1.はじめに
kaggleの"Titanic - Machine Learning from Disaster"における分類精度8割越えを目指して引き続き記事を書いていきます.
今回は前回のコードに交差検証,さらにスタッキング(アンサンブル学習の1種)を加えたコードを掲載しています.
2.方法
以下,提出したコードです.今回から関数表現を増やしているので少し可読性が下がっているかもしれませんがご了承ください.
Titanic Tutorialに載っていたデータインストールのために必要なコード(コピペ)
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
パッケージインストール
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.model_selection import StratifiedKFold
import optuna
import optuna.integration.lightgbm as lgb
import keras
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
import tensorflow as tf
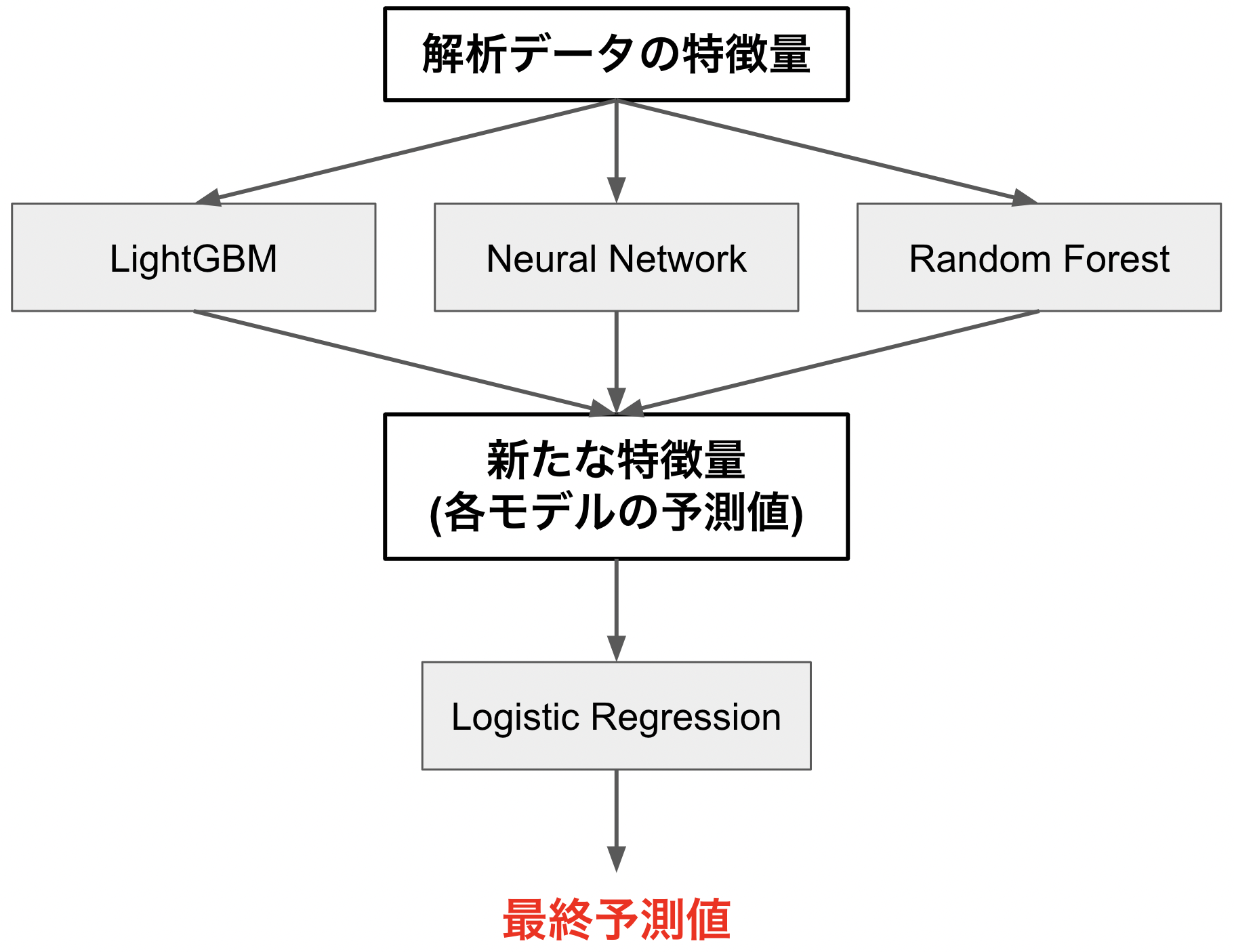
今回はKaggleでよく使われているスタッキングというアンサンブル学習を試してみようと思います.スタッキングでは下の図のように,複数のモデルから得られた予測値を新たな特徴量とし,ロジスティック回帰のような線形モデルによりさらに学習を行い,分類を行います.このようにモデルを2層に分けることにより,さらに高精度の分類モデルが得られるとのことです.しかし1層目のモデルが前回のようにLightGBMとNeural Networkだけではやや寂しかったので,今回はRandom Forestも追加しています.
