はじめに
みなさん、Gemini 1.5 pro を覚えていますでしょうか。
こちらは、2024年の2月16日にGoogleが発表したLLMです。
このLLMが発表されてから1ヶ月以上経った今、
新しい技術が次から次に現れています。(例えば Claude 3 など)
この記事では、Gemini 1.5 pro に再度フォーカスを当てて、
「Gemini 1.5 proのここがすごい!」
という点をまとめて伝えたいと思います![]()
特長
1.MoEアーキテクチャ
Gemini 1.5 pro では、自然言語処理において 「MoEアーキテクチャ」 を採用しており、特に大規模なデータセットに対する理解と処理能力が高いという特長があります。
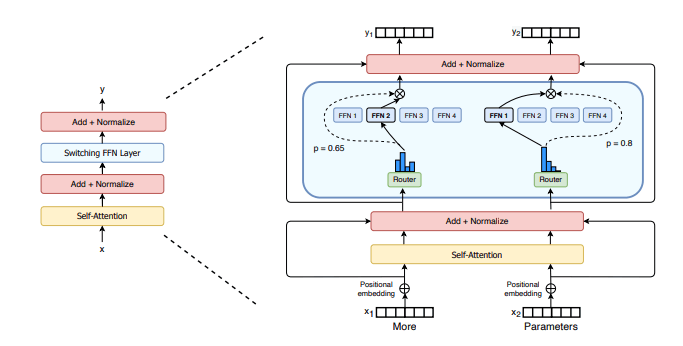
このアーキテクチャは、クエリを受け取るたびにモデル全体を実行する従来の大規模ニューラルネットワークとは異なり、
「エキスパート」ネットワークに分割されており、処理能力の関連する部分だけを使用して、適切な回答を生成できます。
要するに、「特定のタスクに特化した、多数の専門家がいる構造」になっています。
2.大規模なコンテキストウィンドウ
Gemini 1.5 Proの標準コンテキストウィンドウは12万8000トークンですが、初期のテスターは最大 100万トークン 入力可能のGemini1.5を利用できます。
100万トークンとは、具体的に以下のものに匹敵します。
- 「1時間のムービー
 」
」 - 「11時間の音声
 」
」 - 「3万行以上のコード
 」
」 - 「70万語以上のテキスト
 」
」
従来のLLMでは、大規模なデータをインプットする際、コンテキストウィンドウにあわせて文書を分割するチャンクが必要ですが、Gemini 1.5 Proであればその必要性は最小限になります。
できることの例
特長を踏まえ、このLLMができることについて、3つ紹介します。
1. 一冊の教科書をアップロードし、その内容について質問/回答する
まず初めにご紹介するのは、生物学の教科書を一冊丸々アップロードし、教科書の細かい部分の質問をする、というものです。入力量は491,002トークンで、一度にコンテキストウィンドウで読み込むことができます。また、質問に対する回答も100%正しいものになりました。
