やす方法。 - Perlとかmemoとか日記とか。](http://d.hatena.ne.jp/hideden/20080409/1207740439)
> 大量にアクセスがあってMaxClientを大きく設定したい場合、Apacheの1プロセスあたりのメモリを少なくするのが重要。当然アプリ側で大きなライブラリを読み込まずに画像の変換はGearmandにタスクとして投げたりとかの工夫するのも有効だが、fork元になるApacheの親プロセスと子プロセス間でできる限りCopy on Writeな共有メモリを増やすのも有効。
>
> **親プロセス側のメモリにモジュールを持たせる方法**
> 基本はとにかくstartup.plでuseして置くこと。apacheのconfigに
>
> ```apache
> PerlRequire /path/to/startup.pl
> ```
> 等を記載しておき、その中で使用しているアプリケーションのモジュールを列挙する。
>
> use Hoge ();と()を付け、関数のexportを抑止する。これだけでも結構共有メモリは増える。また、forkは親プロセスの複製になるので、こうやって事前にuseしてソースをコンパイル済みにしておくと子プロセス側でコンパイルするコストが節約でき、MaxRequestPerChildを小さめに設定してある&大量にアクセスがあり頻繁に子プロセスが再forkされるようなシステムだと負荷も軽くなるという効果もある。
### 2008-05-06 (id:hogem)
[apacheのMaxClientsの適正値調べた - うまいぼうぶろぐ](http://hogem.hatenablog.com/entry/20080506/1210073173)
> **MPMがpreforkの場合**
>
> ```
> 子プロセスの消費メモリサイズ * MaxClients < OSメモリ容量
> ```
> ただ、これは子プロセスが使ってるメモリが全く共有されてないとして計算した数字なので、MaxClientsはもう少し大きい数値でも良いはず。
>
> ```
> (RSS - SHR) * MaxClients <= OSメモリ容量
> ```
> **SHR: 共有されているメモリサイズ**
> topのSHRの項目を確認する。
> **RSS: プロセスが使っている物理メモリサイズ**
> ps、topのRSSの項目を確認する。
### 2009-09-10 ひろせ まさあき (id:hirose31)
[『Ficia』インフラとPerlにまつわるエトセトラ](http://www.slideshare.net/hirose31/ficiaperl-1981415)
> **共有領域の計算**
>
> * /proc/PID/smaps (kernel >=2.6.14)
> * 共有領域 = Shared_Clean + Shared_Dirty
>
> * shared_memory_size.pl $(pgrep httpd)
> * use Linux::Smaps
> * id:naoya♥♥
> **{Start,{Min,Max}Spare}Servers, MaxClients**
>
> * smapsの結果と搭載メモリを鑑みて計算
> * 増減があるので、実際に変更して様子を見る
> * 「swapしたら負けかなと思ってる」
> * 全部同じ値にして、起動時に一気に fork(2)する
> * reqが来てはじめてよっこらせと fork(2)するのは時間がもったいない
> * 起動時にload avgが上がるのは運用で 回避(Tipsで後述)
>
> 
>
> 
### 2009-12-09 北村聡士
[Apacheのメモリ使用量を調べる - satooshi@blog](http://blog.satooshi.jp/blog/2009/12/09/monitoring-memory-usage-of-apache/)
> **注意事項**
> 今回のスクリプトでは/proc/PID/statusと/proc/PID/smapsからデータを取ってきて、
>
/proc/PID/status
VmPeak
VmSize
VmHWM
VmRSS
/proc/PID/smaps
Rss
Shared_Clean
Shared_Dirty
> をフィルターしている。
>
> **プロセスごとのメモリ使用量を調べる**
>
```bash:getmem.sh
# !/bin/sh
>
# 1 process name
if [ $# -ne 1 ]; then
exit
fi
>
# print header
printf "PID\tVmPeak\tVmSize\tVmHWM\tVmRSS\n"
>
# get memory size
pid=`pgrep $1`
>
for p in $pid
do
if [ -f /proc/$p/status ]; then
vm=`grep -e '^VmPeak:\|VmSize:\|VmHWM:\|VmRSS:' /proc/$p/status | awk '{print $2}'`
