はじめに
はじめまして。Kyashでサーバサイドエンジニアを担当しているhirobeです。
Kyash Advent Calendar 2022の12/3担当分です。
最近は技術基盤を整理することが多いのですが、やりたいことを実現する上でgraceful shutdown可能な非同期リトライするGoライブラリが必要になり、1週間ほどで実装し、OSSとして公開しました。
今現在のステータスとしては、本番環境で利用するためにQAをしているところです。2022年中にはKyashの本番環境にて使われることは間違いないと思います。 今現在のステータスとしては、Kyashの本番環境で実際に利用されています。
実装する前に既にそのようなOSSがあるかざっと調査したのですが、なさそうでした。OSSの機能の詳細は後ほど紹介しますが、「君のやりたいことはこのOSSで既にできるぞ」といったツッコミも歓迎します。
便利だと思ったら使ってくれると非常に嬉しいです!
レポジトリは以下です。
なぜ必要になったか
なぜ必要になったかの説明から入った方が、このライブラリを使うユースケースとかどのような機能を持っていると嬉しいか等、わかりやすいと思うので、まずはその辺りから説明します。
ユーザが決済をした際に、何らかの条件を満たしたユーザには何らかのインセンティブを付与したいとします。
この時、決済処理を行うコードで、条件判定、インセンティブ付与までしてしまっても間違いではないのですが、当然決済スピードに影響しますし、決済処理を行うロジックにインセンティブ付与という本来は関係のないドメイン知識が染み出してしまい、保守性の面でも好ましくありません。
そこで、Kyashでは、決済を担当するマイクロサービスではAWSのSNSへのメッセージ送信のみ行うようにしています。SNSに紐づいている各マイクロサービスに存在するSQSにメッセージが伝播され、インセンティブを担当するマイクロサービスでSQSをpollingして実際の条件判定、インセンティブ付与を行うようにしています。
このように、メッセージを複数のキューに送ることをFanoutといい、SQSに直接メッセージを送るのではなく、SNSを間にかませるのがデザインパターンとなっております。1
実際に本番環境で運用したところ、SNSへの送信に稀に非常に時間がかかることがわかりました。
具体的には、中央値18ms、99パーセンタイルでも80msと十分高速なのですが、最大で確認すると毎日1件くらい5秒以上かかっていることがありました。以下は最大値をとった様子です。
なお、AWSのSDKはcontext.Contextを渡せるようになっており、私達のコードでもタイムアウト付きで渡している箇所が多く、8秒以上かかっているケースにおいてはタイムアウトしているようでした。なので処理に時間がかかっているというよりはネットワーク等の何らかの理由により処理がハングしてしまっていたのではと思います。
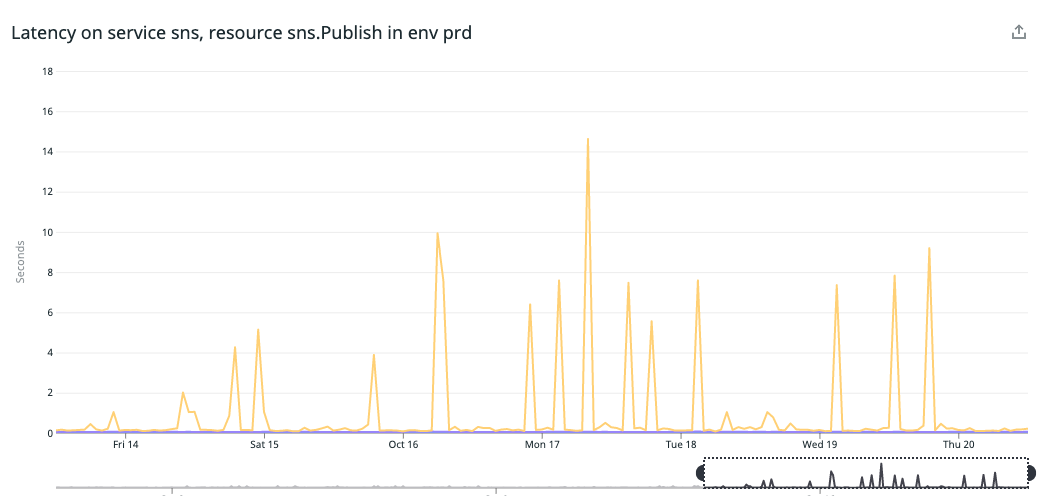
稀とはいえ、この遅延起因で決済が失敗するのはユーザ体験が非常に悪いので、何らかの対応をしないといけません。どのように対応するのが良いでしょうか。
案1: 別のGoルーチンでSNSへ送信する
まず、思いつくのは、送信処理を別のGoルーチンで行うことです。
単純で楽ですが、graceful shutdownできないという問題があります。Go標準ライブラリのnet/httpのShutdownやgRPCのGracefulStopはリクエストを処理しているGoルーチンの完了は待ってくれますが、処理中に作られたGoルーチンは当然のことながら待ちません。デプロイ等が走った時にSNSへ送信中の処理は強制的に終了される可能性があります。
とはいえ、ここを解決するには何らかの仕組みが必要になります(結局その仕組みを作ったわけですが)。
案2: 3秒ほどのタイムアウトで同期的に処理し、失敗した場合はエラーログを吐いた後、非同期にリトライする
案1がよろしくなかったのは非同期にしているからだったので、初回だけは同期的に呼ぼうというアイデアです。エラーログを吐くところまでが同期的な処理のセットであることに注意してください。
99パーセンタイルでも80msなので3秒でほとんどの場合は同期的に成功します。そして、タイムアウトしても決済の処理は3秒の遅延がありつつも成功することがポイントです。
KyashではDatadogにてログレベルに応じて監視できるようにしており、エラーのログレベルでロギングした場合はエンジニアがすぐに検知し、対応できるようになっています。今回のケースで言えば、エンジニアはこのエラーログを検知して、該当の送信処理が最終的にはリトライによって成功したことを確認すれば良いです。数回のリトライをしても処理が失敗する可能性はAWS障害時とデプロイ時以外はほぼゼロなので、基本的には成功の確認をして対応としては終わりでしょう。
一見悪くない案に思えるのですが、運用を考えるとキツいでしょう。3秒に設定した場合は1日に1回はタイムアウトすることが予測され、エンジニアがこのエラーログを毎日確認する必要が生じてしまいます。ほとんどの場合は成功を確認するだけで済むとはいえ、エラーログの頻度が多いと確認が形骸化してしまう可能性があります。
ということで、自作することにしました。