2. 動画をアップロードし、中身を要約する
次にご紹介するのは、30分の動画を与えて、その内容を要約する、というものです。入力量は約500,000トークンとのことでした。結果、要約した内容を整理して生成しています。
3. 複数の論文をアップロードし、その中から質問の答えを見つける
最後にご紹介するのは、研究論文6冊分、48,904文字のプロンプトを与え、そのうちの2冊目の細かい部分の質問をする、というものでした。結果、完璧に正しい回答を出力しています。
LLM比較
では、他のLLMと比較してみましょう。
4つのLLM( GPT-4 , Gemini 1.0 , Gemini 1.5 , Claude 3 )において、
入力可能トークン数と入力媒体の比較を以下のように行ってみました。
| GPT-4 | Gemini 1.0 | Gemini 1.5 | Claude 3 | |
|---|---|---|---|---|
| 入力可能 トークン数 |
128,000 tokens | 32,000 tokens | 1,000,000 tokens | 200,000 tokens (※問い合わせ次第で1,000,000 tokens) |
| 入力媒体 | テキスト 画像 音声 |
テキスト 画像 動画 音声 |
テキスト 画像 動画 音声 |
テキスト 画像 |
上記の表からわかるように、コンテキストウィンドウの大きさは特徴的ですね。また、動画などを入力できる点がユニークであるといえます。
まとめ
以上、Gemini 1.5 proについて、まとめました。
Gemini 1.5 proは、以下の2点に主に強みがあるといえます。
- コンテキストウィンドウが大きく、大規模な文書・動画の入力などが可能
- 膨大なプロンプトから、適切な回答をしてくれる
Gemini 1.5 pro のような大きなコンテキストウィンドウを持つLLMが今後広がれば、社内文書を参照する独自のRAGなども必要なくなるのではないかという議論も出てきています。
【参考】ロングコンテキストRAGに向けたアーキテクチャ
