本記事はVRChat Advent Calendar 2021の18日目の記事です。前回はハツェさんの「UdonのLate-Joiner対応3選」でした。
概要
二年ぶりに開催されたShaderFes 2021にいくつか作品を投稿しました。おそらく、この記事を読んでいる頃には公開されているはずなので、ぜひ先に見に行ってくださいね。
この記事では投稿作品の技術的解説や裏話をしていきたいと思います。かなり技術的な話になるかと思いますが、よろしければお付き合いください。
※スクショは開発テストワールドのものなので、展示場の様子とは若干違う場合があります。
ScrollCalendar
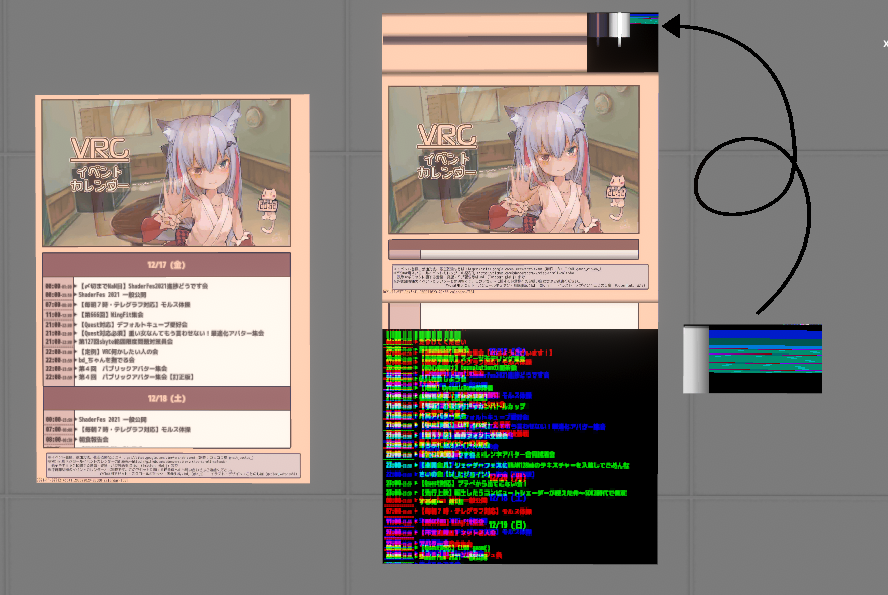
いろんなところに貼っていただいている(旧)スクロール式イベントカレンダーに使われているシェーダーです。(※サポート終了予定です)
VRChatのSDK2環境では、外部画像の読み込み手段はVRC_Panoramaというコンポーネントだけです。このコンポーネントは任意のURLから画像を読み込んで、そのテクスチャを付属するMesh Rendererのマテリアルにぶち込むものです。え?パノラマ?関係ないですね。
マテリアルにぶち込む「だけ」なので、きれいにスクロールさせるのは中々大変です。まぁ、UVスクロールするだけなら簡単だけど、それだとフッター部分が最初から見えなかったり、(最近はあまり問題にはならないが)謎の空白が一番最後にできたり、日付が見れなかったりなど、ちょっと雑すぎると思い、なんかいい感じにスクロールさせるシェーダーを実装しました。
このシェーダーは基本的にデータテクスチャにある指示に従って、テクスチャに入っている各パーツをつなぎ合わせていく感じになります。
デザインのあれこれ
デザインの方はことのしさん(@color_kotonoshi)とコラボで製作しました。そのあともイラストを差し替える度に色調整もしてくださったりなど、大変お世話になりました。ありがとうございます!