シード固定用の関数定義
def reset_seeds(seed_num=0):
np.random.seed(seed_num)
tf.random.set_seed(seed_num)
print("RANDOM SEEDS RESET")
ここでは,結果の再現性を担保するため,各ライブラリーの乱数シードを固定しておきます.
データインストール&欠損値処理
train = pd.read_csv("/kaggle/input/titanic/train.csv")
test = pd.read_csv("/kaggle/input/titanic/test.csv")
train['Age']= train.groupby(['Sex','Pclass'])['Age'].apply(lambda row : row.fillna(row.median()))
test['Age']= test.groupby(['Sex','Pclass'])['Age'].apply(lambda row : row.fillna(row.median()))
test['Fare']= test.groupby(['Sex','Pclass'])['Fare'].apply(lambda row : row.fillna(row.median()))
今まで何も考えることなく中央値による欠損値補間を行っていましたが,ランダムフォレストを使った欠損値補間方法も存在するみたいなので,勉強して使ってみてもいいかもしれません.
特徴量選択&カテゴリー変数の変換
names = ['Pclass','Sex','Age','SibSp','Parch','Fare']
X_train = train[names]
X_test = test[names]
y_train = train['Survived']
sex_le = LabelEncoder()
X_train['Sex'] = sex_le.fit_transform(X_train['Sex'])
X_test['Sex'] = sex_le.fit_transform(X_test['Sex'])
他のブログ等を見ていると,どうやらこの辺の吟味が足りていないように感じます.なので次回以降で探索的データ分析(EDA: Exploratory Data Analysis)をやって,特徴量エンジニアリングに取り組みたいと思います.
標準化
standard = StandardScaler()
standard.fit(X_train)
X_train = standard.transform(X_train)
X_test = standard.transform(X_test)
これも研究室にいた時代に学んだことですが,テストデータというのは本来徐々に追加されていくものなので,訓練データによって標準化を行うのが推奨されているようです.なのでここでもX_trainを使ってstandard.fit()しています.