このようなロングコンテキストLLMに対応したRAGの新たなアーキテクチャについての記事がありましたので、そちらに関しても簡単に紹介します。
以下、参考にさせていただいたサイトです。
ロングコンテキストLLMが解決できること
ロングコンテキストLLMが解決できる、RAGの課題点については以下の4点です。
1. チャンクの調整の必要がなくなる
- ネイティブでの大きなチャンクサイズが使え、チャンク分割の決定が不要になる
- ドキュメント全体やページグループ単位の分析が容易になる
2. 思考連鎖エージェントの調整の必要がなくなる
- 小さなチャンクでは複数の要素にまたがる分析が難しかったが、1回の呼び出しで可能に
- 人工知能による考えながらの行動の必要がなくなる
3. 要約が容易になる
- これまでは複雑な手順が必要だったが、1回の呼び出しで要約可能に
4. パーソナライズされた記憶の構築が向上する
- 十分な背景コンテキストを読み込めるので、コンテキスト維持が容易に
- 開発者の手間が大幅に軽減される
つまり、ロングコンテキストLLMの導入により、チャンク分割、複雑な要素分析、要約生成、会話コンテキスト維持など、様々な面での改善が期待できるということです。
ロングコンテキストLLMが解決しないこと
ロングコンテキストLLMで解決しないことについては以下の4点です。
1. 1Mトークンは大規模な文書コーパスには十分ではない
- GBやTBスケールの企業知識コーパスへの適用が困難
- データ取得方法の工夫が開発者に求められる
2. 埋め込みモデルのコンテキスト長が短い
- 埋め込みモデルで扱えるコンテキストの最大長は、together.aiの32,000トークン程度が限界
- 埋め込みモデルは長文処理能力が低いため、LLMで扱う際に前処理として、テキストをかなり小さな単位に分割しなければならない
3. コストとレイテンシー
- 1Mトークンの処理に最大60秒、0.5$~20$のコストがかかる
- 将来的には改善が見込まれるものの、現状は高コスト・長レイテンシー
4. KVキャッシュの問題
- 1Mトークンでキャッシュに100GBのGPUメモリを消費
- アクティベーションの順序依存性があり、柔軟なキャッシュ運用が困難
