Section1:強化学習
■強化学習とは
・長期的に報酬を最大化できるように環境のなかで行動を選択できるエージェントを作ることを目標とする機械学習の一分野
→行動の結果として与えられる利益(報酬)をもとに、行動を決定する原理を改善していく仕組み
・強化学習のイメージ
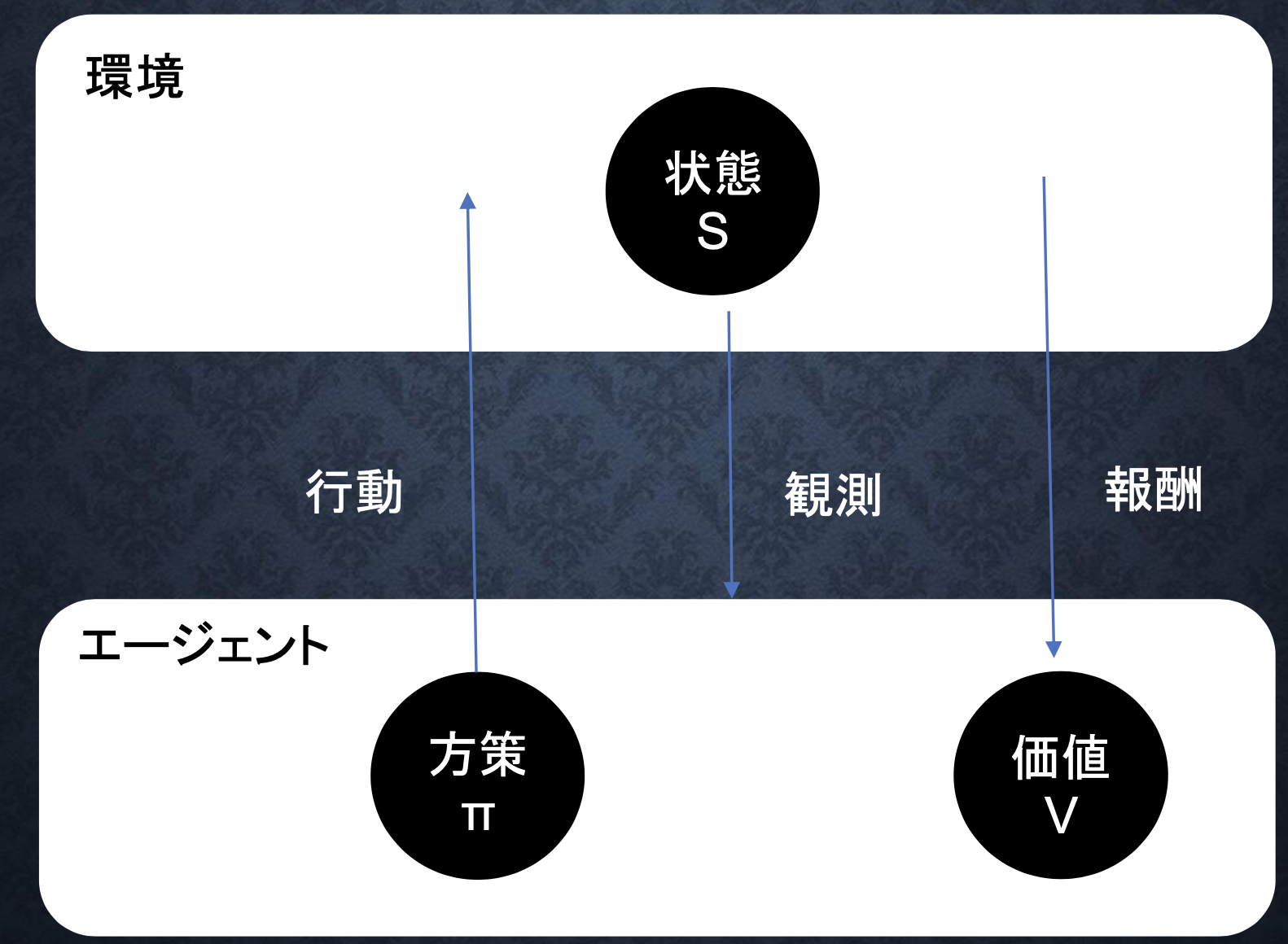
・エージェントは行動する主体のこと
・エージェントは、なんらかの環境に置かれ、環境の「状態」を観測し、それに基づき「行動」を行う。その結果として、環境の状態が変化し、エージェントは環境から「報酬」を受け取ると同時に、「新しい状態」を観測する。
■強化学習の応用例
・マーケティングの場合を考えると、環境、エージェント、行動、報酬は以下のように考えられる。
環境:会社の販売促進部
エージェント:プロフィールと購入履歴に基づいて、キャンペーンメールを送る顧客を決めるソフトウェア
行動:顧客ごとに送信、非送信のふたつの行動を選ぶ
報酬:キャンペーンのコストという負の報酬とキャンペーンで生み出されると推測される売上という正の報酬を受ける
■探索と利用のトレードオフ
・環境について事前に完璧な知識があれば、最適な行動を予測し決定することは可能である。
→どのような顧客にキャンペーンメールを送信すると、どのような行動を行うのかが既知である状況と言える。
→強化学習の場合、上記仮定は成り立たないとし、不完全な知識を元に行動しながら、データを収集し、最適な行動を見つけていくことになる。
・強化学習において、探索と利用はトレードオフの関係にある。
→過去のデータで、ベストとされる行動のみを常に取り続ければ他にもっとベストな行動を見つけることはできない。(→探索が足りない状態)
→逆に、未知の行動のみを常に取り続ければ、過去の経験が活かせない。(→利用が足りない状態)
■強化学習のイメージ
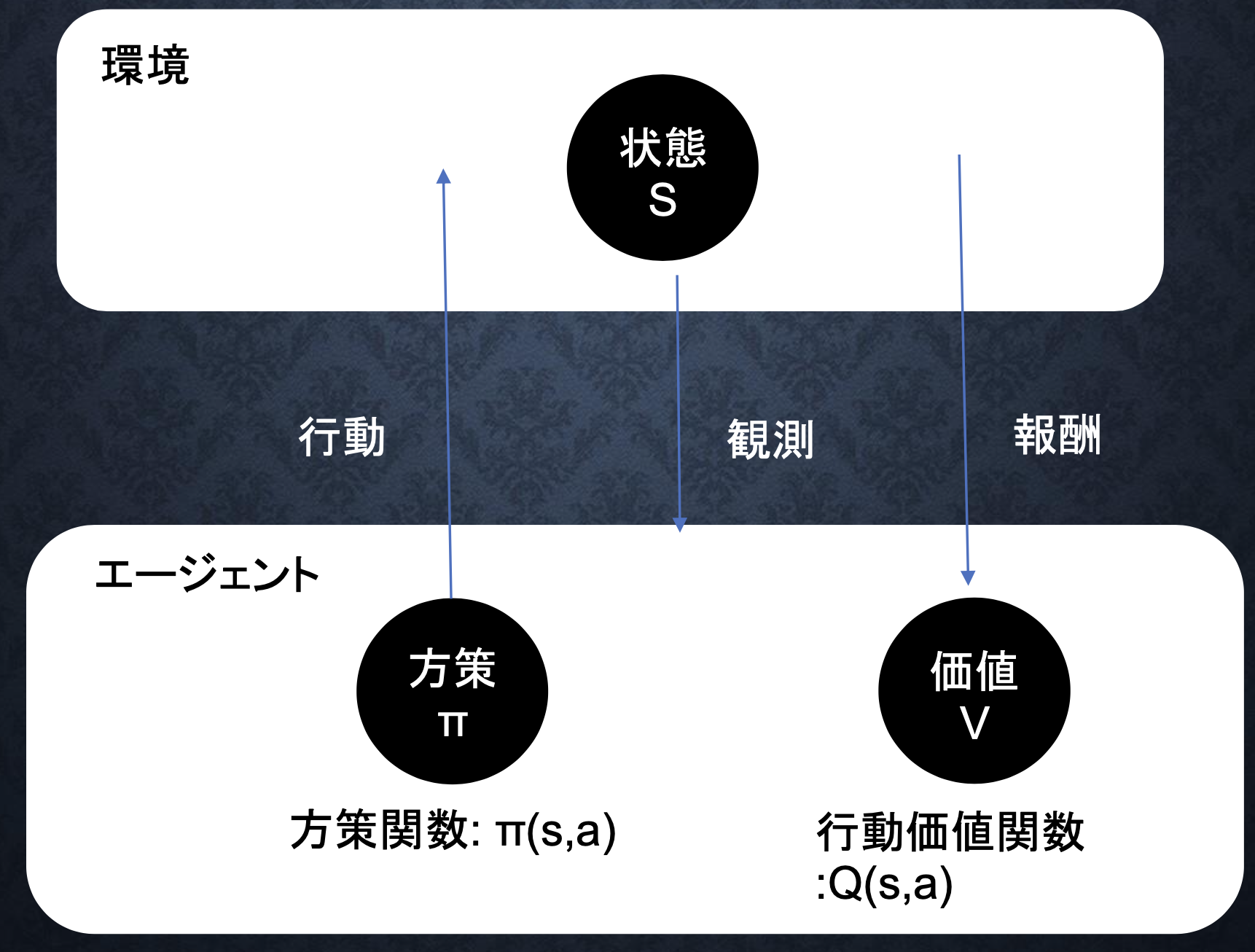
・どういう状態がエージェントにとって最も良い状態であるかをエージェントに考えさせる。
・行動価値関数:どういう状態がエージェントにとって一番いい状態かを決める
・方策関数:エージェントがある状態でどういう行動をするかを決めるための確率を与える
■強化学習の差分
・結論:目標が違う
・教師なし、あり学習:データに含まれるパターンを見つけ出すことと、そのデータから予測することが目標
・強化学習:優れた方策を見つけることが目標
■価値関数
・状態価値関数と行動価値関数の2種類がある
・状態価値関数:ある状態の価値に注目する場合に利用
・行動価値関数:状態と価値を組み合わせた価値に注目する場合に利用
■方策関数
・方策ベースの強化学習手法において、ある状態でどのような行動を採るのかの確率を与える関数のこと
■方策勾配法
・方策反復法:方策をモデル化して最適化する手法
$θ^{(t+1)}=θ^{(t)}+ε∇J(θ)$
※Jは方策の良さを示す。
※NNの重みの更新式に似ている。
※強化学習では報酬を大きくするように計算する。
$∇_θJ(θ)=∇_θ\sum_{a \in A}π_θ(a|s)Q^π(s,a)=E_{πθ}[(∇_θlogπ_θ(a|s)Q^π(s,a))]$
※ある行動をとるときの報酬を足し合わせている。
実装演習
・Q学習という強化学習を実装し、迷路を解く(最短ルートを見つける)
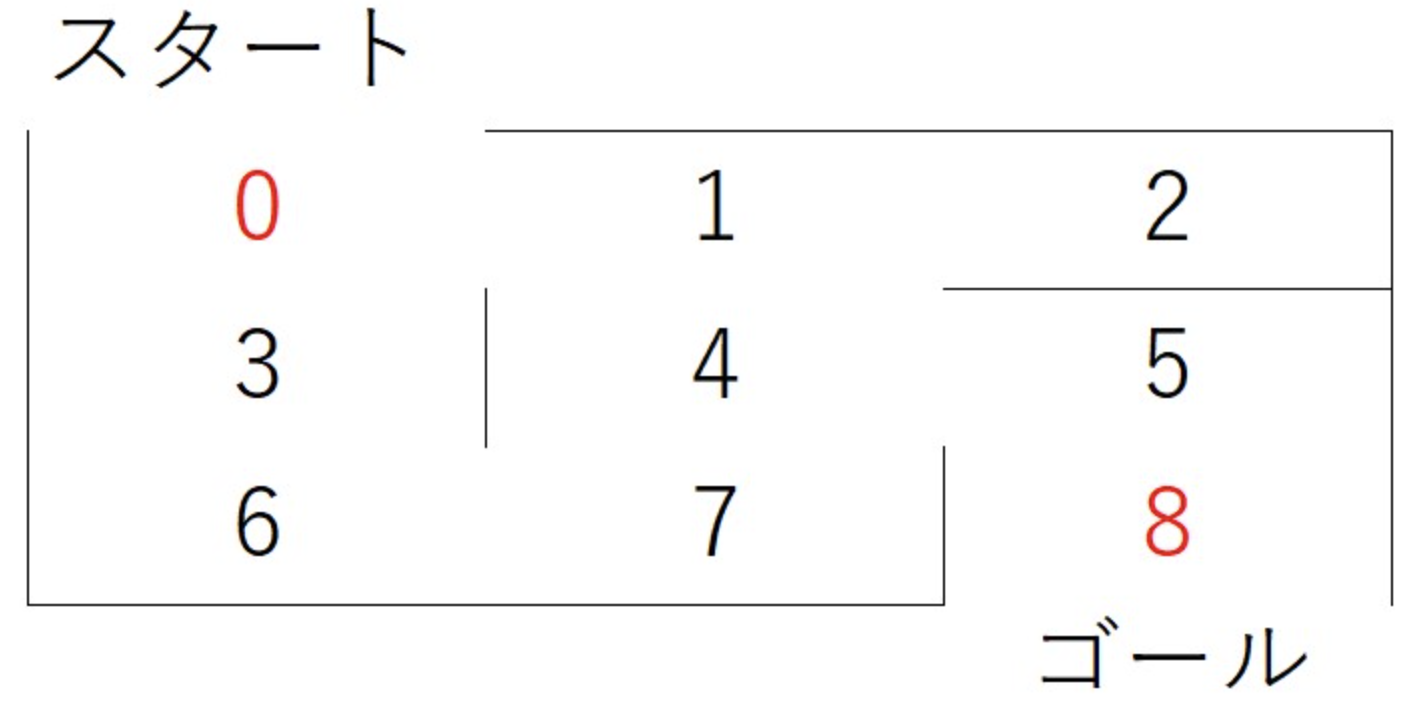
コードは以下のサイトから拝借した
https://dse-souken.com/2021/05/18/ai-17/
#必要なモジュールをインポート
import numpy as np
gamma = 0.9#将来価値の割引。小さいほど行動直後の利益を重視。また、この割引率の存在が効率的な学習の鍵となる。
alpha = 0.1#学習率。大きいと1回の学習による値の更新が急激となる。小さいほど更新がゆるやかとなる。
#報酬の設定
#各場所から移動できる箇所に報酬1を与え、それ以外を0とすることで移動できる方向を指示
#以下の行列の各行が場所に対応。0行目は迷路の位置0、1行目が迷路の位置1
#ゴールとなる8の報酬を大きく設定する
reward = np.array([[0,1,0,1,0,0,0,0,0],#0から1,3に移動できるので、そこに1
[1,0,1,0,1,0,0,0,0],#1から0,2,4に移動できるので、そこに1
[0,1,0,0,0,0,0,0,0],
[1,0,0,0,0,0,1,0,0],
[0,1,0,0,0,1,0,1,0],
[0,0,0,0,1,0,0,0,10000],#8をゴールより5→8の報酬を大きく
[0,0,0,1,0,0,0,1,0],
[0,0,0,0,1,0,1,0,0],
[0,0,0,0,0,1,0,0,0]])
#Q値(行動価値)の初期値を設定。今回は0を初期値とする。
Q = np.array(np.zeros([9,9]))
#Q学習を実装し、各位置における行動価値を算出
#以下の学習を実行すると、行動価値Qを求められる。Qの各行が位置に対応し、たとえば0行1列目の値は0から1に移動する行動の価値となる。
#p_stateのpはpresent(現在)、n_state,n_actionsのnはnext(次)のn
for i in range(10000):#1万回繰り返し学習を行う
p_state = np.random.randint(0,9)#現在の状態をランダムに選択
n_actions = []#次の行動の候補を入れる箱
for j in range(9):
if reward[p_state,j] >= 1:#rewardの各行が1以上のインデックスを取得
n_actions.append(j)#これでp_stateの状態で移動できる場所を取得
n_state = np.random.choice(n_actions)#行動可能選択肢からランダムに選択
#Q値の更新。学習率が小さいほど現在の行動価値が重視され、更新がゆるやかとなる
#ここでQ学習に用いる「たった一つの数式」を利用して行動価値を学習していく
Q[p_state,n_state] = (1-alpha)*Q[p_state,n_state]+alpha*(reward[p_state,n_state]+gamma*Q[n_state,np.argmax(Q[n_state,])])
#最短ルート表示関数の定義。Q値が最も高い行動をappendで追加しているだけ
def shortest_path(start):#0~8の数字を入力。好きなところからスタート可能
path = [start]#pathに経路を追加していく
p_pos = start#p_posは現在位置(positionの略)
n_pos = p_pos#n_pos(次の位置)にいったんp_posを代入
while(n_pos != 8):#n_posがゴール(8)になるまで繰り返し行動を選択
n_pos = np.argmax(Q[p_pos,])#各位置の行動価値が最も高い行動を選択
path.append(n_pos)#経路をpathに追加