printf "%d\t%d\t%d\t%d\t%d\n" $p $vm
fi
done
プロセス間で共有されているメモリ使用量を調べる
# !/bin/sh
>
# $1 process name
if [ $# -ne 1 ]; then
exit
fi
>
# print header
printf "PID\tRSS\tSHARED\n"
>
# get shared memory size
pid=`pgrep $1`
>
for p in $pid
do
if [ -f /proc/$p/smaps ]; then
vm=`grep -e '^Rss:\|^Shared_Clean:\|^Shared_Dirty:' /proc/$p/smaps |
awk '
BEGIN {
rss = 0;
clean = 0;
dirty = 0;
}
{
if($1 == "Rss:") {
rss += $2;
}
else if($1 == "Shared_Clean:") {
clean += $2;
}
else if($1 == "Shared_Dirty:") {
dirty += $2;
}
}
END {
per = (rss == 0) ? 0 : (clean+dirty)*100/rss;
printf("%d\t%d\t%d\n", rss, clean+dirty, per);
}
'`
>
printf "%d\t%d\t%d (%d%%)\n" $p $vm
fi
done
2010-09-01 Masahiro Nagano
プロのサーバ管理者がApacheのStartServers, (Min|Max)SpareServers, MaxClientsを同じにする理由 - blog.nomadscafe.jp
StartServers、(Min|Max)SpareServers, MaxClientsが同じ値の場合、プロセス数が固定されるので忙しいからといってMinSpareServersを確保するためだけに必要以上にforkを行うことはないし、余ったプロセスがKILLされることもない。IDLEのプロセスがCPUリソースを消費することはほぼないので余計なCPUは使いません。
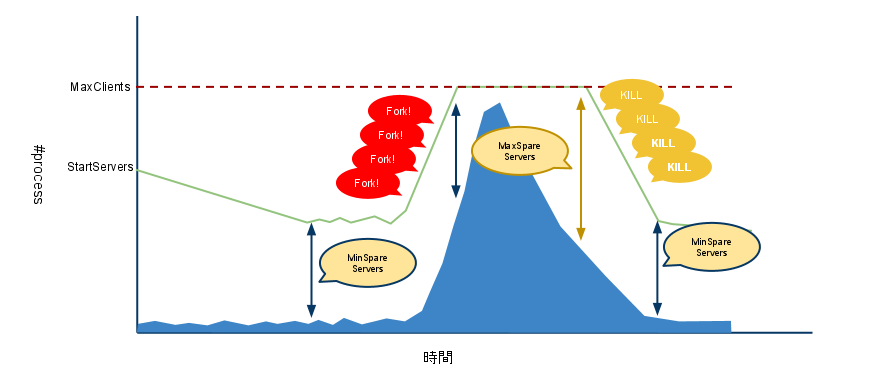
経験上、MaxClientsは一日の最大のBUSYプロセス数の倍あればいいと思います。CloudForecastやCactiなどを使って利用しているプロセス数をモニタリングするのはもはや必須課題です。
2010-09-23 holly
Copy on Writeで共有してるメモリ使用量を調べる。例によってお気軽にshellで。perlでいうとLinux::Smapsとかインストールされていない場合。
smaps.sh#!/bin/sh echo -e "PID\tVSZ\tRSS\tShared"
for pid in $@; do
smaps="/proc/$pid/smaps"
vsz=$(grep -E "^Size" $smaps | awk 'BEGIN{ num = 0 } { num += $2 } END{ print num }')
rss=$(grep -E "^Rss" $smaps | awk 'BEGIN{ num = 0 } { num += $2 } END{ print num }')
shared=$(grep -E "^Shared" $smaps | awk 'BEGIN{ num = 0 } { num += $2 } END{ print num }')
percent=$(echo "scale=2; ($shared / $rss) * 100" | bc | cut -d "." -f 1)
echo -e "$pid\t${vsz}KB\t${rss}KB\t${shared}KB(${percent}%)"
done
> こんなシェルスクリプトを作ればとりあえず、調べたいプロセスのCopy on Writeで共有してるメモリ使用量を出力できる。
>
> 子プロセスの中で確保した配列の一部(約1/10)にデータを書き込んでみる。
>
> 1/10くらいがShared_DirtyからPrivate_Dirtyに値が変化している。スクリプトで1/10に対してだけデータを書き込んだのとほぼ一致している。
### 2011-01-15 (id:youhey)
[Apacheチューニングのためのメモリ使用量計算 - ひとりごと](http://d.hatena.ne.jp/youhey/20110115/1295060276)
> 「/proc/(pid)/status」のメモリサイズからメモリ消費量をリストアップするスクリプトを準備した。
> ```bash:memory_size.sh
> #!/bin/sh
>
> GREP="/bin/grep"
> AWK="/bin/awk"
> PRINTF="/usr/bin/printf"
>
> if [ $# -lt 1 ]; then