ちなみに、日付ヘッダの重なる動きは最初はアメリカのテレビガイドチャンネルの動きに大いに影響されています。

データ部分
元々のデータテクスチャはこんな感じです。
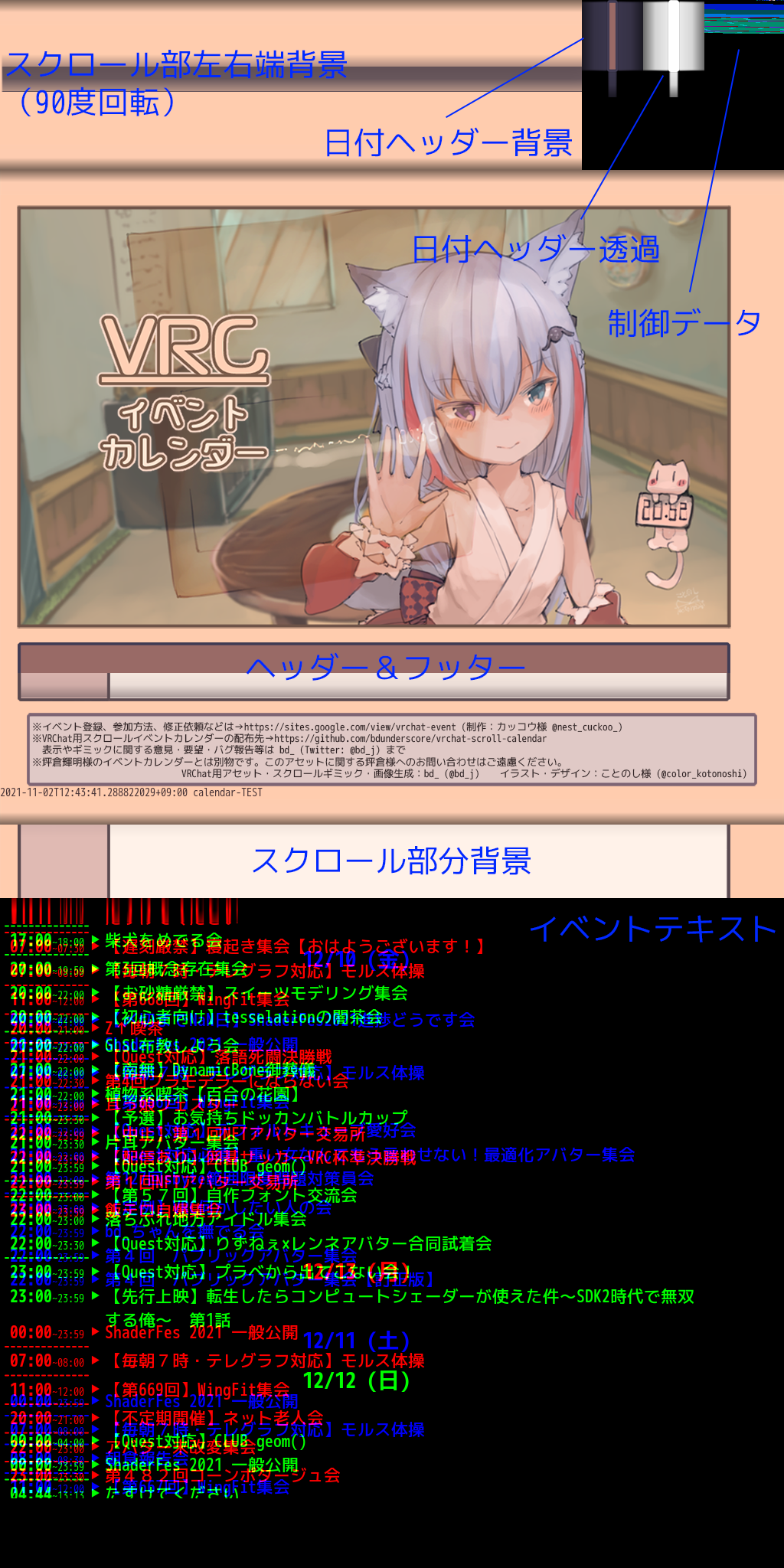
制御データにズームするとこんな感じ・・・だけどアルファーにも情報が入ってて見えないですね。

右上から左へと読むもので、最初は各パーツの大きさやテクスチャでの参照座標、テキストの色パレットなどがはいってから、スクロール部分の横数ピクセルごとに直前の日付表示の位置とパレットの参照が入っています。
ここで少し難しかったのは、VRC_Panoramaの仕様でテクスチャが勝手にsRGBに設定されるため、データを入れようとしても若干劣化します。そこで、RGBチャンネルにそれぞれ6ビットだけ割り当てて、アルファーに8bit全部入れることで、1ピクセルに26bitを安定で入れることに成功しました。
実はこのシステム、かなり後からカスタマイズできます。各部分の大きさ、色合い、フォントなどがワールド部分を再導入しなくても自由に変えることができます。横部分もいつかテクスチャ入れようかな?と思い、ループせずに左上にでかでかとテクスチャに入れてます。まぁ、そこまで変えるのがめんどくさいので結局は画像差し替えとパレット変更しかやってませんが・・・
テキストの圧縮(?)