p_pos = n_pos#行動後が次のp_posとなる
return path
print(shortest_path(0))#スタートを0として最短経路を表示
出力結果

→最短ルートが正しく表示された。スタート地点を変えても正しい結果が得られた。
Section2:AlphaGo
・AlphaGoは、グーグル傘下のDeepMind社によって開発された囲碁AI。
・人間の棋譜のデータを元に、コンピューターが自分自身との対戦を数千万回にわたり繰り返すことで強化された
・モンテカルロ木探索と呼ばれる探索アルゴリズムを組み合わせたことが特徴
■強化学習のステップ
1.教師あり学習によるRollOutPolicyとPolicyNetの学習
2.強化学習によるPolicyNetの学習
3.強化学習によるValueNetの学習
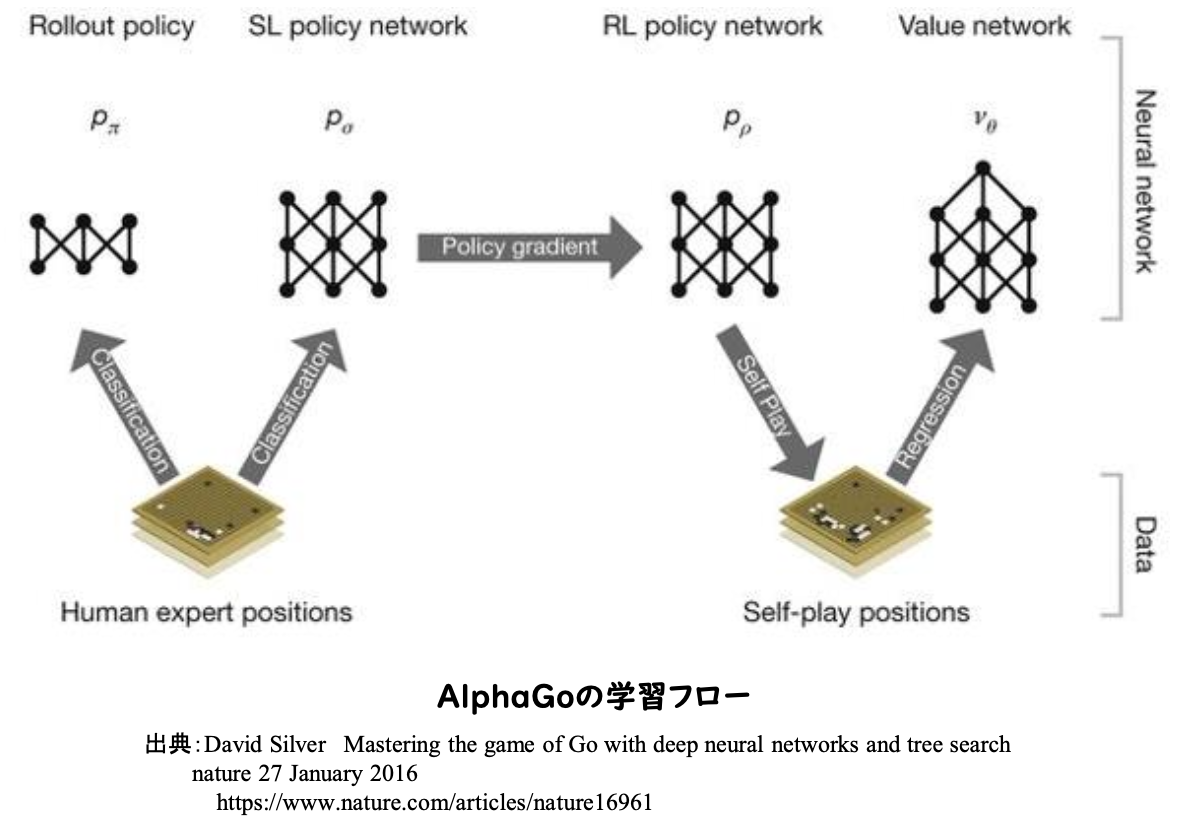
※RollOutPolicy:NNではなく線形の方策関数。探索中に高速に着手確率を出すために使用される
※PolicyNet:どこに打つかを決める方策関数
※ValueNet:そこに打つとどうなるかを決める価値観数
具体的には、
1.PolicyNetの教師あり学習。ネット囲碁対局サイトの棋譜データから3000万局面分の教師を用意し、教師と同じ着手を予測できるよう学習を行う。2.PolicyNetの強化学習。現状のPolicyNetとPolicyPoolからランダムに選択されたPolicyNetと対局シミュレーションを行い、その結果を用いて方策勾配法で学習を行う。3.ValueNetの学習。policyNetを使用して対局シミュレーションを行い、その結果の勝敗を教師として学習する。
■AlphaGo Zero
・AlphaGoの進化版。主な違いは以下。
1.教師あり学習を一切行わず、強化学習のみで作成
2.特徴入力からヒューリスティックな要素を排除し、石の配置のみにした
3.PolicyNetとValueNetを1つのネットワークに統合した
4.Residual Netを導入した
5.モンテカルロ木探索からRollOutシミュレーションをなくした
■Residual Network
・ネットワークにショートカット構造を追加して、勾配の爆発、消失を抑える効果を狙ったもの
・Residula Networkを使うことにより、100層を超えるネットワークでの安定した学習が可能となった
・基本構造はConvolution → BatchNorm → ReLU → Convolution → BatchNorm → Add → ReLU のBlockを1単位にして積み重ねる形
Section3:軽量化・高速化技術
■分散深層学習
・深層学習は多くのデータを使用したり、パラメータ調整のために多くの時間を使用したりするため、高速な計算が求められる。そのため、複数の計算資源(ワーカー)を使用し、並列的にニューラルネットを構成することで、効率の良い学習を行うようにしている。高速技術には、データ並列化、モデル並列化、GPUによる高速技術などがある。
■データ並列化
・親モデルを各ワーカーに子モデルとしてコピー
・データを分割し、各ワーカーごとに計算させる
・データ並列化は各モデルのパラメータの合わせ方で、同期型か非同期型か決まる
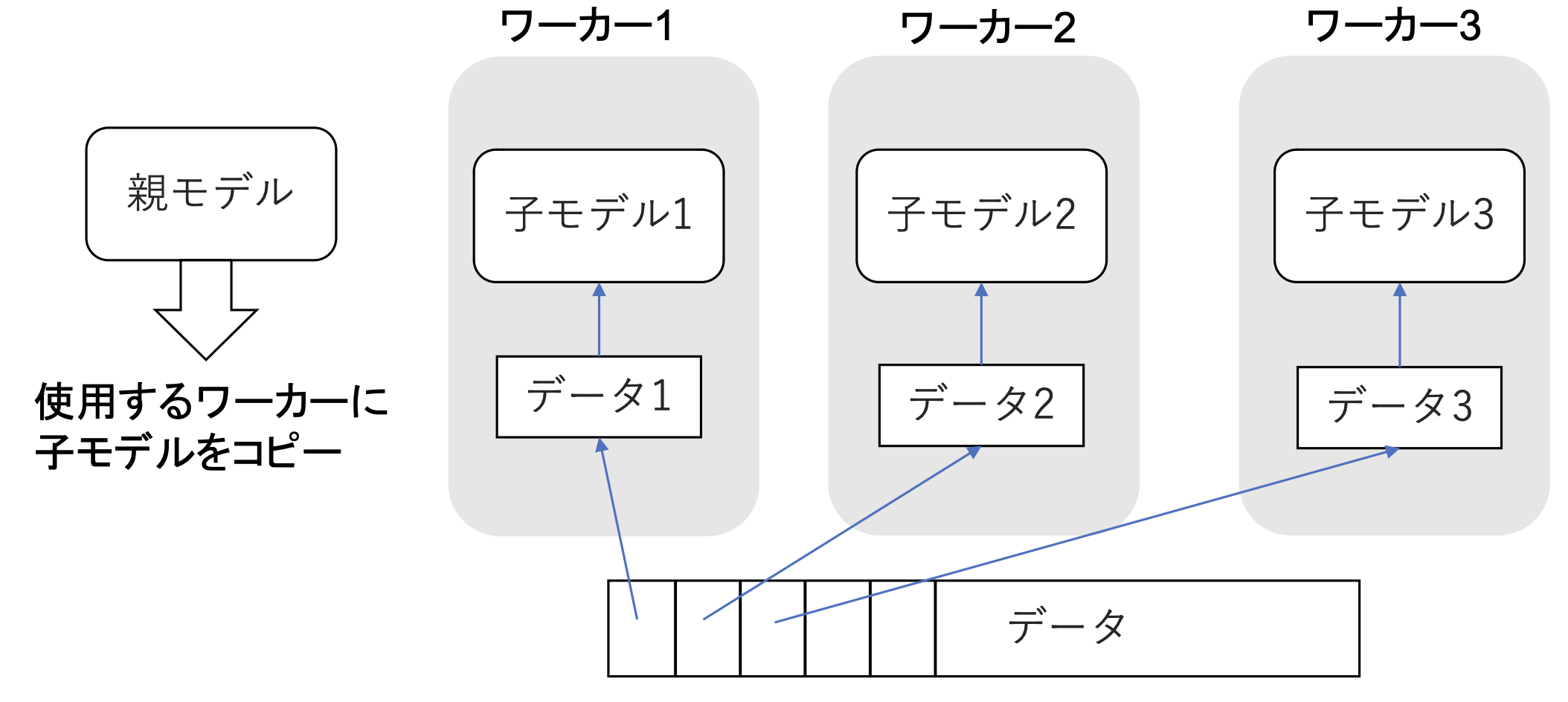
・処理のスピードは、お互いのワーカーの計算を待たない非同期型の方が早い。
・非同期型は最新のモデルのパラメータを利用できないので、学習が不安定になりやすい。
・現在は同期型の方が精度が良いことが多いので、主流となっている。
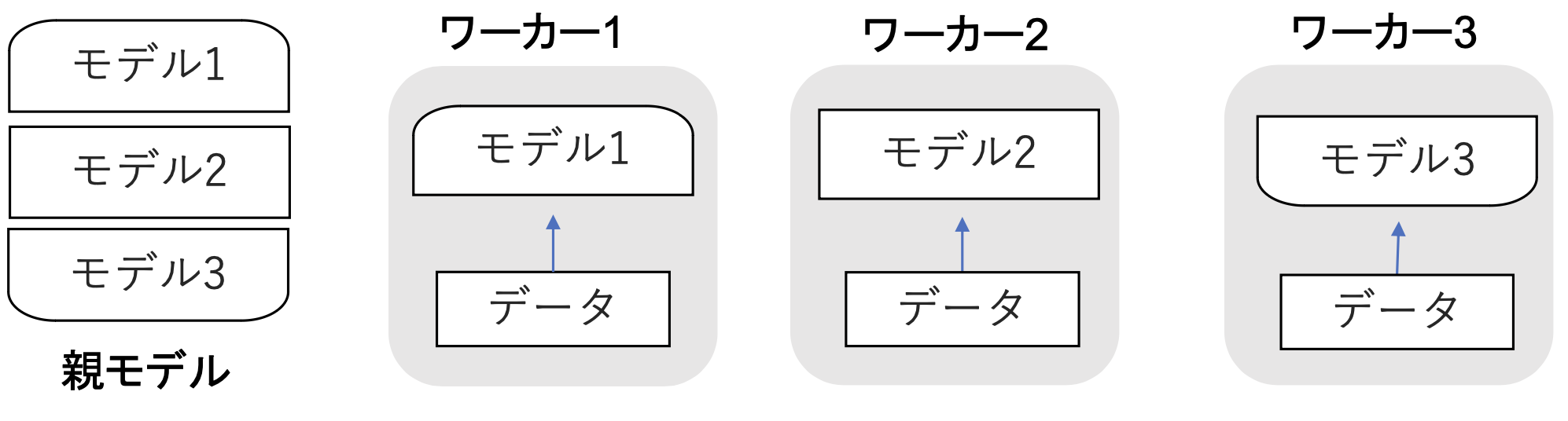
■モデル並列化
・親モデルを各ワーカーに分割し、それぞれのモデルを学習させる。全てのデータで学習が終わった後で、一つのモデルに復元
・モデルが大きい時はモデル並列化を、データが大きい時はデータ並列化をすると良い。
・モデルのパラメータ数が多いほど、スピードアップの効率も向上する。
■GPUによる高速化
・GPGPU (General-purpose on GPU)
→元々の使用目的であるグラフィック以外の用途で使用されるGPUの総称
・CPU
→高性能なコアが少数
→複雑で連続的な処理が得意。
・GPU
→比較的低性能なコアが多数
→簡単な並列処理が得意
→ニューラルネットの学習は単純な行列演算が多いので、高速化が可能
■モデルの軽量化
・モデルの精度を維持しつつパラメータや演算回数を低減する手法の総称
・モデルの軽量化はモバイル、IoT機器において有用な手法
・モバイル端末やIoTはパソコンに比べ性能が大きく劣る
→モデルの軽量化は計算の高速化と省メモリ化を行うためモバイル、IoT機器と相性が良い手法
・代表的な軽量化の手法は3つ:量子化、蒸留、プルーニング
■量子化
・ネットワークが大きくなると大量のパラメータが必要となり、学習や推論に多くのメモリと演算処理が必要
→通常のパラメータの64bit浮動小数点を、32bitなど下位の精度に落とすことでメモリと演算処理の削減を行う
・利点:計算の高速化、省メモリ化
・欠点:精度の低下
→bit数が小さいほど精度が下がるが、実際はほぼ精度は変わらない。現在は多少精度が悪くなっても16bitなどを用いて、計算速度を優先するのが有効な手法となっている。ただし、極端に精度が落ちない程度に量子化する必要あり。
・省メモリ化
■蒸留
・精度の高いモデルはニューロンの規模が大きな規模が大きなモデルになっている。そのため、推論に多くのメモリと演算処理が必要
→規模の大きなモデルの知識を使い、軽量なモデルの作成を行う。このことを蒸留という。
・蒸留は教師モデルと生徒モデルの2つで構成される
教師モデル:予測精度の高い、複雑なモデルやアンサンブルされたモデル
生徒モデル:教師モデルをもとに作られる軽量なモデル
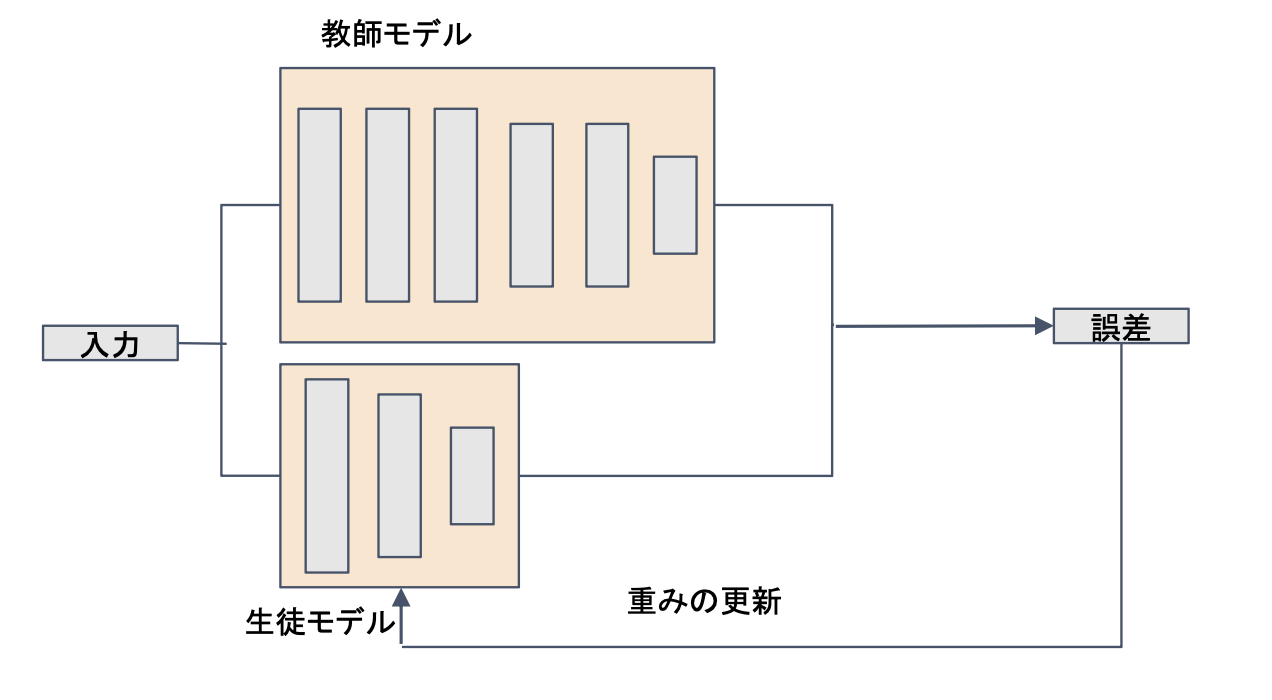
・教師モデルの重みを固定し生徒モデルの重みを更新していく
・誤差は教師モデルと生徒モデルのそれぞれの誤差を使い重みを更新していく
→教師モデルの精度を引き継ぎながら、生徒モデルを学習させることができる。
■プルーニング
・ネットワークが大きくなると大量のパラメータが必要になるが、全てのニューロンの計算が精度に寄与しているわけではない。
→モデルの精度に寄与が少ないニューロンを削減する(プルーニング)ことで、モデルの軽量化、高速化が見込まれる。
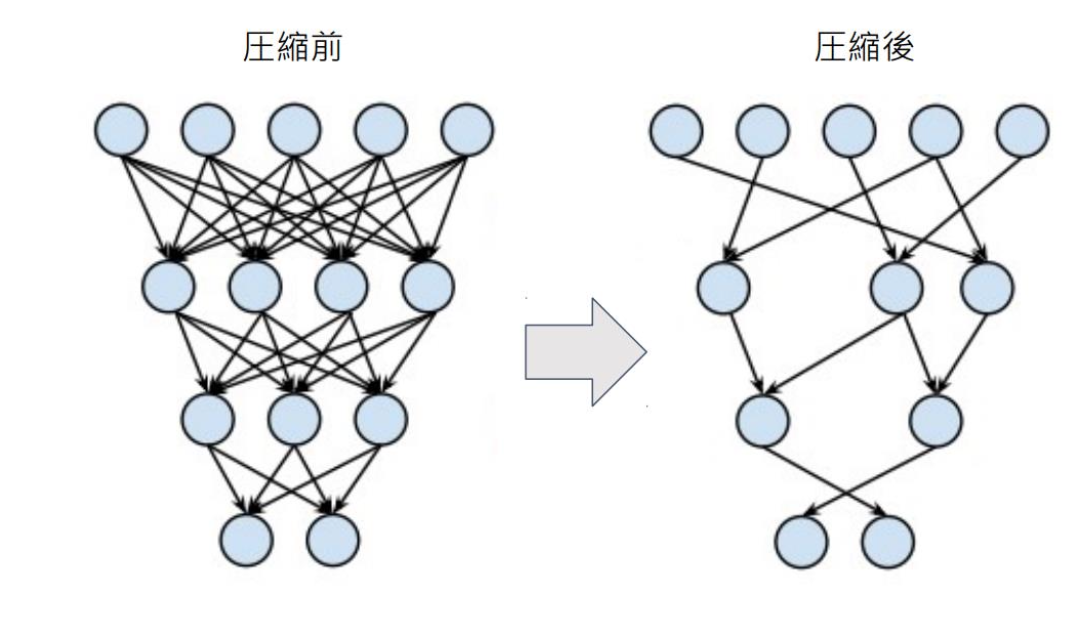
・ニューロンの削減の手法:重みが閾値以下の場合ニューロンを削減し、再学習を行う
→閾値を大きくすれば、ニューロンは大きく削減できるが精度も減少する
Section4:応用技術
■MobileNet
・ディープラーニングモデルの軽量化・高速化・高精度化を実現
・一般的な畳み込みレイヤーの計算量を考える
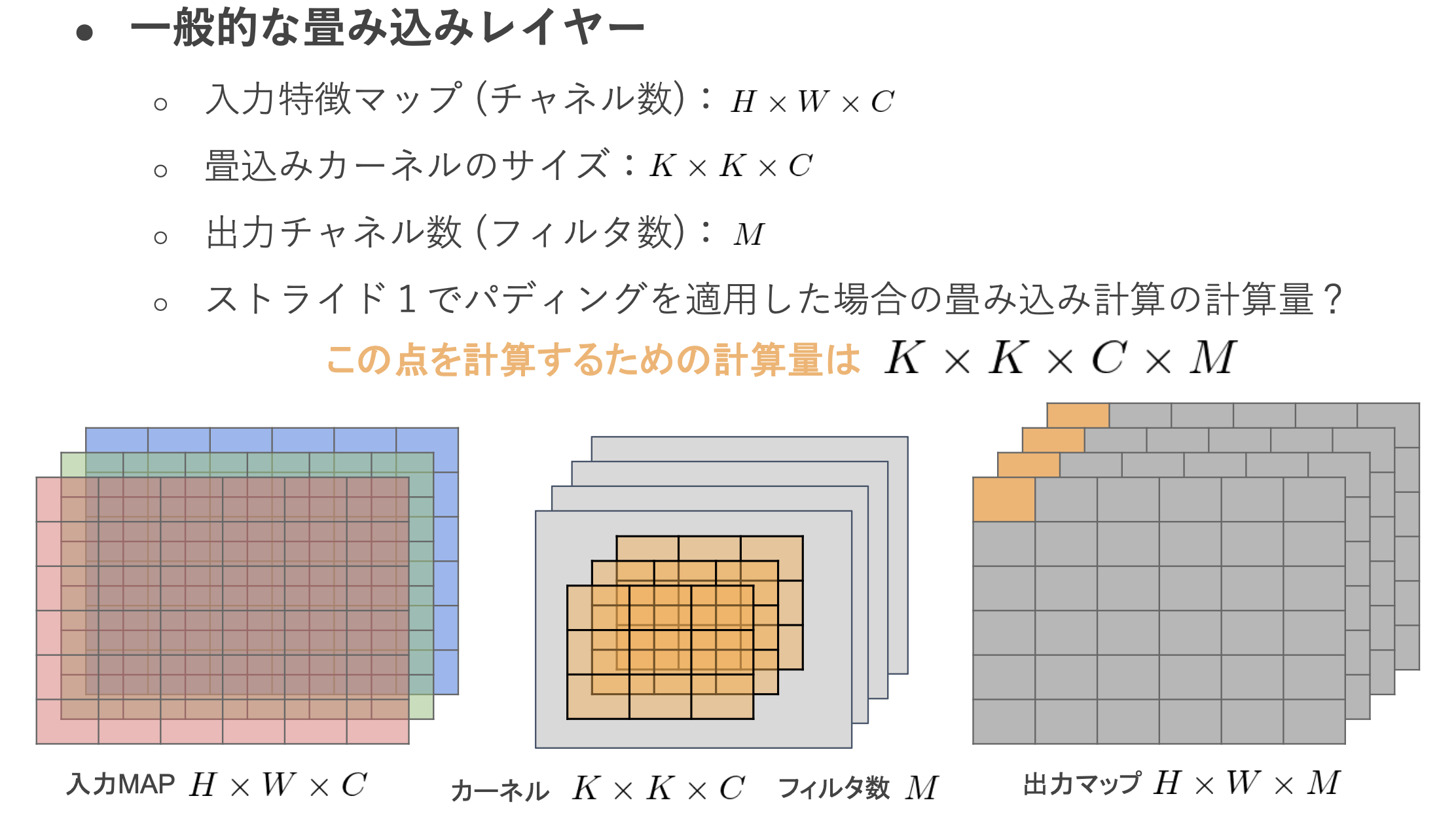
→一番右側の出力マップの左上の点を計算するための計算量は、K * K * C * Mとなる
