本記事はハンズラボアドベントカレンダー2022の4日目の記事です。
はじめに
下記のようなElasticBeanstalk上で動作するAPI(Node.js-Express)がありました。APIは主にDynamoDBやS3にアクセスします。
通常は問題なく動いてくれます。が、しばしばAPIの呼び出し元が504エラーを受け取ることがありました。
発生頻度は不定で規則性もなく、対応の優先度が低かったのですが、先日1日あたりのリクエスト総数の0.1%程度が504エラーで返ってしまうという事象が数日間続き、なんとかせねば、、、となりました。
HTTP 504: Gateway Timeout
504エラーが発生する原因は色々ありますが、今回はアプリケーションログなどから下記によって引き起こされたものと判断できました。
ロードバランサーは接続を確立しているが、アイドル状態のタイムアウト時間以内にターゲットが応答しなかった。
つまり、APIがリクエストされてレスポンスするまでに、nodeの処理時間がALBのアイドルタイムアウト(60秒)以上の時間がかかって、ALBが504を返していたのです。
何に時間がかかっていたのか
地道ですが、APIエンドポイントの各処理にconsoleログを仕込んだり、元々入れていたX-rayのトレーシング結果を確認したり、サポートに問い合わせたりして、ボトルネックとなる箇所を絞り込んでいきました。
その結果、 「DynamoDBにアクセスする処理(関数)が時間がかかっている」 ことが分かりました。
正確には 「DynamoDB自体の遅延は無く、DynamoDBのリクエストが何らかの要因で遅延し、最初のリクエストから130秒後のリトライで成功していた」 ことが分かりました。
ALBのアイドルタイムアウト、および、nginxのkeepAliveTimeoutを130秒以上に伸ばせば、手っ取り早く504エラーを解消できますが、根本的には解消しません。(呼び出し元のタイムアウトに引っかかるかもしれません)
リトライ処理を司るaws-sdkはデフォルト設定だったので、この設定を見直して根本対応を行います。
前提
- AWS SDK for JavaScript v2系
aws-sdkのリトライ
aws-sdkはAWSリソースへのAPIコールが失敗すると自動でリトライしてくれます。そのリトライのデフォルト設定(AWS SDK for JavaScript v2系の場合)は下記のようになっています。
- 接続タイムアウト 設定無し
- TCP接続確立までのタイムアウト
- ソケットタイムアウト 120秒
- TCP接続確立後のタイムアウト