VRC_PanoramaでDXT5などの圧縮は使えませんが、VRAMを少しでも節約しようと思い、テキスト部分を三つに分けて、RGBで重ねることにしました。しかし、これだと色情報が抜けてしまうので、コラムごとのパレット指定で描写しています。

カレンダー全体を通して、四つのコラムの横位置が指定されています。時刻、矢印、テキスト、という感じです。横数ピクセルごとに、それぞれのコラムに入っているテキストを8色のパレットに指定できます。4つ目はどこって? 永遠に未使用です。
ShaderFesでの改変
実は、ShaderFesで投稿したカレンダーはそこそこ改変しています。とまぁ、最もわかりやすいのは自動切換えです。今まで8枚のイラストを載せていますが、せっかくなら全部展示しよう!と思い、自動的に切り替える仕様にしてみました。というわけでこの8192x4096無圧縮ARGB32テクスチャを投稿しました:
いやーいいですね。祭りって感じ。これで決まりだッ!ってそのまま投稿しました。
はい、怒られました。
さすがに無圧縮8192x4096はやりすぎでした。128MB以上VRAMを使ってごめんなさい。
しかしやっぱり全部載せたかったので、遅くはなったけれど、圧縮できないデータ部分と普通にDXT1で圧縮してもいいヘッダー部分に分けて、テキスト部分で3枚重ねをやめて普通に単色圧縮テクスチャに変更。そして、元のテクスチャっぽく表示する解説用シェーダーを組んで、急遽送りました。最適化をするチャンスを与えてくださってありがとうございました。
ついでにこの修正を機にAudioLinkを使って画像切換えを同期させました。めでたしめでたし。
DrawingRetreat
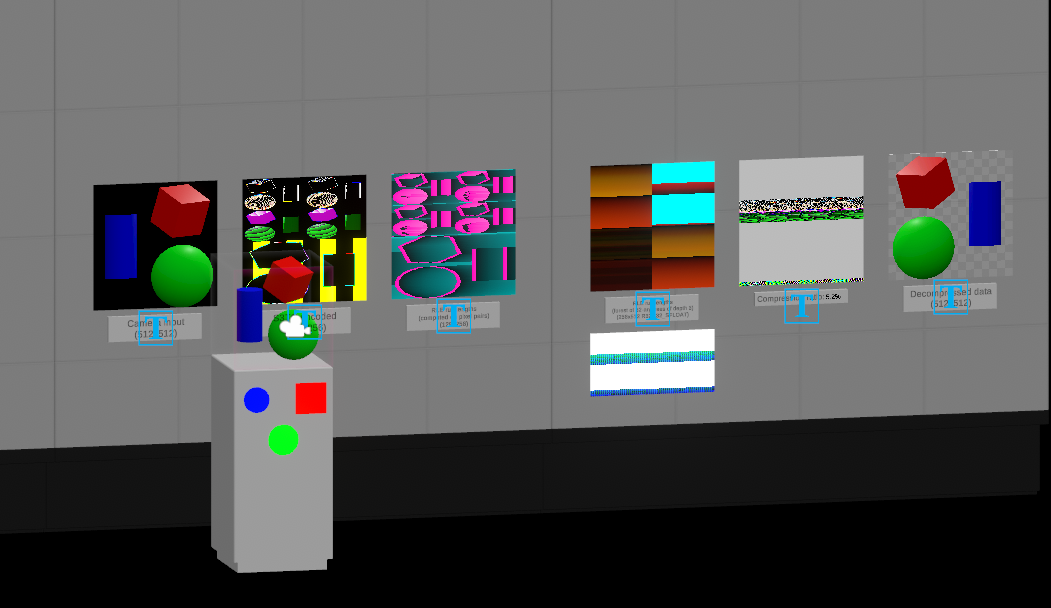
この展示では、お描き合宿で使われている圧縮の内部処理を公開しています。前に置いてある台の上に載せたオブジェをカメラで撮って、その圧縮過程とダウンロードシミュレーションを表示しています。ペデスタルの中にUnlitを使ったオブジェも用意しているので、光によるグラデーションによる圧縮率低下を見ることもできたりします。
しかし、やはり展示を見るだけでは内部処理まではなかなかわかりませんね…日本語+英語の解説を184文字に収めるのはまぁさすがに無理でした。というわけで解説していきましょう。
全体の流れ
お描き合宿の圧縮は二つの圧縮方式を合わせたものです。一つはUnityでもよくつかわれるDXT5方式、もう一つはランレングス符号化(以後、RLE)です。今思えばRLEは適役ではなかったかもしれないけど、まぁ、VRChatのワールドジャムに間に合わせるには妥協も大事ということで。
