*この記事はWanoアドベントカレンダーの7日目です。
表題の通りなんですが、結論から先にいうと、Athena超便利なのでみんな使うべし、って感じですね。
Cloudfrontのみならず、決まったフォーマットでいろんなログをS3に雑に上げておけば、あとからAthenaでどうにでもなるぜー、っていう話です。
あれ、これでもう書くことないな。
とりあえずやってみたことをば。
Athenaってなに?

S3にあるログファイルをSQL文で解析できます。
BigQueryみたいに大量のログデータの解析とかで使ったりとか。
課金体系はBigQueryと同じように、スキャンしたデータの量で決まります。
selectした結果のデータが少なくても、検索対象が全データとかだとお金かかります。
BigQueryと同じようにパーティションを切れば大丈夫です。
間違っても150万円を溶かさないように。
準備
今回はCloudfrontのログをAthenaで検索します。
なのでまずはCloudfrontのログを残す設定をやっておきます。
各Distributionの詳細 -> generalタブ -> Edit に入って、
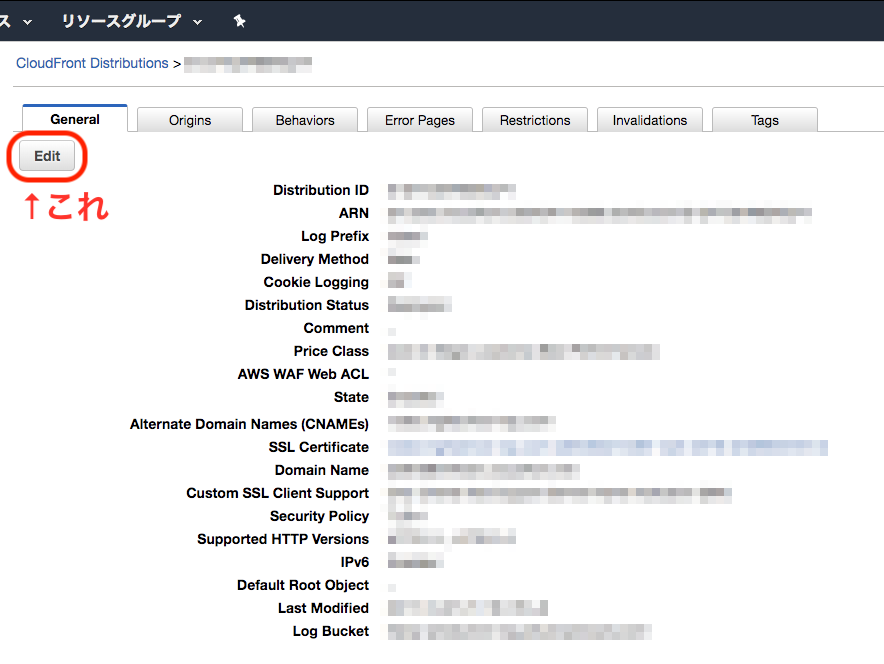
Loggingをオンにする。
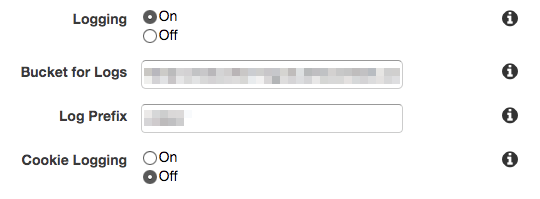
これで設定完了。
Athenaの設定
全部ここに書いてある。
http://docs.aws.amazon.com/athena/latest/ug/cloudfront-logs.html
流れとしては、DB作って、テーブル定義流したらハイ終わりー!って感じ。
まずはAthenaのQueryEditorを開きます。
DBを作ります。
CREATE DATABASE hoge_db
テーブル定義を流します。(↑のドキュメントのまま)
CREATE EXTERNAL TABLE IF NOT EXISTS hoge_logs (
`date` date,
`time` string,
`location` string,
bytes bigint,
requestip string,
method string,
host string,
uri string,
status int,
referrer string,
useragent string,
querystring string,
cookie string,
resulttype string,
requestid string,
hostheader string,
requestprotocol int,
requestbytes bigint,
timetaken bigint,
xforwardedfor string,
sslprotocol string,
sslcipher string,
responseresulttype string,
httpversion string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES
(
"input.regex" = "^(?!#)([^ \\t]+)\\s+([^ \\t]+)\\s+([^ \\t]+)\\s+([^ \\t]+)\\s+([^ \\t]+)\\s+([^ \\t]+)\\s+([^ \\t]+)\\s+([^ \\t]+)\\s+([^ \\t]+)\\s+([^ \\t]+)\\s+([^ \\t]+)\\s+([^ \\t]+)\\s+([^ \\t]+)\\s+([^ \\t]+)\\s+([^ \\t]+)\\s+([^ \\t]+)\\s+([^ \\t]+)\\s+([^ \\t]+)\\s+([^ \\t]+)\\s+([^ \\t]+)\\s+([^ \\t]+)\\s+([^ \\t]+)\\s+([^ \\t]+)\\s+([^ \\t]+)$"
)
LOCATION 's3://your_log_bucket/prefix/';
おもむろに以下のクエリをうつ。
SELECT * FROM hoge_db."hoge_logs" limit 10;
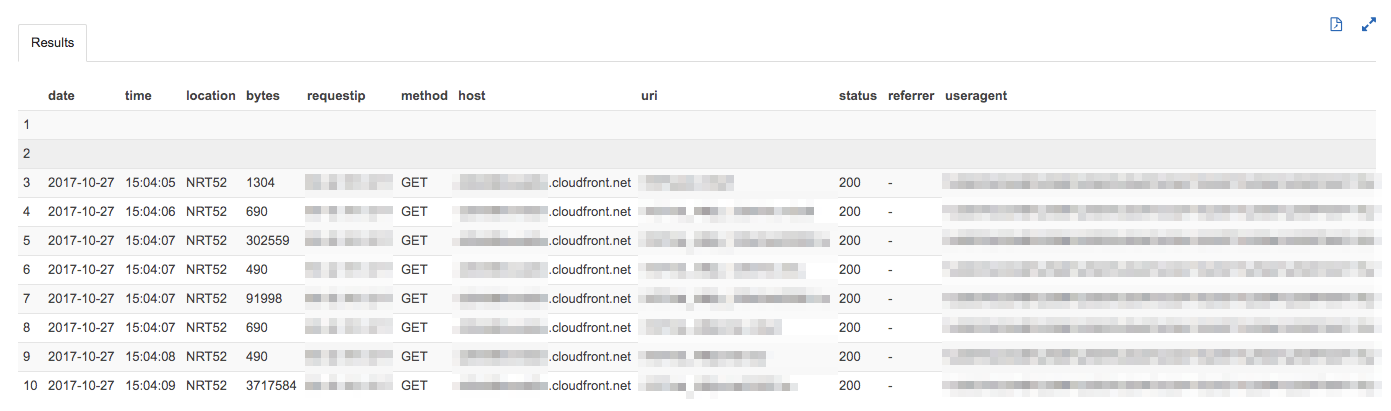
HAPPY!!🎉
パーティションを切れるようにする
とりあえずここまででもう使えるんですが、150万円を溶かすのが怖いので、パーティションを切れるようにします。
Athenaでは、S3のパスの/区切り単位でパーティションを切ることができます。