少々長くなりましたが、このように非同期で処理を行いたいがgraceful shutdownができないので正確な挙動が必要な処理には非同期処理が使えない、といったケースは割と多くあるのではと思います。
今回作ったライブラリはそこを解決するライブラリですが、それ以外にも細かい考慮がされていたりします。その辺りを次章で説明します。
どのような機能か
実は、テストコードを除くとコード全体で300行ほどしかないのでソースを読んでしまった方が速い方もいるかも知れません。
とは言え、実装としてはなかなか難しいものになっており、また意図がわからないのもあると思うので簡単に紹介します。
インタフェースとしては以下のようになっています。
type RetryableFunc func(ctx context.Context) error
type FinishFunc func(error)
type AsyncRetry interface {
// Do calls f in a new goroutine, and retry if necessary. When finished, `finish` is called regardless of success or failure exactly once.
// Non-nil error is always `ErrInShutdown` that will be returned when AsyncRetry is in shutdown.
Do(ctx context.Context, f RetryableFunc, finish FinishFunc, opts ...Option) error
// Shutdown gracefully shuts down AsyncRetry without interrupting any active `Do`.
// Shutdown works by first stopping to accept new `Do` request, and then waiting for all active `Do`'s background goroutines to be finished.
// Multiple call of Shutdown is OK.
Shutdown(ctx context.Context) error
}
使い方の基本としては、Doにて非同期処理をf、その結果をハンドリングする処理をfinishとして引数として渡します。shutdown時にはShutdownを呼びます。
graceful shutdown
大まかな挙動としては、net/httpのShutdownやgRPCのGracefulStopと同様かと思います。
Shutdownを呼ぶと新規のDoを拒否するようになりますが、現在実行中の処理が終了するのを待ってくれます。その「現在実行中の処理」にRetryableFuncの実行だけでなく、FinishFuncの実行も含まれていることがポイントです。FinishFuncの実行も待ってくれるので、エラーが起きた際にロギングするなどしてエンジニアに気付かせるチャンスがあることが保証されます。
Shutdownのinterfaceとしては、Shutdownの呼び出しはすぐにreturnしてしまって、完了時に通知されるchan errorを返した方が便利な気がしたのですが、net/httpやgRPCがそうなっていないので関数呼び出しが現在実行中の処理が終了するまでブロックされるようにしています。
Shutdownが呼ばれた際に、リトライ処理がどうなるかは再送のところに書きます。
リトライ
リトライ関連の処理は完全にhttps://github.com/avast/retry-go に委譲しています。このライブラリはGoのリトライライブラリの中では一番気に入っています。今回がっつり使わせてもらう際にバグを発見してContributeできたので良かったです。
https://github.com/avast/retry-go の機能としてはざっと以下の通りです。
- 試行回数を指定できる
- exponential backoff と jitterにて再送され、調節できる
- 毎回の試行前に挟みたい処理を指定できる
- リトライしたいか否かの判定をerrorをもとに判断する関数を指定できる
-
context.Contextを指定することができ、そのcontextをキャンセルすると、次回の再送を試みずに失敗として処理終了する
他にも機能がありますが、主な機能はこのあたりでしょう。
作ったライブラリでも上記を指定できるようになっています。
箇条書きの最後のみ補足すると、Shutdownが呼ばれた時、およびContext(ctx context.Context)というOptionで指定されたcontextがキャンセルされた時に、https://github.com/avast/retry-go に渡したcontextをキャンセルするような実装になっています。つまり、次回のリトライを中断し、即座に終了します。
graceful shutdown可能とはいえ、プロセスが動いているプラットフォームがshutdown処理を永遠に待つことはあり得ず、例えばAWSのECSのデフォルトでは、SIGTERMシグナルの送信後30秒後にSIGKILLシグナルが送信されます。
