はじめに
今回取り組むのはSIGNATEの練習問題「民泊サービスの宿泊価格予測」です。さらに深い分析・洞察を得るためのベンチマークを作ることを目的とします。
今回作成したコードはこちらにJupyterNotebook形式で残しています。
1、課題の把握
本課題では民泊サービスであるAirbnbの掲載物件データを使って、物件ごとの宿泊価格を予測するモデルの構築に取り組みます。Airbnbでは物件オーナーが部屋の広さや立地をもとに宿泊価格を決めていますが、妥当な料金設定を行うのは容易ではないようです。
2、EDA(探索的データ分析)
必要なライブラリをインポートし、学習データ・検証データ・提出用データをそれぞれ読み込みます。
# ライブラリのインポート
import numpy as np
import pandas as pd
from pandas import DataFrame, Series
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
from scipy.stats import norm,skew
from sklearn.preprocessing import LabelEncoder
import lightgbm as lgb
import warnings
warnings.filterwarnings('ignore')
# データの読み込み
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
sub = pd.read_csv('sample_submit.csv',names=('id','pred'))
# 行数を変数として指定
ntrain = train.shape[0]
ntest = test.shape[0]
# データ数の確認
train.shape, test.shape
# ((55583, 29), (18528, 28))
学習データには55583件、検証データには18528件のデータが含まれていることが確認できます。最終的に予測したい宿泊価格yは学習データのみに含まれているため、列数が検証データより一列多くなります。
学習データと検証データの最初の5行を表示します。
train.head()

test.head()

amenitiesとnameは文字列のようです。文字列のままでは処理できないため、対策を考える必要があります。学習データ全29列を確認したところ、カテゴリ変換で対処できない文字列が含まれるカラムは以下の通りでした。
| ヘッダ名称 | 説明 |
|---|---|
| amenities | アメニティ |
| description | 説明 |
| name | 物件名 |
| thumbnail_url | サムネイル画像リンク |
目的変数**y(宿泊価格)**の分布を可視化します。
sns.distplot(train['y']);

コンペ概要にもあるように、課題種別は回帰です。回帰の場合、目的変数の値が正規分布に従っていることが重要です。現状のyは正規分布からは程遠いため対処が必要です。ついでに現時点での歪度と尖度も調べます。
# 歪度と尖度を表示
print("歪度: %f" % train['y'].skew())
print("尖度: %f" % train['y'].kurt())
# 歪度: 4.264338
# 尖度: 26.030945
歪度は4.26、尖度は26.03でした。かなり偏っていますね。
主要なカテゴリ変数についても、箱ひげ図を用いてyとの関係性を探ります。
(accommodates)
var = 'accommodates'
data = pd.concat([train['y'], train[var]], axis=1)
f, ax = plt.subplots(figsize=(16, 8))
fig = sns.boxplot(x=var, y="y", data=data)
fig.axis(ymin=0, ymax=2100);
plt.xticks(rotation=90);

