はじめに
7年ぶりくらいにアルゴリズムとデータ構造を勉強し直しています。
シェルソートなんてものもあったなーと名前すら忘れているアルゴリズムもあったりと、良い復習になったのですが、ソートに関していうと、様々なソート手法を紹介した後に、「言語の標準のソート実装はクイックソートがベースになっていることが多いです」で説明が終わっていることが多い気がします。
Goのソート実装がどのようになっているか気になり実装を確認したのでまとめたいと思います。
Goは通常のSortと安定ソート(同じ値が元順序を維持する制約がつくもの)であるStableを提供しますが、Sortのみ取り扱います。
Sort実装はクイックソートとヒープソートとシェルソートを柔軟に使い分けてます。それぞれのソート手法のポイントを簡単に説明したうえで最後にGoのSort実装を紹介したいと思います。
クイックソート
ポイントはなんといってもpivotの選択と部分ファイル(pivotをもとに分割されたファイルを指す)の構築方法です。
pivot
単純に端の要素をpivotとしてしまってはソート済み配列の場合 O(N^2)になってしまうのは有名です。そこで対象配列からランダムにpivotを選択するなど工夫をすることでO(NlogN)を保証するようにする必要があります。
ここでは、Goの実装でも使われている、John Tukeyさん考案のnintherを紹介します。
発表論文は残念ながら無料での閲覧はできなかったので、 https://www.johndcook.com/blog/2009/06/23/tukey-median-ninther/ を参考にします。
「クイックソートのpivot選択」という目的から一旦離れて、nintherがそもそもどのようなものかを説明したいと思います。
nintherは9つの数字のmedianの推定量として3つの数字のmedianをとり、そのmedianをとったものを指します。9つの数字がソート済みであればこれは真のmedianと等しくなりますが、ソート済みでない場合は等しくなるとは限りません。
例えば3,1,4,4,5,9,9,8,2の場合はnintherは5になりますが、真のmedianは4です。
ninther(3,1,4,4,5,9,9,8,2) = median(median(3,1,4), median(4,5,9),median(9,8,2)) = 5
データの中心となる値を知りたい(まさにクイックソートのpivotのように)ときにまず思い浮かぶのは平均をとることでしょう。平均であれば追加のメモリ不要でO(N)で計算できます。が、平均は正規分布のような理想的な分布では問題なく実体と乖離しないのですが、外れ値に弱いという特性がありロングテールな分布にはうまく推定量として機能しません。
では、medianを計算することを考えましょう。ソートして中央の位置にある配列の要素とすればいいのでO(NlogN)かかると思いがちですが、O(N)で計算できることが知られています。気になる人は、こちらがわかりやすいです。O(N)とはいえ、定数部分が無視できず高速ではない、メモリがO(N)で必要になるという欠点があります。
そこでざっくりとした推定量としてnintherが登場したのでした。「nintherをとる」と表現した場合、文脈によって指すものが変わり、わかりづらいのですが、観測する限り文脈依存で以下を指しているようです。
- データが
9M個あるとする。1ブロックM個の9ブロックについてはそれぞれ真面目にmedianを計算し、それぞれの結果を並べた9つの数列に対してnintherを取る- この場合、必要なメモリは
9M->Mに減らせたことになります。
- この場合、必要なメモリは
- 上のnintherによる推定を複数回行う
- たとえばデータが
81M個のときには、1ブロック9M個の9ブロックそれぞれについて、1ブロックM個の9ブロックそれぞれから算出したmedianをもとにnintherを取り、さらにそのnintherをとる。この場合、必要なメモリは81M->2Mに減らせたことになります。 - 同様に
729Mことの時には、729M->3Mに減らせたことになります。
- たとえばデータが
- なるべく等間隔に9つの要素を抽出し、nintherを取る操作を行う。
- 新たなメモリは不要で実装もかなり単純です。
- 3要素のmedianを取得するには2~3回の比較を伴うので、合計8~12回の比較ですむことがわかります
- 一方、普通に9要素のmedianを求めると比較回数は最大
ceil(log(9!))=19になると思われます。 - クイックソートのpivotでnintherをとると表現した場合はこちらです。
というわけで、クイックソートの場合は単純に等間隔に9つの要素を抽出し、そのnintherをpivotとします。
部分ファイルの構築
pivotとして選択された要素と同じ値を持つ要素は左右のどちらかの部分ファイルに残るのが普通です。
「pivotと比較して左右から中央にポインタを進め、お互い止まったところで要素をswapする」という流れにおいて、pivotと同じ値のときにポインタを進めるべきかそれとも止めるべきかでいうと、左右両方とも止めたほうが良いことが知られています。これは重複した要素が多数ある場合に左右のファイルの大きさがバランスされやすくするためです。極端な例として配列の要素が全て同じだった場合、pivotと同じ値の時に「左右どちらかのみ止める」「左右どちらも止めない」いずれの場合も計算量がO(N^2)になってしまうことがわかります。
