ジャーニーマン( @beajourneyman )です。長いの"ジャニ"と呼ばれています。
Amazon Bedrock Knowledge Bases Web Crawler (Preview)で「自分チャットボット🤖」を作って、実際に問い合わせてみた内容のまとめです。今回は「モデルアクセスの有効化」は割愛しています。また、ブラウザの日本語設定をオンにしている環境ですので、画面の表示がカタカナになってるケースがあります。ご留意ください。
Web Crawler の対象にしたのは自分のQiitaです。記事公開本数も40本弱とちょうど良さそうな分量だと感じたので、実際にクロールしてみました。
構築手順
AWSマネージメントコンソールにログインし、サービスから「Ammazon Bedrock」を選択します。左ペインの「オーケストレーション」メニューの中から「ナレッジベース」を選択します。画像右下オレンジ色の「ナレッジベースの作成」ボタンを押します。
画面遷移すると画面中央ボティ部の左側に以下のようにどのステップを実行しているか分かるチュートリアルが出てきます。今どのステップか分かりやすいです。そちらのステップに則って解説します。
ステップ 1:ナレッジベースの詳細を入力
ステップ 2:データソースを設定
ステップ 3:埋め込みモデルを選択し、ベクトルストアを設定する
ステップ 4:確認して作成
ステップ 1:ナレッジベースの詳細を入力
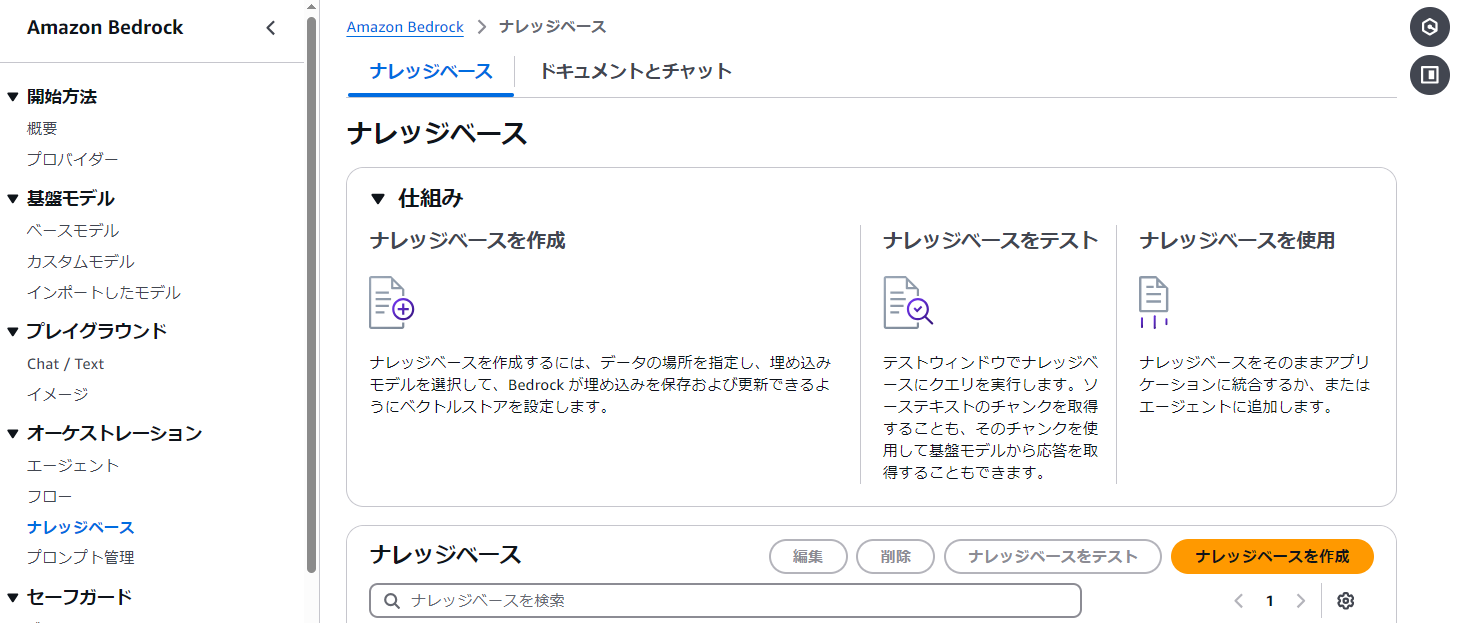
分かりやすい「ナレッジベース名」を設定して、IAM許可はデフォルトの設定、「Web Crawler - Preview」を選択して最下部のオレンジの「次へ」ボタンを押します。タグやログは、お使いのAWSアカウントのルールに則ってご設定いただくと混乱がないと思います。
ステップ 2:データソースを設定
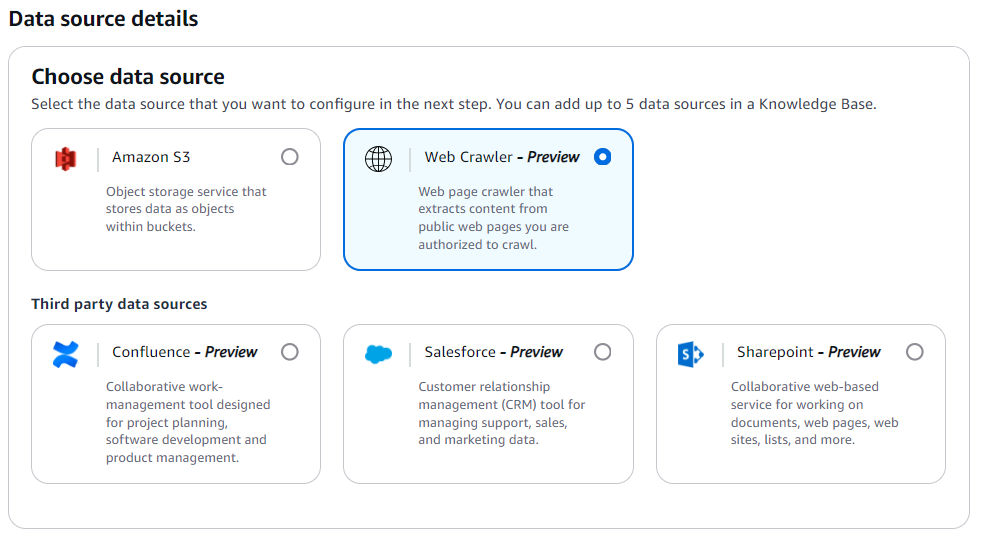
続いて同じく分かりやすい「データソース名」を設定し、ソースURLを設定します。今回は著作権的にも問題ない自分のQiita執筆記事としました。同時に「同期スコープ」と「Content Chanking and Persinng」の設定ができますが、デフォルトで下部「次へ」ボタンを押します。「クローリング最大スロット」は1〜300で設定でき値が大きいほど早くなりますが、ソースのURL数が分かっている場合は、任意の値にしても良いです。約40記事なので40にしました。


ステップ 3:埋め込みモデルを選択し、ベクトルストアを設定する
