はじめに
OpenAIのGPT-4やMetaのLLaMAのような大規模言語モデル(LLM)を個別タスクに適応させる方法として、パラメータチューニングがあります。しかし、パラメータチューニングは至難の業です。大量のデータセットが必要だったり、高性能なGPUが必要だったり...と個人では到底不可能です。さらに、チューニングできたとしてもLLMが指示を聞いてくれなくなるなど、多くの壁に直面します。そこで、パラメータをチューニングする以外の方法としてRetrieval-Augmented Generation(RAG)があります。RAGは、LLMが持つ内部知識を補うために外部知識を活用するというフレームワークです。RAGでは外部知識を活用することにより、LLMでは答えることができなかった質問にも答えることができるようになります。
今回は、RAGシステムの開発時に陥りがちな7つの失敗について解説します。原論文であるSeven Failure Points When Engineering a Retrieval Augmented Generation Systemをベースに解説していきます。

RAGの概要
目次
RAGシステム概要
RAGシステムについて、実際に開発することを踏まえて、より詳細なステップごとにもう少し詳しく説明します。ざっくりとした流れは上図の RAGの概要 の通りです。RAGシステムをより詳細にすると下図のようになります。
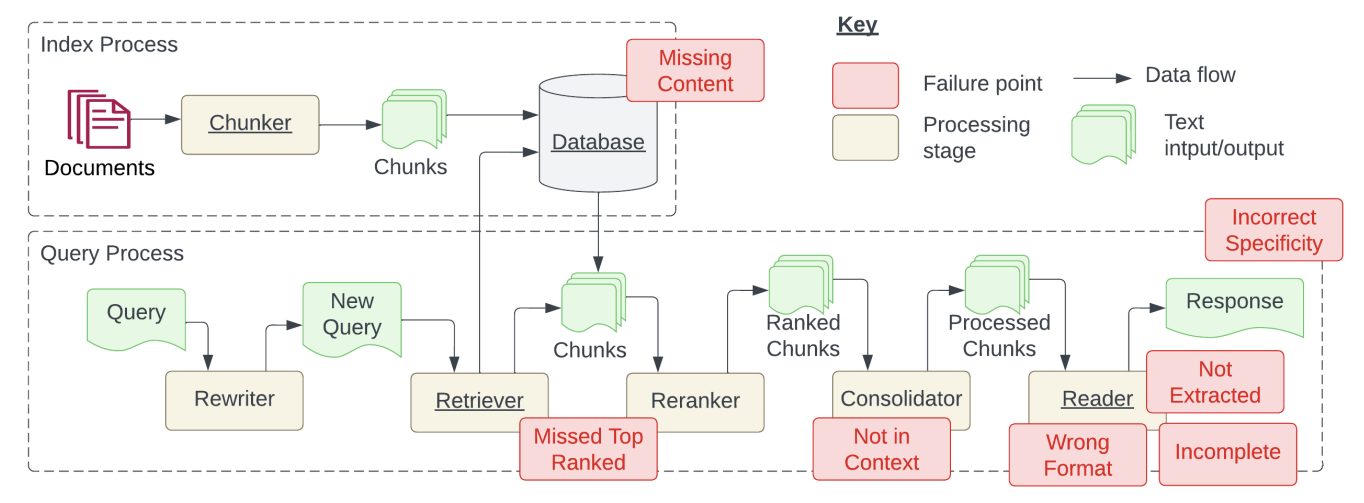
Scott Barnett et al.(2024) Seven Failure Points When Engineering a Retrieval Augmented Generation System
まず、RAGシステムは大きくIndex ProcessとQuery Processに分けられます。
Index Process
Index Processは、RAGシステムを開発する、もしくは新たなドキュメントをデータベースに格納する際に行われるプロセスです。このプロセスでは、各ドキュメントを小さなチャンクに分割し、 Embeddongモデルを使用してベクトル表現に変換します。その後、元のチャンクとベクトル表現がデータベースに格納されます。開発者は、ドキュメントをどのようにチャンク化するか、またチャンクのサイズをどれくらいにするかについて決める必要があります。チャンクが小さすぎると特定の質問に回答できなくなり、チャンクが大きすぎると生成される回答にノイズが含まれる可能性があります。また、動画のようなドキュメントには、「音声を抽出しテキストに変換する」など、異なるチャンク化と処理が必要です。
Query Process
Query Processは、実行時に行われるプロセスです。
次に、Query Processの処理ステージ(Rewriter, Retriever, Reranker, Consolidator, Reader)について説明します。
Rewriter
Rewriterでは、自然言語で表現された質問を一般的なクエリに変換します。 この一般化のためにLLMが使用されます。また、「この概念をさらに説明してください」のような曖昧な質問を具体化するために、以前のチャット履歴から追加の文脈を新しいクエリに含めることも行います。
Retriever
Retrieverでは、データベースから関連するドキュメントを見つけます。 Rewirterによって生成されたクエリをEmbedding modelを用いてベクトル表現に変換します。そして、類似性手法(例:コサイン類似度)を使用して、類似度の高い上位 k 件のドキュメンをが取得します。
Reranker
Rerankerでは、取得したドキュメントを再ランキングし、答えを含む可能性の高いチャンクが上位になるように調整します。
Consolidator
Consolidatorでは、大規模言語モデルの制約を克服するために必要です。
- トークン制限:プロンプトに含めることができるテキスト量に上限があります(例:GPT-4oでは128,000トークン)
- レート制限:時間枠内で使用できるトークン数が制限されており、システムのレイテンシ(応答時間)を制約します
これらを克服するために、Consolidatorでは大規模言語モデル(LLM)に渡す文脈を最適化します。 具体的には、関連性の低い情報や矛盾する情報を削除したり、複数のチャンクを統合したりします。
Reader
Readerでは、生成されたテキストから答えを抽出します。 具体的には、以下の役割を行います。
- プロンプトからノイズを除去する
- フォーマットの指示(例:質問に選択肢リストで回答するなど)に従う
- クエリに対して返す出力を生成する
ケーススタディ
この研究では、RAGシステムを実装する際に生じる課題を明らかにするため、3つのケーススタディを実施されました。この章では、各ケーススタディについて詳しく説明していきます。

Scott Barnett et al.(2024) Seven Failure Points When Engineering a Retrieval Augmented Generation System
Cognitive Reviewer