> echo "usage: ${0} [pid ...]" 1>&2
> exit 100
> fi
>
> $PRINTF "PID\tRSS\t(peak)\tVM\t(peak)\n"
>
for p in $@
do
status="/proc/${p}/status"
if [ -f $status ]; then
rsssize=`$GREP '^VmRSS:' $status | $AWK '{print $2}'`
rsspeak=`$GREP '^VmHWM:' $status | $AWK '{print $2}'`
vmsize=`$GREP '^VmSize:' $status | $AWK '{print $2}'`
vmpeak=`$GREP '^VmPeak:' $status | $AWK '{print $2}'`
$PRINTF \
"%d\t%d\t(%d)\t%d\t(%d)\n" \
$p \
$rsssize \
$rsspeak \
$vmsize \
$vmpeak
fi
done
for p in pgrep httpd; do grep "^VmHWM:" /proc/$p/status |awk '{print $2}'; done
> で、すみそうな気も。
> ```bash
[www]~ $ ./memory_size.sh `pgrep httpd`
[www]~ $ sudo ./shared_memory_size.pl `pgrep httpd`
からエクセルにデータをもっていて、ごにょごにょと(古いプロセスと新しいプロセスのデータは破棄して、平均を算出、共有を考慮した消費量を予測)……。
2011-03-17 (id:R-H)
apacheのMaxClientを算出するスクリプトを作った - webネタ
apacheの設定にあるMaxClientsは、サーバースペック等から算出できるため、毎回手動で計算するのは面倒なのでスクリプトを作った。
計算方法
(サーバーメモリ量) / (httpd使用メモリ量 - httpd使用共有メモリ量) = MaxClients
2011-05-19 Phize
Apacheチューニング: MaxClientsに設定できる上限値を計算する - (DxD)∞
MaxClientsに設定できる上限値を計算するシェルスクリプトを作成しました。
get_max_clients.sh#!/bin/bash _PIDS=(`pgrep httpd`) _PROC_COUNT=${#_PIDS[@]} _MEMORY_TOTAL=`free | grep Mem | awk '{print $2;};'` #_MEMORY_FREE=`vmstat -a | awk 'NR==3{print $4+$5;};'` _RSS_TOTAL=0 _SHARED_TOTAL=0 for _PID in ${_PIDS[@]}; do
_SMAPS=`cat /proc/$_PID/smaps`
_RSS=`echo "$_SMAPS" | grep Rss | awk '{value += $2} END {print value;};'`
_SHARED=`echo "$_SMAPS" | grep Shared | awk '{value += $2} END {print value;};'`
_RSS_TOTAL=`expr $_RSS_TOTAL + $_RSS`
_SHARED_TOTAL=`expr $_SHARED_TOTAL + $_SHARED`
done
_RSS_AVERAGE=
expr $_RSS_TOTAL / $_PROC_COUNT
_SHARED_AVERAGE=expr $_SHARED_TOTAL / $_PROC_COUNT
_PROC_MEMORY=expr $_RSS_AVERAGE - $_SHARED_AVERAGE
#_MIN_MAX_CLIENTS=expr $_MEMORY_FREE / $_PROC_MEMORY
_MAX_MAX_CLIENTS=expr $_MEMORY_TOTAL / $_PROC_MEMORYecho "Memory Total / (Rss Average - Shr Average) = $_MEMORY_TOTAL / ($_RSS_AVERAGE - $_SHARED_AVERAGE)"
#echo "Memory Free / (Rss Average - Shr Average) = $_MEMORY_FREE / ($_RSS_AVERAGE - $_SHARED_AVERAGE)"
#echo "MaxClients = $_MIN_MAX_CLIENTS ~ $_MAX_MAX_CLIENTS"
echo "MaxClients = $_MAX_MAX_CLIENTS"exit 0
> 実際には、OSやその他のプロセスが使用するメモリもあるため、総メモリ量ではなく、空きメモリ量を使用したほうがいいかもしれません。
>
>(コメントアウトしている部分は、空きメモリ量からMaxClientsを算出しています。ただし、起動済みのApacheプロセスが使用しているメモリ量を考慮していないので不完全です。)