→また、出力マップ全体の計算量は、H * W * K * K * C * Mとなる
→このように一般的な畳み込みレイヤーは計算量が多い。
→Depthwise ConvolutionとPointwise Convolutionの組み合わせで軽量化を実現
・Depthwise Convolution
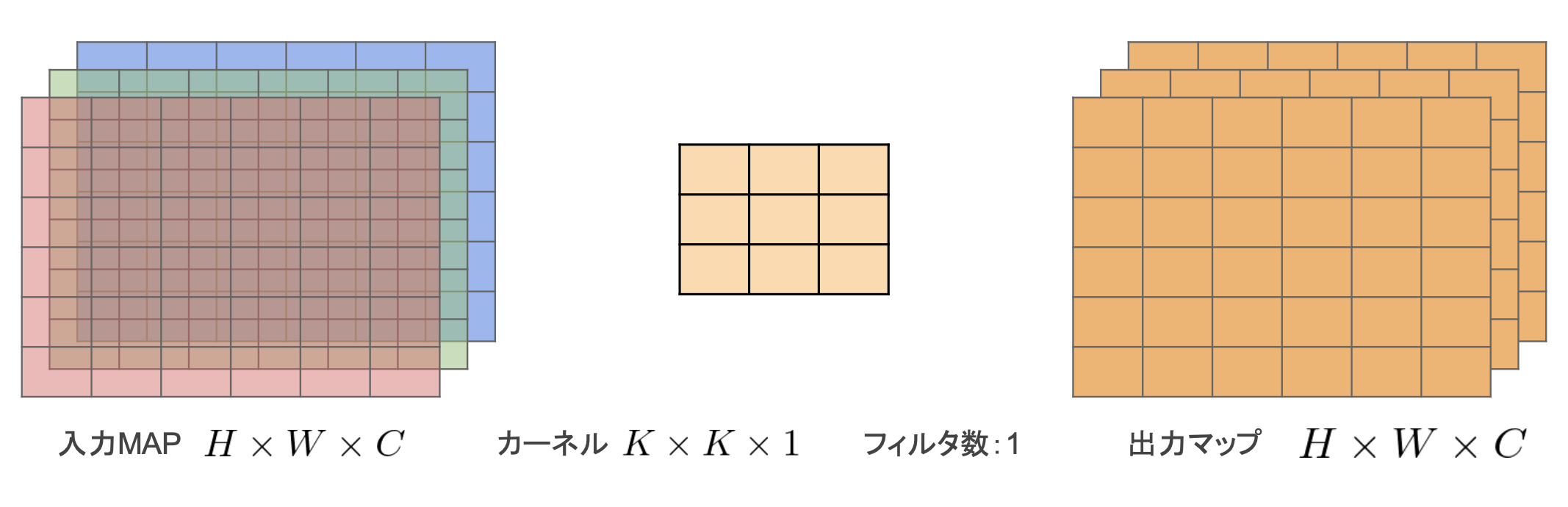
・フィルタは1固定
・入力マップのチャネルごとに畳み込みを実施
・通常の畳み込みカーネルは全ての層にかかっていることを考えると計算量が大幅に削減可能
→出力マップの計算量:H * W * C * K * K
(一般的な畳み込み層の計算量だと、H * W * K * K * C * M)
・Pointwise Convolution
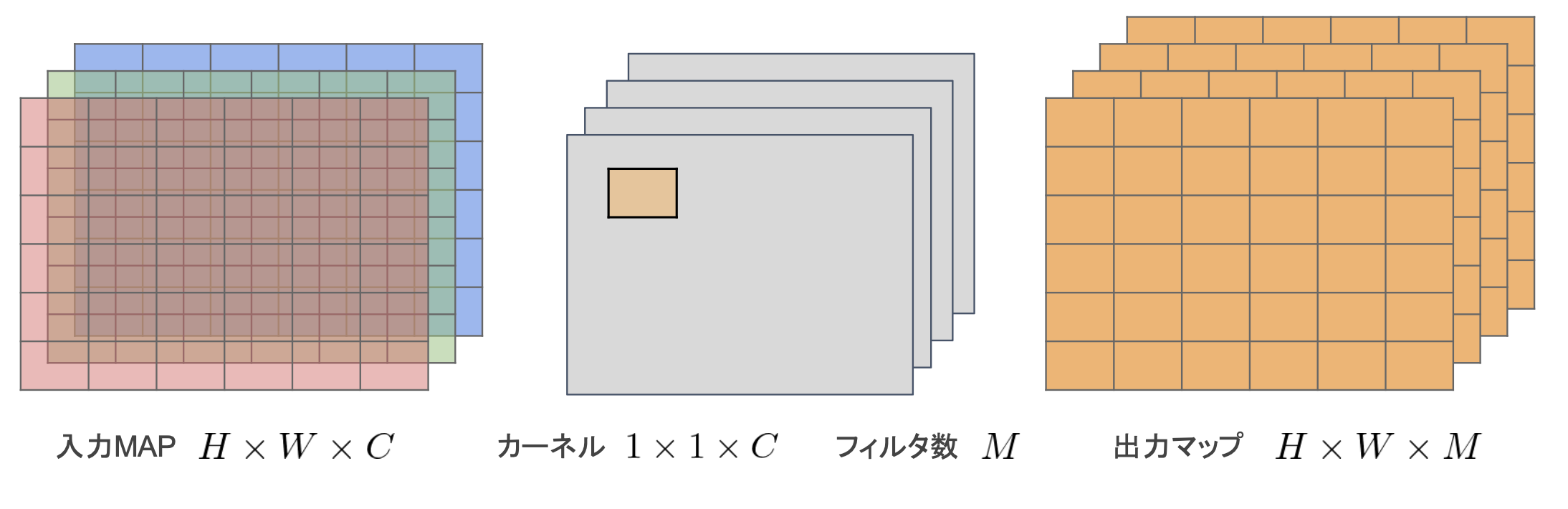
・カーネルサイズを1*1に固定
・入力マップのポイントごとに畳み込みを実施
・出力マップ(チャネル数)はフィルタ数分だけ作成可能 (任意のサイズが指定可能)
→出力マップの計算量:H * W * C * M
■DenseNet
・畳込みニューラルネットワークアーキテクチャの一種。
・ニューラルネットワークでは層が深くなるにつれて、学習が難しくなるという問題があった。→Residual Network(ResNet)などの CNNアーキテクチャでは前方の層から後方の層へアイデンティティ接続を介してパスを作ることで問題を対処した。

・Dense Blockでは出力層に前の層の入力を足しあわせる処理がなされた
・Dense Block間はTransition Layerと呼ばれ、特徴マップのサイズを変更し、ダウンサンプリングを行っている
・DenseNetとResNetの違い
→DenseBlockでは前方の各層からの出力全てが後方の層への入力として用いられる
→RessidualBlockでは前1層の入力のみ後方の層へ入力される
・DenseNet内で使用されるDenseBlockと呼ばれるモジュールでは、成長率(Growth Rate)と呼ばれるハイパーパラメータが存在する
■Layer正規化/Instance正規化(Layer Norm/Instance Norm)
・Batch Norm
→ミニバッチに含まれるsampleの同一チャネルが同一分布に従うよう正規化
→H x W x CのsampleがN個あった場合に、N個の同一チャネルが正規化の単位
→ミニバッチのサイズを大きく取れない場合には、効果が薄くなってしまう。
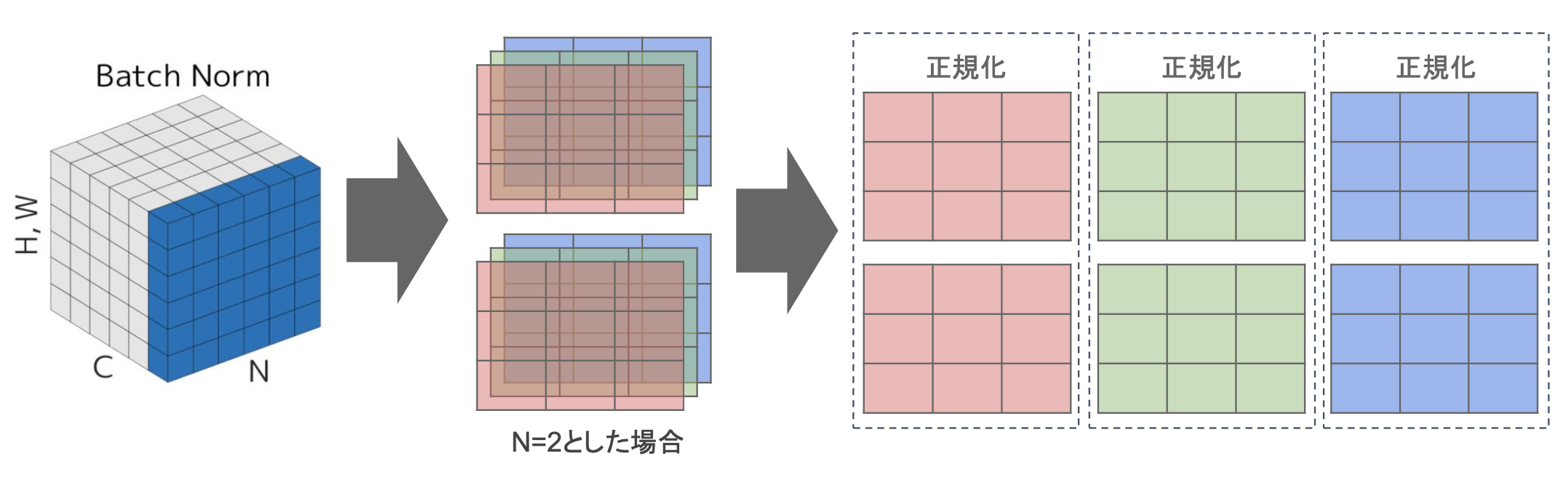
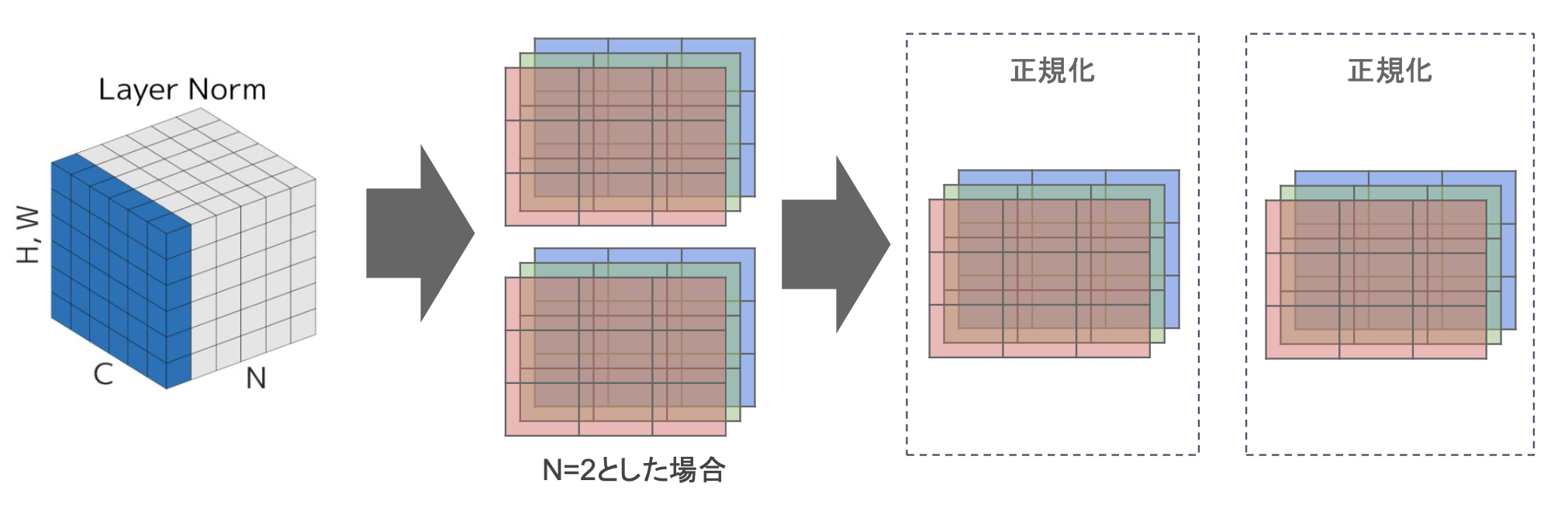
・Layer Norm
→それぞれのsampleの全てのpixelsが同一分布に従うよう正規化
→N個のsampleのうち一つに注目。H x W x Cの全てのpixelが正規化の単位。
→ミニバッチの数に依存しないので、Batch Normの問題を解消できていると考えられる。
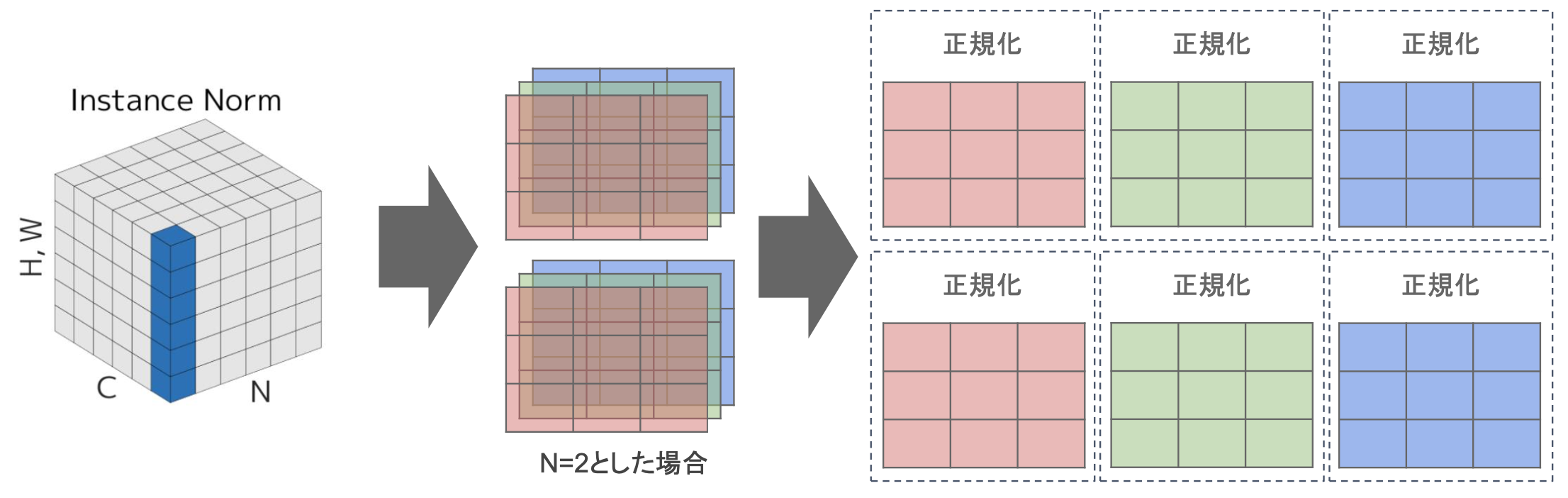
・Instance Norm
→各sampleの各channel毎に正規化
→コントラストの正規化に寄与・画像のスタイル転送やテクスチャ合成タスクなどで利用
■WaveNet
・生の音声波形を生成する深層学習モデル
・Pixel CNN(高解像度の画像を精密に生成できる手法)を音声に応用したもの
・時系列データに対して畳み込みを適用する
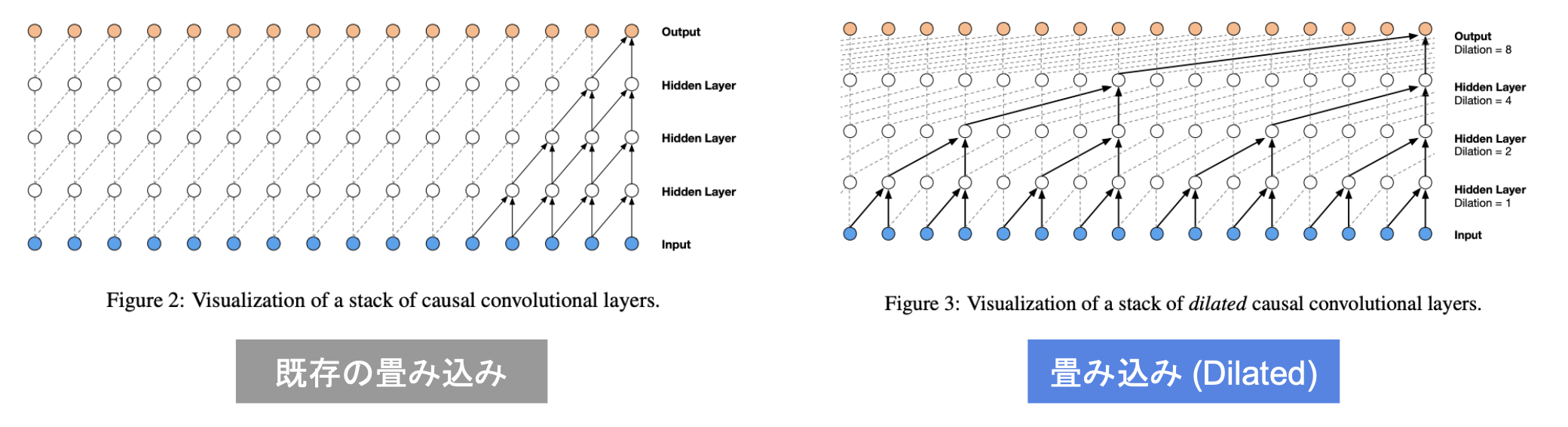
・Dilated Convolution
→層が深くなるにつれて畳み込みリンクを離す
→受容野を簡単に増やすことができるという利点がある
→下図ではDilated = 1,2,4,8となっている
確認テスト
Q:Depthwise Convolitionはチャネル毎に空間方向へ畳み込む。すなわち、チャネル毎に$D_K×D_K×1$のサイズのフィルターをそれぞれ用いて計算を行うため、その計算量は(い)となる。
A:(い):H * W * C * K * K
Q:次にDepthwise Convolutionの出力をPointwise Convolutionによってチャネル方向に畳み込む。すなわち、出力チャネル毎に1×1×Mサイズのフィルターをそれぞれ用いて計算を行うため、その計算量は(う)となる。
A:(う):H * W * C * M
Q:深層学習を用いて結合確率を学習する際に、効率的に学習が行えるアーキテクチャを提案したことが WaveNet の大きな貢献の1つである。提案された新しいConvolution型アーキテクチャは(あ)と呼ばれ、結合確率を効率的に学習できるようになっている。(あ)を用いた際の大きな利点は、単純なConvolution layerと比べて(い)ことである。
A:(あ):Dilated causal convolution、(い):パラメータ数に対する受容野が広い
ResNet(転移学習)
・転移学習:教師あり学習において、目的とするタスクでの教師データが少ない場合に、別の目的で学習した学習済みモデルを再利用すること
・ImageNet:1400万件以上の写真のデータセット。様々なAI/MLモデルの評価基準になっており、学習済みモデルも多く公開されている。ImageNetを元に事前学習モデルを作ることに利用。
・ImageNet学習済みモデル:ResNet50、ResNet101、ResNet152などがある。数が大きいほどパラメータ数が大きい。
■ResNetの特徴
1.SkipConnection
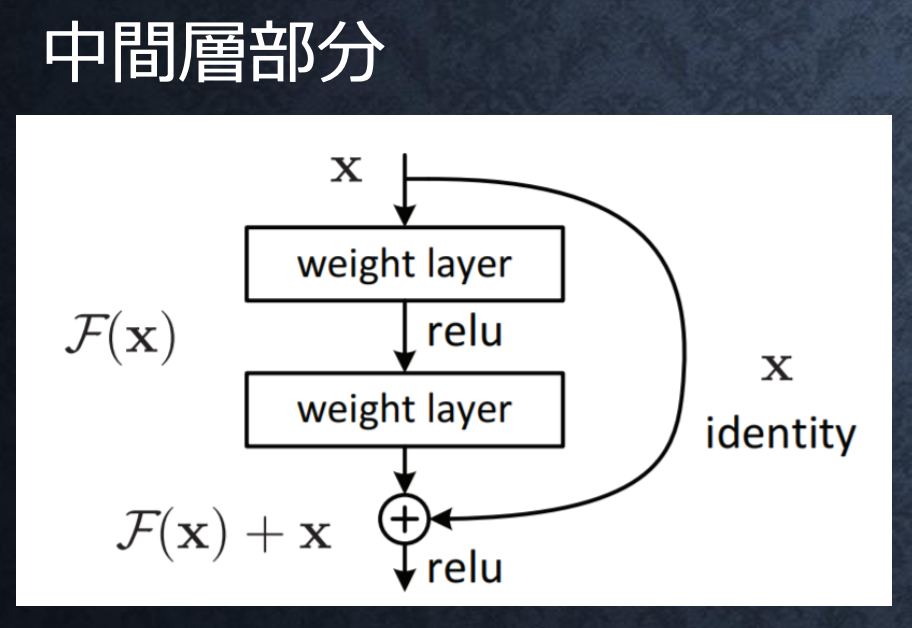
→深い層の積み重ねでも学習可能になり、勾配消失や勾配爆発が起きにくくなった。
2.Bottleneck構造
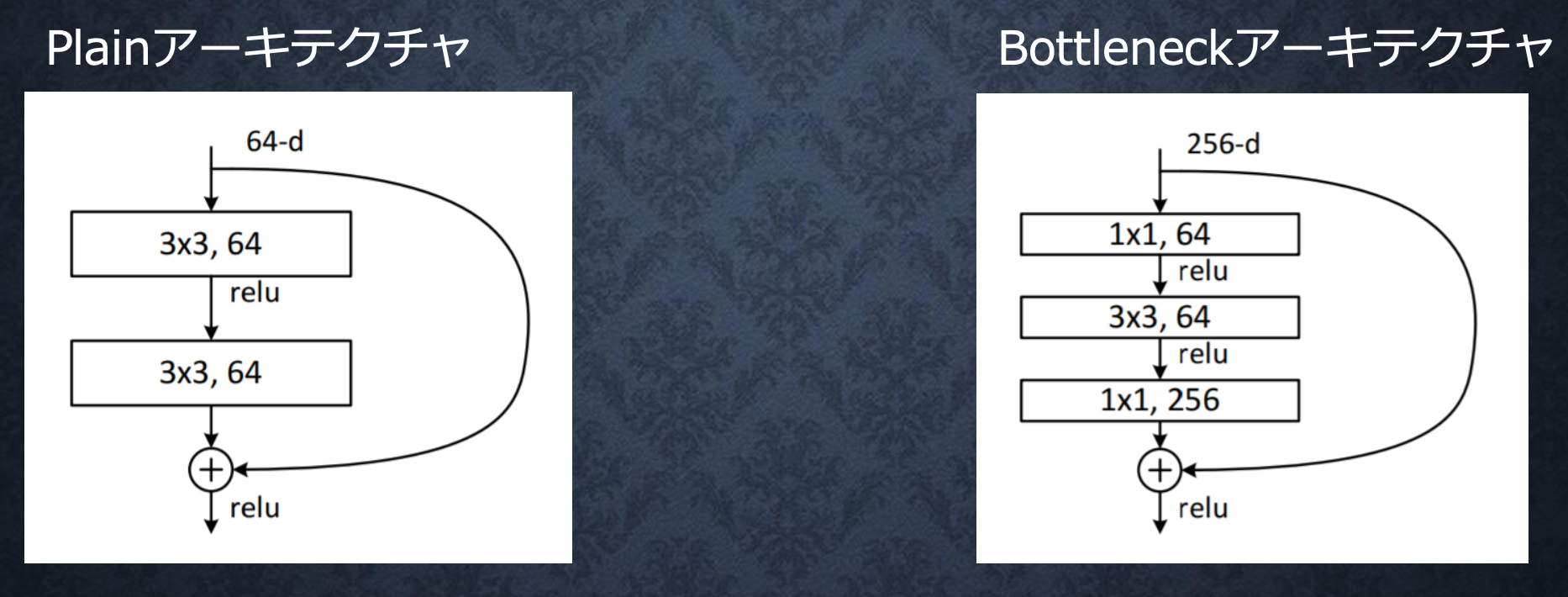
→同一計算コストで1層多い構造が取れる。
■Wide ResNet
・フィルタ数をk倍したResNet
・パラメータを増やす方法として、層を深くするのではなく各層を広く(Wide)した。
■ドメインシフト
・機械学習のコンテキストにおいて、訓練データの分布とテストデータの分布が異なる現象
・機械学習モデルが未見のデータに対して期待通りの性能を示さなくなる主要な原因の一つ
→訓練データとテストデータの分布が近いと、テストデータの予測精度が高い
→訓練データとテストデータの分布が遠いと、テストデータの予測精度が低い
・ドメインシフトの原因:時間的変動・地域的変動・機械的変動・操作的変動
・ドメインシフトの対処方法:データの再収集・データ拡張・転移学習・ドメイン適応・不変表現学習
実装演習
・tf_flowersというデータセットを用いて、以下3つの結果を比較。
→事前学習なしでResNetを利用する / ImageNetによる事前学習を利用する / ImageNetによる事前学習を利用する(ファインチューニングあり)
→それぞれの学習曲線は以下の通り。