たとえばS3上のとあるログのパスがs3://hoge-bucket/2017/10/23/fuga.gzだったら、hoge-bucket、hoge-bucket/2017、hoge-bucket/2017/10、hoge-bucket/2017/10/23の単位でパーティションを切ることができます。
ただ、悲しいことにcloudfrontからloggingをオンにしただけでは、上記のように/入りでデータを保存してくれません。
XXXXXXXXXXXXXX.2006-01-02-00.XXXXXXXX.gzという感じのファイル名で吐かれてしまいます。
このままではパーティションを切ることはできないので、lambdaを使ってcloudfrontのログがputされたらゴニョゴニョしてファイルを吐きなおします。
以下、node.jsで書いたlambda関数。
'use strict';
const aws = require('aws-sdk');
const s3 = new aws.S3({ apiVersion: '2006-03-01' });
exports.handler = (event, context, callback) => {
const source_bucket = event.Records[0].s3.bucket.name;
const source_key = decodeURIComponent(event.Records[0].s3.object.key.replace(/\+/g, ' '));
// XXXXXXXXXXXXXX.2006-01-02-00.XXXXXXXX.gzというファイルを、XXXXXXXXXXXXXX/2006/01/02/00/XXXXXXXX.gzに変換している
var key_components = source_key.split(/[-\.]/);
var extension = key_components.pop();
var filename = key_components.pop();
key_components.push(filename + "." + extension);
var renamed_key = key_components.join("/");
var params = {
Bucket: "hoge-renamed-bucket",
CopySource: source_bucket + "/" + source_key,
Key: renamed_key,
};
s3.copyObject(params, function(err, data) {
if (err) console.log(err, err.stack); // an error occurred
});
};
雑にリネームして別Bucketに吐きなおしているだけのコード。
ちなみにこのlambda関数を動かすためのポリシーはこんな感じ。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:*"
],
"Resource": "arn:aws:logs:*:*:*"
},
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:ListBucket"
],
"Resource": "*"
}
]
}
copyObjectをするにはPutObjectとListBucketが必要。
logsはlambdaの実行ログを見れるようにするため。
パーティションを切る
Athenaに戻って、実際にパーティションを切ります。
例えば以下のようなクエリを打てば月ごとにパーティションを切れます。
ALTER TABLE hoge_logs ADD PARTITION (year='2017',month='01') location 's3://hoge-renamed-bucket/XXXXXXXXXXXXXX/2006/01/'
年ごと、月ごと、日ごとなど、お好きな単位でお切りください。
SELECTする場合は次のようにパーティションを指定すればオーケー。
SELECT * FROM hoge_renamed_log WHERE year = '2017' AND month = '01';
まとめ
とりあえず何となくパーティションを意識してS3にログを雑に保存しておけば、あとからAthenaでテーブルを定義しちゃえばいくらでも探すことができます。
今回はcloudfrontでやりましたが、テーブル定義の時にデータ区切り文字を指定すればいろんなログデータのタイプに適用できるので、めっちゃ便利。
S3にデータ保存するのはそんなに高くないし、とりあえずみんな雑にS3にログを保存すれば良いと思います。
参考文献
- AWSのドキュメント
- クラスメソッド
- Qiita
- cloudpack