記事の内容
友達の友達の友達と友達・・と辿っていく誰に辿り着くのか?
意外な所でこの人とこの人が繋がってるんだ!みたいなことありますよね。
この記事ではTwitterの相互フォローしている人同士を可視化してみました。
やったこと
やったことは大きく分けると2つです。
- フォローしているユーザーの情報を取得する
- 可視化する
フォローしているユーザー情報を取得する
import json
import config
from requests_oauthlib import OAuth1Session
from time import sleep
from mongo_dao import MongoDAO
import datetime
# APIキー設定(別ファイルのconfig.pyで定義しています)
CK = config.CONSUMER_KEY
CS = config.CONSUMER_SECRET
AT = config.ACCESS_TOKEN
ATS = config.ACCESS_TOKEN_SECRET
# 認証処理
twitter = OAuth1Session(CK, CS, AT, ATS)
mongo = MongoDAO("db", "followers_info")
get_friends_url = "https://api.twitter.com/1.1/friends/list.json" # フォローしているアカウントを取得
get_user_info_url = "https://api.twitter.com/1.1/users/show.json" # ユーザー情報を取得する
count = 200
targets = ['yurinaNECOPLA']
registed_list = []
depth = 2 # 潜る深さ
max_friends_count = 1000 # フォローアカウントがめちゃくちゃ多い人が居るので一定数を超えてると除外する
# フォローアカウントが一定数を超えていないか判定する
def judge_friends_count(screen_name):
params = {'screen_name': screen_name}
while True:
res = twitter.get(get_user_info_url, params=params)
result_json = json.loads(res.text)
if res.status_code == 200:
# フォローしている人数は「friends_count」、フォローされている人数は「followers_count」
if result_json['friends_count'] > max_friends_count:
return False
else:
return True
elif res.status_code == 429:
# 15分間で15回しかリクエストを送信出来ないので上限に達していたら待つ
now = datetime.datetime.now()
print(now.strftime("%Y/%m/%d %H:%M:%S") + ' 接続上限のため待機')
sleep(15 * 60) # 15分待機
else:
return False
# 指定したscreen_nameのフォロワーを取得する
def get_followers_info(screen_name):
followers_info = []
params = {'count': count,'screen_name': screen_name}
while True:
res = twitter.get(get_friends_url, params=params)
result_json = json.loads(res.text)
if res.status_code == 200 and len(result_json['users']) != 0:
for user in result_json['users']:
# APIから取得した情報のうち、必要な情報だけをdict形式で設定 (このPGでidは使ってない・・)
followers_info.append({'screen_name': user['screen_name'], 'id': user['id']})
# パラメーターに次の取得位置を設定する
params['cursor'] = result_json['next_cursor']
# APIの接続上限を超えた場合の処理
elif res.status_code == 429:
now = datetime.datetime.now()
print(now.strftime("%Y/%m/%d %H:%M:%S") + ' 接続上限のため待機')
sleep(15 * 60) # 1分待機
else:
break
return followers_info
# dictのlistからscreen_nameのみのlistを取得する
def followers_list(followers_info):
followers_list = []
for follower in followers_info:
followers_list.append(follower['screen_name'])
return followers_list
# 再帰処理
def dive_search(target_list, d):
for name in target_list:
if name in registed_list or not judge_friends_count(name):
continue
print(name)
followers_info = get_followers_info(name)