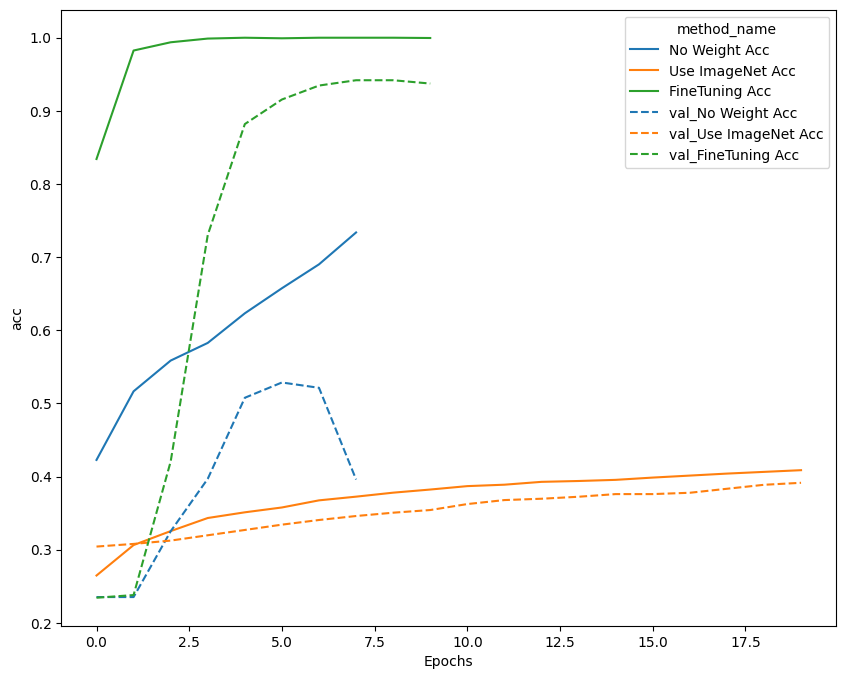
※No Weight Acc:事前学習なし、Use ImageNet Acc:事前学習あり、FineTuning Acc:事前学習あり+ファインチューニング
→ファインチューニングありのものが最もスコアが良かった。事前学習の結果を元に再学習させているので、さらに精度が良くなったと思われる。
・ResNetとWideResNetそれぞれで、転移学習とファインチューニングを実行
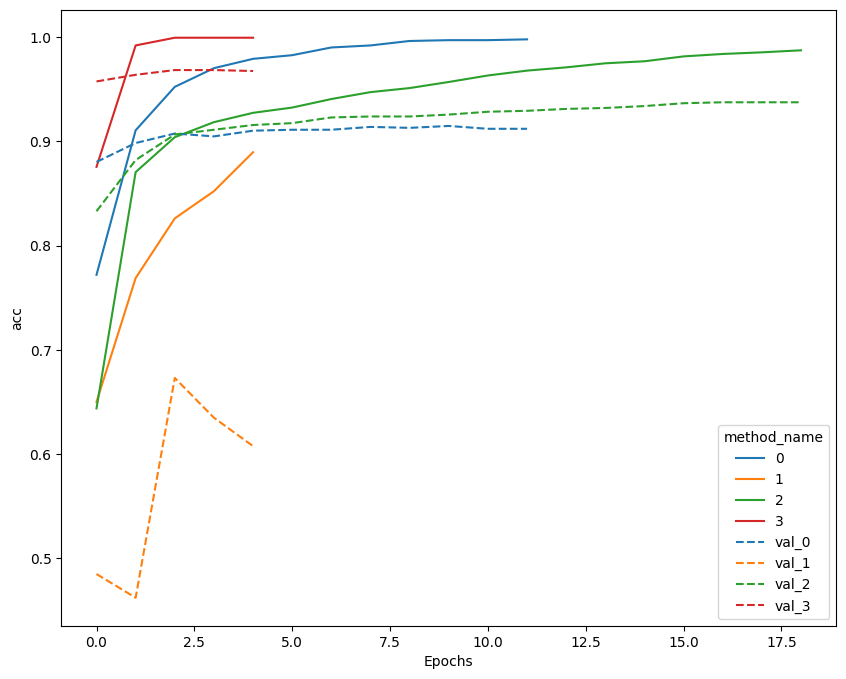
※0:ResNet+転移学習、1:ResNet+ファインチューニング、2:WideResNet+転移学習、3:WideResNet+ファインチューニング
→WideResNetを用いてファインチューニングしたものが最もスコアが良かった。上記でもファインチューニングを用いたものがスコアが良かったことから、ファインチューニングはスコアの向上に大きく貢献しているものと考えられる。
EfficientNet
・AlexNet以降は、CNNモデルを大規模にスケールアップすることで精度を改善するアプローチが主流となった
・従来では、幅、深さ、解像度を「適当」にスケールアップしていた
幅:1レイヤーのサイズ(ニューロンの数)
深さ:レイヤーの数
解像度:入力画像の大きさ
・精度を向上できたものの、モデルが複雑で高コストであるのが問題
→2019年に開発したEfficientNetモデル群では、効率的なスケールアップの規則を採用することで、開発当時の最高水準の精度を上回り、同時にパラメータ数を大幅に減少することに成功
■EfficientNetとCNNモデルのスケールアップ
・幅、深さ、解像度などを何倍増やすかは、複合係数(Compound Coefficient)を導入することで最適化
・EfficientNetではCompound Coefficientに基づいて、深さ・広さ・解像度を最適化したことにより、「小さなモデル」かつ高い精度を達成
・モデルが小さくなったことで、さらなる効率化に貢献(小型化と動作の高速化)
■EfficientNetの性能
・ImageNetデータを用いた、既存のCNNとEfficientNet系モデルを比較
→EfficientNetは精度と効率の両側面で優れている
→パラメータの数と計算量は数倍〜1桁減少
→転移学習でも性能を発揮(シンプルかつ簡潔な構造、汎用性が高い)
■Compound Scaling Method(複合スケーリング手法)の詳細
・Depth(d):
→ネットワークの層を深くすることで、表現力を高くし、複雑な特徴表現を獲得できる
・Width(w):
→ユニット数を増やすことでより細かい特徴表現を獲得し、学習を高速化できる
→しかし、深さに対してユニット数が大きすぎると、高レベルな特徴表現を獲得しにくくなる
・Resolution(r):
→高解像度の入力画像を用いると、画像中の詳細なパターンを見出せる
→時代が進むにつれてより大きいサイズの入力画像が使われるようになってきた
・畳み込み演算の演算量FLOPSはd,w2,r2に比例
Vision Transformer
・Vision Transformerは言語処理用に開発されたTransformerを画像分類タスクに応用したモデル
・画像をどのように系列データとしてにTransformerに入力するかがポイント
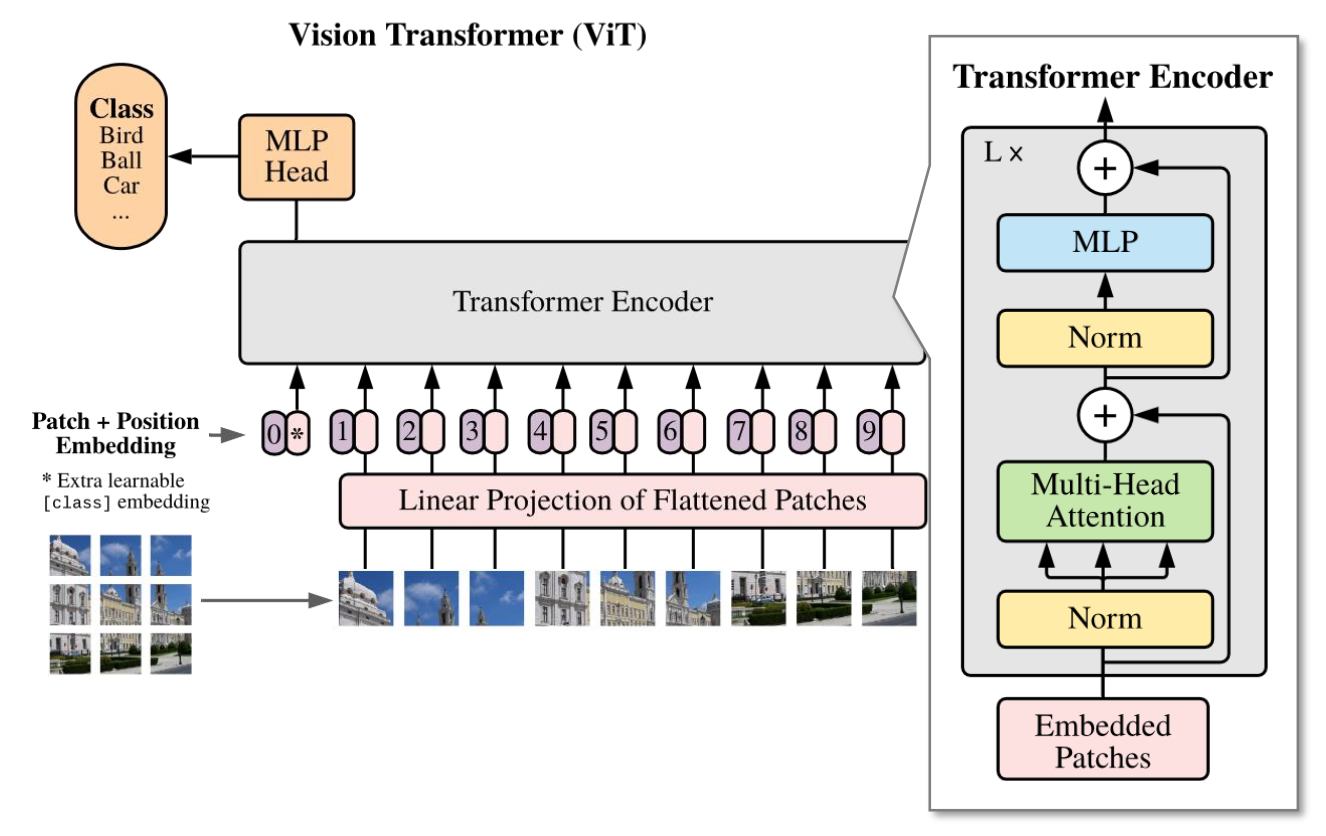
■画像特徴量の入力方法(画像の”トークン”系列化)
1.画像をパッチに分割し系列化:𝑁個の画像パッチで構成される系列
2.パッチごとにFlatten化:“トークン(単語)”化 → これを入力値に使用
■Vision Transformerのアーキテクチャ(Transformer Encoderの使用)
・Transformer Encoderへの入力値の準備
1.画像データから計算したEmbedding表現(埋込表現)を計算
2.系列の最初に[CLS]Tokenという特別な系列値を付加
3.パッチの位置関係を示すPosition Embeddingの付加
・Transformer Encoder:言語処理向けのオリジナルと同等の構造
・MLP Head:[CLS]Token系列値の出力特徴量から分類結果を出力
■Vision Transformerにおける事前学習とファインチューニング
・ViTの事前学習は、教師ラベル付きの巨大データセットで行われ、性能がデータセット規模の影響を受ける
・ファインチューニングでは、MLP Head部分を取り換えることで、分類タスクにおけるクラス数の違いに対応する。
・ファインチューニングで、事前学習より高い解像度の画像に、Position Embeddingの変更のみで対応できる。
■性能とその評価
・事前学習におけるデータセットが大規模な場合において、既存手法より高性能。
・事前学習のデータセットが小規模な場合、既存手法(CNN)に比べ低性能。
・同計算量において、既存手法より高性能。大計算量域でさらなる性能向上の余地がある。
物体検知とSS解説
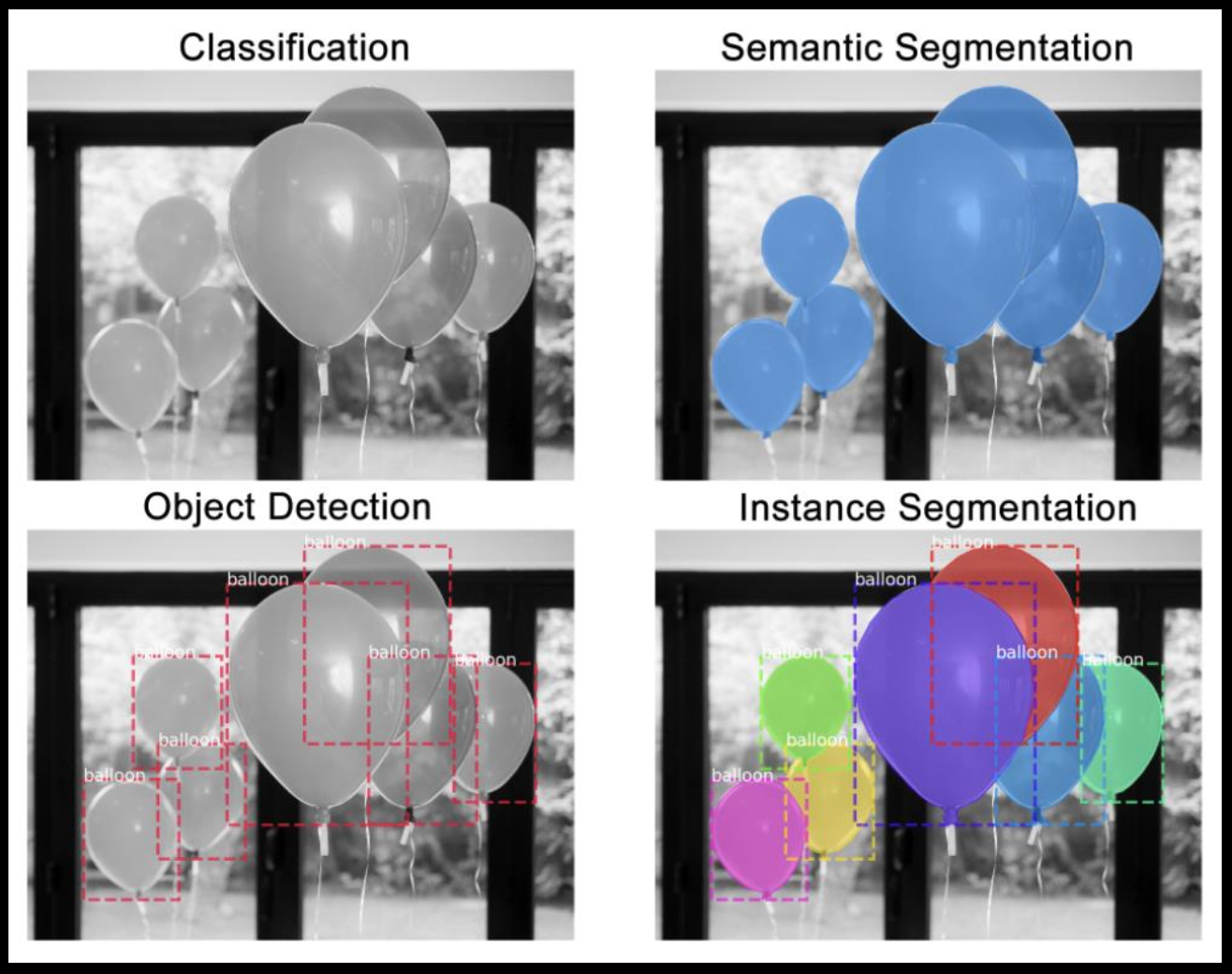
■広義の物体認識タスク
・入力:画像、カラーモノクロは問わない。
・出力:以下の4つに分かれる
Classification(分類):(画像に対し単一または複数の)クラスラベル
Object Detection(物体検知):Bounding Box[bbox/BB]、どこに何があるか
Semantic Segmentation(意味領域分割):(各ピクセルに対し単一の)クラスラベル
Instance Segmentation(個体領域分割):(各ピクセルに対し単一の ) クラスラベル + インスタンスの区別
■物体検出タスクの種類
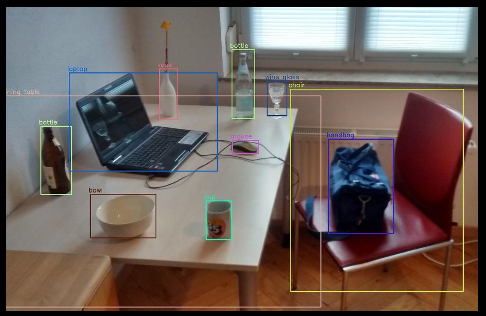
・物体検出
目的:画像内の物体を検出し、それぞれの物体に対して境界ボックスを指定する
特徴:物体の位置とカテゴリーを特 定する。各物体が独立して検出される。
・セマンティックセグメンテーション
目的:画像内の全てのピクセルをカテゴリに分類する。
特徴:同じカテゴリーの物体でも個々に区別せず、全てのピクセルが何らかのカテゴリーに分類される

・パノプティックセグメンテーション
目的:セマンティックセグメンテーションと物体検出の組み合わせで、画像内の全ての物体を個別に認識し、それぞれのピクセルにカテゴリを割り当てる。
特徴:個々の物体を識別しつつ、画像内の全ピクセルをカバーする。

■代表的なデータセット
・さまざまなアルゴリズムを精度評価する時にデータセットが利用される。
・目的に応じたデータセットの選択を行う必要がある。
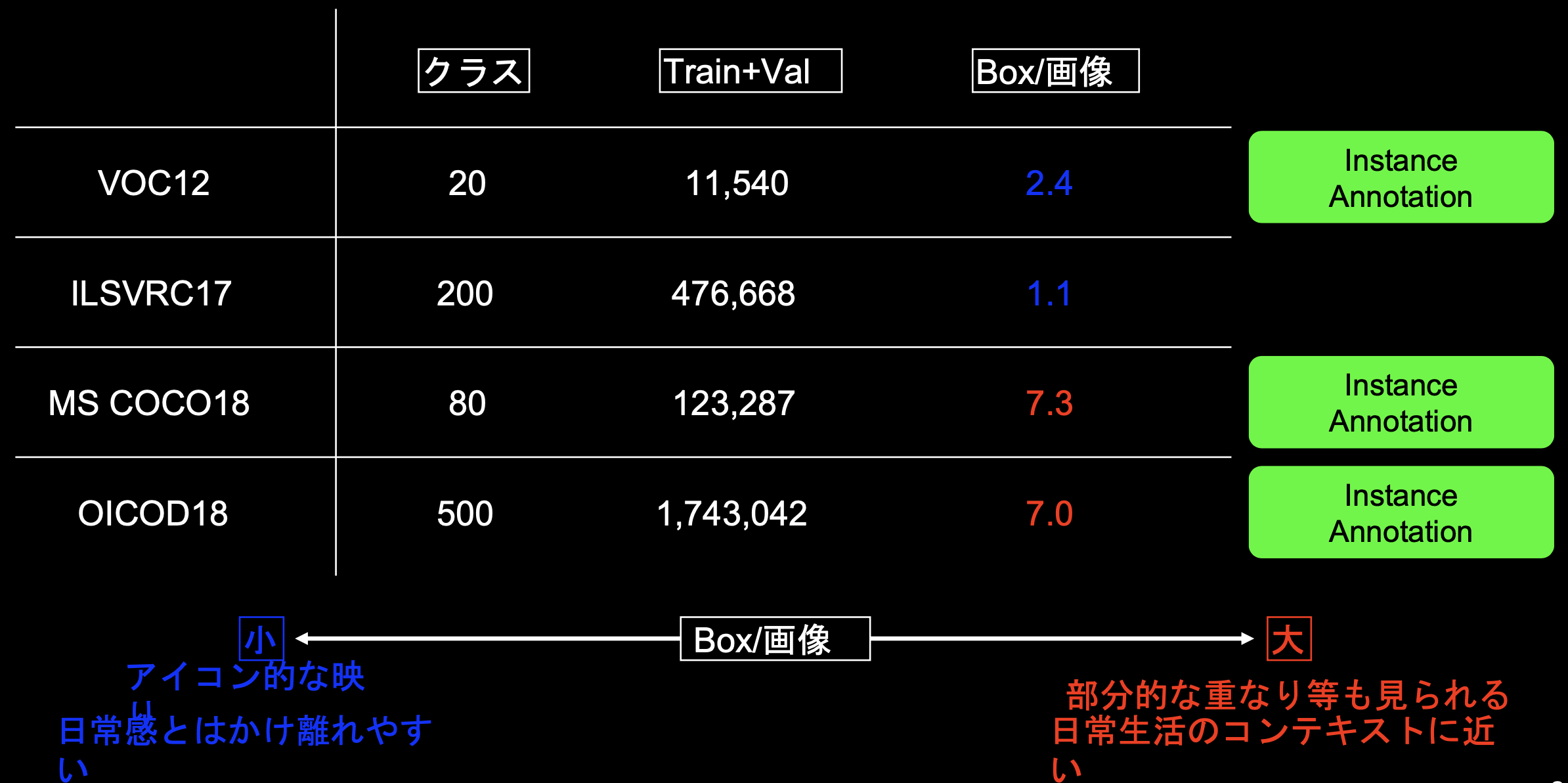
・いずれも物体検出コンペティションで用いられたデータセット
・ILSVRCだけはInstance Annotationがない
・目的に応じたBox/画像のデータセットを選択することがポイント!