つまり、RAGではロングコンテキストLLMの能力を最大限に生かせておらず、コンテキスト長、コスト、キャッシュ効率など、大規模知識ベース適用に向けた技術的課題が残されていると言えます。
ロングコンテキストLLMに対応したRAGの新アーキテクチャ
ロングコンテキストLLMを最大限活用するRAGの新アーキテクチャとして、提案されているものを3点紹介します。
 Small-to-Big Retrieval
Small-to-Big Retrieval
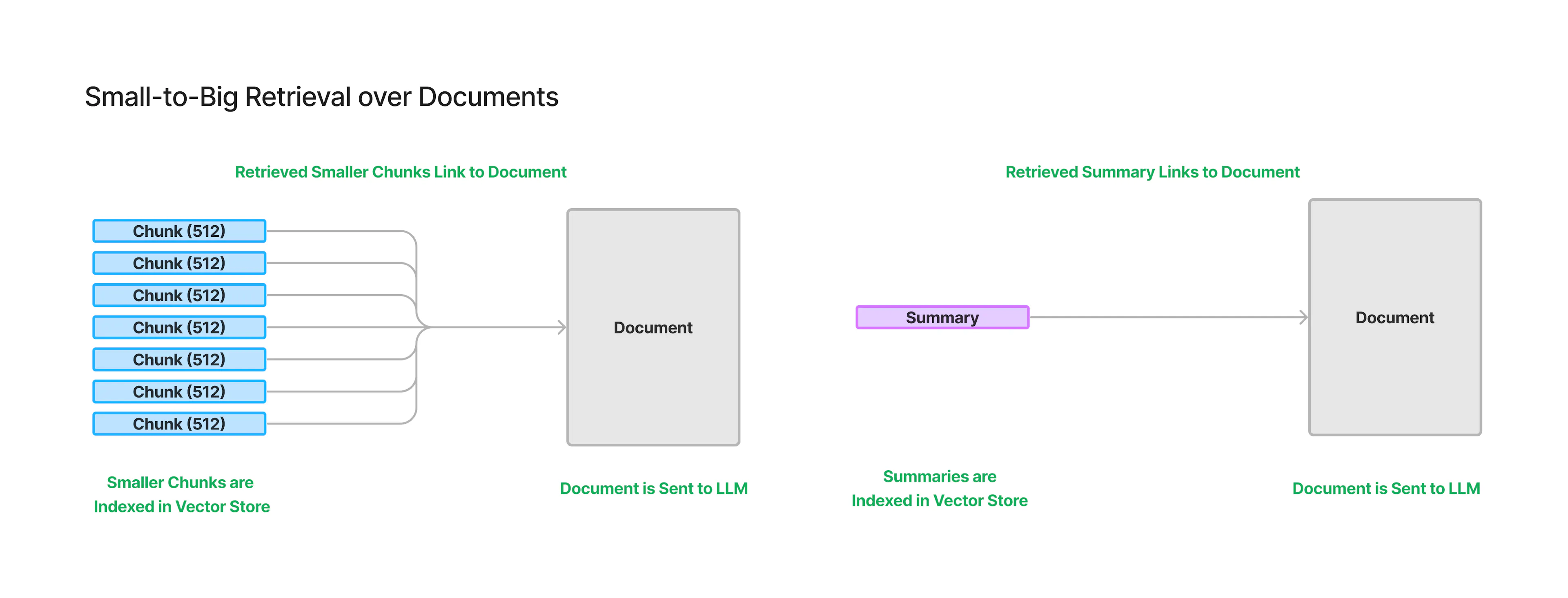
大規模な知識ベースから情報を検索する際、長文のコンテキストを扱える大規模言語モデル(LLM)を使うには、「Small-to-Big Retrieval」という手法をとるべきです。
この手法は、次の2ステップからなります。
- 文書を小さなチャンクに分割し、それぞれの埋め込み表現をインデックス化する
- 各小さなチャンクを、より大きなチャンク(例えば元の文書全体)にリンクさせる
また、小さなチャンクを使う理由は 2 つあります。
- 現在の埋め込みモデルは、大量の文章を一度に処理するのが苦手なので、文章を小さなチャンクに分けてそれぞれを埋め込む必要がある
- ドキュメント全体に1つの埋め込みを割り当てるよりも、ドキュメントを小さなチャンクに分けて複数の埋め込みを作った方が、関連する情報を見つけやすくなる(ドキュメント全体の埋め込みには情報が過密に詰まりすぎてしまうため)
小さなチャンクごとに埋め込みを作ることで、モデルの能力の限界を補い、より適切な情報検索が可能になるということです。
つまり、大規模知識ベースからの検索には、小さなユニットの埋め込み表現を利用しつつ、最終的には元の大きなコンテキストにアクセスできるようにする「Small-to-Big Retrieval」が有効であると言えます。
 Intelligent Routing for Latency/Cost Tradeoffs
Intelligent Routing for Latency/Cost Tradeoffs
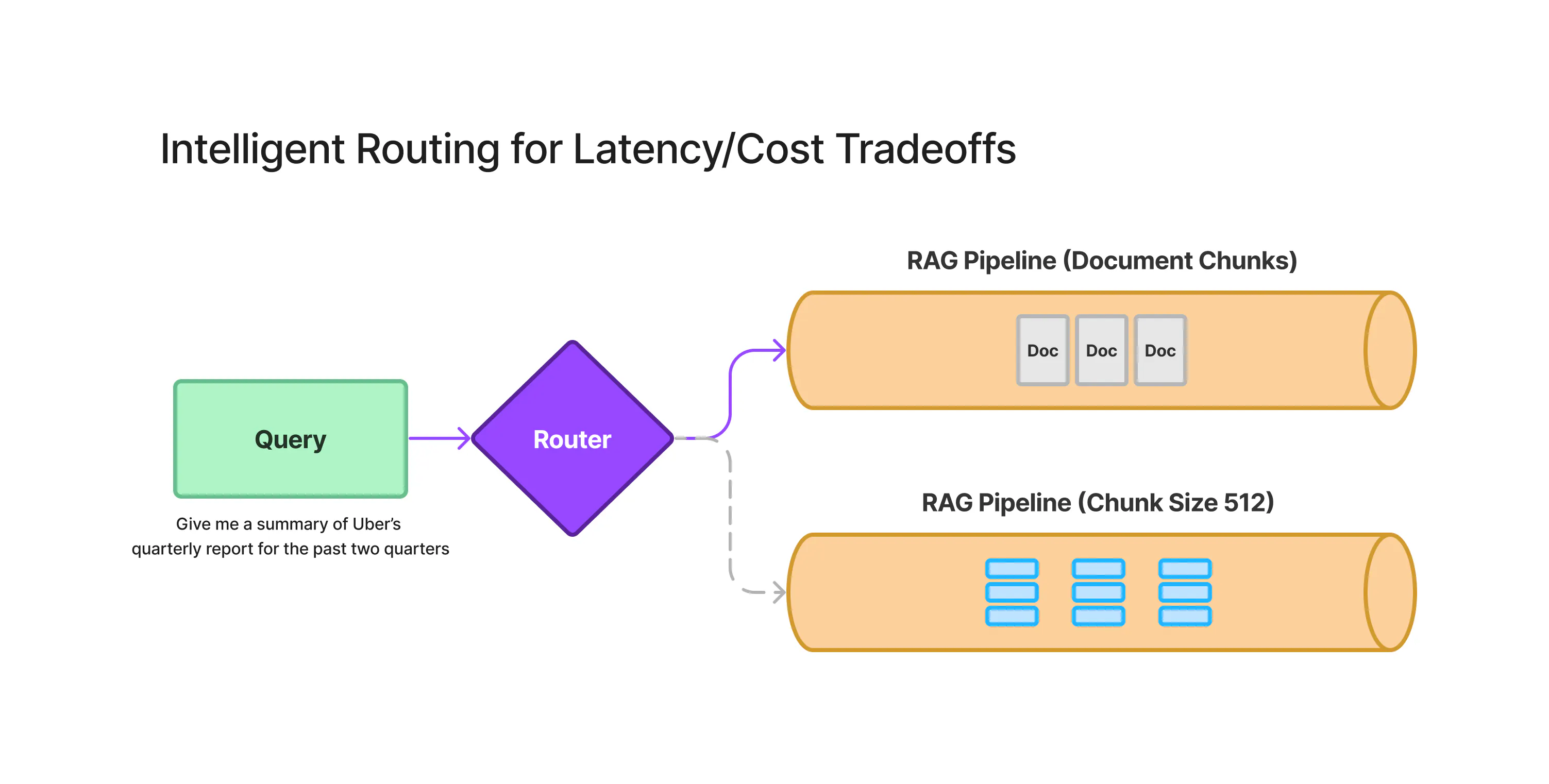
ロングコンテキストLLMの登場により、各ユースケースに適したコンテキストの量や取得方法を適切に選択する必要性が高まっています。