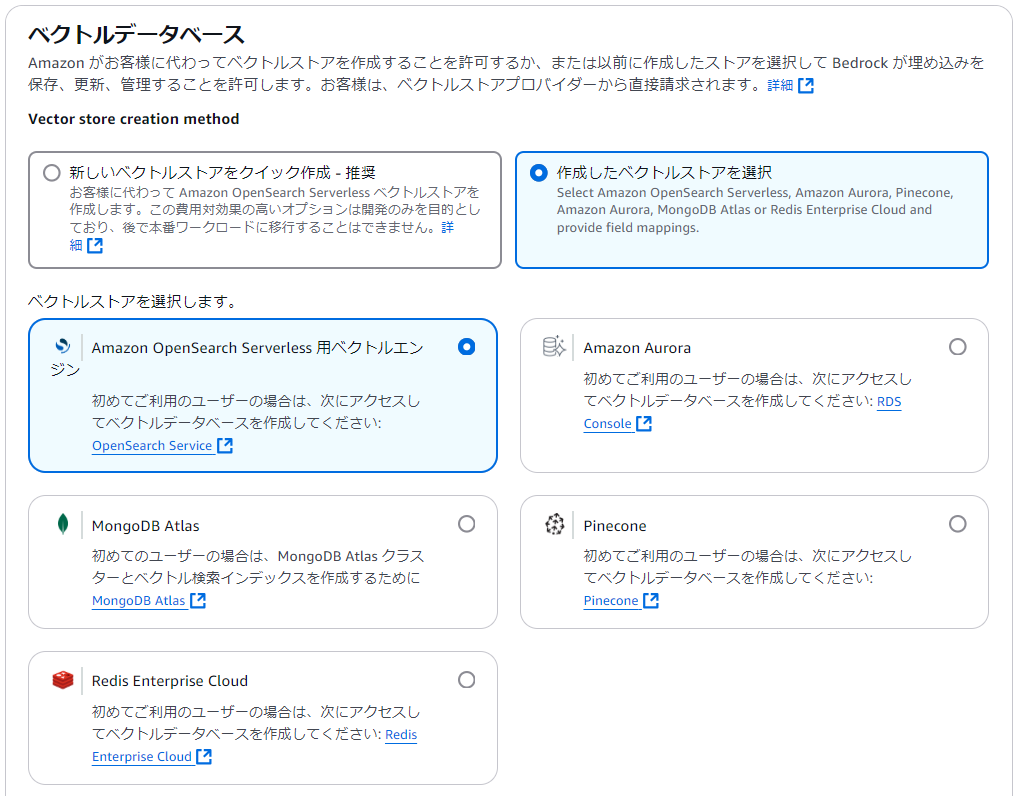
「埋め込みモデル」は料金と用途に応じて選択します。今回は「Titan Text Embedelings v2」にしました。「ベクトルデータベース」は左が新規作成、右が既存へ追加になります。

<余談>
右を選ぶケースは、既に構築済みのナレッジベースに新たな知識を投入してRAGを強化する場面で利用するユースケースです。実際にやってみると内部的に別々で持っているデータソースながらひとつのナレッジベースで回答してくれます。利用者側は選ばなくて良いので、楽なのかなと思います。「コレクションARN」以降は、「Amazon OpenSearch Service」の「コレクション」から対象コレクションを選んで値を確認し設定します。

ステップ 4:確認して作成
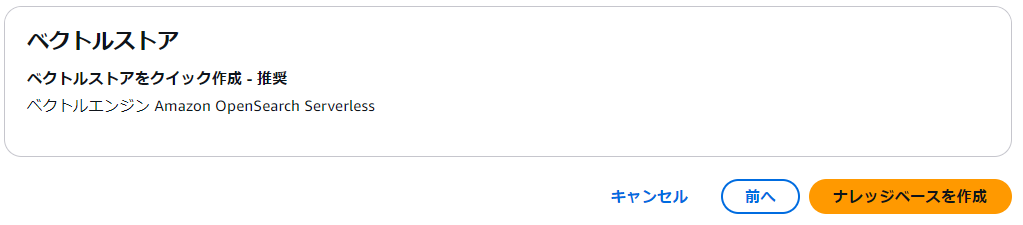
「確認して作成」ステップまで来ると設定した内容が表示されます。問題なければ、右下の「ナレッジベースを作成」ボタンを押します。「データソース〜設定し名前〜がナレッジベース〜設定し名前〜に正常に追加されました」とグリーンのメッセージが表示され「ナレッジベースの概要」が表示されます。こちらは数分要するコトがあります。