- リトライ回数 設定無し
今回は、DynamoDB自体への接続に時間がかかっていた場合があるので、接続タイムアウトを小さな値に設定し、早くリクエストを捨てて、次のリクエストを投げることが良さそうです。
ただ、このリトライがどういう挙動をしているのかドキュメント上からは読み取れなかったので、少し検証してみました。
検証方法
EC2インスタンスにnodeを入れて、DynamoDBのlistTablesを呼び出してみたときのtcpdumpを取得します。そして、それをWiresharkで確認します。
- EC2インスタンスにてパケットキャプチャ開始
sudo tcpdump tcp -Alvvv -s 0 port not 22 -w tcpdump.pcap
- 別コンソールにてnodeスクリプトを実行
const AWS = require('aws-sdk');
AWS.config.update({region: 'ap-northeast-1'});
// default
const ddb = new AWS.DynamoDB({apiVersion: '2012-08-10'});
// タイムアウト設定を入れた例
// const ddb = new AWS.DynamoDB({apiVersion: '2012-08-10', httpOptions:{connectTimeout: 8*1000}, maxRetries: 2});
ddb.listTables({}, function(err, data) {
if (err) {
console.log("Error", err.code);
} else {
console.log("Table names are ", data.TableNames);
}
});
- しばらく待って、tcpdumpを止める
- ローカルマシンに結果をコピー
# ローカルマシンにて
scp -i ~/.ssh/key.pem ec2-user@xxx.xxx.xxx.xxx:/home/ec2-user/tcpdump.pcap ./
- Wiresharkでtcpdump.pcapを読み込みます
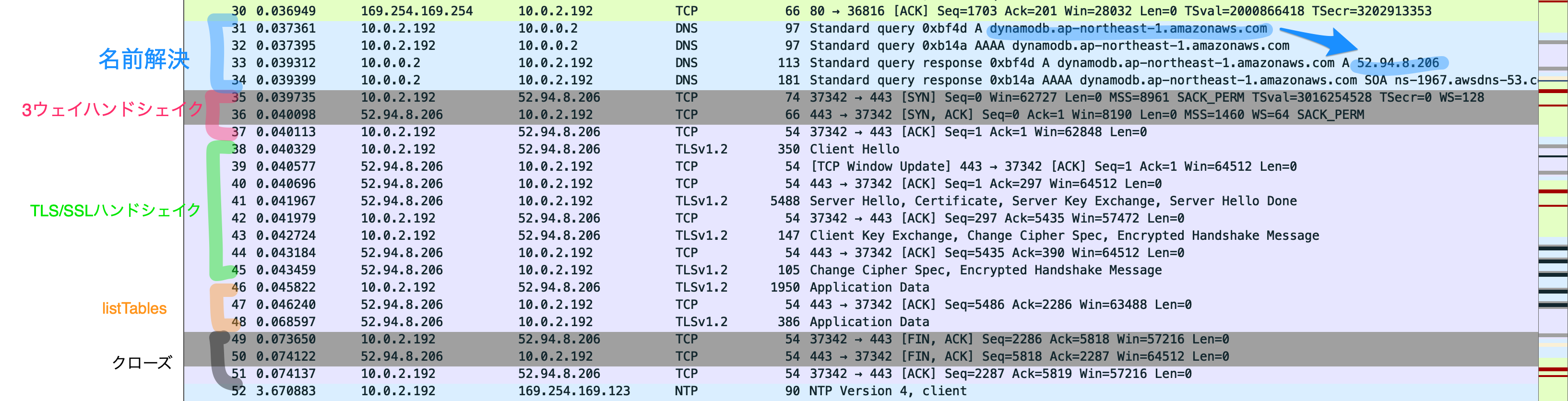
正常な場合の挙動
まず、正常な場合の挙動を見てみましょう。画像はWiresharkの画面キャプチャです。
10.0.2.192 がEC2インスタンスです。