ロングコンテキストLLMには高いコストとレイテンシーがあるため、すべての質問に適しているわけではありません。一方で、従来の検索エンジンと言語モデルを組み合わせたRAGなどの手法も存在します。
そこで、賢いルーティング層を設け、与えられた質問に応じて、最適な検索・言語モデルの組み合わせ方を自動で選択することが提案されています。
この層がコストと遅延を考慮して最適な戦略を選べば、単一のインターフェースで様々な種類の質問に効率的に答えられるようになります。コストを抑えつつ、質の高い回答を得ることができるようになる可能性があります。
 Retrieval Augmented KV Caching
Retrieval Augmented KV Caching
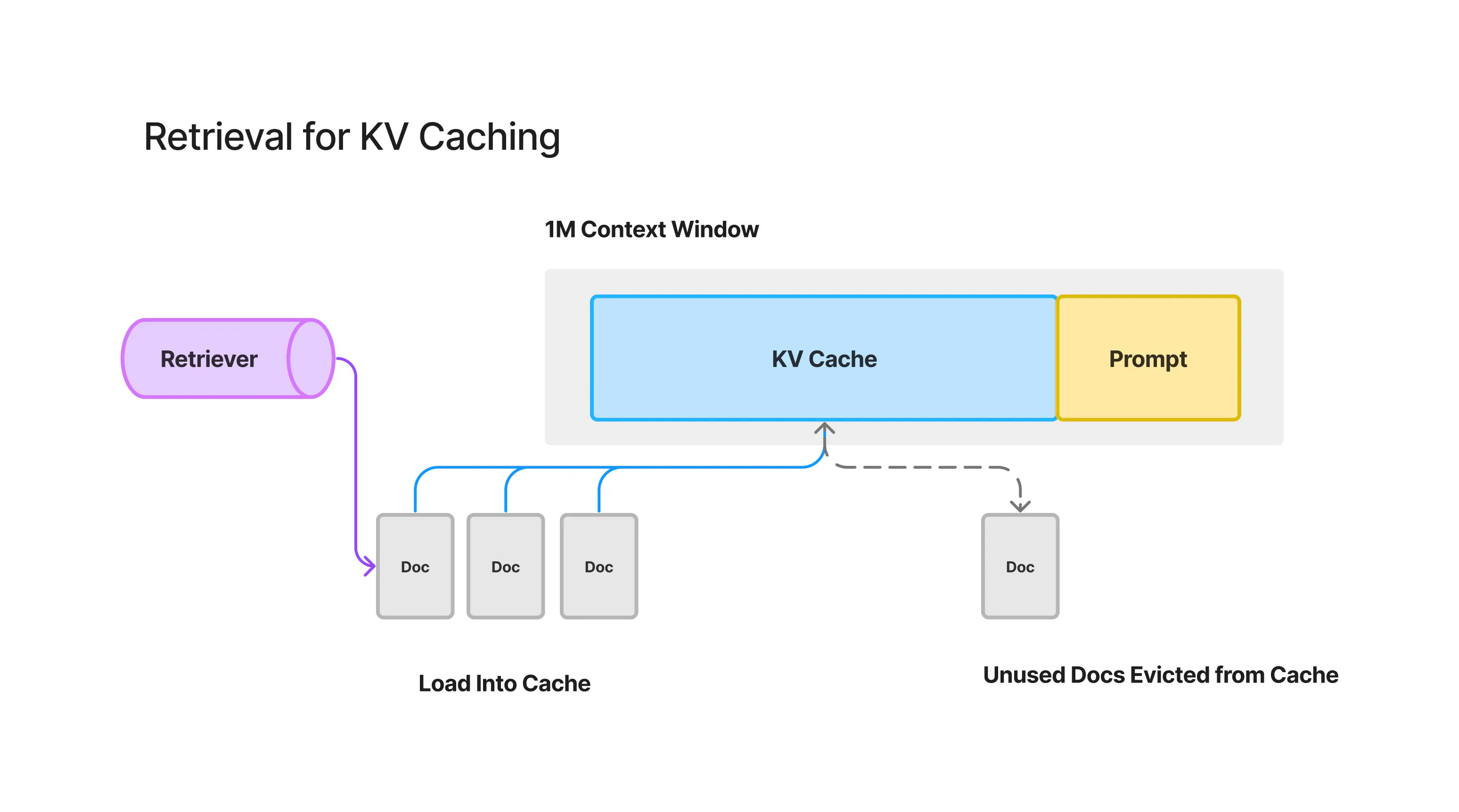
現在、Googleや他の企業は、レイテンシーとコストを削減するため、「KVキャッシュ」と呼ばれる技術の最適化に取り組んでいます。
KVキャッシュは、ドキュメントのトークン情報を一時的に保存しておくことで、言語モデルが同じ情報を繰り返し計算する手間を省きます。
しかし長文のドキュメントの場合、キャッシュの使い方に工夫が必要です。「Retrieval Augmented Caching」と呼ばれる手法で、キャッシュ済み情報と、ユーザーにとって関連性の高い新しい情報を組み合わせる方法が検討されています。
キャッシュ済み情報の位置が重要なため、従来のキャッシュアルゴリズムをそのまま使うことはできません。キャッシュと検索を上手く組み合わせる新しいアルゴリズムが必要とされています。
最適なKVキャッシュの使い方については、APIなど具体的な規定はまだ決まっていません。技術の進化に合わせて対応が必要となります。
要するに、大規模言語モデルの高速化と低コスト化に向けて、キャッシュと検索の賢い組み合わせ方が模索されている、という状況です。
さいごに
今回、Gemini 1.5 pro について、この記事でお話ししました。
現在未だ限定リリース中で、テストユーザーのみが実際に触って動かせるものです。
今後 一般の方向けに公開された際、利用者はどんな使い道を見出すのか、今後がとても楽しみです。