以下は擬似プログラムです。簡単そうに見えて難しいです。
左から進むポインタは右端のpivotが番兵となっていますが、右から進むポインタはpivotが最小であるときのためにif (j == l) のテストが必要です。
// 配列aの[l,r]区間を対象としてa[r]をpivotとして分割する。
// 返り値をiとすると、[l,i-1][i+1,r]の2ファイルに分割する
int partition(Item a[], int l, int r) {
int i = l-1, j = r; Item v = a[r];
for (;;) {
while (less(a[++i], v));
while (less(v, a[--j])) if (j == l) break;
if (i >= j) break;
swap(a[i], a[j]);
}
swap(a[i], a[r]);
return i;
}
さらなる改良として、pivotと同じ値を持つ要素を左右のどちらの部分ファイルにも残らないようにすることができます。これを達成するよく知られた方法は、pivotと同じ値は左右の端にそれぞれ一時的においておき、左右からのポインタが交差した(上記プログラムのfor文を抜けた)後にそれらを中央にもってくることにより達成できます。
ヒープソート
ヒープソートは以下の手順にてソートします。
- 配列をヒープにする
- ヒープのルートから要素を1件ずつpopする
上記の1の計算量は実はO(N)です。そして、in-placeに実行できます(新たにメモリを必要とせずメモリを再利用できます)。単純に配列を1件ずつヒープにinsertするという手法だとO(NlogN)ですので工夫する必要があります。
ヒープの性質として1件のpopはlog(N)なので2の計算量は最悪の場合でも、log(N) + log(N-1)+...+log2+log1なので、O(Nlog(N))になります。in-placeに実行できます。
1,2含めて、ヒープソートの計算量はO(NlogN)となります。
1の計算量はO(N)を実現するアルゴリズムおよびその計算量は直感的ではないと思うので、Algorithms in Cの第9章の証明を紹介します。
底から高さ1の部分木を順にheap化し、底から高さ2の部分木を順にheap化し、、という作業をルートにいたるまで行います。
「ASORTINGEXAMPLE」をheap化するときの様子が以下です。
最初に「NLE」「PMI」「TXA」「RGE」からなる木をheap化し、PとIのswap、XとTのswapが発生します。
次にOをルートとする部分木、Sをルートする部分木をheap化し、最後に木全体をheap化します。
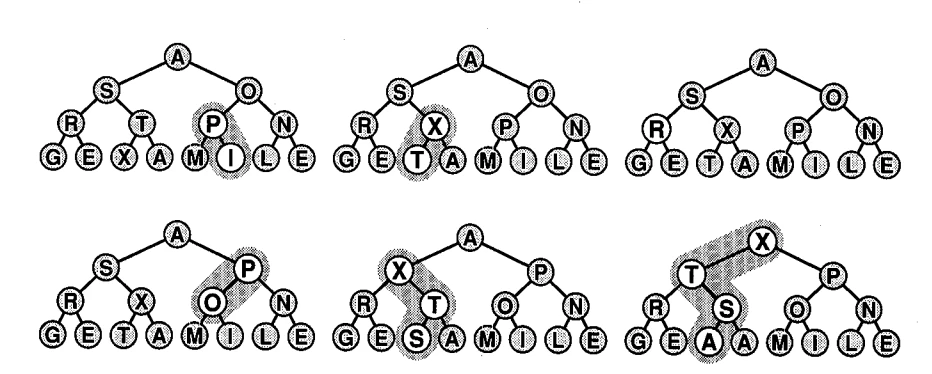
簡単に要素数を$N=2^n-1$とします。(n-1)が木の高さに該当します。
このとき要素の昇進回数の上界は
\sum_{1\leq k< n} k2^{n-k-1} = 2^n -n - 1 < N
となります。式変形は高校数学の範囲で簡単に求めることができます。
「手順2 ヒープのルートから要素を1件ずつpopする」についても軽く補足しておきます。
普通に実装しようと思うと、新しい配列を用意して、最小値がルートにあるようにしたheapから1件ずつ取得して配列に先頭から入れていくことを想定すると思いますが、実はin-placeに実装できます。
すぐにpopした要素をheapを表現する配列の末尾から順に埋めていくことが思いつきます。これでもin-placeではあるのですが最後にreverseする必要があります。
ということで最適解は
最大値がルートにあるようにしたheapからpopし、末尾に詰めていく
です。美しいですね
シェルソート
シェルソートは馴染みがない方もいそうなので少し詳しく書きます。基本的にはAlgorithms in Cを参考にしてます。
シェルソートは挿入ソートを改良したものです。挿入ソートはどんなものだったかというと以下です。exportされてませんが、goの標準ライブラリの実装です。
// [a,b)をソートします
// Insertion sort
func insertionSort(data Interface, a, b int) {
for i := a + 1; i < b; i++ {
for j := i; j > a && data.Less(j, j-1); j-- {
data.Swap(j, j-1)
}
}
}
2重ループの内側の処理をみればわかるように、配列が事前にソート順に近ければかなり早くにループをぬけることがわかります。平均すると比較回数は $O(N^2/4)$ です。
挿入ソートの問題点は「要素の交換が隣の要素としか行わない」ことです。例えば、最小の要素が配列の右端にあった場合、要素はN回内側のループが必要になります。
そこで、離れた要素をグループにし、グループ内で事前にソートしておけばいいのでは?というのがシェルソートのアイデアです。
用語として、h要素離れた要素がソートされている状態をh-整列と呼ぶことにすると、あらかじめ決まったhの列(例えば1,4,13)に対して、hの降順に挿入ソートしていく(例では13-整列,4-整列,1-整列)とシェルソートになります。