Cognitive Reviewerは、研究者が科学文書の分析を支援するために設計されたRAGシステムです。 研究者は研究質問または目的を指定し、関連する研究論文をアップロードします。その後、アップロードされたすべての文書が目的に基づいてランク付けされます。これにより、研究者が手動でレビューできるようになり、さらに研究者はアップロードされたすべての文書に対して直接質問することもできます。
このシステムは現在、Deakin Universityの博士課程の学生の文献レビューを支援するために使用しています。
AI Tutor
AI Tutorは、学生が授業内容について質問し、その回答を学習資料から取得するRAGシステムです。学生は回答の出典リストを参照することで、回答を検証することができます。 このシステムはDeakin Universityの学習管理システムに統合されており、PDF文書、動画、テキスト文書を含むすべての学習コンテンツをインデックス化します。
動画に関しては、Index ProcessにおいてOpenAIの自動音声認識モデルであるWhisperを使用して文字起こしされ、その後チャンク化されます。AI Tutorは、2023年10月30日に開始した200名の学生が受講する授業でパイロット運用されています。
Biomedical Question and Answer
前述の2つのケーススタディは、比較的小規模なコンテンツサイズの文書に焦点を当てていました。これに対し、大規模なスケールでの課題を調査するために、BioASQデータセットを使用してRAGシステムを構築しました。 BioASQデータセットは、生物医学の専門家によって作成されたもので、ドメイン固有の質問と回答ペアが含まれています。回答形式には、Yes/No、テキスト要約、事実ベースの短文回答(Factoid)、およびリスト形式が含まれます。
この実験では、BioASQデータセットから4017件のオープンアクセス文書をダウンロードし、合計1000件の質問を用意しました。
ちなみに、この実験ではOpenAIが実装するOpenEvalsを使用して評価され、手動で40件の回答を検査し、OpenEvalsによって不正確と判断されたすべての回答が確認されました。その結果、自動評価は生物医学のドメインにおいて、人間の評価者よりも悲観的であることが判明しました。しかし、この結果は必ずしも正しいとは言えません。というのも、BioASQがドメイン固有のデータセットであり、評価担当者が専門家ではないためです。つまり、大規模言語モデルが評価担当者よりもこの分野に詳しい可能性があるからです。
7つの失敗
上述の3つのケーススタディを通じて発見された7つの失敗について説明します。下図の赤いBoxが失敗するポイントとその場所です。
(再掲) Scott Barnett et al.(2024) Seven Failure Points When Engineering a Retrieval Augmented Generation System
1. データベースが不十分
インデックス化した文書では回答できない質問を行った場合の失敗です。この場合、RAGシステムは「すみません、分かりません」といった応答を返しべきです。しかし、内容に関連しているが回答が存在しない場合、システムは誤って回答を生成する可能性があります。
2. 上位ランクの文書を見逃す
質問への回答がデータベース内に存在するが、その文書が十分に高いランクを得られず、ユーザーに返されない場合の失敗です。理想的には、すべての文書がランク付けされ、次のステップで使用されるべきです。しかし、実際にはトークン制約などの性能に基づいて選択された上位 K 件の文書のみが返されるため、発生します。
3. プロンプトに含まれない - Consolidatorの限界
回答を含む文書がデータベースから取得されても、生成時のプロンプトに含まれなかった場合の失敗です。これは、多数の文書がデータベースから返され、Consolidatorプロセスを経る際に発生します。
4. プロンプトから抽出されない
プロンプトに回答が存在しているにもかかわらず、大規模言語モデルが正しい回答を生成できなかった場合の失敗です。通常、プロンプト内にノイズや矛盾する情報が多すぎる場合に発生します。
5. 指定された形式に従わない
質問が表やリストなど、特定の形式での回答生成を求めている場合に、大規模言語モデルが指示を無視するケースです。
6. 不親切な回答
回答が返されるものの、ユーザーのニーズに対して具体性が足りない、または過剰である場合の失敗です。また、ユーザーが曖昧な質問をした場合にも発生します。
7. 不完全な回答
回答が完全に間違っているわけではないが、プロンプトに存在する情報の一部が欠けている場合の失敗です。例えば、「文書A、B、Cに記載されている主要なポイントは何ですか?」という質問に対して、一部のポイントが抜け落ちることがあります。この場合は、「文書Aに記載されている主要なポイントは何ですか?」のように質問を別々に行うことで回避することができます。
所感
今回は、RAGシステムにおける陥りがちな失敗を7つに分けて説明しました。RAGシステムに依存する部分よりもLLMに依存する部分の方が多いという印象です。特に、失敗ケースの3~5に関しては、LLMの性能に依存する部分が強いのでプロンプトやRAGの戦略で対処するのは難しいと感じています。OpenAIやMetaなどのモデル開発している企業に託すしかないですね。失敗ケースの6と7はRewriterを工夫すれば回避できそうな気がしています!