### 2011-08-05 (id:yumatsumo)
[プロセスのCoW共有しているメモリのサイズ - マツモブログ](http://d.hatena.ne.jp/yumatsumo/20110805)
> /proc/PID/smapsをそのままコリコリ読むスクリプト書いてみました。
>
> つまりLinux::Smaps入れないでもOKです。(List::Utilは5.8以降だとコアモジュールなので使ってます。)
>
> ```perl:shared_memory_size.pl
> #!/bin/env perl
>
> use strict;
use warnings;
>
use List::Util ();
>
@ARGV or die "usage: %0 [pid ...]";
>
my @output;
>
for my $pid (@ARGV) {
die "invalid pid '$pid'" if $pid =~ /\D/;
my @smaps = `cat /proc/$pid/smaps`;
die if $? != 0;
my @shared = map { /(\d+)\s+kB/; $1 } grep { /^Shared_(Clean|Dirty)/ } @smaps;
my $shared_total = List::Util::sum(@shared);
my @rss = map { /(\d+)\s+kB/; $1 } grep { /^Rss/ } @smaps;
my $rss_total = List::Util::sum(@rss);
my $parcent = sprintf '(%d %%)', int(($shared_total / $rss_total) * 100);
push @output, [$pid, $rss_total, $parcent];
}
>
unshift @output, [qw(PID RSS SHARED)];
>
for my $out (@output) {
print join "\t", @$out;
print "\n";
}
2012-08-12 junjun_iphone
30ごえのWEBエンジニアの日記:Apacheのプロセス毎のメモリ使用量
プロセス毎のメモリ使用量は単純に/proc/(PID)/statusのVmHWMを見ればいいわけではないようです。
親プロセスから子プロセスをforkすると、子プロセスが親プロセスのメモリ空間を共有するため、共有分を考慮しないといけません。/proc/(PID)/smapsはrootユーザにしかread権限が無いようなので、rootユーザで以下のコマンドを実行します。
echo -e "PID\tPPID\tRSS\tSHARED\tPRIVATE";ps -ef|grep httpd|grep -v grep|while read line;do args=(${line});echo -ne ${args[1]}"\t"${args[2]}"\t";cat /proc/${args[1]}/smaps|awk 'BEGIN{rss=0;shared=0;}/Rss/{rss+=$2;}/Shared/{shared+=$2;}END{printf("%.1f\t%.1f\t%.1f\n",rss/1024,shared/1024,(rss-shared)/1024);}';done
30ごえのWEBエンジニアの日記:Apacheのプロセス毎のメモリ使用量を計算するコマンドを解説
プログラム構造が理解しやすいように、前回紹介したコマンドに改行を入れてみました。
echo -e "PID\tPPID\tRSS\tSHARED\tPRIVATE";
ps -ef
|grep httpd
|grep -v grep
|while read line;
do
args=(${line});
echo -ne ${args[1]}"\t"${args[2]}"\t";
cat /proc/${args[1]}/smaps
|awk '
BEGIN{rss=0;shared=0;}
/Rss/{rss+=$2;}
/Shared/{shared+=$2;}
END{printf("%.1f\t%.1f\t%.1f\n",rss/1024,shared/1024,(rss-shared)/1024);}
';
done
[1行目] タイトル行を画面出力(各列はTAB区切り)
[2行目] psコマンドでプロセス一覧を取得
[3、4行目] 文字列「httpd」を含む行を抽出(grepコマンドのプロセスは除外する)
[5、6行目] 取得した結果に対して、1行ずつ7行目〜15行目までの処理をループ
[7行目] 3、4行目で取得した結果をスペースを区切り文字として分割した結果を配列に格納
[8行目] プロセスID、親プロセスIDを画面出力(改行はしない)
[9、10、16行目] プロセスIDに対するsmapsファイルを読み込み、awkコマンドに渡し、11行目〜14行目の処理をループ