シェルソートの計算量を考える上で重要な性質を二つ紹介します。
k整列な列をh整列すると、k整列かつh整列する
元の整列は維持されているという主張です。
当然のように聞こえるかもしれませんが全然自明ではないです。
証明はhttps://cympfh.cc/taglibro/2017/06/28 を参考にしてください。証明を自力で思いつくのは到底できなかったですが、理解するのは難しくないです。
hとkが互いに素のとき、(h-1)(k-1)以上の全ての自然数はah+bk(a,bは0以上の整数)で表せる
hとkが互いに素のとき、任意の整数はah+bk(a,bは整数)で表せることはかなり有名ですが、a,bに制限がついた上記は知らない方も多いのではないでしょうか。
証明はhttps://examist.jp/mathematics/integer/axby-kouzou/ が非常にわかりやすいです。
さて、上記の二つの性質を利用すると、k->h->g と最後にg整列するときに、N(h-1)(k-1)/g以下の比較でおさえられることがわかります。例えば13->4と整列済みである場合、任意の要素において、その要素より小さいことが確定していないのは、1,2,3,5,6,7,9,10,11,14,15,18,19,22,23,27,31,35前のみで、(13-1)(4-1) = 36前とその先は必ず小さいことが保証されます。
証明まではおえていませんが、増分列に依存して計算量が決まり、例えば以下がわかってます。
増分列 1,4,13,40,121,364,1093,..の場合、$O(N^{3/2})$
増分列 1,8,23,77,281,1073,4193..の場合、$O(N^{4/3})$
Goのソート
前置きが長くなりましたが、上記の知識を前提にGoのソート実装を見ましょう。
先に、ソースコードのメインの部分をのせてしまいます。
func quickSort(data Interface, a, b, maxDepth int) {
for b-a > 12 { // Use ShellSort for slices <= 12 elements
if maxDepth == 0 {
heapSort(data, a, b)
return
}
maxDepth--
mlo, mhi := doPivot(data, a, b)
// Avoiding recursion on the larger subproblem guarantees
// a stack depth of at most lg(b-a).
if mlo-a < b-mhi {
quickSort(data, a, mlo, maxDepth)
a = mhi // i.e., quickSort(data, mhi, b)
} else {
quickSort(data, mhi, b, maxDepth)
b = mlo // i.e., quickSort(data, a, mlo)
}
}
if b-a > 1 {
// Do ShellSort pass with gap 6
// It could be written in this simplified form cause b-a <= 12
for i := a + 6; i < b; i++ {
if data.Less(i, i-6) {
data.Swap(i, i-6)
}
}
insertionSort(data, a, b)
}
}
クイックソートをベースにしつつ、再帰が閾値を超え多すぎると検知した時点でヒープソートに切り替えるアルゴリズムをイントロソートと呼びます。pivotの選択を可能な限りうまく行ったところで、恣意的なデータを作成すればパフォーマンスが著しく低下し、さらにそれを利用して攻撃することもあるようです。閾値を設定し、ヒープソートに切り替えるのは自然に受け入れられる考えだと思います。
**Goの実装もイントロソートとなっていることがわかります。**引数のmaxDepthが許容できるクイックソートの深さを表現していますが、$2 \times \lceil \log(N+1) \rceil$ が引数として呼び出されます。
pivotの選択はすでに書いたようにneither(median of median)を利用していますが、要素が40以下の時には3要素のmedianが採用されます。
ソースコードのコメントに記載のある論文に理由が書いてあり、単純に小さい要素のpivotの選択には最大12の比較はtoo muchでしょということのようです。
The ninther yields a better-balanced recursion tree at the cost of at most twelve extra comparisons.While this is cheap for large arrays, it is expensive for small arrays. Our final code therefore chooses the middle element of smaller arrays, the median of the first, middle and last elements of a mid-sized array, and the pseudo-median of nine evenly spaced elements of a large array.