元々ワールド用のギミックで、Udonで全部圧縮するのが負荷的に無理だったので、シェーダーでごり押しする形となった。DXT5方式の選択もそれに合わせてシェーダーで実装しやすい方式を採用しています。
S3TC/DXT5
DXT5とは、S3TC圧縮の一種で、一定数のピクセルを固定圧縮率で圧縮します。固定なので、無駄にデータを食ったり劣化がひどかったりする場合もあるけど、処理(特にシェーダーでは)簡単なので使えるところは使える。DXT5の流れをおおざっぱに言うと、
- 画像を4x4ピクセルのブロックに仕分ける
- 色情報を…
- 主成分分析で主な二つのベース色を解析する
* この二つの色を565方式で、一色16bitで表現します - ピクセルをすべてその二つの色の間にある色にマッピングする
- 色指定情報を一ピクセル2bitまで削る
- アルファー情報を…
- 二つの参考アルファー値を選んで
- 混ぜ具合を指定するテーブルのどれかにマッピングする(一ピクセル3bit)
最終的に4x4ピクセルを128bitまで圧縮できます。アルファーもフル活用してピクセルに変換した結果がこういう風に表示されます。
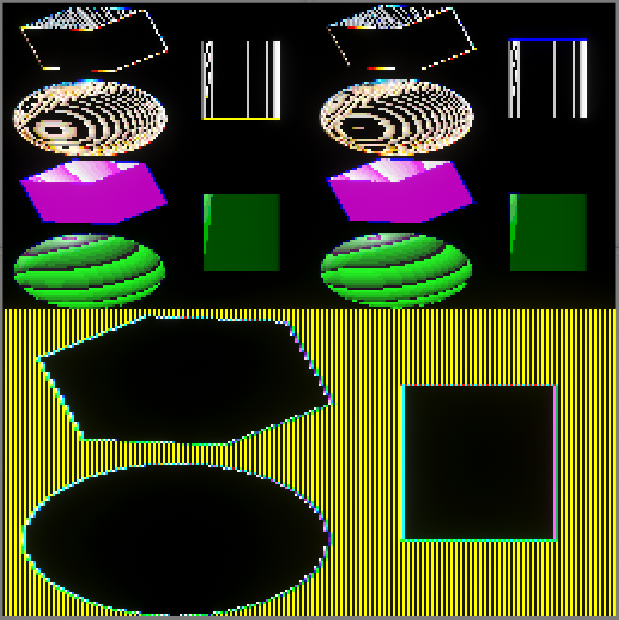
そのあとの圧縮処理のため、下からアルファー情報(一ブロック→2ピクセル)、ベース色(一ブロック→1ピクセル)、色指定情報(一ブロック→1ピクセル)に分けて保存しています。
余談ですが、圧縮するときはこの論文を参考にしました。とても分かりやすかったんですが、途中の主成分分析の所で、固有ベクトルを三次方程式で解くように指示していました。三次方程式をプログラムで解けと言われたので、まぁ素直にWikipediaにあった汎用的な解の式を使いました。素直に虚数計算等をhlslで実装した結果、こうなりました

二日後わかったことが、
- RenderDocのデバッガーを信用してはならない(floatで計算されたものをdoubleで再計算して、変数の内容で実際とは違う数値を表示した)
- 汎用的に三次方程式を解こうとすると浮動小数点の制度限界にぶち当たって死ぬ
そして、固有値が最も大きい固有ベクトルを求めるだけなのであれば、これで十分ということもわかりました。
# define F_EPSILON 0.00001
float4 Eigenstep(float3x3 covMat, float3 estimate) {
float3 newVec = normalize(mul(covMat, estimate));