※VOC:Visual Object Classes
※ILSVRC:ImageNet Scale Visual Recognition Challenge
※COCO:Common Object in Context
※OICOD:Open Images Challenge Object Detection
■IoU(Intersection over Union)
・物体検出においてはクラスラベルだけでなく, 物体位置の予測精度も評価したい!
$IoU = \frac{TP}{TP + FP + FN}$
※Confusion Matrixの要素を用いて表現
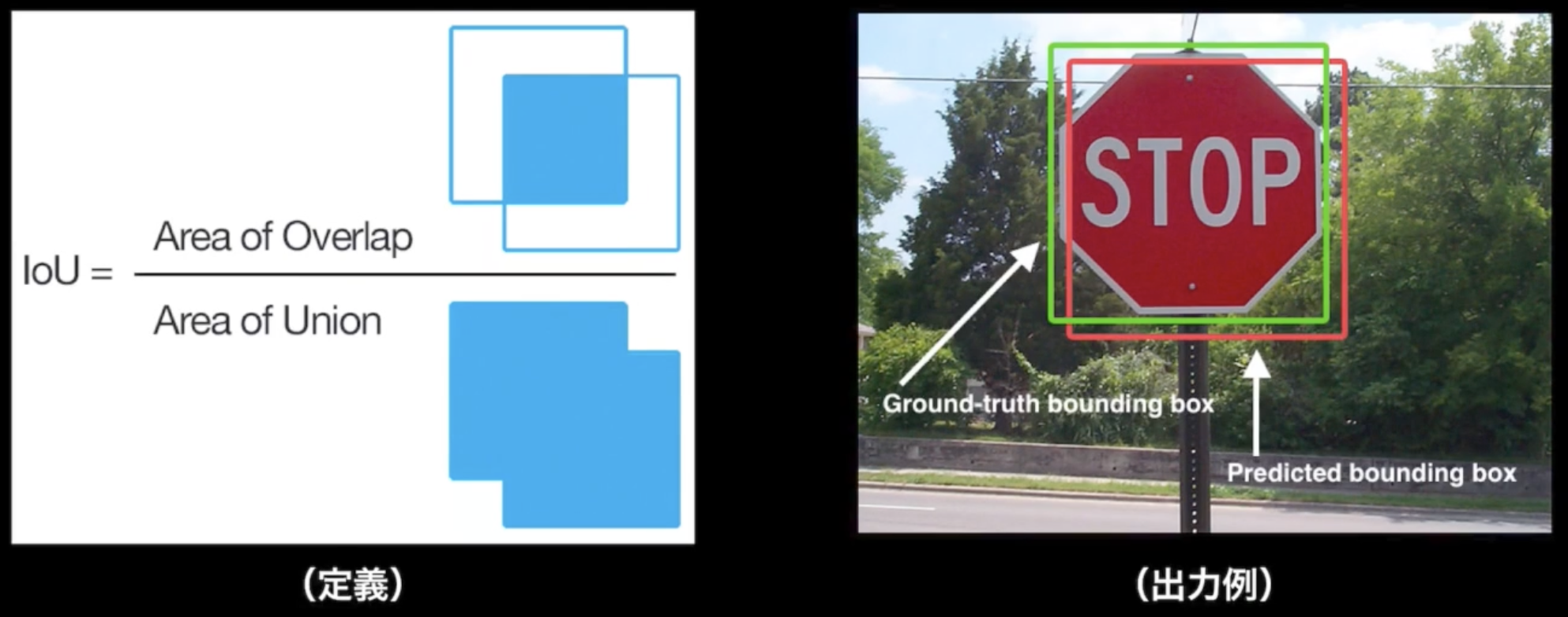
※重なっている部分がTP、他の部分がFPもしくはFN
※IoUは、Ground-Truth BBに対する占有面積、Predicted BBに対する占有面積ではないことに注意。
■入力1枚で見るPrecision/Recall
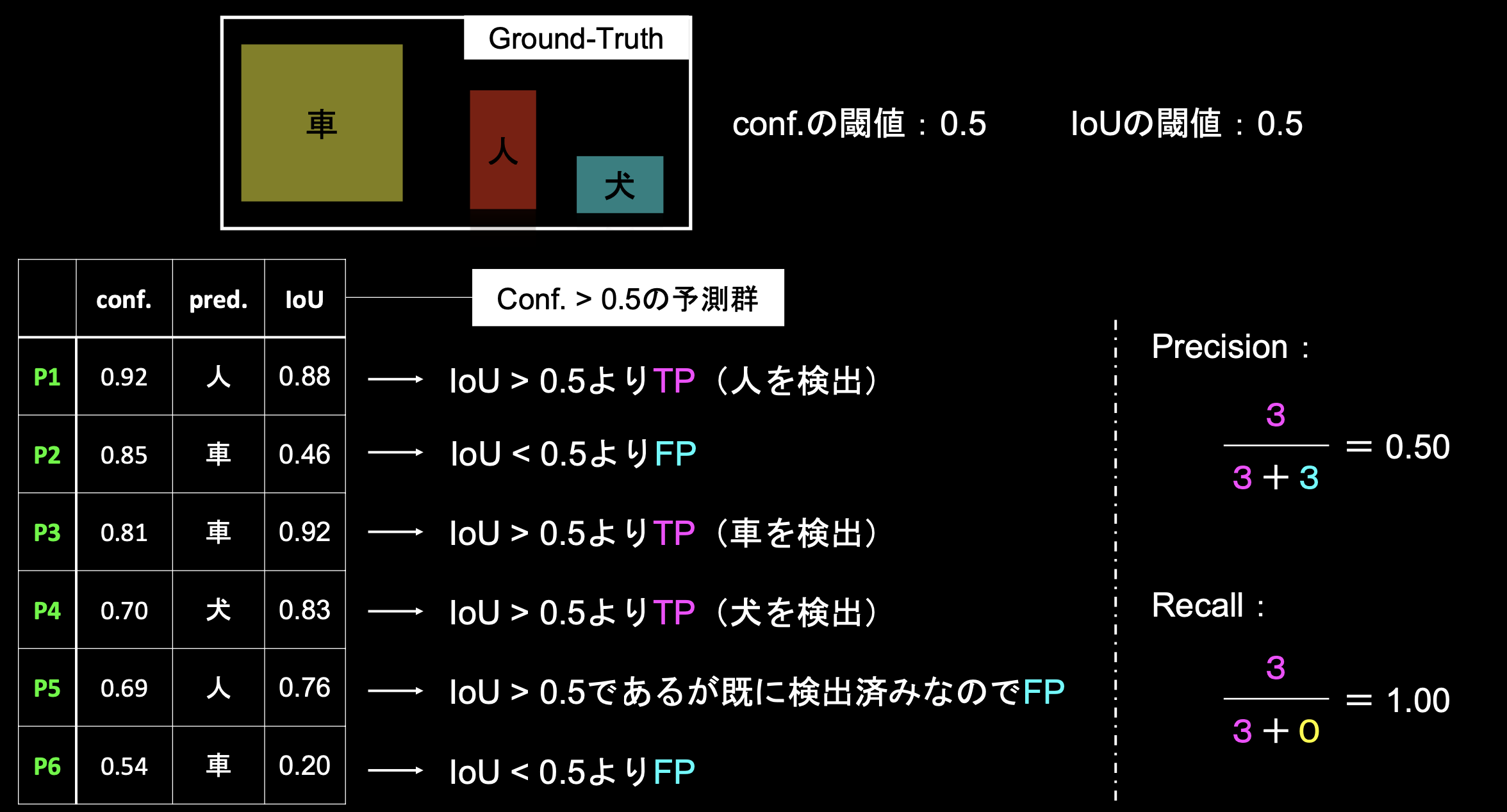
・Conf.>0.5 かつ IoU>0.5 → TP、Conf.>0.5 かつ IoU<0.5 → FP
・P5はConf.>0.5 かつ IoU>0.5だが、P1で既に人を検出済みなのでFPとなる
・FNのものはないため、Recallの分母のFN部分は0
■Precision/Recallの計算例(クラス単位)
・人の画像が4種類ある場合を見ていく。

・Conf.>0.5 かつ IoU>0.5 → TP、Conf.>0.5 かつ IoU<0.5 → FP
・P5はConf.>0.5 かつ IoU>0.5だが、P1で既にPic1の人を検出済みなのでFPとなる
・4枚目の画像が検出されていないため、Recallの分母のFN部分が1となる。
■精度評価の指標
・AP:Average Precision(PR曲線の下側面積)
$AP = \int_{0}^{1}P(R)dR$
・mAP:mean Average Precision
クラス数がCの時、$mAP = \frac{1}{C}\sum_{i=1}^C AP_i $
・FPS:Flames per Second
応用上の要請から, 検出精度に加え検出速度を指標としたもの
■深層学習以降の物体検知
・2012年、AlexNetの登場を皮切りに, 時代はSIFTからDCNNへ
※SIFT:Scale Invariant Feature Transform、DCNN以前のアルゴリズム、
・2013年以降のアルゴリズムは以下の通り
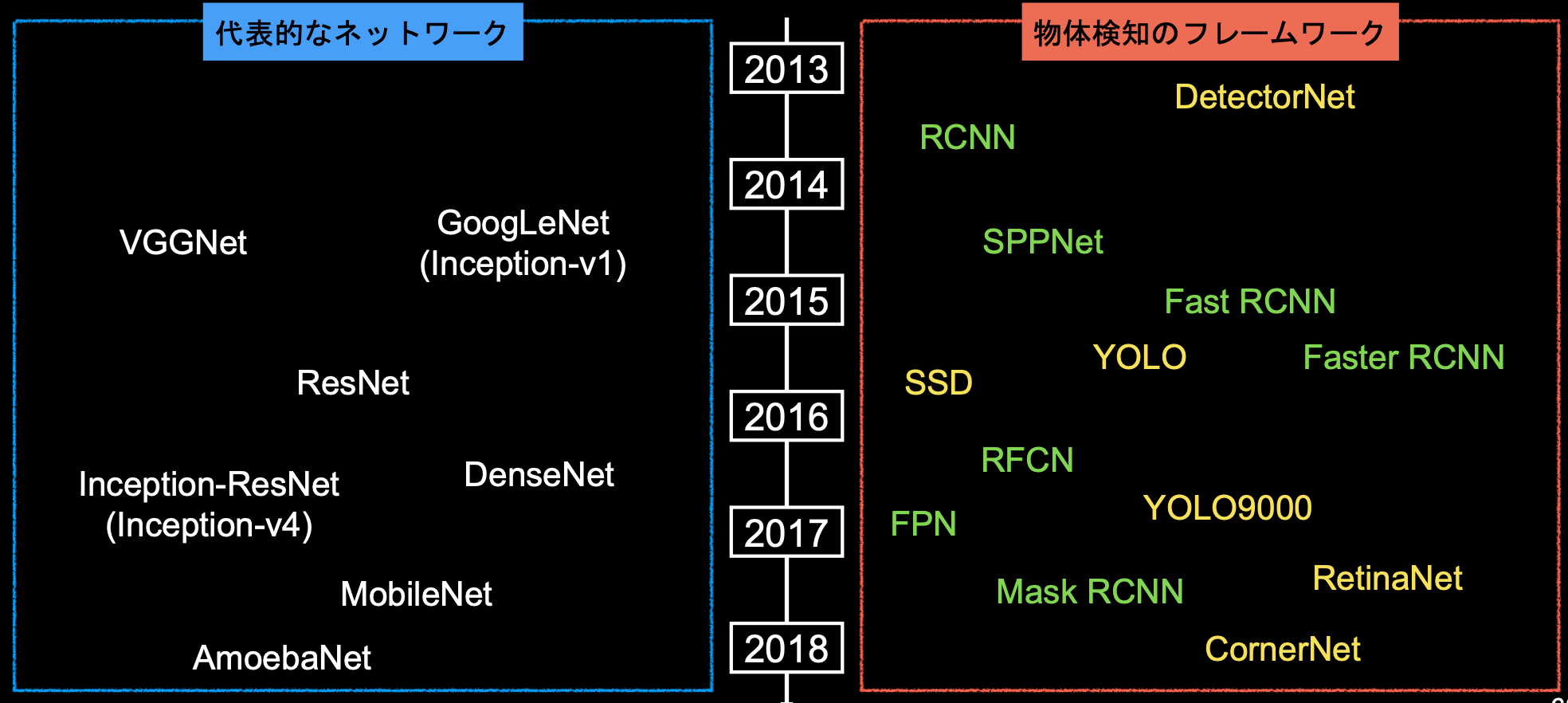
・緑色→2段階検出器(Two-stage detector)
・候補領域の検出とクラス推定を別々に行う
・相対的に精度が高い傾向
・相対的に計算量が大きく推論も遅い傾向
・黄色→1段階検出器(One-stage detector)
・候補領域の検出とクラス推定を同時に行う
・相対的に精度が低い傾向
・相対的に計算量が小さく推論も早い傾向
■SSD(Single Shot Detector)
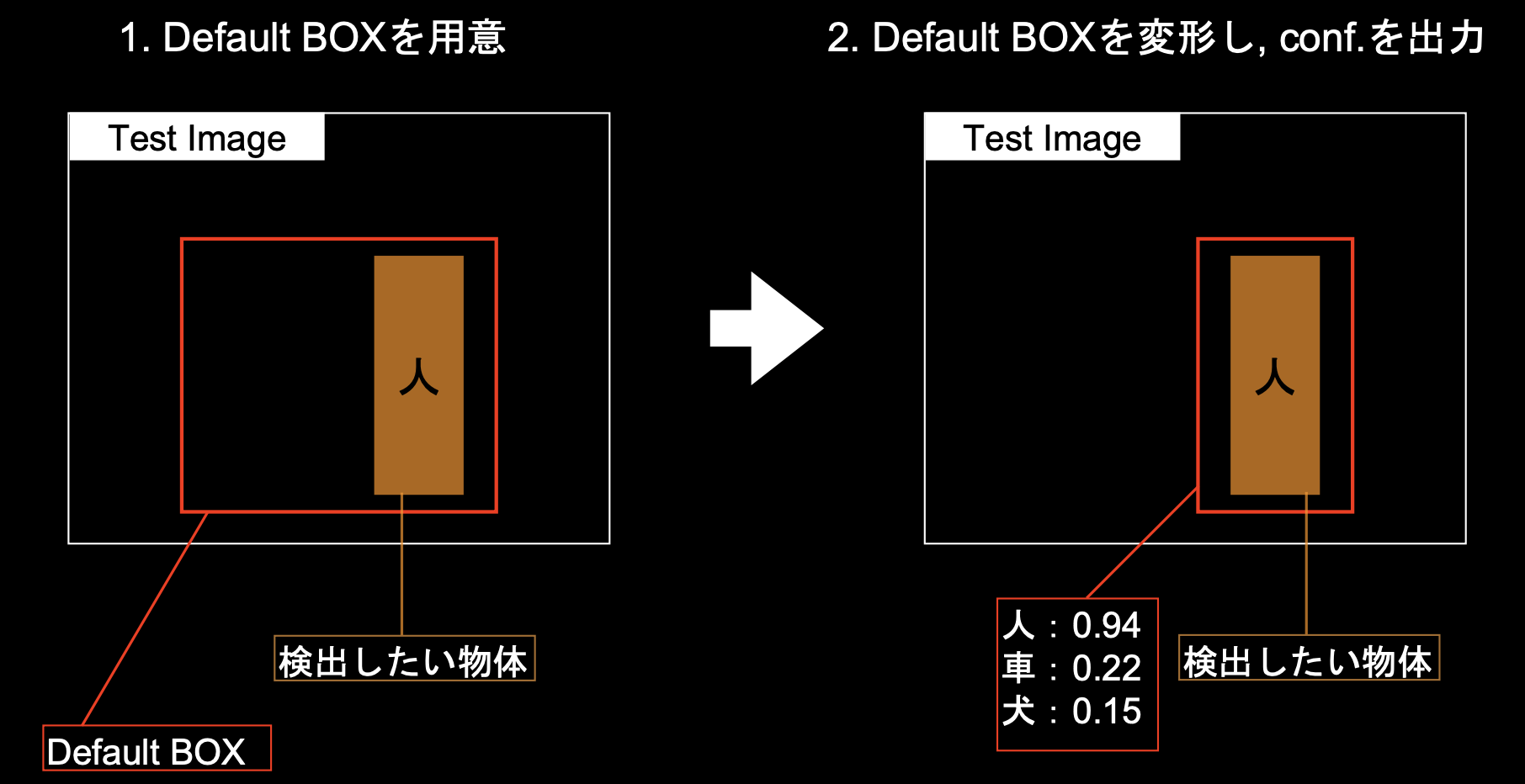
1.Default BOXを適当な位置に適当な大きさで用意
2.SSDが学習を進めてDefault BOXを修正していく
■特徴マップからの出力
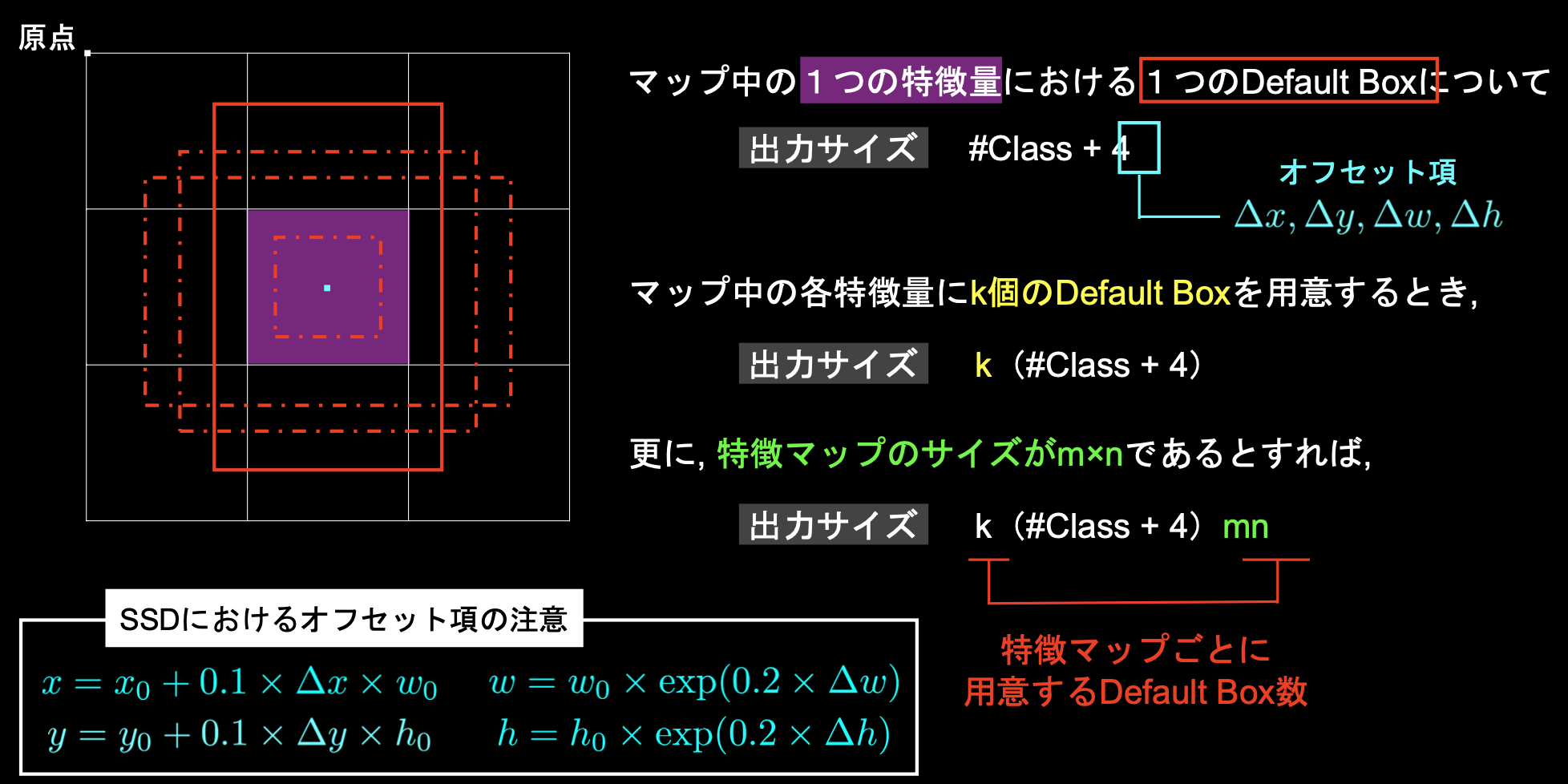
・オフセット項としてDefault Boxの中心位置や幅、高さを用意している
・k個のDefault Boxを用意する時、特徴マップのサイズがmnだとすると、特徴マップごとに用意するDefault Box数はkm*nとなる
■Semantic Segmentation
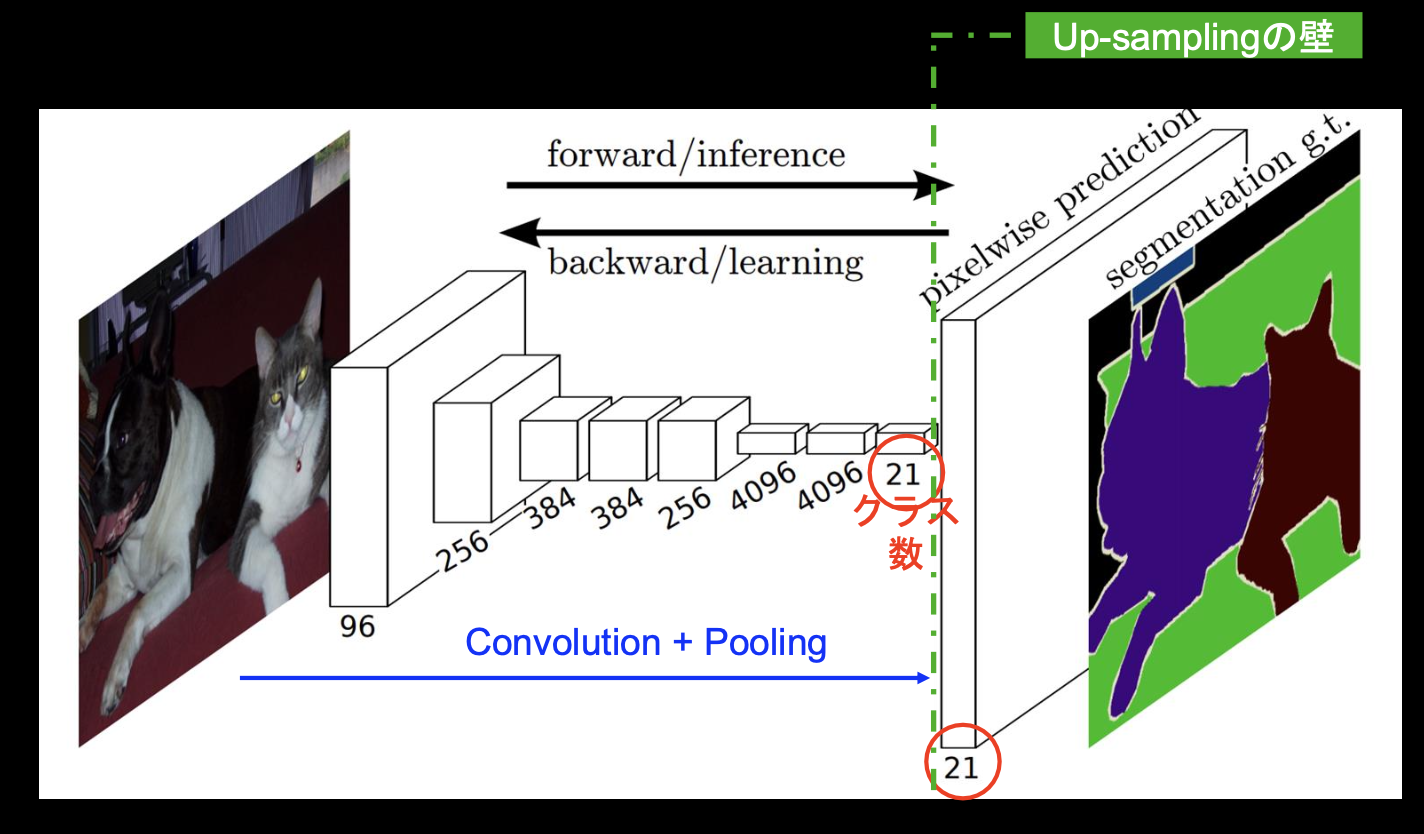
・convolutionを重ねていった最後に解像度を元に戻す(Up-sampling)
・convolutionにより解像度が落ちていくのが問題
→FCN:低レイヤーPooling層の出力を要素ごとに足し算することでローカルな情報を補完してからUp-sampling
→Unpooling:プーリングした時の位置情報を保持しておき、プーリングを元に戻すときに保持していた位置情報を利用する
→Dilated Convolution:Convolutionの段階で受容野を広げる手法
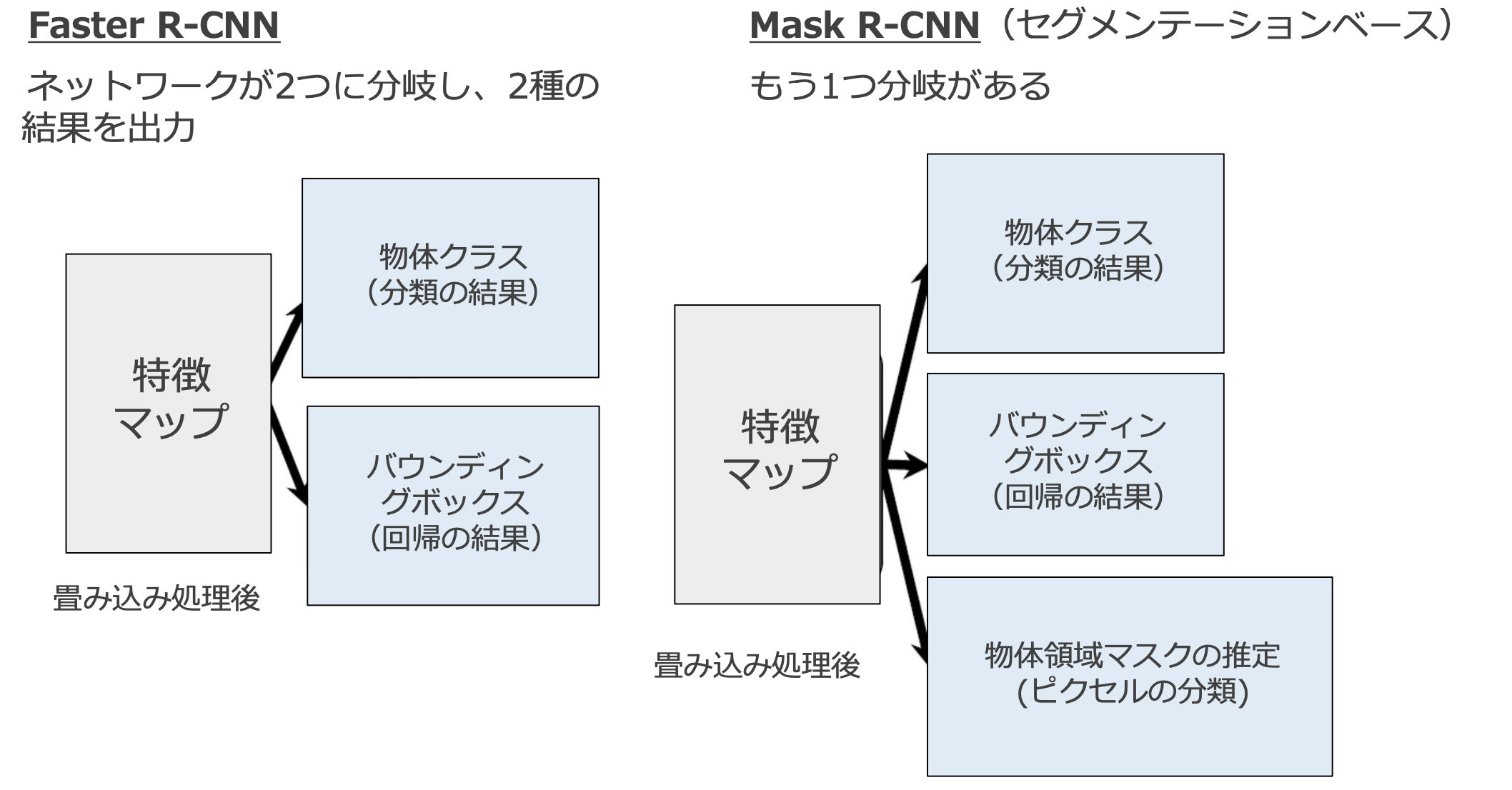
Mask R-CNN
・Faster R-CNNを拡張したアルゴリズム
→インスタンスセグメンテーションに対応するので、Faster R-CNNの物体検出機能にセグメンテーションの機能を付加したイメージ
→バウンディングボックス内の画素単位でクラス分類を行うため、物体の形も推定可能
・画像中の物体らしき領域とその領域にあるクラスを検出
→Mask R-CNNは、画像全体ではなく、物体検出の結果として得られた領域についてのみセグメンテーションを行うことで効率アップ
→「物体らしさ」が閾値以上の領域にのみ絞り、領域毎に最も確率が高いクラスを採用
・Mask R-CNNはFaster R-CNNと構造に類似点が多い
FCOS(Fully Convolutional One-Stage Object Detection)
・従来の物体検出アルゴリズムはアンカーボックスを用いるものが多かったのに対し、FCOSはアンカーフリーであることが大きな特徴
→多くの物体検出モデルは 「アンカーボックス」に依存している
→アンカーボックスとは大量のバウンディングボックスの候補のこと
→アンカーボックスのほとんどが ネガティブサンプル(検出したい物体が含まれていない領域)のため、均衡が崩れ学習がうまくいかなくなる
・FCOSは全てのピクセルから四次元ベクトルを予測する(YOLOv1は中央付近の点からのバウンディングボックスのみ予測するため精度が低くなる)
・FCOSではFPN(Feature Pyramid Networks)という、複数のサイズの特徴マップを生成する手法を使っている
→低解像度の特徴は全体の特徴を捉えやすく意味に強い、高解像度の特徴は細かい部分に強いが意味に弱い両方の良いところを両立させているのが、FPN。
Transformer
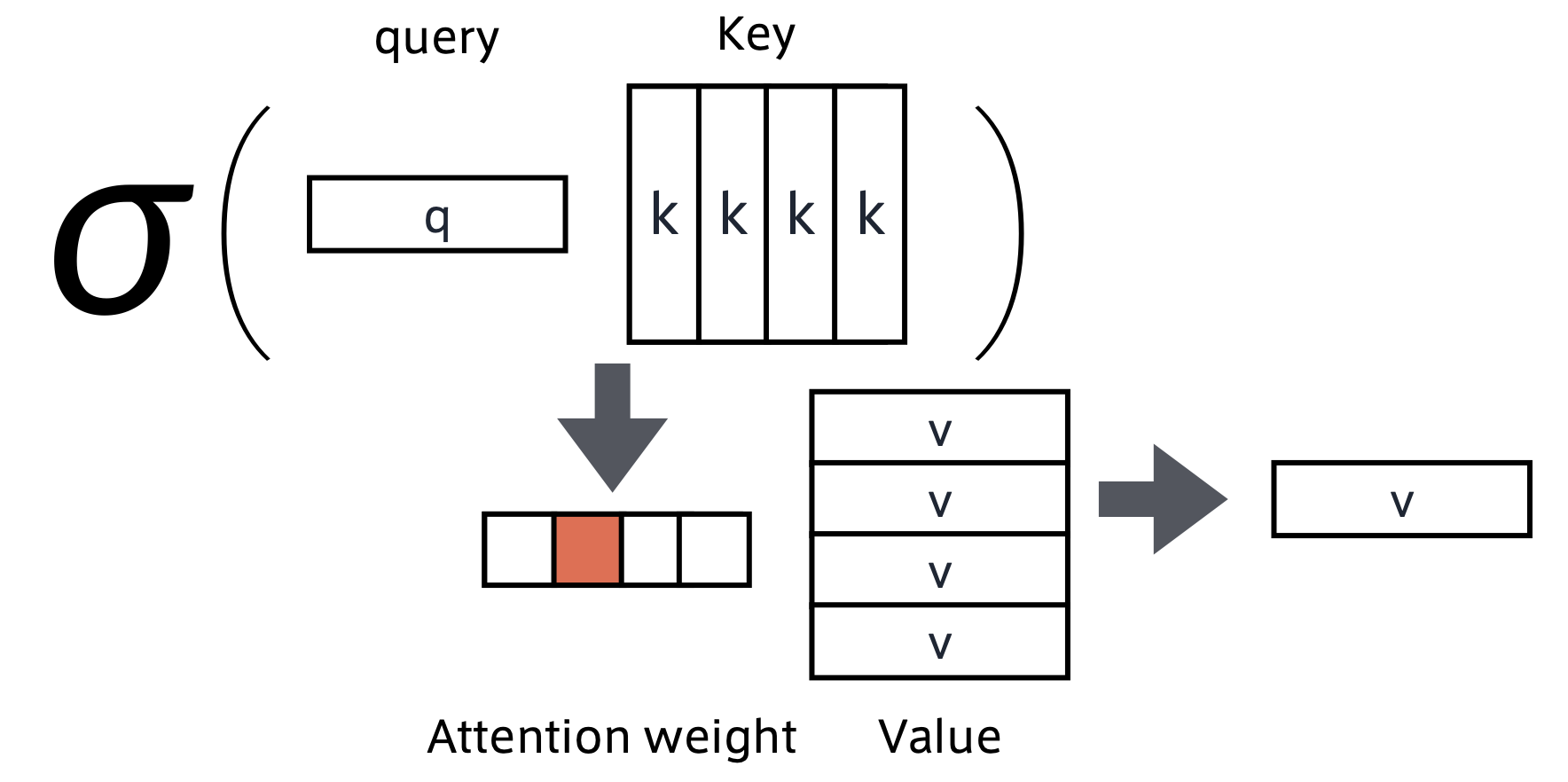
■Attention(注意機構)
・注目すべき部分とそうでない部分を学習して決定していく機構
・何をしているか:
→query(検索クエリ)に一致するkeyを索引し、対応するvalueを取り出す操作であると見做すことができる。これは「辞書オブジェクト」の機能と同じ。
■Transformer
・2017年6月に登場
・Attention機構のみを利用したモデル。RNNを使わない。
・当時のSOTAをはるかに少ない計算量で実現
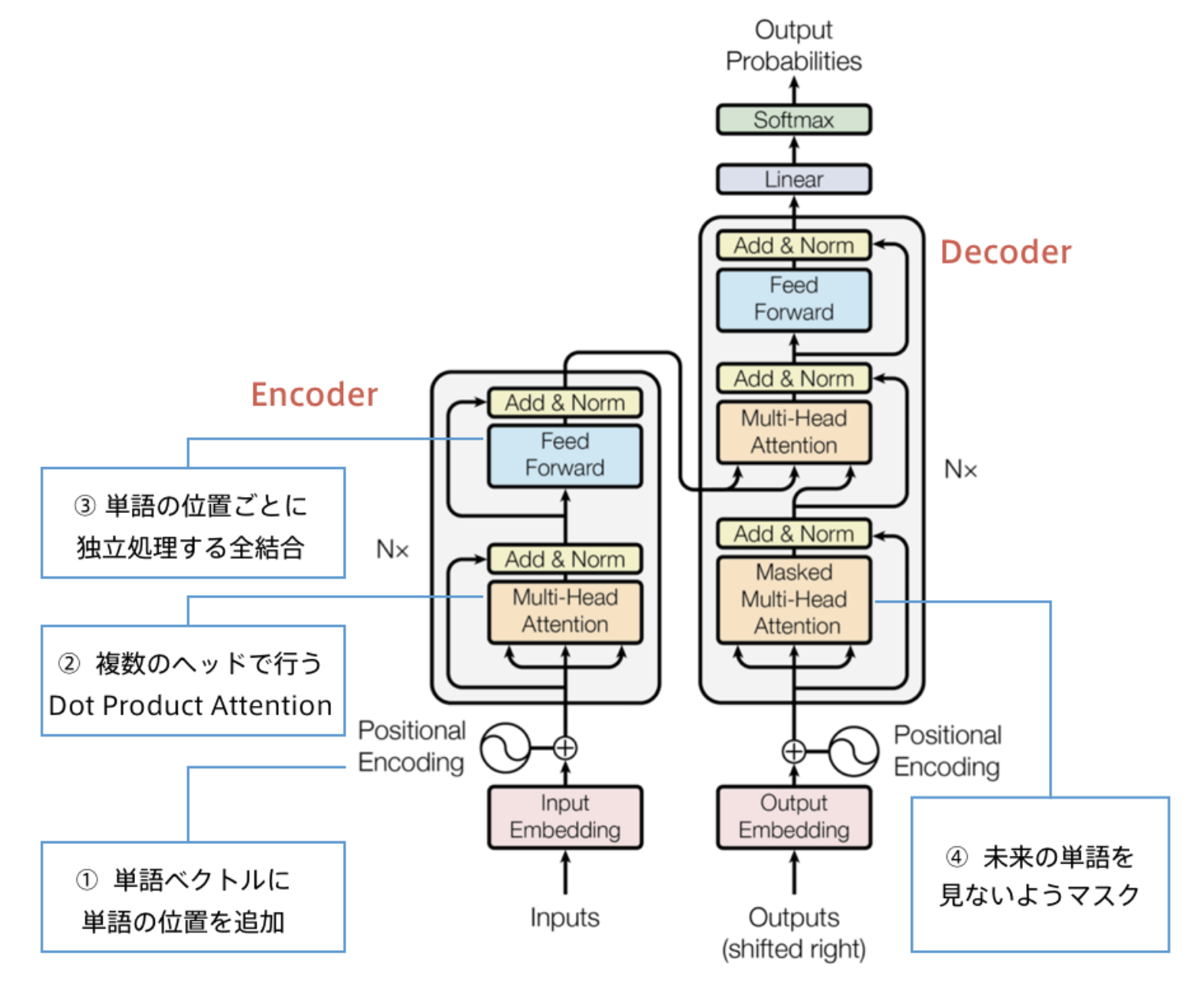
→EncoderとDecoderに分かれている。どちらもSelf Attention機構を取り入れている。
→RNNを利用していないため、はじめに位置情報を追加する処理を入れている。
■注意機構の種類
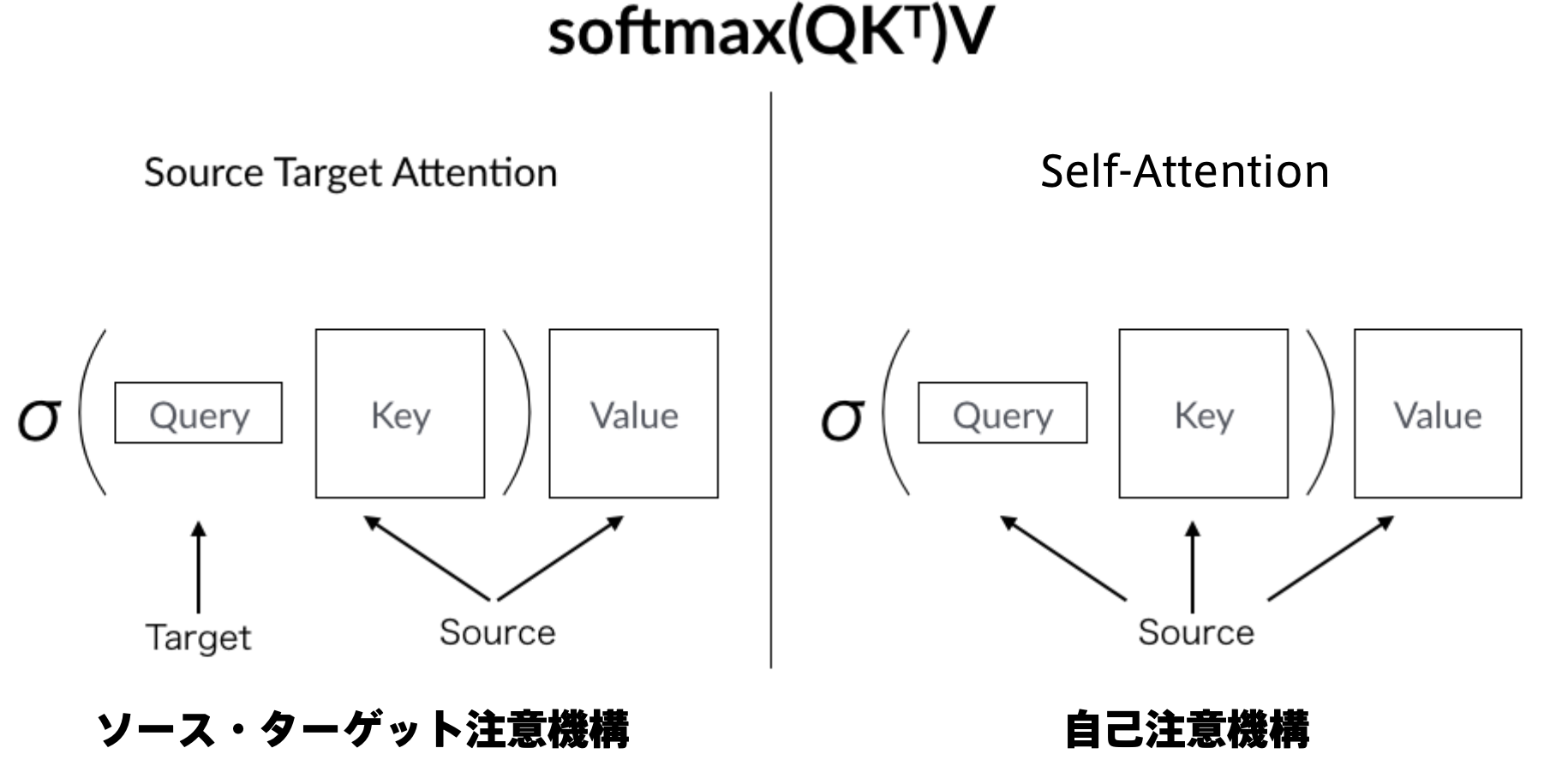
・Source Target Attention(ソース・ターゲット注意機構)
→情報がソースとターゲットに分かれている