pivotと比較して部分ファイルを作成していく部分について補足します。
先ほど取り上げたようなpivotと同じ値を持つ要素を左右のどちらの部分ファイルにも残らないようにすることを可能な限り目指す実装になっているようですが、軽く驚くくらい複雑な実装がされてます。興味ある方は
https://github.com/golang/go/blob/8854368cb076ea9a2b71c8b3c8f675a8e19b751c/src/sort/sort.go#L120-L193
を読んでみるといいと思います。こんな複雑な実装をするほど優位性があるのだろうかと疑問に思いつつ、そこまで興味が持てず調べてません。興味がある人は論文を読んでみると良さそうです。
クイックソートのテクニカルなところでいうと、pivotの左右でソートしていく時に要素が少ない方を再帰して、多い方をループで処理しているのが興味深いです。これによりスタックの深さはlog(N)以下であることが保証されています。
要素数が12以下のときには増加列6,1のシェルソートが使われています。要素数が少ない時にはシェルソートの方が効率が良いということです。
pivotとそれによる分割ファイルのpivotを辺として結ぶことで分割する様子を2分木として表現できます。2分木の性質から、かなりの分割ファイルの大きさが0か1であることがわかります。小さな部分ファイルについてはクイックソートの通常の再帰処理は無駄が多いので専用の方法を使った方が良さそうということがわかります。
Algorithms in Cによると、小さいとみなす部分ファイルの大きさの閾値の適正値は5-25の範囲内でこの範囲内の値を選択し、挿入ソートに切り替えることで1割ほど実行時間が改善されるとのことです。
さらに、部分ファイルを挿入ソートするのではなく、すぐにreturnして処理を打ち切り、一番最後に配列全体を挿入ソートする方がわずかに性能をあげることができるようです。これは挿入ソートの性質からして、部分ファイルごとに挿入するのと最後に全体をソートし直すのとでは差がないことによります。
ただ、イントロソートではヒープソートに切り替えている可能性もありますし、処理打ち切りの戦略は筋が悪そうです。
Goでは、閾値を12とし、なおかつ挿入ソートを改善したシェルソートが採用されています。この12の根拠は理論的なものではなく、おそらくシミュレーション等で一番性能が良かったのではと思われます。
https://github.com/golang/go/blob/master/src/sort/sort_test.go にベンチマークがあるので、参考にしてみると良いと思います。
この部分は個人的にも気になったので、シェルソートに切り替える閾値や、シェルソートの増分列を変化させた上で、BenchmarkSortInt64Kという長さ64000のint配列のソートのベンチマークを評価してみた結果が以下です。
| Threshold to use ShellSort | Gaps | Result(ns/op) | note |
|---|---|---|---|
| 0 | - | 9090035 | Not use ShellSort |
| 6 | 1 | 8730842 | |
| 12 | 6,1 | 8419891 | Currently Sort use this |
| 12 | 1 | 8472024 | |
| 18 | 6,1 | 8394926 | |
| 18 | 1 | 8547184 | |
| 24 | 9,6,1 | 8668785 | |
| 24 | 6,1 | 8426417 | |
| 24 | 1 | 8663981 | |
| 48 | 9,6,1 | 8684211 | |
| 48 | 6,1 | 9130984 | |
| 48 | 1 | 10201709 | |
| 96 | 9,6,1 | 8880709 | |
| 96 | 6,1 | 9127415 | |
| 96 | 1 | 14034377 | |
| 192 | 9,6,1 | 10204530 | |
| 192 | 6,1 | 10211346 | |
| 192 | 1 | 22057045 |
増分列1と記載があるものは挿入ソートを指すことに注意してください。
シェルソートに切り替えたほうが速く、なおかつ、12~24あたりを閾値として採用し、増分列は6,1が良さそうであることがわかります。
どのような修正を加えたのか、実行環境等は
https://github.com/KeiichiHirobe/algorithms/tree/main/go/sort_test
をご確認ください。
おわりに
クイックソート、ヒープソート、シェルソートの少し発展的な部分をとりあげ、最後にGoでのSortの実装を説明しました。
実装自体はそこまで理解するのは難しくなく、複数のソート戦略を組み合わせたものとなってますが、絶妙なバランスをもとに速度が保障されているのではと思います。
先人達の知恵を全て取り込んで最終的にソート実装が今の形に収まっているということを想像すると、ワクワクしますね。