〜前略〜
<ご注意>
最近、リソースの制限が厳しいのか構築に失敗するケースを聞きます。何度か実施しても失敗が続くようなら、リージョンを変えて構築してみてください。その際は有効なモデルが異なるケースもあるので「モデルアクセスの有効化」でご確認いただき、必要に応じてご設定ください。
最後に:同期する
ナレッジベースが追加されています(当方環境では3つになっています)。リストの「名前」の下から作成したナレッジベースのリンクを選択してください。
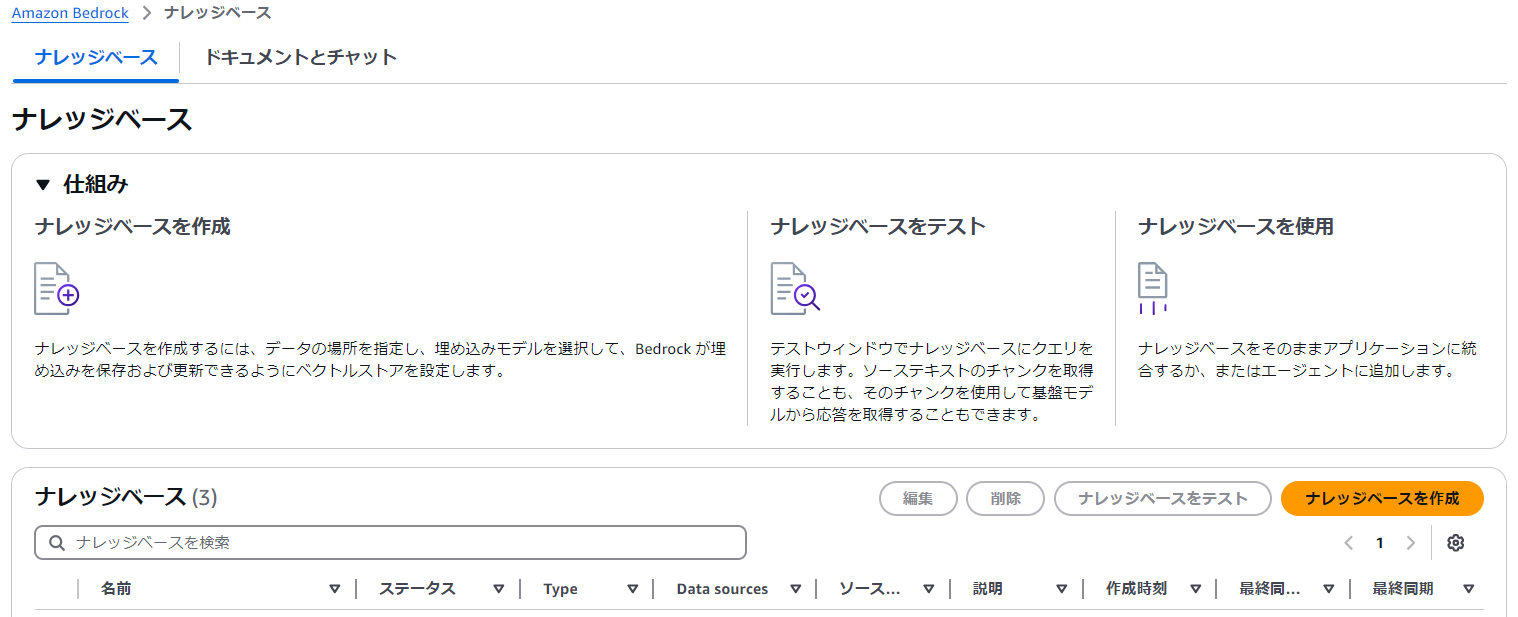
作成できたら「同期」します。こちらには数分かかる場合があります。実際に計測してみたら7分30秒かかりました。


<データの追加>
今後、新しくナレッジベースのデータを追加した場合は、再度データを同期してデータを最新にしてください。
構築は以上です。
ナレッジベース(RAG)に問い合わせてみる
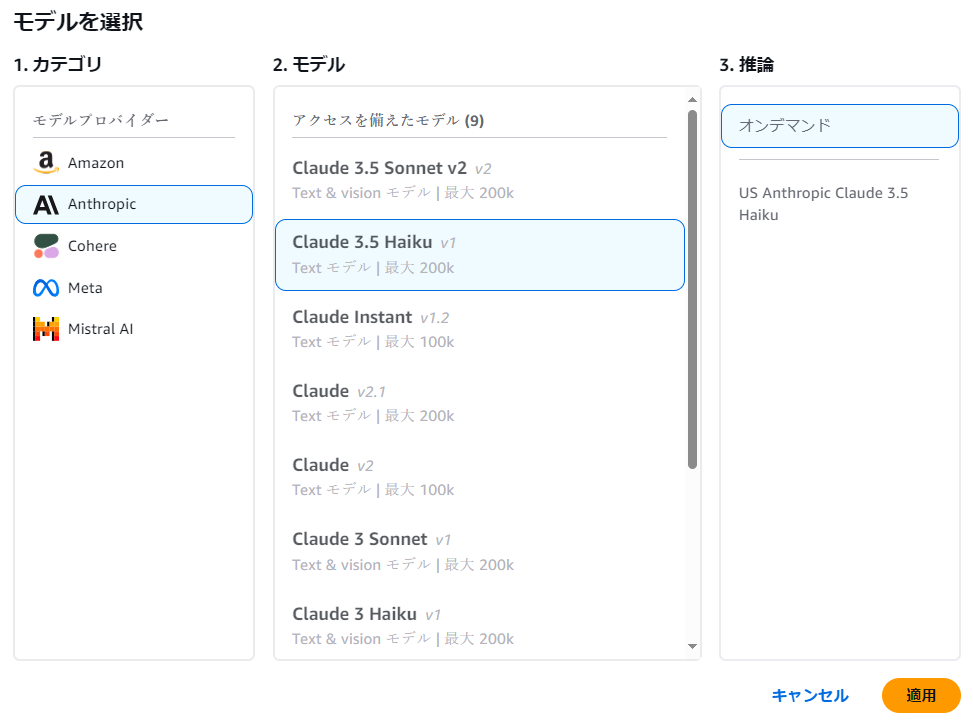
では、早速試してみます。右ペインが「ナレッジベースをテスト」になっていますので「モデルを選択」ボタンを押します。大きめのポップアップが出てくるので「1.カテゴリ」「2.モデル」を選択し「3.推論」はそのままで、右下の「適用」ボタンを押します。