→受け取った情報に対して近い情報のものをベクトルとして取り出す。
・Self-Attention(自己注意機構)
→Query,Key,Value全てをソースとして受け取っている。
→入力を全て同じにして学習的に注意箇所を決めていく
■計算機構
・Position-Wise Feed-Forward Networks:位置情報を保持したまま順伝播させる
・Scaled dot product attention:全単語に関するAttentionをまとめて計算する
・Multi-Head attention:重みパラメタの異なる8個のヘッドを使用
→8個のScaled Dot-Product Attentionの出力をConcat
→それぞれのヘッドが異なる種類の情報を収集
・Add & Norm
・Add (Residual Connection)
→入出力の差分を学習させる
→実装上は出力に入力をそのまま加算するだけ - 効果:学習・テストエラーの低減
・Norm (Layer Normalization)
→各層においてバイアスを除く活性化関数への入 力を平均0、分散1に正則化
→効果:学習の高速化
・Position Encoding
→RNNを用いないので単語列の語順情報を追加する
BERT
・Bidirectional Transformerをユニットにフルモデルで構成したモデル
・事前学習タスクとして、マスク単語予測タスク、隣接文判定タスクを与えた
・BERTからTransfer Learningを行った結果、8つのタスクでSOTA達成
■事前学習のアプローチ
・Feature-based
→特徴量抽出機として活用するためのもの
→様々なNLPタスクの素性として利用され、N-gramモデルやWord2Vecなど文や段落レベルの分散表現に拡張されたものもある。最近ではElMoが話題になった。
・Fine-tuning
→言語モデルの目的関数で事前学習する
→事前学習の後に、使いたいタスクの元で教師あり学習を行う(すなわち事前学習はパラメータの初期値として利用される)
■BERTのアプローチ
・双方向Transformer
→tensorを入力としtensorを出力
→モデルの中に未来情報のリークを防ぐためのマスクが存在しない
→従来のような言語モデル型の目的関数は採用できない(カンニングになるため)
→事前学習タスクにおいて工夫する必要がある
・事前学習 (Pre-training) タスク
・空欄語予測
→文章中の単語のうちランダムにマスクされる。マスクされた単語が何か予測。
・隣接文予測
→二つの文章を入力として、隣接文であるかのT/Fを出力する
・事前学習 (Pre-training) 手続き
・データセット:BooksCorpus(800MB) + English Wikipedia(2500MB)
・入力文章の合計系列長が512以下になるように2つの文章をサンプリング
・バッチサイズ:256 (= 256x512系列 = 128,000単語/バッチ)
→1,000,000ステップ=33億の単語を40エポック学習
・Adam:LR=1e-4、L2weight_decay=0.01
・Dropout:0.1
・活性化関数:GeLu(ReLUに似た関数)
・系列レベルの分類問題
→固定長の分散表現は最初の[CLS]トークンの内部表現から得られる
→新しく追加する層は分類全結合層+ソフトマックス層のみ
・Fine-tuning自体は高速にできるので、ハイパーパラメータ探索も可能
実装演習
・BERTの学習済みモデルを使って転移学習してみる
・学習に使うデータは夏目漱石の「こころ」「それから」「夢十夜」
・エポック数5回でラベルの予測を実行
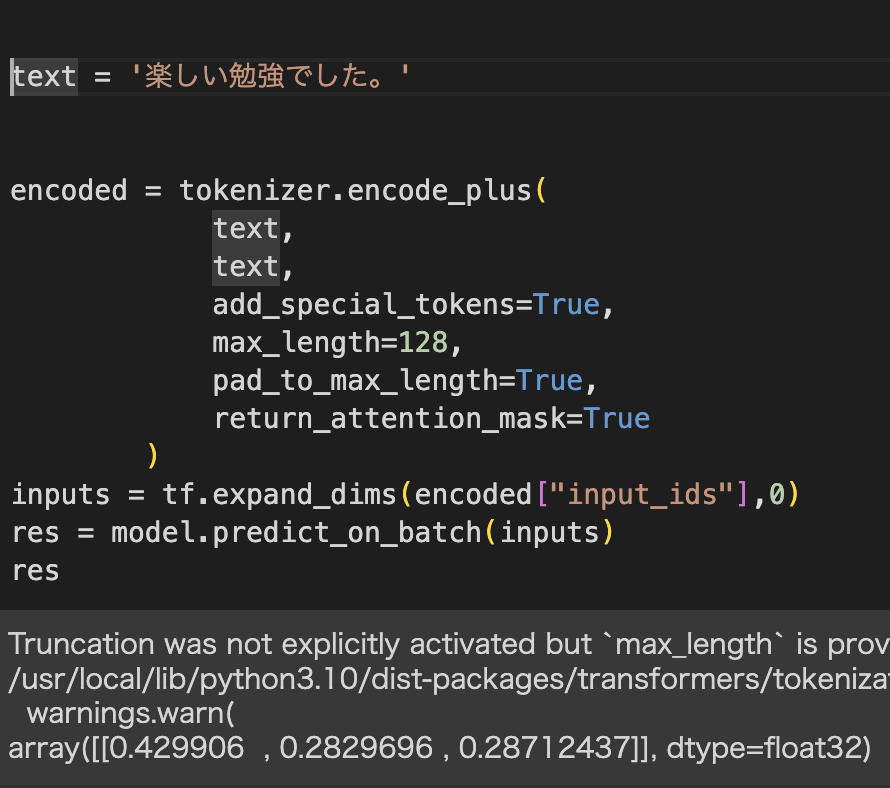
→ラベル0が0.429と「こころ」が最も近しいようだ。
・エポック数50回実施。(かなり時間がかかった)

・テキストを「こころ」の冒頭に変更して実行
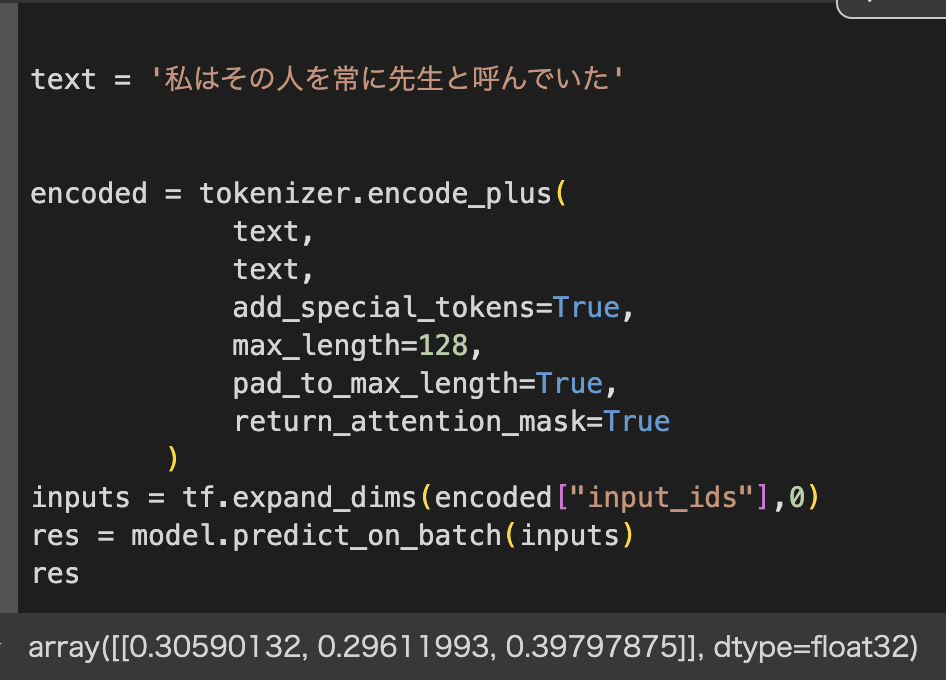
→「こころ」の冒頭を入力したのだが、結果は「夢十夜」のラベル3が0.397と最も高いという結果が出てしまった。うまく学習できていないのだろうか。エポック数を変更すればもっと良い結果が得られるかもしれない。
GPT(Generative Pre-Training)
・2019年にOpenAIが開発した有名な事前学習モデル
・その後、GPT-2、GPT-3が相次いで発表され、2024年5月では最新版はGPT-4o
・パラメータ数が桁違いに増加し、GPT-3のパラメータ数は1750億個、約45TBのコーパスで事前学習を実施
・GPTの構造はトランスフォーマーを基本する。「ある単語の次に来る単語」を予測し、自動的に文章を完成できるように、教師なし学習を行う
・出力値は「その単語が次に来る確率」
■GPT-3の推論
・zero-shot、one-shot、few-shotに分類できる。
zero-shot:なんのタスクか(翻訳なのか、文生成なのかなど)を指定した後、すぐ推論させる
one-shot:なんのタスクかを指定した後、1つだけラベル付きの例を教え、その後推論させる
few-shot:なんのタスクかを指定した後、2つ以上の例を教え、そのあと推論させる
→実際にchatgptに上記をやってみると、例文を与えた方が、例文に沿った推論結果に近づいた。
音声認識
・音波:空気の振動による音の波
・ある地点における波形は振幅:(音の大きさ)と波長(音の高さ)によって表される。
→周波数:一秒あたりの振動数(周期数)
→角周波数:周波数を回転する角度で表現
・波形の扱い
・標本化、量子化、フーリエ変換などにより波形処理を行う
→標本化:連続時間信号を離散時間信号に変換
→量子化:等分した振幅にサンプルの振幅を合わせる
→サンプリング周波数:1秒間で処理することができるサンプルの個数
→フーリエ変換:波形を機械学習の入力とするために行う
→ある波形f(t)から振幅・角周波数を表す関数F(w)に変換する作業
・スペクトログラム
・複合信号を窓関数に通して、周波数スペクトルを計算した結果を3次元のグラフ(時間、周波数、振幅)で表したもの
・現実的である非周期音声データの分析のために実施
・メル尺度
・人間の聴覚に基づいた尺度
・人間の耳は周波数の低い音に対して敏感で、周波数の高い音に対して鈍感であるという性質がある
・逆フーリエ変換
・振幅・周波数から元の波形を構築する作業
・ケプストラム
・フーリエ変換したものの絶対値の対数を逆フーリエ変換して得られるもの
・音声認識の特徴量として利用される
CTC(Connectionist Temporal Classification)
・CTCはEnd-to-Endモデルの中でも比較的初期に提案されたモデル。
・従来手法のように隠れマルコフモデル(HMM)を使用せずにディープニューラルネットワーク(DNN)だけで音響モデルを構築する手法として提案された
・CTCの重要な発明は以下2つ
・ブランクの導入
・前向き・後向きアルゴリズムを用いたRNNの学習
DCGAN
■GAN(Generative Adversarial Nets)とは
・生成器と識別器を競わせて学習する生成&識別モデル
・Generator:乱数からデータを生成
→Discriminatorに誤判断させたい
・Discriminator:入力データが真データ(学習データ)であるかを識別
→正しく判別したい
・2プレイヤーのミニマックスゲーム