→価格の中央値が最も高いのは16人収容できる物件です。ホスト側(物件を貸し出す側)は、物件の収容人数が多い場合は宿泊価格を高く設定する傾向にあるようです。
(bathrooms)
var = 'bathrooms'
data = pd.concat([train['y'], train[var]], axis=1)
f, ax = plt.subplots(figsize=(16, 8))
fig = sns.boxplot(x=var, y="y", data=data)
fig.axis(ymin=0, ymax=2100);
plt.xticks(rotation=90);
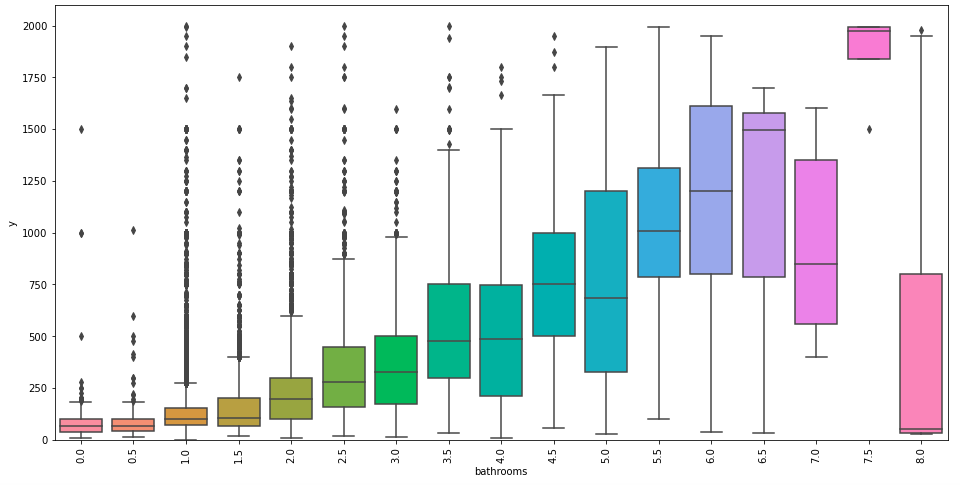
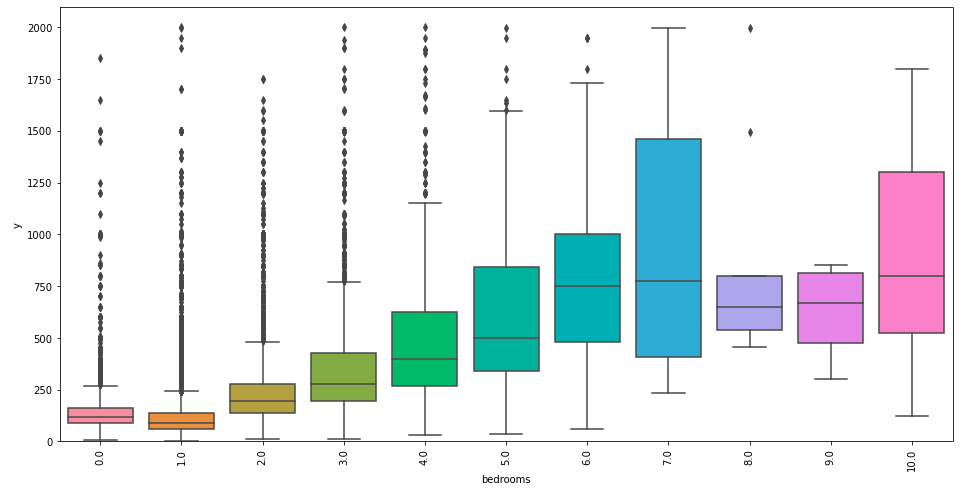
(bedrooms)
var = 'bedrooms'
data = pd.concat([train['y'], train[var]], axis=1)
f, ax = plt.subplots(figsize=(16, 8))
fig = sns.boxplot(x=var, y="y", data=data)
fig.axis(ymin=0, ymax=2100);
plt.xticks(rotation=90);
(beds)
var = 'beds'
data = pd.concat([train['y'], train[var]], axis=1)
f, ax = plt.subplots(figsize=(16, 8))
fig = sns.boxplot(x=var, y="y", data=data)
fig.axis(ymin=0, ymax=2100);
plt.xticks(rotation=90);

どの変数も多ければ多いほど価格は高くなるようです。ここでは、可視化の結果を踏まえた新しい特徴量の作成を見据えて、「{bath|bed} roomsを足し上げれば精度向上に繋がるかもしれない」という仮説を立てます。
3、データの前処理
「データの把握」の段階で、目的変数が正規分布に従っていないことが分かっています。その対処として、yの対数をとり擬似的に正規分布に寄せてみます。正規分布に近づいているか、残差をとって正規QQプロットによる診断も行います。
# 処理前
sns.distplot(train['y'] , fit=norm);
# パラメータを取得
(mu, sigma) = norm.fit(train['y'])
print( '\n mu = {:.2f} and sigma = {:.2f}\n'.format(mu, sigma))
# 可視化
plt.legend(['Normal dist. ($\mu=$ {:.2f} and $\sigma=$ {:.2f} )'.format(mu, sigma)],loc='best')
plt.ylabel('Frequency')
plt.title('y distribution')
# 正規QQプロットの適用
fig = plt.figure()
res = stats.probplot(train['y'], plot=plt)
plt.show()

# 処理後
# log1p(numpyの関数)を適用、対数をとる
train["y"] = np.log1p(train["y"])
# 適用後の分布を確認
sns.distplot(train['y'] , fit=norm);
# パラメータを取得
(mu, sigma) = norm.fit(train['y'])
print( '\n mu = {:.2f} and sigma = {:.2f}\n'.format(mu, sigma))
# 可視化
plt.legend(['Normal dist. ($\mu=$ {:.2f} and $\sigma=$ {:.2f} )'.format(mu, sigma)],loc='best')
plt.ylabel('Frequency')
plt.title('y distribution')
# 正規QQプロットの適用
fig = plt.figure()
res = stats.probplot(train['y'], plot=plt)
plt.show()