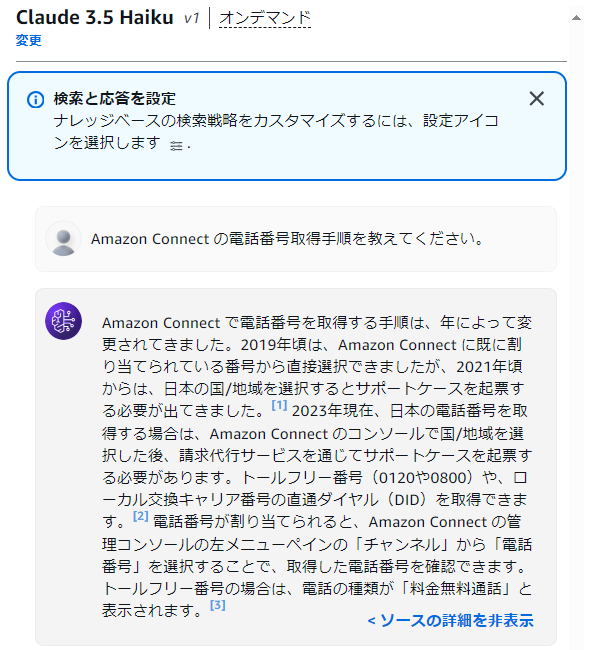
普段 Amazon Connet の記事を書いているので、少しマニアックですがそれを質問してみました。構築前(同期前)は以下の回答でした。

構築後(同期後)はこちらの回答になりました。かなりマニアックな解説をしてくれます(画像は見やすいため「ソースの詳細を表示」した状態で取得しています)。
右下の「ソースの詳細を表示≫」をクリックしてみます。ソースチャンクが並んでいます。
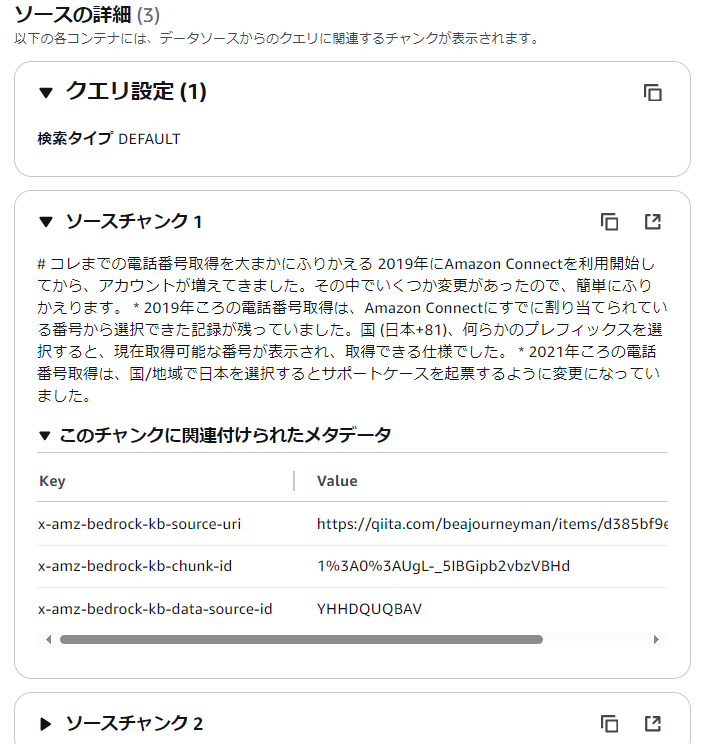
右の四角「別画面」ボタンを押すとソース記事にリンクしました。確かに該当記事がしっかりベクターストアとして、取り込まれています。
所感
自分が書いた記事の内容から回答をしてくれます。作ってみて「自分チャットボット🤖」だなと思ったので、タイトルに入れてみました。実は、noteで5年近く毎日書いている記事をベクターストアにして「JAWS-UGで初登壇したのはいつですか?」などと聞いてみたいのですが、先ほど見たら2,600本以上あったので、費用的に宝くじでも当たったら試してみたいと思います。
ご紹介の通り簡単な手順で構築できますので、是非試してみてください。
以上です。