float error = length(estimate - newVec);
return float4(newVec, error);
}
float3 ComputeMaxEigenvector(float3x3 covMat) {
// 初期ベクトルは適当(ゼロでなければOK)
float3 estimate = abs(covMat[0]) + abs(covMat[1]) + abs(covMat[2]);
for (int i = 0; i < 2; i++) {
// 何回か掛算すればそのうち固有ベクトルになるはず
estimate = Eigenstep(covMat, estimate).xyz;
}
// エラーが下がっているか確認
float4 stepResult = Eigenstep(covMat, estimate);
float4 nextStepResult = Eigenstep(covMat, stepResult.xyz);
if (nextStepResult.w < stepResult.w + F_EPSILON) {
return nextStepResult.xyz;
} else {
// 初期値を変えてやり直す
float3 estimate = normalize(float3(1, 1, 1));
for (int i = 0; i < 4; i++) {
estimate = Eigenstep(covMat, estimate).xyz;
}
return estimate;
}
}
RLE
先ほどのDXT5後の画像を見ていきましょう
見ての通り、同じ色(特に黒・0)が続くことが多いです。下部分は二ピクセルごと繰り返したりなど、無駄が多いです。特に白紙のキャンバスは無駄しかないですね。RLEはこの繰り返すピクセルを、一回だけ出力してから繰り返す数を指定することで圧縮する方式です。
普通にCPUでやるんだたら実装すごく簡単だけど、Udonが重すぎるのでかなり苦労しました…
元々のお描き合宿では、まずは繰り返す・繰り返さない部分の長さ(ラン長と呼びます)を判定してもらいます。

ここの青いところは、右から左へ見て、繰り返す長さを表示しています。ピンクのところは、逆に繰り返さないランの長さを指定しています。なおランの長さはピクセルの数ではなく、ピクセルが二つ入っている「ペア」の数です。この後、Udonでランのはじめでこのテクスチャの該当ピクセルを参照して、その数だけ前へスキップするような処理になっています。
が
ShaderFesではUdonの使用が禁止されていますので、この先をシェーダーのみで再実装せざるを得ませんでした。そこで問題なのは