mongo.insert_one({'screen_name': name, 'followers_info': followers_info})
registed_list.append(name)
if depth > d:
dive_search(followers_list(followers_info), d + 1)
else:
return
dive_search(targets, 0)
このプログラムでは起点となるアカウントを決めておきます。
(//ネコプラ//というアイドルグループの碧島ゆりなさんのアカウントを起点としています)
その後、以下の流れで再帰的に処理していきます。
① フォローしているユーザーの情報を取得する
② ①の情報をmongoDBに登録する
③ ①で取得したユーザー情報を1件ずつ取得し、①から実行する
depthの値を変えるとどれだけ再帰的に潜っていくのかを変更出来ます。
2だと友達の友達までを取得するイメージです。
本当はもっとデータを取得したかったのですが、フォロー関係の情報を取得するAPIが15分間で15リクエストしか送れません。
起点としているアカウントは現時点で100アカウントをフォローしていますが、このアカウントから始めても処理が完了するのに3時間ほどかかりました。
しかも、途中で「既存の接続はリモート ホストに強制的に切断されました。」というエラーが発生して処理が落ちてしまいました。
この時点でフォローしているユーザー100アカウントのうち、60ほどしか完了していません。
うまく動いたとしても、6時間ほどは掛かっていたと思います。
mongoDBへのデータ登録などは以下のコードを使っています。
可視化する
前項で記載した通り、データは全て集まったとは言えない状況ですが、とりあえず集まったデータで可視化してみます。
可視化に使用するライブラリはNetworkXというものを使いました。
インストールは以下のコマンドで出来ます。
pip install networkx
import json
import networkx as nx
import matplotlib.pyplot as plt
from requests_oauthlib import OAuth1Session
from mongo_dao import MongoDAO
mongo = MongoDAO("db", "followers_info")
start_screen_name = 'yurinaNECOPLA'
# 新規グラフを作成
G = nx.Graph()
#ノードを追加
G.add_node(start_screen_name)
depth = 3
processed_list = []
def get_followers_list(screen_name):
result = mongo.find(filter={"screen_name": screen_name})
followers_list = []
try:
doc = result.next()
if doc != None:
for user in doc['followers_info']:
followers_list.append(user['screen_name'])
return followers_list
except StopIteration:
return followers_list
def dive(screen_name, d):
if depth > 0:
if screen_name in processed_list:
return
followers_list = get_followers_list(screen_name)
for screen_name in followers_list:
f = get_followers_list(follower)
if start_screen_name in f:
G.add_edge(screen_name, follower)
processed_list.append(screen_name)
dive(follower, d + 1)
else:
return
dive(start_screen_name, 0)
# 図の作成。figsizeは図の大きさ
plt.figure(figsize=(10, 8))
# 図のレイアウトを決める。kの値が小さい程図が密集する
pos = nx.spring_layout(G, k=0.8)
# ノードとエッジの描画
# _color: 色の指定
# alpha: 透明度の指定
nx.draw_networkx_edges(G, pos, edge_color='y')
nx.draw_networkx_nodes(G, pos, node_color='r', alpha=0.5)
# ノード名を付加
nx.draw_networkx_labels(G, pos, font_size=10)
# X軸Y軸を表示しない設定
plt.axis('off')
plt.savefig("mutual_follow.png")
# 図を描画
plt.show()
フォロワーの取得手順とロジックは似ています。
再帰的にフォロワーを取得していき、相互フォローしているアカウントが見つかったらエッジを追加しています。
結果
こんな感じになりました。
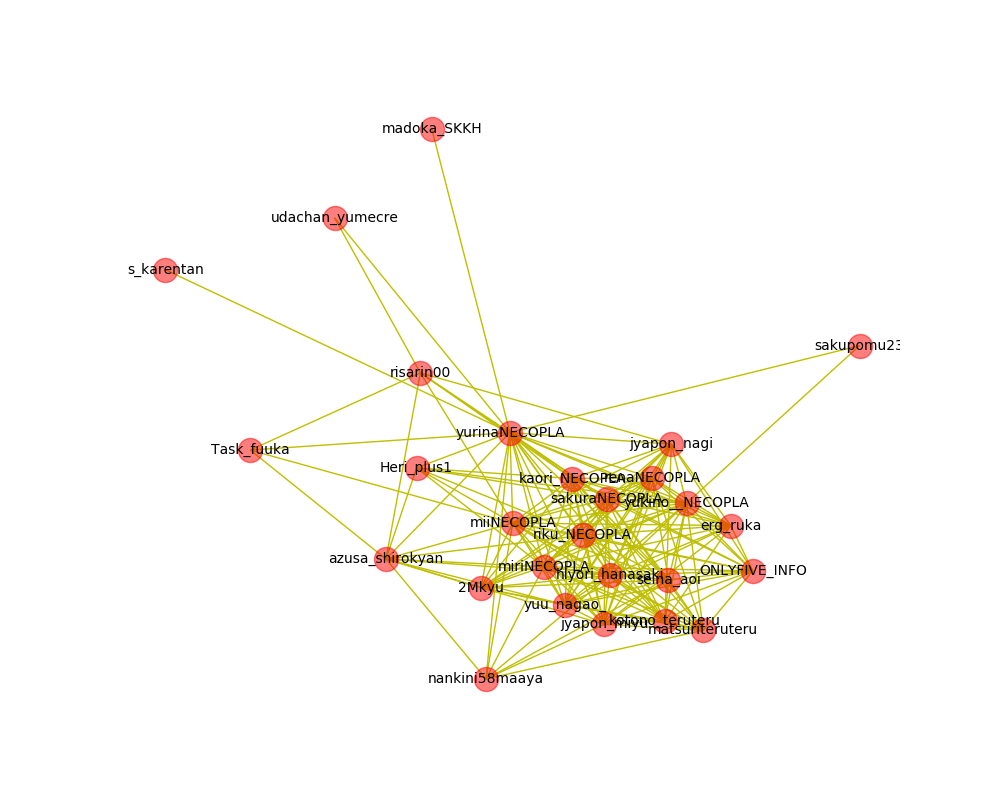
ライブラリの詳しい仕組みまでは理解出来ていないのですが、繋がりが多いアカウント同士が密集していますね。
この密集しているあたりのアカウントは同じ事務所所属のアイドルなので納得の結果になりました。
感想
なかなか面白い結果になりました。
Twitter APIのリクエスト発行上限が15/分となっているため、あまりデータ量を増やせませんでした。
時間を見つけてデータをもっと収集出来れば、友達の友達の友達の・・・という繋がりが見えてくるかもしれません。