[11行目] awkコマンド内での変数を初期化
[12行目] 文字列「Rss」を含む行の場合、値を変数Rssに加算
[13行目] 文字列「Shared」を含む行の場合、値を変数Sharedに加算
[14行目] smapsファイルの全ての行をループした後に、変数Rss、変数Shared、変数Rss−変数Sharedを画面出力し、改行する
2013-03-28 ハシモト チヒロ
apache(httpd)のメモリ量を計測 - 不完全な死体
# !/bin/bash
PIDS=`ps axfv | grep httpd | grep -v 'grep' | awk '{print $1}'`
SUM=0
COUNT=0
printf "MEM\tS_Clean\tS_Dirty\tOwn_Memory\n"
for pid in $PIDS
do
MEM=$(cat /proc/$pid/status | grep 'VmHWM' | awk '{print $2}')
SC=$(grep Shared_Clean /proc/$pid/smaps | awk 'BEGIN{n=0}{n+=$2}END{print n}')
SD=$(grep Shared_Dirty /proc/$pid/smaps | awk 'BEGIN{n=0}{n+=$2}END{print n}')
OWN_MEM=`expr $MEM - \( $SC + $SD \)`
SUM=`expr $SUM + $OWN_MEM`
printf "$MEM\t$SC\t$SD\t$OWN_MEM\n"
COUNT=`expr $COUNT + 1`
done
printf "SUMMARY\t$SUM kb\n"
AVG=`expr $SUM / $COUNT`
printf "AVG\t$AVG kb\n"
2013-10-10 (hirobanex)
Apacheとかforkしたプロセスのメモリチューニングに関するメモとスクリプト | hirobanex.net
apacheのプロセスチェックするときだとsudoつけて実行するから、いちいちSystem perlにLinux::Smapsいれなきゃいけないくて、しかもぼくのubuntu環境だと最新版の0.12の06-VmFlags.tってテストがこけてキモイし、別にLinux::Smaps使わなくてもいいやと思ったので、スクリプト化しました。
あと、共有していない部分のメモリ使用量もいちいち掛け算するのだるいので、右に出すことにした。
none_shared_memory_fetcher.pl
!/usr/bin/env perl
use strict;
use warnings;
@ARGV or die "usage: %0 [pid ...]";
printf "PID\tRSS\tSHARED\tNONE_SHARED\n";
for my $pid (@ARGV) {
open my $fh, "< /proc/$pid/smaps" or (warn $! and next);
my @rows = <$fh>;
my $rss = mem_size_fetcher('Rss',@rows) or next;
my $shared = mem_size_fetcher('Shared_Clean',@rows) + mem_size_fetcher('Shared_Dirty',@rows);
printf
"%d\t%d\t%d (%d%%)\t%d\n",
$pid,
$rss,
$shared,
int(($shared / $rss) * 100),
($rss - $shared),
}
sub mem_size_fetcher {
my ($target,@rows) = @_;
my $mem_size = 0;
for my $row (@rows) {
my ($mem) = $row =~ /^$target:\s*(\d+)/i;
$mem_size +=($mem||0);
}
return $mem_size;
}
> NONE_SHAREDのkb数が子プロセス単独のメモリ使用量
>
> なお、リクエストの度にメモリリークとかいろいろで子プロセスは太る傾向にあるから、ある程度リクエスト流して、MaxRequestsPerChildの上限近いプロセスで計算する必要があるみたい。
### 2014-12-23 (@gotyoooo)
[サーバ障害時のトラブルシューティング ~クリスマスイブでも早く帰ろう~ - Qiita](http://qiita.com/gotyoooo/items/cc3634715deb31a80570)
>```bash:check_apache_memory.sh
# !/bin/sh
MEMTOTAL=`grep 'MemTotal' /proc/meminfo | awk '{print $2}'`
UNIT=`grep 'MemTotal' /proc/meminfo | awk '{print $3}'`
>