RLEってシェーダーと相性が悪いですよね
本来(フラグメント)シェーダーでは、出力ピクセルごとに走るため、圧縮用途にはあまり向いていません。というのは、可変レート(最後の大きさがデータの内容によって変わる)圧縮では、例えば出力ピクセル1234番では、その前の1233個のピクセルの計算結果によって参照するべき入力データが変わります。
また、VRChatではCompute Shaderなどが使えないので、フラグメントシェーダー一回では4色分のデータしか出せません(後からgeometry shaderでいろいろできるとわかったが…)
なので、圧縮シェーダーを作るには、効率よく該当するデータを探す何かが必要です。そしてその何かをまたシェーダーで生成しないといけない縛りです。
RLE用検索木の構築
採用した方式は、検索木の構築です。検索木のノードはそれぞれ、特定ピクセルから始まる、一定数のランの該当するもので、ノード内に①ランに該当する入力ペアの数 ②ランに該当する出力ペアの数 という情報が入っています。
検索木を構築するには、まずは入力ペアごとに、そのペアから始まる32個のランをまとめたノードを生成します。これをレベル0とします。
次に、入力ランごとに、そのペアから始まるレベル0のノードを32個まとめます(一個目のノードの該当領域の終わりでまらノードを読み込んで、の繰り返し)
これを合計三つのレベル構築していけば、最終的にペアゼロから任意の入力・出力位置までたどれる検索木ができあがります。ね、簡単でしょう(デバッグが地獄でした)
その結果がこちらです

左下:レベル0
右下:レベル1
左上:レベル2
右上:検索した結果、出力ペアから入力ペアへのマッピング
という感じです。
ついでに解凍用のデータも生成されます

このテクスチャもお描き合宿でも存在していて、解凍するときに二分検索で解凍位置から圧縮位置にマッピングするためのデータが入っています(お描き合宿ではUdonで生成しています)
マッピングデータを使って生成されるのはこちらの圧縮データです。

うん、わからん。圧縮データはそれでよし(デバッグ時は地獄です)
RLEのネック
あそこまでやってRLEを実装しましたけど、実はお絵描き合宿ではほぼほぼ空白とアルファー部分でしか活躍できてません。お絵描き合宿ではブラッシュに多少のノイズを載せて質感を与えてるけど、そのせいでベース色や色指定情報にもノイズが乗ります。その結果、RLEが描きこまれた部分ではあまり活躍できません…
いつかJPEGに近い方式でやり直してみたいけど、なかなか時間取れないですね…
ダウンロードシミュレーション