→1人が自分の勝利する確率を最大化する作戦を取り、もう一人は相手が勝利する確率を最小化する作戦を取る
■DCGAN(Deep Convolutional GAN)とは
・GANを利用した画像生成モデル
・Generator
→Pooling層の代わりに転置畳み込み層を使用
→最終層はtanh、その他はReLU関数で活性化
・Discriminator
→Pooling層の代わりに畳み込み層を使用
→Leaky ReLU関数で活性化
・中間層に全結合層を使わない
・バッチノーマライゼーションを適用
Conditional GAN(条件付きGAN)
・画像生成時に条件パラメータを与え,生成したい画像のクラスを指定できる。(従来のGANでは生成する画像のクラスは指定できない)
・Generator:yの画像を生成(条件ラベルyの場合)
・Discriminator:以下のように識別(画像とラベルのペア)
→(Gが生成した犬の画像G(z|y),y ラベル)→ Fake
→(Gが生成した犬の画像G(z|y),y 以外のラベル) → Fake
→(真のラベル yの画像 x,yラベル) → Real
→(真のラベル yの画像 x , y 以外のラベル) → Fake
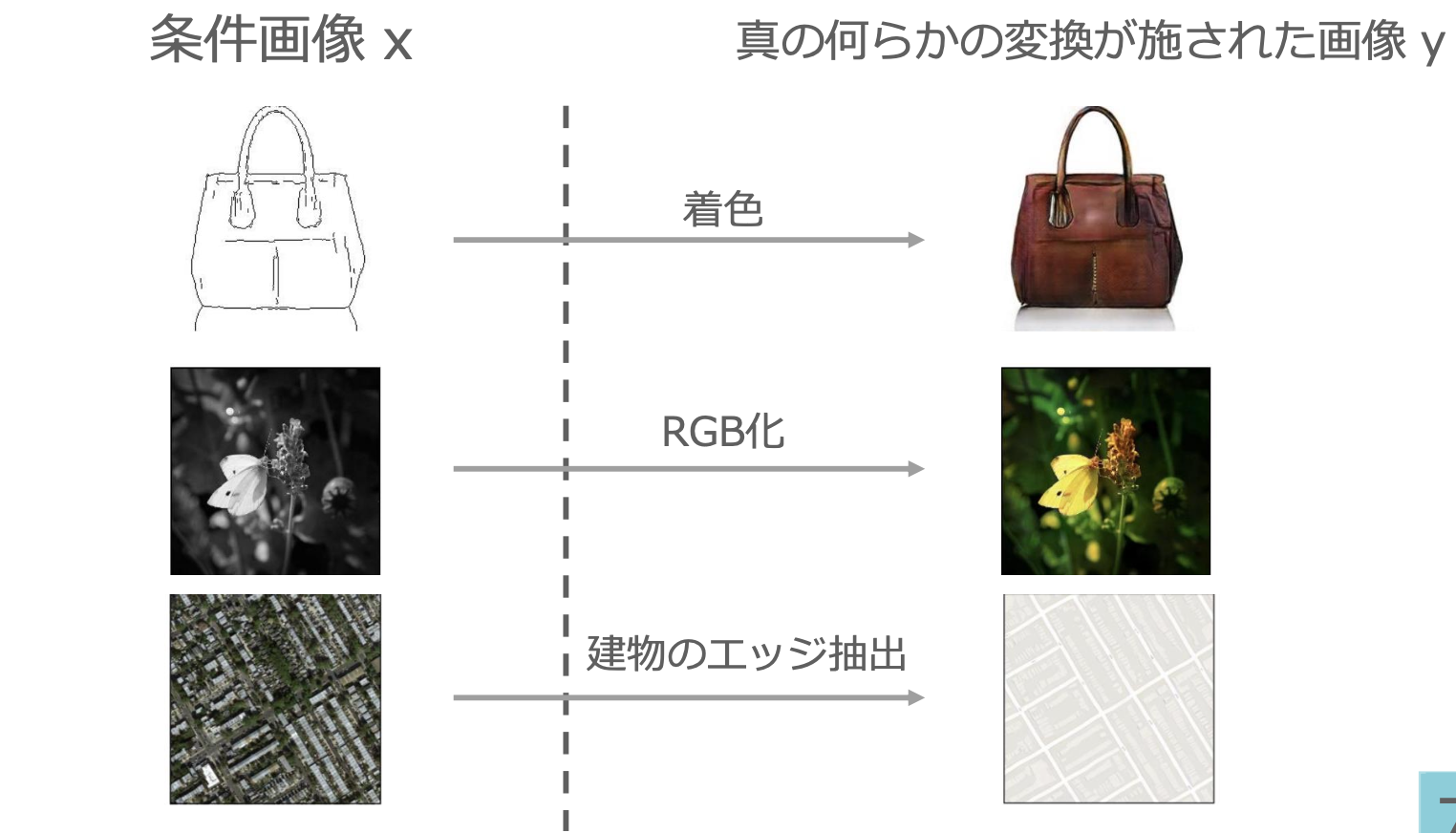
Pix2Pix
・CGANと同様の考え方
・条件としてラベルではなく画像を用いる
・条件画像が入力され,何らかの変換を施した画像を出力する
・画像の変換方法を学習
・Generator:条件画像xをもとにある画像 G(x, z)を生成
・Discriminator:(条件画像 x → Generatorが生成した画像 G(z|x))の変換と(条件画像 x → 真の変換が施された画像 y)の変換が正しい変換かどうか識別する
・以下のような画像のペアが学習データ
・Pix2Pixのネットワーク
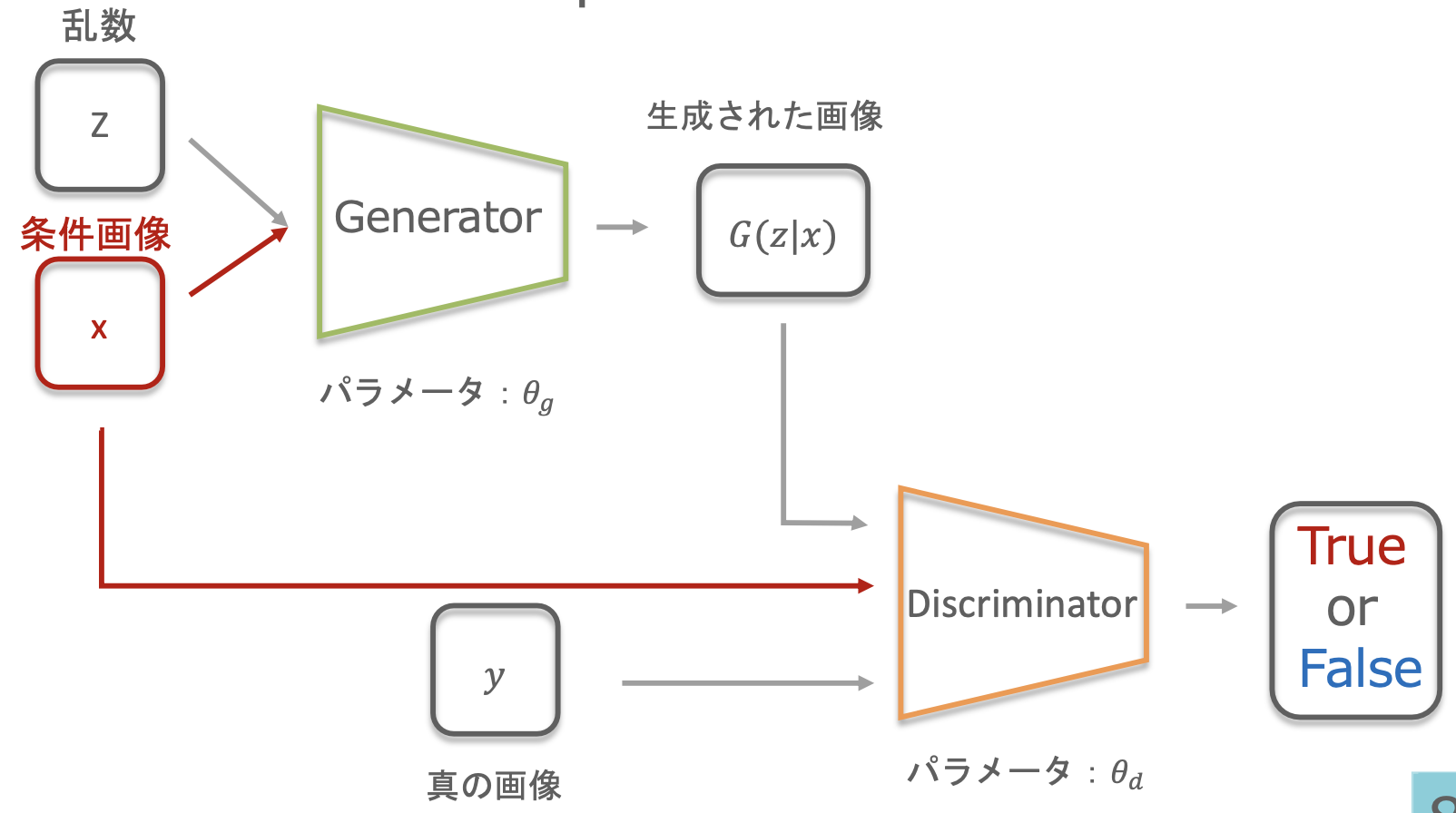
・GeneratorにU-Netを使用、物体の位置を抽出
・L1正則化項をDiscriminatorの損失関数に追加
・普通のGANと異なり,Pix2Pixは画像の変換方法を学習するため 条件画像と生成画像に視覚的一致性が見られる
・PatchGAN:条件画像をパッチに分けて,各パッチにPix2Pixを適応
A3C(Asynchronous Advantage Actor-Critic)
・強化学習の学習法の一つ
・複数のエージェントが同一の環境で非同期に学習する
・名前の由来:3つの”A”
→Asynchronous:複数のエージェントによる非同期な並列学習
→Advantage:複数ステップ先を考慮して更新する手法
→Actor:方策によって行動を選択
→Critic:状態価値関数に応じて方策を修正
※Actor-Criticとは 行動を決めるActor(行動器)を直接改善しながら、方策を評価するCritic(評価器)を同時に学習させるアプローチ
■A3Cによる非同期 (Asynchronous) 学習の詳細
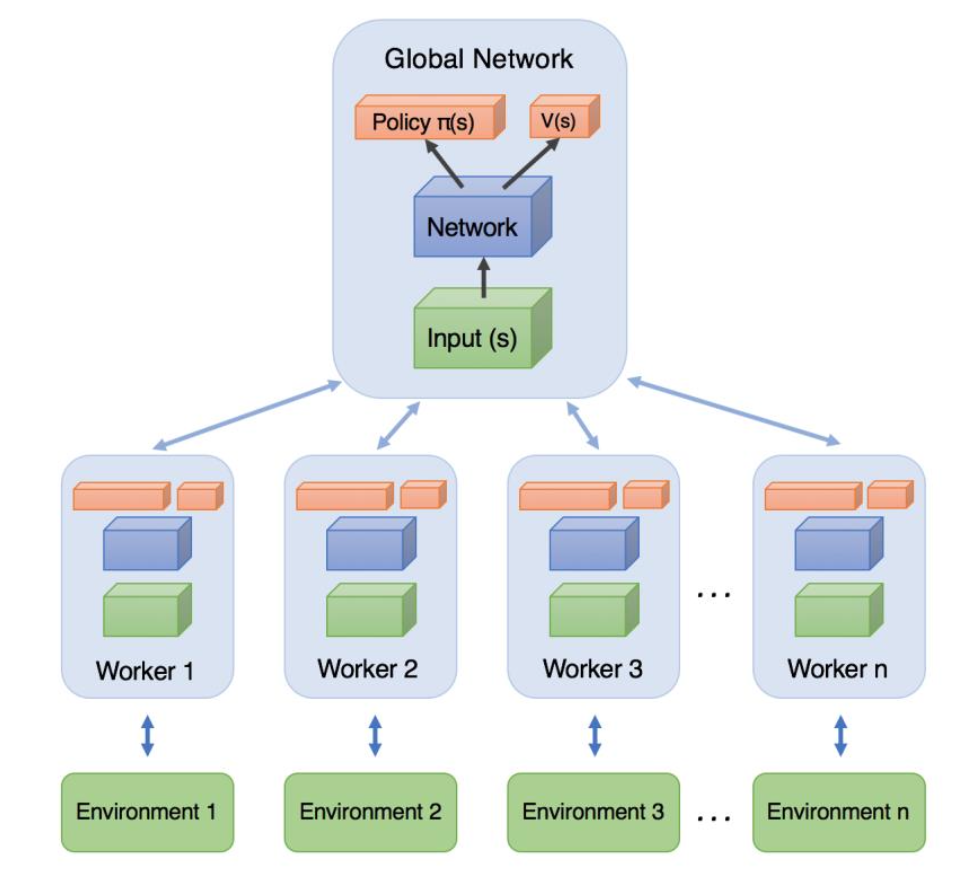
・複数のエージェントが並列に自律的に、rollout (ゲームプレイ) を実行し勾配計算を行い、その勾配情報をもって、好き勝手なタイミングで共有ネットワークを更新
・各エージェントは定期的に自分のネットワーク (local network) の重みをglobal networkの重みと同期する
■並列分散エージェントで学習を行うメリット
・学習が高速化
・学習を安定化
→経験の自己相関が引き起こす学習の不安定化は、強化学習の長年の課題だったが、DQNはExperience Replay(経験再生)機構を用いてこの課題を解消した。バッファに蓄積した経験をランダムに取り出すことで経験の自己相関を低減したが、経験再生は基本的にはオフポリシー手法でしか使えない
→A3Cはオンポリシー手法であり、サンプルを集めるエージェントを並列化することで
自己相関を低減することに成功した
■A2Cについて
・A3Cの進化版
・A2Cは同期処理を行い、Pythonでも実装しやすい
→A3Cでは、Python言語の特性上、非同期並列処理を行うのが面倒だった。また、パフォーマンスを最大化するためには、大規模なリソースを持つ環境が必要があった。
・各エージェントが中央指令部から行動の指示を受けて、一斉に1ステップ進行し、中央指令部は各エージェントから遷移先状態の報告を受けて次の行動を指示する
・性能がA3Cに劣らないことがわかったので、その後よく使われるようになった
■分岐型Actor-Criticネットワーク
・一般的なActor-Criticでは、方策ネットワークと価値ネットワークを別々に定義し、別々のロス関数(方策勾配ロス/価値ロス)でネットワークを更新する
・A3Cはパラメータ共有型のActor-Criticであり、1つの分岐型のネットワークが、方策と価値の両方を出力し、たった1つの「トータルロス関数」でネットワークを更新
→Total loss = −アドバンテージ方策勾配 +α・価値関数ロス −β・方策エントロピー
※係数α、β:ハイパーパラメータ(係数βは探索の度合いを調整する)
Metric-learning(距離学習)
・距離学習ではデータ間のmetric、すなわち「データ間の距離」を学習する。
→データ間の距離を適切に測ることができれば、距離が近いデータ同士をまとめてクラスタリングができたり、他のデータ要素から距離が遠いデータを異常と判定することで異常検知したりと様々な応用が可能
(ディープラーニング技術を利用した距離学習の手法 → 深層距離学習)
・深層距離学習では、2つの特徴ベクトル間の距離がデータの類似度を反映するようにネットワークを学習する
・深層距離学習ではネットワークの構造自体は工夫しなくても、類似度を反映した埋め込み空間を構成できるように学習を行うだけで精度向上が可能
・埋め込み空間 (embedding space):特徴ベクトルの属する空間
→埋め込み空間内で類似サンプルの特徴ベクトルは近くに、非類似サンプルの特徴ベクトルは遠くに配置されるように学習を行うことになる。CNNを深層距離学習の手法を用いて学習していくと、類似サンプル (から得られる特徴ベクトル)は埋め込み空間内で密集していき、逆に非類似サンプルは離れていく。
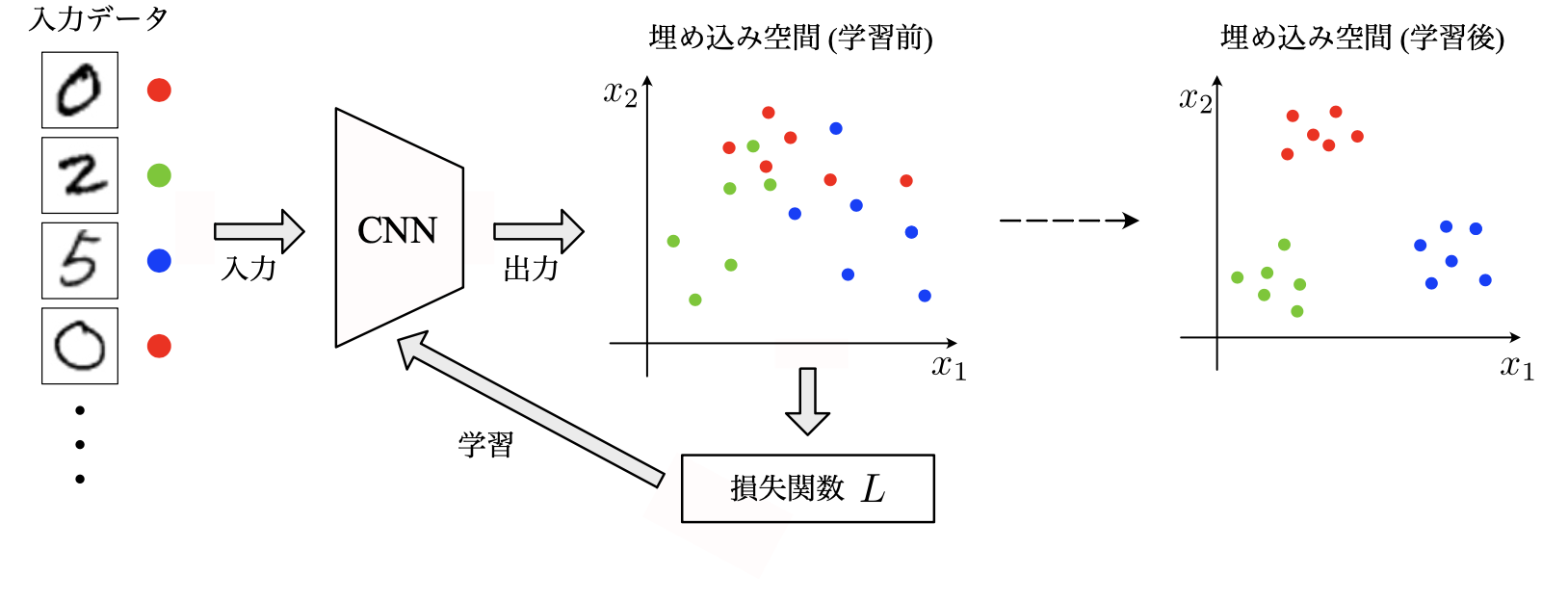
→画像分類やクラスタリングが容易になる
■Siamese network (シャムネットワーク)
・2006年に提案された深層距離学習の手法
・2つのサンプルをペアで入力しそれらのサンプル間の距離を明示的に表現して調整するのが特徴
・CNNにペア画像を入力し、その出力である特徴ベクトルの距離が「最適」となるようにネットワークのパラメータを学習する。
■Triplet network (トリプレットネットワーク)
・2014年に提案された深層距離学習の手法
・Siamese networkでは2つのサンプルをセットにして入力するのに対して、Triplet networkでは 3つのサンプルを一組で入力する
・Siamese networkで問題となった同じクラスのペアと異なるクラスのペアの間に生じる不均衡を解消
・実は問題点がある。
→1.学習がすぐに停滞してしまう
→2.クラス内距離がクラス間距離より小さくなることを保証しない
→Quadrupt lossと呼ばれる次の損失関数が提案されている
MAML (Model-Agnostic Meta-Learning) (メタ学習)