対数をとると、正規分布に寄せられていることが分かります。正規QQプロットでも多少のずれはありますが、yの残差が赤い45度線上に並んでいることが分かります。よって目的変数の誤差も正規分布に従っているといえそうです。
# y列を抽出
train_y = train['y']
train_y.shape
# (55583,)
# 学習データと検証データを結合
all_data = pd.concat((train, test)).reset_index(drop=True)
all_data.drop(['y','id'], axis=1, inplace=True)
print("all_data size : {}".format(all_data.shape))
# all_data size : (74111, 27)
各列における欠損値を処理します。
# 欠損値の割合を確認
all_data_na = (all_data.isnull().sum() / len(all_data)) * 100
all_data_na = all_data_na.drop(all_data_na[all_data_na == 0].index).sort_values(ascending=False)[:30]
missing_data = pd.DataFrame({'Missing Ratio' :all_data_na})
missing_data.head(15)

13個の変数に欠損値があるようです。元データや可視化結果を眺めながらどのように補充するか、もしくはデータから落とすか決めます。今回はthumbnail_urlとzipcodeは落とします。
# 年月関連の変数を全て浮動小数点型に変換し、欠損値は0で埋める
for c in ('first_review','last_review','host_since'):
all_data[c] = pd.to_datetime(all_data[c])
all_data[c] = pd.DatetimeIndex(all_data[c])
all_data[c] = np.log(all_data[c].values.astype(np.float64))
all_data[c] = all_data[c].fillna(0)
# 欠損値を1で埋める
for c in ('bathrooms','beds','bedrooms'):
all_data[c] = all_data[c].fillna(1)
# 欠損値をNoneで埋める
for c in ('host_response_rate','neighbourhood','host_identity_verified','host_has_profile_pic'):
all_data[c] = all_data[c].fillna('None')
# 中央値で埋める
all_data['review_scores_rating'].fillna(all_data['review_scores_rating'].median(),inplace=True)
# 使わない列を落とす
all_data = all_data.drop(['thumbnail_url','zipcode'],axis=1)
ここでデータ型を確認します。
all_data.dtypes

object型がかなり多いです。今回はその対処のため、Label Encoderを用います。
# ラベルエンコーディング
cols = ('bed_type','cancellation_policy','city','cleaning_fee','host_identity_verified','host_has_profile_pic','host_response_rate','instant_bookable','property_type','room_type','neighbourhood')
for c in cols:
lbl = LabelEncoder()
lbl.fit(list(all_data[c].values))
all_data[c] = lbl.transform(list(all_data[c].values))
# データ型を確認
all_data.dtypes

ほぼ数値型に変換できました。
残っているobject型の変数ですが、文章中の文字数をカウントするだけの簡単な手法で対処します。
# 対象の列の文字数をカウント
for c in ('amenities','description','name'):
all_data[c] = all_data[c].apply(lambda x: sum(len(word) for word in str(x).split(" ")))
all_data.dtypes

全て数値型になっていることが確認できます。
descriptionのヒストグラムを表示して文字数の違いを把握します。
# descriptionのヒストグラム
plt.hist(all_data['description'],alpha=0.5)
plt.xlabel('description')
plt.ylabel('count')
plt.show()

説明文が800字以上の物件が圧倒的に多いことが分かります。
最後にEDAの時点で仮説を立てた**{bath|bed} rooms**を足しあげましょう。
# 新しい特徴量をつくる
# bathroomsとbedroomsの数を足し上げる
all_data['total_rooms'] = all_data['bathrooms'] + all_data['bedrooms']
4、学習
今回はGBDT(勾配ブースティング木)の中で、最近コンペで最もよく使われているLightGBMを用いて学習から予測まで行います。
# 学習データと検証データに分ける
train = all_data[:ntrain]
test = all_data[ntrain:]
# LGBMRegressorを用いて学習
model = lgb.LGBMRegressor(num_leaves=100,learning_rate=0.05,n_estimators=1000)
model.fit(train,train_y)
# 学習したモデルで検証データを予測
pred = np.expm1(model.predict(test))
feature_importances_から、どの変数がモデルに寄与しているか確認します。
# 変数重要度を可視化
ranking = np.argsort(-model.feature_importances_)
f, ax = plt.subplots(figsize=(11, 9))
sns.barplot(x=model.feature_importances_[ranking],y=train.columns.values[ranking], orient='h')
ax.set_xlabel('feature importance')
plt.tight_layout()
plt.show()

重要度トップ2は緯度・経度でした。最後にcsvファイルに書き出して提出します。
# 提出
sub['pred'] = pred
sub.to_csv('sub.csv',index=False,header=None)
5、結果
以上、前処理や学習を行った結果、44/163位(2020年10月6日時点)でした。まあまあの結果ですが、あらゆる点で改善の余地があります。(落とした特徴量の活用、自然言語処理、モデル選択、交差検証、パラメータ調整、アンサンブル...)このような工夫次第でさらに良い結果を出せるので、本記事がその一助となれば幸いです。
6、参考文献
・Kaggle「House Prices: Advanced Regression Techniques」公開Notebook「Stacked Regressions : Top 4% on LeaderBoard」