dynamodb.ap-northeast-1.amazonaws.comの名前解決を行い、DynamoDBのIP: 52.94.0.206とTCP接続を確立し(3ウェイハンドシェイク)、その後Https通信のためのやり取り(TLS/SSLハンドシェイク)のあと、listTablesが行われています。
TCP接続が確立できない場合(aws-sdk設定デフォルト)
次に、TCP接続が確立できない場合の挙動を見てみましょう。aws-sdkの設定はデフォルトです。(EC2のSGを変更して外に行けないようにしました)
名前解決のあと52.94.8.230に対してSYNを送信しTCP接続を試みますが、外向け通信ができないのでACKが返ってきません。1秒後に再度SYN、更に2秒後に再度SYN、更に4秒後、8秒後、16秒後、32秒後SYNを送っています。
そして、最初のSYNから約130秒に再度名前解決を行い、今度は13.248.69.8に対して同様にTCP接続を試みています。
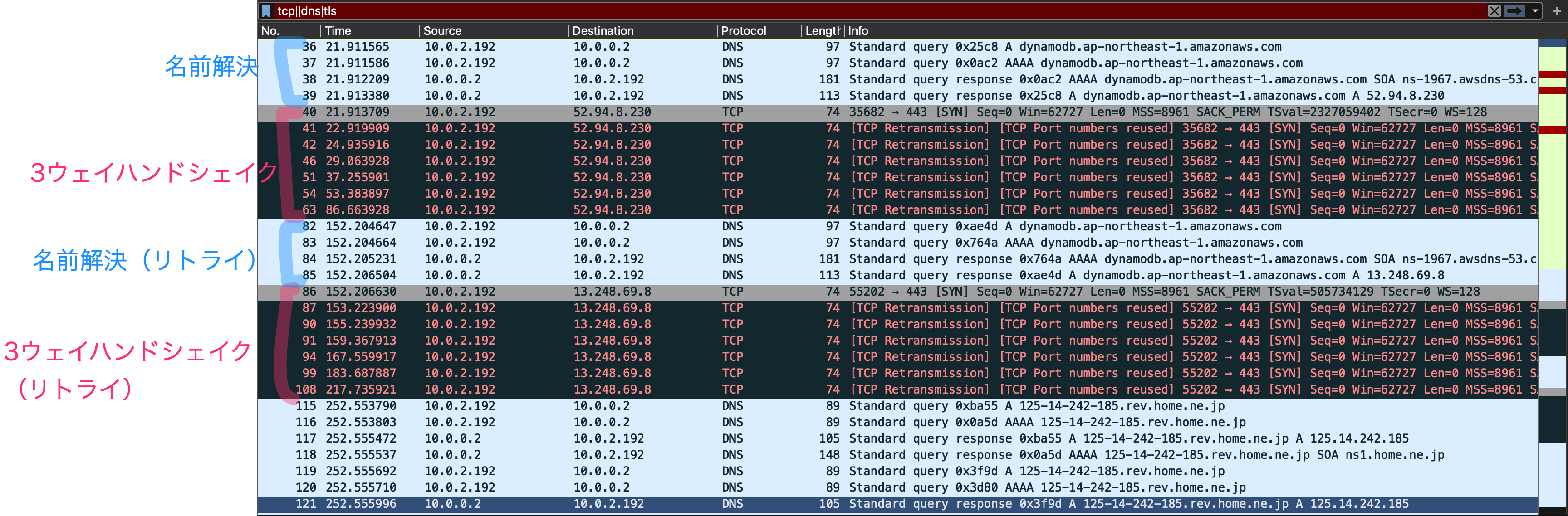
分かったこと
- aws-sdkのデフォルト設定だと接続タイムアウトは設定無しなので、2^リトライ回数秒毎にTCP接続を試みるかと思いましたが、130秒が上限のようです。
- リトライ毎にDynamoDBエンドポイントの名前解決が行われ、異なるIPに対して接続試行されるんですね。
TCP接続が確立できない場合(接続タイムアウト8秒、最大リトライ回数2)
次に、TCP接続が確立できない場合で接続タイムアウトを8秒、最大リトライ回数2とした場合を見てみましょう。
TCP接続のSYNの再送は1秒後、2秒後、4秒後と合計3回行われ、最初の名前解決から8秒後に再度、名前解決が行われています。そして、名前解決〜3ウェイハンドシェイクのセットは合計3回だけでした。
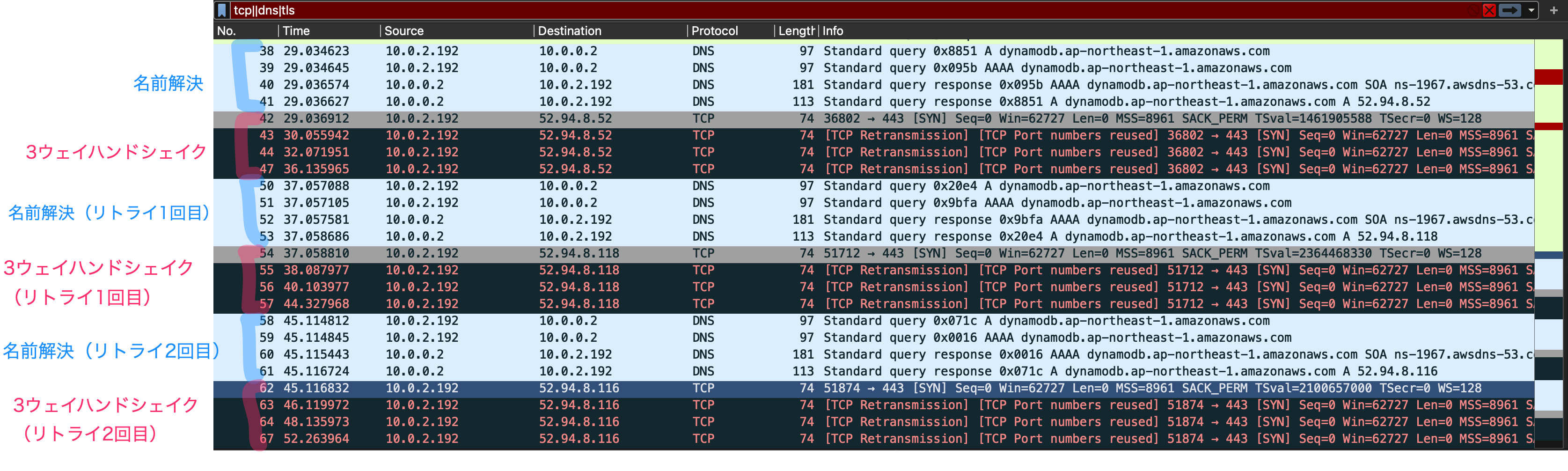
分かったこと
- 最大リトライ回数は3ウェイハンドシェイクのSYNの再送に対するものではなく、名前解決以降の処理すべてに対するものですね。
TCP接続後のソケットタイムアウトに引っかかる場合(接続タイムアウト8秒、ソケットタイムアウト1ミリ秒、最大リトライ回数設定無し)
ソケットタイムアウトをとても小さな値にして、ソケットタイムアウトに引っかかる場合の動作を見てみましょう。
名前解決のあと、3ウェイハンドシェイクでTCP接続を確立し、TLS/SSLハンドシェイクが行われてますが、この段階でEC2インスタンスがRSTを送信して接続を一方的に閉じています。
その後、名前解決〜TLS/SSLハンドシェイクのセットが続きます。。
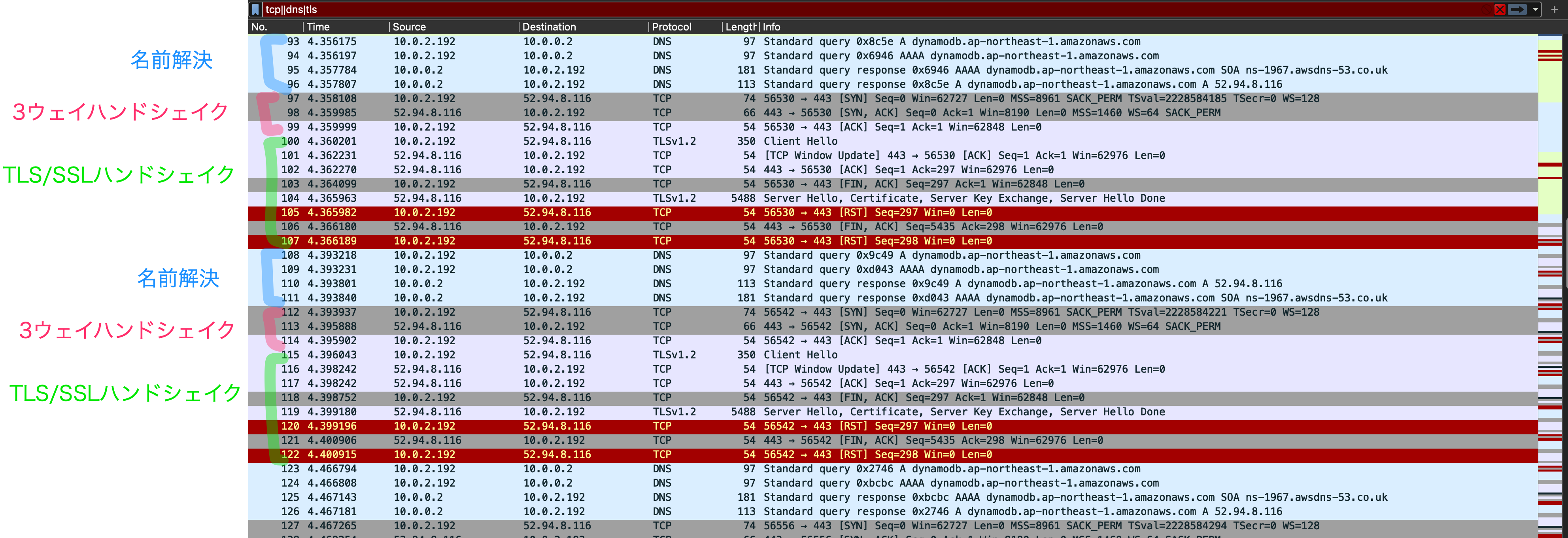