・深層学習モデル開発に必要なデータ量を削減する手法。以下2つの特徴を持つ。
Model-Agnostic:微分可能である以外、モデルや損失関数の具体的な形式を仮定しない
Task-Agnostic:回帰、分類、強化学習など、様々なタスクに適用できる
・深層学習では学習に大量のデータを必要とするが、MAMLではこれを解決。
・タスクに共通する重み(メタ知識)を学習し、新しいモデルの学習に活用
・MAMLでは、タスクごとの学習を行った結果を共通重みに反映させ学習する
→Few-Shot learningで既存手法を上回る精度を実現
・課題はタスクごとの学習と共通パラメータの学習で計算量が多いこと
・計算コストを削減する改良案 (近似方法)
→First-order MAML(FOMAML):2次以上の勾配を無視し計算コストを大幅低減
→Reptile:Innerloopの逆伝搬を行わず、学習前後のパラメータの差を利用
グラフ畳み込み(GCN)
・CNN:画像認識などで特徴をはっきりさせるために使われるディープラーニングの畳み込み手法
→CNNは幾何学的なものへの利用に限られる。グラフに対しては使えない。
→GCNで解決。
・畳み込み:フィルターをかけて特徴をはっきりさせること
・GCN:グラフはネットワークのことであり、エッジとノードから構成される。GCNでは、ノードの近くにある情報を特徴量として使う。
・GCNの利用:新型コロナウイルスの感染者数予測、分子構造、交通状況など
・Spatial GCN:グラフを空間的に考えて畳み込む。2014年に発表。
・Spectral GCN:グラフをスペクトルに分解して畳み込む。2020年に発表。
Grad-CAM,LIME,SHAP
・ディープラーニング活用の難しいことの1つは「ブラックボックス性」
・判断の根拠を説明できない
→実社会に実装する際に「なぜ予測が当たっているのか」を説明できないことが問題
・モデルの解釈性に注目し、「ブラックボックス性」の解消を目指した研究が進められている
■CAM(Class Activation Mapping)
・2016のCVPRにて発表されたCNNの判断根拠可視化の手法
・GAP(Global Average Pooling)を使用するモデルに適応できる手法
・GAPは学習の過学習を防ぐ、正則化の役割として使われてきたが、GAPがCNNが潜在的に注目している部分を可視化できるようにする性質を持っていることが分かった
■Grad-CAM(Gradient-weighted Class Activation Mapping)
・CNNモデルに判断根拠を持たせ、モデルの予測根拠を可視化する手法
・名称の由来は”Gradient” = 「勾配情報」
・最後の畳み込み層の予測クラスの出力値に対する勾配を使用
・勾配が大きいピクセルに重みを増やす:予測クラスの出力に大きく影響する重要な場所
・CAMはモデルのアーキテクチャにGAPがないと可視化できなかったのに対し、Grad-CAMはGAPがなくても可視化できる。また、出力層が画像分類でなくてもよく、様々なタスクで使える
■LIME (Local Interpretable Model-agnostic Explanations)
・特定の入力データに対する予測について、その判断根拠を解釈・可視化するツール。
・表形式データ:「どの変数が予測に効いたのか」
・画像データ:「画像のどの部分が予測に効いたのか」
・単純で解釈しやすいモデルを用いて、複雑なモデルを近似することで解釈を行う
※複雑なモデル:人間による解釈の困難なアルゴリズムで作った予測モデル
例:決定木のアンサンブル学習器、ニューラルネットワークなど
・LIMEへの入力は1つの個別の予測結果
・画像データ:1枚の画像の分類結果
・表形式データ:1行分の推論結果
・対象サンプルの周辺のデータ空間からサンプリングして集めたデータセットを教師データとして、データ空間の対象範囲内でのみ有効な近似用モデルを作成する。近似用モデルから予測に寄与した特徴量を選び、解釈を行うことで、本来の難解なモデルの方を解釈したことと見なす
・スーパーピクセル:色や質感が似ている領域をグループ化すること
■SHAP(SHapley Additive exPlanations)
・機械学習モデルの予測結果を解釈するための手法
・各特徴量がモデルの出力にどの程度寄与しているかを定量的に評価する
・協力ゲーム理論の概念であるshapley value(シャープレイ値)を機械学習に応用
実装演習
・トイレットペーパーの画像を与えてGrad-CAMでヒートマップを作成

→予測クラス:999となっており、トイレットペーパーの画像クラスが999なので予測は合っている。トイレットペーパーの中心部分と背景に注目していることがわかる。今回は背景が真っ黒の画像だったが、他の色や別のものが紛れていると、注目箇所が変わったり、うまく予測できなかったり、また違った結果になったのだと思う。
Docker
・仮想環境はハードウェア上で独立した複数の環境を実行する技術で、ホスト型、ハイパーバイザー型、コンテナ型の3種類が存在
・ホスト型:物理的なホストOS上で動作
・ハイパーバイザー型:ハードウェア上で直接実行
・コンテナ型:単一のOSカーネルで複数のコンテナ実行
■Dockerとは
・Dockerとはコンテナ型仮想化ソリューション
・Docker の定義と背景
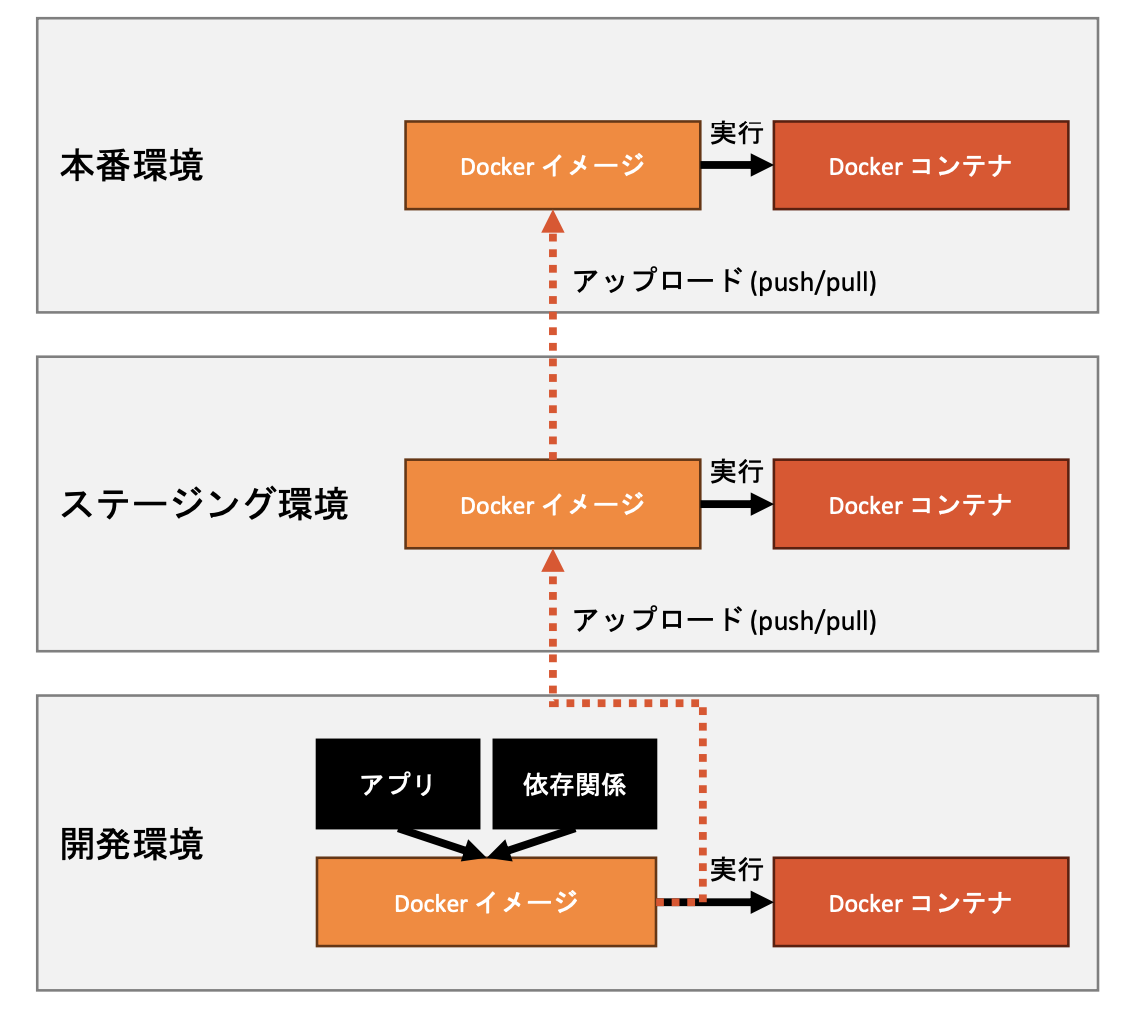
・アプリケーションと依存関係をコンテナとしてパッケージ化
・どの環境でも一貫した動作を保証
・アプリケーションの依存関係をインフラから分離
・Dockerのアーキテクチャ
・Dockerエンジン:コア技術
・Dockerイメージ:アプリケーションと依存関係のスナップショット
・Dockerコンテナ:イメージから生成。アプリケーションの実行環境
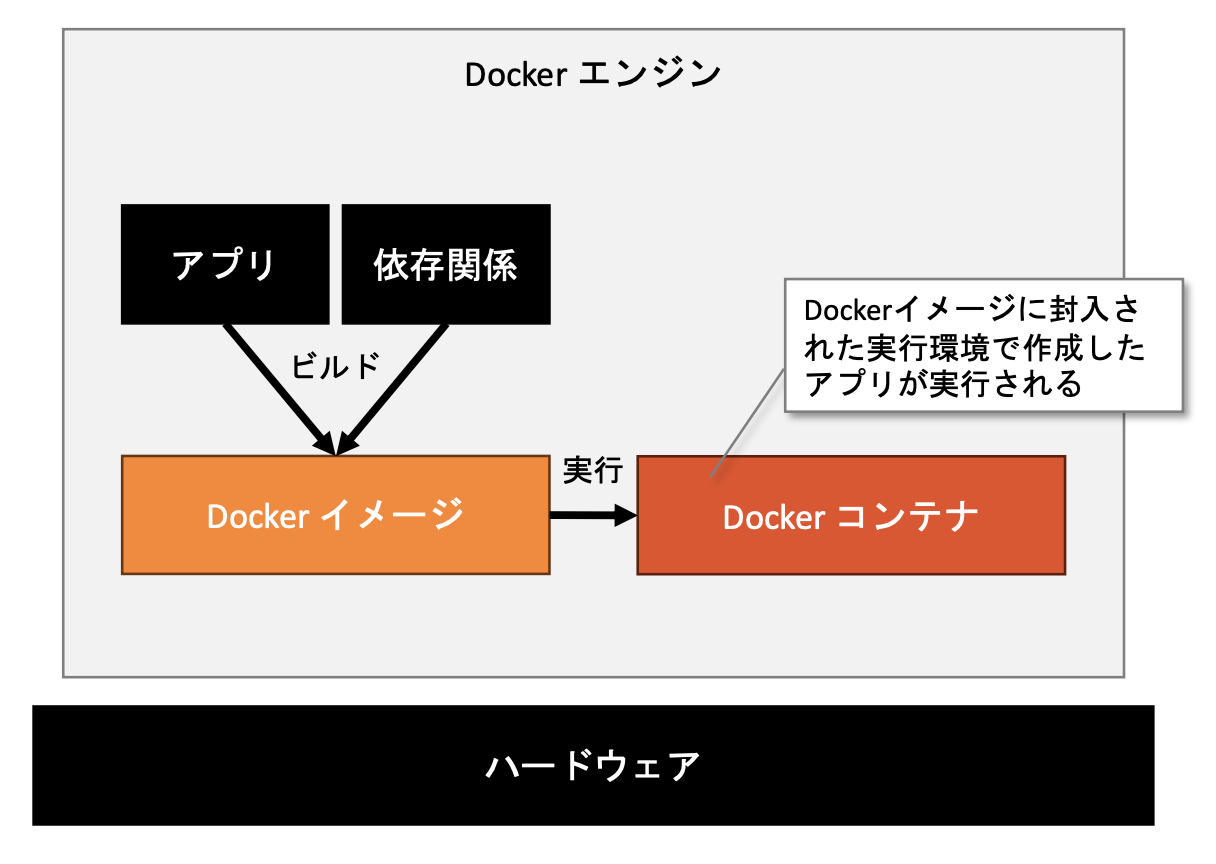
・Dockerは、アプリケーションの開発からデプロイメントまでの一貫性と効率性を向上させるために広く利用されている。
・本番環境でのデプロイ
・コンテナの概念を導入することによる環境の隔離
・環境の統一と再現性の確保
・アプリケーションと依存関係のコンテナ化
・開発、テスト、本番環境の動作の一貫性
・主要なDockerコマンド
・docker build:Dockerfile からイメージの作成
・docker run:コンテナの起動
・docker ps:実行中のコンテナの一覧表示
・docker images:ローカルのイメージ一覧表示
・docker start:停止しているコンテナの起動、既存の停止コンテナを再起動
・docker stop:実行中のコンテナの停止、docker startで再起動可能
・主要な命令
・FROM:ベースイメージの指定
・RUN:シェルコマンドの実行
・CMD:デフォルトのコマンド指定
・ENTRYPOINT:デフォルトのアプリケーション指定
・Dockerfileとは
・Dockerコンテナイメージを作成するためのスクリプトファイル
・ベースイメージの選択、アプリケーションのコードの追加、依 存関係のインストール、環境変数の設定などが記述される
・コンテナオーケストレーション:大規模なアプリケーションなどで複数のコンテナ管理を実現するソリューション
・Kubernetes:オープンソース、大規模運用向け
・docker-compose:Docker公式、開発環境・小規模デプロイ向け