1層目モデル構築用関数
def build_NN(unit1=64, unit2=128, unit3=256, dropout=0):
reset_seeds() # 上記にて定義した再現性確保のための関数
model = keras.models.Sequential()
model.add(keras.layers.Dense(unit1, activation='relu', kernel_initializer=keras.initializers.he_normal(seed=0))) # He Weight Initialization
model.add(keras.layers.Dense(unit2, activation='relu', kernel_initializer=keras.initializers.he_normal(seed=0))) # He Weight Initialization
model.add(keras.layers.Dense(unit3, activation='relu', kernel_initializer=keras.initializers.he_normal(seed=0))) # He Weight Initialization
if dropout > 0:
model.add(keras.layers.Dropout(dropout))
model.add(keras.layers.Dense(1, activation='sigmoid', kernel_initializer=keras.initializers.glorot_uniform(seed=0))) # Xavier Weight Initialization
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=["accuracy"])
return model
def objective(trial):
params = {
'max_depth': trial.suggest_int('max_depth', 1, 5),
'n_estimators': trial.suggest_int('n_estimators', 50, 150),
'min_samples_split': trial.suggest_int('min_samples_split', 2, 10)
}
optuna_model = RandomForestClassifier(**params)
optuna_model.fit(X_train, y_train)
val_preds = optuna_model.predict(X_val)
train_preds = optuna_model.predict(X_train)
return accuracy_score(y_val, val_preds)*accuracy_score(y_train, train_preds)*1000
def train_lgb(X_train, X_val, y_train, y_val):
lgb_train = lgb.Dataset(X_train, y_train)
lgb_val = lgb.Dataset(X_val, y_val)
params = {
'boosting': 'gbdt', # 勾配ブースティング決定木
'objective':'binary', # 機械学習タスクの種類。ここでは二値分類
'metric':'binary_error', # モデルの評価指標
"verbosity": -1,
'deterministic':True, # 再現性確保用のパラメータ
'force_row_wise':True # 再現性確保用のパラメータ
}
model = lgb.train(params = params,
train_set = lgb_train,
valid_sets = lgb_val,
verbose_eval = 100,
early_stopping_rounds = 100,
optuna_seed=0) # 再現性確保用のパラメータ
return model
def train_NN(X_train, X_val, y_train, y_val):
model = build_NN()
early_stopping = keras.callbacks.EarlyStopping(
monitor='val_loss',
patience=10)
model.fit(
X_train,
y_train,
validation_data=(X_val, y_val),
epochs=50,
batch_size=32,
callbacks=early_stopping)
return model
def train_RF(X_train, X_val, y_train, y_val):
study_rf = optuna.create_study(direction='maximize')
optuna.logging.set_verbosity(optuna.logging.WARNING)
study_rf.optimize(objective, n_trials=50)
model = RandomForestClassifier(**study_rf.best_params)
model.fit(X_train, y_train)
return model
def train_and_predict(X_train, X_val, y_train, y_val):
model1 = train_lgb(X_train, X_val, y_train, y_val)
model2 = train_NN(X_train, X_val, y_train, y_val)
model3 = train_RF(X_train, X_val, y_train, y_val)
y_pred1 = model1.predict(X_val, num_iteration=model1.best_iteration)
y_pred2 = np.squeeze(model2.predict(X_val))
y_pred3 = model3.predict(X_val)
return model1, model2, model3, y_pred1, y_pred2, y_pred3
この辺から鬼ほど分かりにくくてすみません。実際に使ったコードをそのまま載せさせています。僕は基本機能ごとに関数化して実装するのでここでは機能ごとに関数を作っています。
ニューラルネットワークはTaitanic編2で紹介したコードにより得られた,ハイパーパラメータチューニング後の最適パラメータをセットしています.またLightGBMとランダムフォレストはOptunaによりパラメータの最適化をおこなっています.今回はこの3つのモデルを第一層目で適用します.細かい概念図は後ほど記載しています.
5分割交差検証
K = 5
sum_preds = np.zeros([X_test.shape[0], 3])
y_pred1 = np.zeros(X_train.shape[0])
y_pred2 = np.zeros(X_train.shape[0])
y_pred3 = np.zeros(X_train.shape[0])
kf = StratifiedKFold(n_splits=K, shuffle=True, random_state=0)
for ii, (train_index, val_index) in enumerate(kf.split(X_train, y_train)):
X_train_kf = X_train[train_index,:]
y_train_kf = y_train[train_index]
X_val = X_train[val_index,:]
y_val = y_train[val_index]
model1, model2, model3, y_pred1[val_index], y_pred2[val_index], y_pred3[val_index] = train_and_predict(X_train_kf, X_val, y_train_kf, y_val)
sum_preds[:,0] += model1.predict(X_test, num_iteration=model1.best_iteration)
sum_preds[:,1] += np.squeeze(model2.predict(X_test))
sum_preds[:,2] += model3.predict(X_test)
sum_preds /= K
ここではスタッキングについて下の概念図を使って説明させて頂きます.