PARENT_PID=`ps auxw | grep httpd | grep root | grep -v grep | awk '{print $2}'`
PARENT_MEM=`grep 'VmHWM' /proc/${PARENT_PID}/status | awk '{print $2}'`
>
PID=`ps auxw | grep httpd | grep -v root | awk '{print $2}'`
COUNT=0
CHILED_MEM_TOTAL=0
CHILED_MEM_TOTAL_NO_SHARE=0
>
echo -e "[apacheプロセスメモリ使用量]"
echo -e "(親プロセス)"
echo -e "PID\tMEM"
echo -e "${PARENT_PID}\t${PARENT_MEM}${UNIT}"
echo -e "(子プロセス)"
echo -e "PID\tMEM\tSHARED\tPRIVATE"
for pid in $PID
do
#cat /proc/$pid/status | egrep '(^Pid:|VmHWM)'
#メモリ使用量
PMEM=`grep 'VmHWM' /proc/${pid}/status | awk '{print $2}'`
#共有メモリ使用量
SHARE_MEM=`awk 'BEGIN{shared=0;}/Shared/{shared+=$2;}END{printf("%d",shared);}' /proc/${pid}/smaps`
#プライベートメモリ使用量
PRIVATE_MEM=`expr $PMEM - $SHARE_MEM`
#メモリ合計計算
CHILED_MEM_TOTAL=`expr $CHILED_MEM_TOTAL + $PMEM`
CHILED_MEM_TOTAL_NO_SHARE=`expr $CHILED_MEM_TOTAL_NO_SHARE + $PRIVATE_MEM`
>
#カウントアップ
COUNT=`expr $COUNT + 1`
echo -e "${pid}\t${PMEM}${UNIT}\t${SHARE_MEM}${UNIT}\t${PRIVATE_MEM}${UNIT}"
done
>
# 平均値計算
CHILED_MEM_AVE=`expr $CHILED_MEM_TOTAL / $COUNT`
CHILED_MEM_AVE_NO_SHARE=`expr $CHILED_MEM_TOTAL_NO_SHARE / $COUNT`
>
echo -e "子プロセス数 \t\t\t: ${COUNT}"
echo -e "子プロセスメモリ使用量合計 \t: ${CHILED_MEM_TOTAL} ${UNIT}"
echo -e "子プロセスメモリ使用量平均 \t: ${CHILED_MEM_AVE} ${UNIT}"
echo -e "子プロセスメモリ使用量合計(共有除く) \t: ${CHILED_MEM_TOTAL_NO_SHARE} ${UNIT}"
echo -e "子プロセスメモリ使用量平均(共有除く) \t: ${CHILED_MEM_AVE_NO_SHARE} ${UNIT}"
>
echo "=============================================================="
USE_MEM=`expr $PARENT_MEM + $CHILED_MEM_TOTAL_NO_SHARE`
echo -e "apacheメモリ使用量 \t: ${USE_MEM} ${UNIT}"
echo -e "総メモリ量 \t\t: ${MEMTOTAL} ${UNIT}"
2016-01-07 Amazon AWS
Amazon EC2 での Apache メモリのチューニング
5.以下のように設定変数 ServerLimit と MaxClients(または Apache 2.4 の場合は MaxRequestWorkers)の値を計算します。
a. インスタンスの RAM が 4 GB を超える場合は、Apache プロセスの平均 %MEM 値で
90% を割ります。たとえば、平均 %MEM 値が 0.8% だとすると、90% (0.9)を 0.8%(0.008)で割ります。
結果は 112.5 になり、小数点第 1 位で四捨五入して整数にします。この場合は、112 になります。
b. インスタンスの RAM が 4 GB 以下の場合は、Apache プロセスの平均 %MEM 値で
80%. たとえば、平均 %MEM 値が 0.8% だとすると、80% (0.8)を 0.8%(0.008)で割ります。
結果は 100 になります。
注
これらの値は、インスタンスが専用のウェブサーバーであると想定して計算されます。サーバーで他のアプリケーションをホストしている場合は、この計算を行う前に、90% または 80% のいずれかから、これらのアプリケーションの合計メモリ使用量の割合を引きます。RAM が 4 GB 以下のインスタンスで、Apache に加えて他のアプリケーションを実行している場合は、パフォーマンスが低下することがあります。