せっかくなのでダウンロードするシミュレーションも作ってみました。カメラループを使った時計でどこまで配信しているかを計算して表示するだけの簡単な仕組みのはずが、実は少し複雑です。
元々のDXT5テクスチャは意図的にアルファー、ベース色、色指定に分けているのは、RLEの効率を上げるだけでなく、ダウンロードするときできるだけ早くアバウトに表示するためのものです。アルファーとベース色だけでイラストの輪郭ぐらいがわかるので、色指定は最後に回しています。そして、アルファーとベース色は大体同じところまでダウンロードしてないと意味がないが、圧縮率はだいぶ違う場合が多いので、うまくペース配分する必要があります。
お描き合宿ではUdon、ShaderFesではシェーダーですが、アルゴリズムは大体同じ。二分検索で決まった送信予算内に入る、もともとのピクセル数を計算する。そしてそれに該当するアルファー、ベース色を送信した後、ひたすらに色指定情報を送信するわけです。
ところが、ShaderFesでのダウンロードはお描き合宿とは違う順番になっていることにお気づきだったでしょうか?
HilbertCurve
お描き合宿では、ヒルベルト曲線というものを使って画像を並び替えています。こんな感じのうねうねするやつをピクセルの上に重ねて、ひも解く感じです:
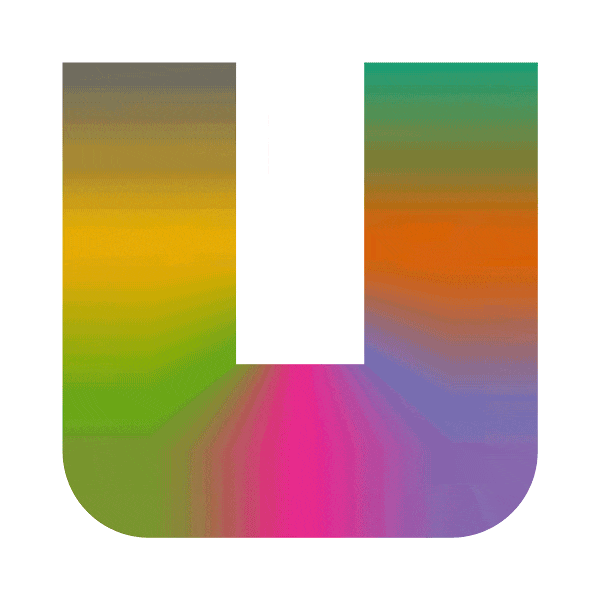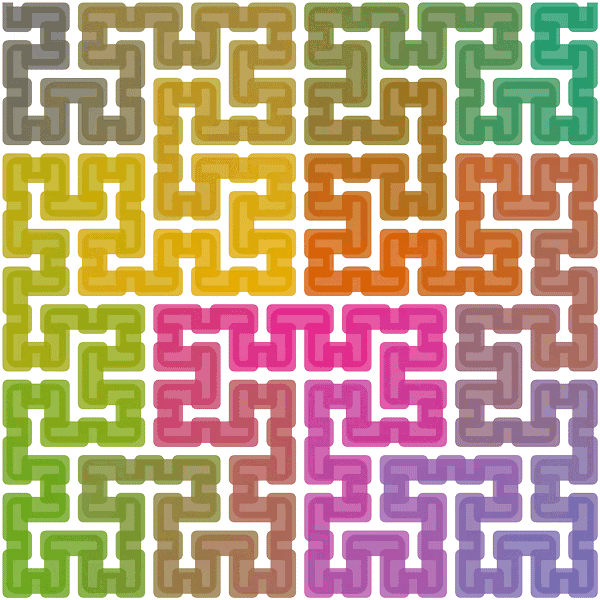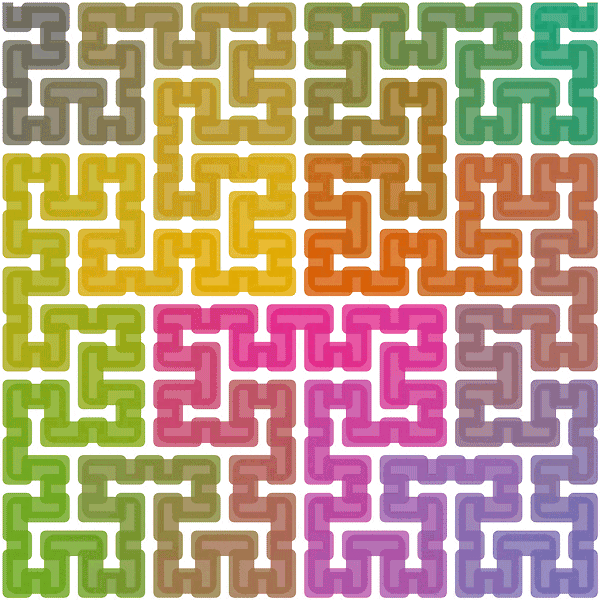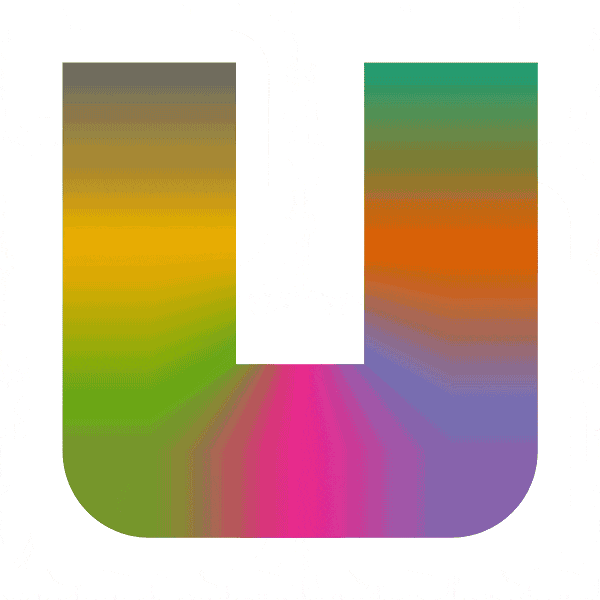
こうすることでRLEの圧縮率が上がるのでは?と思ったけど、まぁ、あまり劇的に変わるわけではない。ランの数が若干減りますが、どっちかというと繰り返さない部分の情報量が多い。まぁ、多少はUdonの処理負担が下がるのでいいけど・・・
圧縮展示ではいろいろとかなり分かりづらくなるので外しましたが、せっかくなのでヒルベルト曲線部分のデバッグ用シェーダーも載せてみました。

終わりに
こういう展示会に何かを投稿するのは実は初めてで、記事を書いている時点では未公開なのでかなり楽しみにしています!今回のイベントスタッフ、いろいろと融通を利かせてくれたりかなり大変そうなまとめ作業したりいろいろとお疲れ&ありがとうございます!みんな見に行ってね!
最後に添削してくださった神城アオイさんもありがとうございます!それでは良いお年を~!

…え?DarkRadar?
…まぁ、うん。友達と一緒にいろいろと実験すればわかるんじゃないかな?