スタッキングでは,交差検証法(本記事では5分割交差検証)を学習用データ(X_train)に適用し,学習データを訓練データ(X_train_kf)と検証データ(X_val)に分割するサイクルを繰り返します.このサイクルにより得られた検証データ(X_val)に対する予測値を結合させることにより,学習用データ(X_train)全体に対する予測値を得ることができます.これをロジスティック回帰の学習用データとします.
ではテストデータはどう得るのか?という話ですが,それは5分割交差検証の各フェーズにて構築された5つのアンサンブルモデル(ここではLightGBM ,Neural Network, Random Forestにより構成されたモデルを1つのアンサンブルモデルと呼んでいます)による,5つの(テストデータに対する)予測値を平均することによって得ています.イメージとしては1層目では訓練データでモデル構築,検証データでモデル評価を行っているのに対し,2層目では検証データでモデル構築,テストデータでモデル評価を行うような感じです.
下の図を見てもまだまだ分かりにくいと思いますので,そういった方にはこちらのサイトがわかりやすくてオススメです.

2層目モデル構築用関数
def make_lr_dataset(y_pred1, y_pred2, y_pred3):
X_test_lr = np.zeros([len(y_pred1), 3])
X_test_lr[:,0] = np.transpose(y_pred1)
X_test_lr[:,1] = np.transpose(y_pred2)
X_test_lr[:,2] = np.transpose(y_pred3)
return X_test_lr
def train_lr(y_pred1, y_pred2, y_pred3, y_train):
model = LogisticRegression()
X_val_lr = make_lr_dataset(y_pred1, y_pred2, y_pred3)
model.fit(X_val_lr, y_train)
return model
def final_predict(sum_preds, model):
X_test_lr = make_lr_dataset(sum_preds[:,0], sum_preds[:,1], sum_preds[:,2])
print(X_test_lr)
y_pred = model.predict(X_test_lr)
y_pred[(y_pred >= 0.5)] = 1
y_pred[(y_pred < 0.5)] = 0
return np.array(y_pred, dtype='int')
最初の関数(make_lr_dataset)が3つのモデル(LightGBM ,Neural Network, Random Forest)の予測値を新たなデータセットとして構成し,2つ目の関数(train_lr)がロジスティック回帰モデルのtraining,そして最後の関数(final_predict)がロジスティック回帰モデルによるpredictionの出力を行う役割を担っています.
ロジスティック回帰によるスタッキング
model = train_lr(y_pred1, y_pred2, y_pred3, y_train)
y_pred = final_predict(sum_preds, model)
ここまでコードがごちゃごちゃしていると,エラーが発生した時のデバックが大変です.
予測結果をCSVファイルに変換
output = pd.DataFrame({'PassengerId': test.PassengerId, 'Survived': y_pred})
output.to_csv('submission.csv', index=False)
print("Your submission was successfully saved!")
3.結果
以上のモデルによる予測結果を提出したところ,予測精度は78.708%と,前回と全く同じ精度でした.
スタッキングを理解し実装するまでに時間がかかったのにも関わらず,精度が向上しなかったので少しショックでした.おそらく与えられた特徴量をそのまま使うだけではこの辺りの精度が限界なのでしょう.
もう少し勉強を続け,めげずに頑張りたいと思います.
4.おわりに
今回はLightGBM,Neural Network,Random Forestの3つのアーキテクチャによる予測値(確率)を新たな特徴量とし,ロジスティック回帰により学習・予測することで,タイタニックデータの生存者・死亡者の2値分類に挑みました(スタッキング).一応勉強して理解したつもりではありますが,もし間違っていればご指摘いただけると幸いです.
次回はたぶんEDA(探索的データ分析)を勉強してそれをまとめます.