以前会社で使ったリソースをそのままアップロードします
特に、「閾値(シックスシグマなど)では、統計データを分離出来ない場合」、
または、「評価値が外的要因で常時変動する場合」
こうした解析方法は役立ちます
対象とするデータ
紙に、微妙に直径が異なる円と潰れた円を印刷しておく
粒子解析(ブロブ解析)を使用すると、円の部分だけを抽出して、円の座標と直径(フェレ径に相当)を出してくれる。

その直径を混合したデータが、Excelデータで保存され、くり抜いた画像がbitmapデータで保存される。

緑に囲われたデータが、実際に検出したエリア。
そのCSVファイルはこうなっている
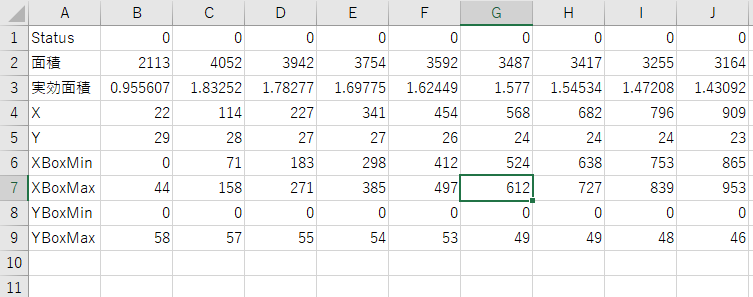
ここにある「実効面積」は、小さい円と大きい円が混ざったデータとなっているので、このデータからどのような分布が混在しているかを調べたい。
なお、水準数Mは固定とする
参考サイト
広島大学 栗田先生の教材
アルゴリズムの整理
EMアルゴリズムで実装する
初期値
ガウス分布の水準iの分布の混合率、平均、分散を$ \alpha_i, \mu_i, \sigma_i^2 $とすると、その正規分布の密度関数は
p_i(x) = \frac{1}{\sqrt{2 \pi \sigma_i^2}} \exp[ - \frac{(x-\mu_i)^2}{2\sigma_i^2}]
ここで定義された$ \alpha_i, \mu_i, \sigma_i^2 $は初期値のパラメータとして与えて置く
Eステップ
この分布の値から、kをデータ番号とすると、
全体に対する各データに対する暫定の混合率$a_j(x_k)$、平均$u_j(x_k)$と分散$v_j(x_k)$を出すことが出来るので
a_j(x_k) = \frac{p_j(x_k)}{\sum_{i=0}^{M} p_i(x_k)} \\
u_j(x_k) = a_j(x_k) \times x_k \\
v_j(x_k) = a_j(x_k) \times (x_k - \mu_j)^2
Mステップ
Eステップから求めた値を使用して、$ \alpha_i, \mu_i, \sigma_i^2 $を更新する。
データ数をNとすると
\alpha_i = \frac{\sum_{k=0}^{N} a_i(x_k)}{N} \\
\mu_i = \frac{ \sum_{k=0}^{N} u_i(x_k)}{\sum_{k=0}^{N} a_i(x_k)} \\
\sigma_i^2 = \frac{ \sum_{k=0}^{N} v_i(x_k)}{\sum_{k=0}^{N} a_i(x_k)} \\
なお、推定粒子数はここから出てきた結果
N_i = \alpha_i \times N
で計算する。
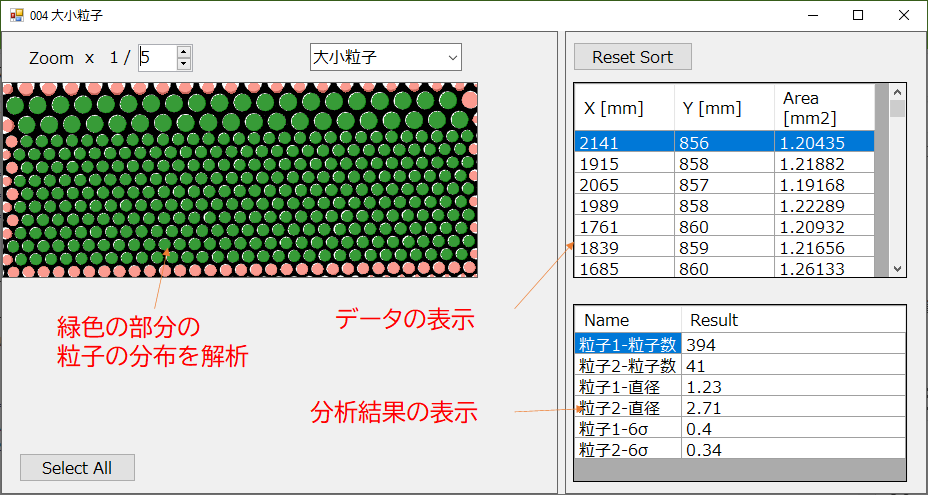
実行結果
デモプログラムより
ソースコード
展示会はVisual Studio 2013の開発環境でC#にて実施
アルゴリズムの部分コードはこちら