わかったこと
- 最大リトライ回数が設定無しの場合、上限は無いみたい。
- リトライが走るときは、名前解決からやり直し。
- のせてないですが、SSL/TLSウェイハンドシェイク後のlistTablesでソケットタイムアウトに引っかかる場合も名前解決からやり直しです。
まとめ
- aws-sdkの接続タイムアウト設定がデフォルト(設定無し)でかつ、TCP接続に失敗する場合は、最初名前解決したDynamoDBエンドポイントのIPに対して最大6回SYNを試み、約130秒後にリトライが行われる。(7回目(127秒後)のSYNは送信されない)
- 最大リトライ回数がデフォルト(設定無し)の場合、無限にリトライが行われる(たぶん)
- 接続タイムアウト・ソケットタイムアウトによるリトライは、毎回DynamoDBエンドポイントの名前解決が行われ、異なるDynamoDBのIPに対してリクエストが投げられることになる
| SYN再送回数 | 前回送信からn秒後に送信 | 最初のSYN送信からの秒数 |
|---|---|---|
| 1 | 1 (2^(1-1)) |
1 |
| 2 | 2 (2^(2-1)) |
3 |
| 3 | 4 (2^(3-1)) |
7 |
| 4 | 8 (2^(4-1)) |
15 |
| 5 | 16 (2^(5-1)) |
31 |
| 6 | 32 (2^(6-1)) |
63 |
| 7 | 64 (2^(7-1)) |
127 |
というわけで
こちらにあるように、AWSリソースのアクセス時にはネットワーク上のエラーが発生する可能性があり、これは避けられません。
DNS サーバー、スイッチ、ロードバランサーなど、ネットワークの多数のコンポーネントが、特定のリクエストの存続期間中どこでもエラーを生成する可能性があります。
ただの個人的な経験則ですが、ネットワーク上の問題で5秒待ってもだめなものは10秒待っても100秒待っても変わらない気がします。
なので、運悪く名前解決で問題のあるIPを引き当ててしまった場合にさっさと別のIPにリクエストが飛ぶように、接続タイムアウトはかなり短い値にするのが良さそうです。
そして、処理が終わらない・・・ということにならないように、最大リトライ回数もきちんと設定するのが良いです。
さいごに
動くからとデフォルト設定を過信してはだめですね。特に、今回のようにElasticBeanstalkでALB+nginx+Node.jsですべてデフォルト設定の場合はこの問題が起こる可能性があります。
sdkによって設定が違うのは何でなのか・・・
参考