Shutdownが呼ばれたら次回のリトライを中断すべきという判断です。
context.Context
ややこしいですが、ここでのcontextはOptionで指定されたcontextではなく、Doの第一引数のcontextを指します。
ここで指定されたcontextは、 第二引数のRetryableFunc func(ctx context.Context) errorを呼び出すときにそのまま渡されません。
指定するcontextはアプリケーションがひき回しているであろうcontextをそのまま渡せるようにデザインされています。アプリケーションで利用しているcontextは多くの場合、サーバがリクエストを受けてからレスポンスするまでをライフサイクルと見做し、レスポンスを返したらキャンセルされることが多いでしょう。例えば、request.Contextはそのような挙動になっています。
非同期リトライで行いたいタスクは当然のことながら、このライフサイクルと同じでは困るので、cancelが伝播されないようにライブラリが工夫しています。
一方、contextに紐づいているValueは維持できているべきなので、Valueを維持しつつ、cancelが伝播されないよう https://github.com/Kyash/async-retry/blob/main/without_cancel_ctx.go にて実装しています。
この処理自体は、数年前にWebのどこかで自分が見つけた実装なのですが、やりたいことに比べて実装がテクニカルすぎる気がするのですが、もっと自然な実装方法があれば教えて欲しいです。
[2023/4/20追記]
先日、https://github.com/golang/go/commit/1844b541664525a0298603154915e74ca742e406
にて 全く同じ関数名で、本家にWithoutCancelが追加されたようです! そっちを使ってください!
なお、たまに紐づいているValueのkeyをハードコーディングして移し替える処理を見かけますが、保守性が悪いですし、ましてやライブラリがcontextに詰め込んでいるものまで把握するのは難しい2ので止めるべきだと思います。
最後に、Optionで指定されたcontextがキャンセルされた場合はRetryableFunc に渡しているcontextをキャンセルするようになっています。一方、Shutdown時にはキャンセルしません。
これは、Optionで指定されたcontextがキャンセルされたということはアプリケーションが処理をキャンセルしたいと判断したと推測されるので、現在実行中の処理もキャンセルできるならした方が好ましいだろうという判断です。デフォルトの挙動はこのようになっていますが、いずれもOptionで変更可能です。
| Shutdownが呼ばれた時 | Optionで渡したcontextがキャンセルされた時 | |
|---|---|---|
RetryableFuncの引数のcontext |
キャンセルされない(変更可能) | キャンセルする(変更可能) |
| retryの挙動 | 次回のretryを中止 | 次回のretryを中止 |
少々、この辺りややこしいので整理すると、こんな感じです。
「次回のretryを中止」を正確に書くと、RetryableFunc実行中であれば実行終了時に成功失敗に関わらず処理を終了、次回のretryに向けてinterval中であったら待つのを止めて終了となります。
timeout
Timeout(timeout time.Duration)というOptionでタイムアウトが指定できます。
これは各retry時にライブラリがtimerをセットします。
recover from panic
教科書的にはrecoverをするなと言われていますが、GoではいずれかのGoルーチンがpanicするとプロセスごと死ぬのでWebサービスではrecoverをするべきだと思います。
ginなどのフレームワークやgRPCのmiddlewareでrecoverを指定していても、リクエスト処理をしているGoルーチン以外については自前でrecoverをする必要があり、漏れがちです。ライブラリでは内部的にrecoverをしています。
おわりに
「graceful shutdown可能な非同期リトライをする」のは一見簡単そうに見えるのですが、考慮すべきことが多く、また非同期処理ならではの実装の難しさがありました。
OSSとして公開するのは、Kyashのサーバサイドとしては初めての試みですが、使ってくれる人が増えたり、contributeしてくれたり、採用にプラスになったらいいなーと思っています。
Kyashに興味ある方は以下よろしくお願いします!
-
SNSを間に挟むようにしたのも自分が最近やったタスクの一つです。StandartなSNSにはStandardなSQS、FIFOなSNSにはFIFOなSQSしか紐づけられないということを知り、おっ!?となりました ↩
-
例えば、https://qiita.com/behiron/items/cc02e77ed41103f4a195 に書いたように、DatadogやOpenTelemetryライブラリの実装では、contextにbaggage、tracingの情報を積めることで機能を実現しています ↩