はじめに
下図のような構成の機能があったのですが、データストアのバージョンアップのために、
Lambdaによるデータ投入を一時的に止める必要がありました。
データ投入停止中に発生したDynamoDBの変更をきちんと拾えるような手順が必要です。
ここら辺は雰囲気で理解してたので、DynamoDB Streamsを止めて再開したらいい感じにしてくれるんじゃね、とか思ってましたがそうじゃなかったです。
本記事はこの辺りについて調べたものです。

DynamoDB StreamsとLambdaについて
DynamoDB Streams概要
DynamoDBの項目(レコード)に対して変更(新規作成、値の変更、削除)を行うと、ストリームデータとして保持してくれるのがDynamoDB Streamsです。
これにLambdaを関連付けると、DynamoDBに変更があったらそのデータをLambdaが拾ってS3に吐く、みたいなことができます。
DynamoDB Streamsはテーブル単位で有効化できます。
有効化すると、それ以降のDynamoDBの変更がDynamoDB Streamsにレコードとして貯まっていきます。
レコードは24時間経過すると自動で削除されます。
DynamoDB Streamsは有効化する度に新しいStreamが作られ、現在有効な物はLatestStreamARNとして区別できます。

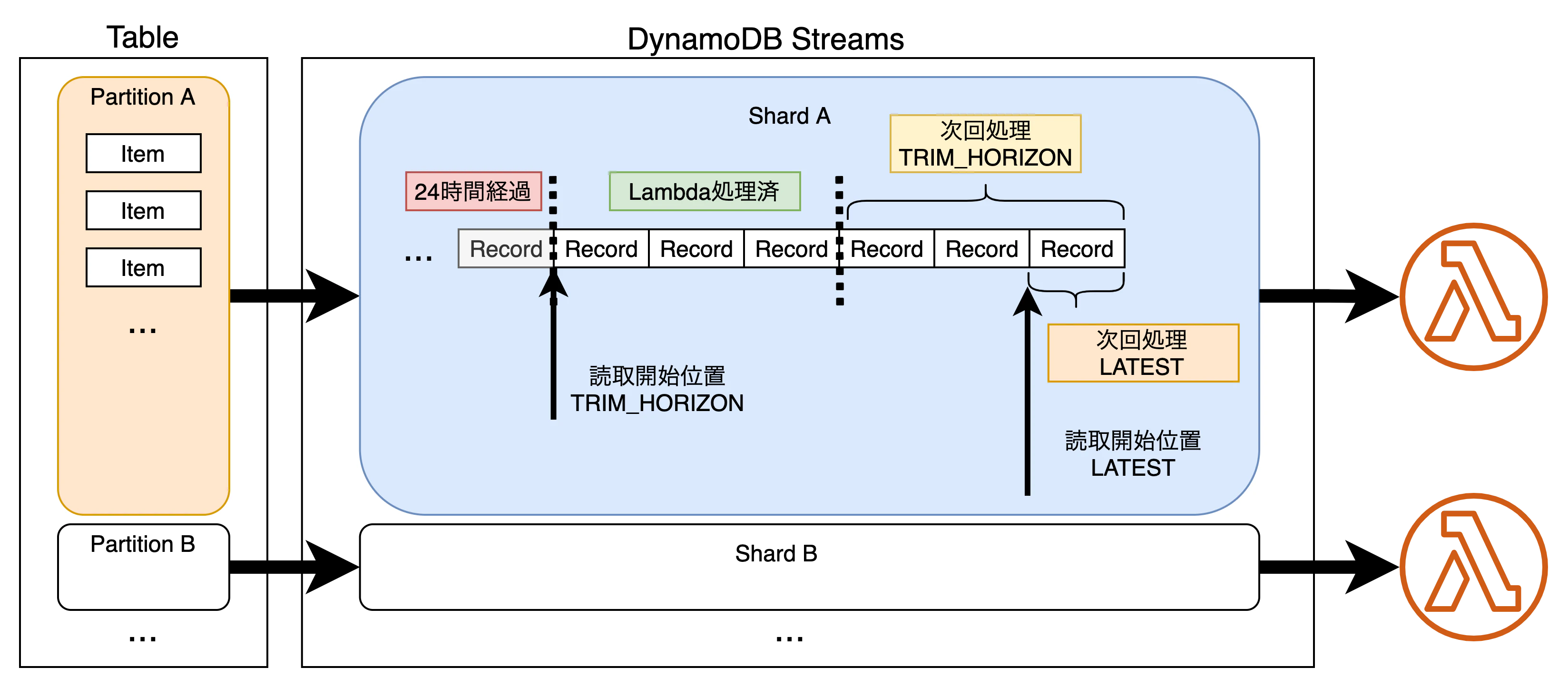
DynamoDB Streamsの中身
DynamoDB Streamsは並列した複数のパイプの中にデータが貯まっていくイメージです。
このパイプをShard、データをRecordと言います。
DynamoDBは項目(レコード)をパーティションに分けて保存しますが、このパーティションに対してShardが紐付きます。
例えば、Partiotion Aに属する項目Xを削除したとき、Shard Aに削除レコードとして追加されます。
また、同一Shard内のレコードの順序は保証されます。
例えば、テーブルに項目Xを新規追加してPartition Aに属したとします。項目Xに対して、属性値の変更、項目Xの削除を行うと、Shard Aには項目Xの新規作成、変更、削除というレコードがこの順番で追加されます。

Lambdaとの紐付け
LambdaのトリガーとしてDynamoDB Streamsを設定すると、全Streamの内、LatestStreamARNのものが紐づきます。
Lambdaは1秒間に4回、DynamoDB Streamsをポーリングし、最大でバッチサイズ分のレコードを受け取って処理します。
もう少し詳しく
LambdaはDynamoDB StreamsのShard毎に起動します。
Shard内は大きく3つの部分に分かれます。
- 24時間経過したレコード群
- 説明のため書いてますが、実際にはShardから削除されてます
- Lambdaが処理したレコード群
- Lambdaが管理してる(はず)
- Lambdaがまだ処理してないレコード群
- 今後処理される
この内、Lambdaがまだ処理してないレコード群から最大でバッチサイズ分のレコードをLambdaが読み取って処理を行います。
Shard内のどこから読み取るかですが、下記2種類のどちらかを指定します。
- 水平トリム(TRIM_HORIZON)
- 24時間経過したレコードをトリムしたレコードから、、つまり最も古い(先頭)のレコードから読み取る
- 最新(LATEST)
- 最も新しい(末尾)のレコードから読み取る
読み取ったレコード群から、[Lambdaが処理したレコード群]を除いたレコード群が、実際にLambdaが受け取るレコード群です。
結局、どうすれば良いか
最初の話に戻ります。
DynamoDB Streamsを止めて再開したらいい感じにしてくれるんじゃね
これはダメですね。
DynamoDB Streamsを無効化すると当然ですがDynamoDBの変更を拾ってくれませんし、再開すると元のStreamとは別のStreamに変わってしまいます。(=Lambdaとの紐付きが変わる)
では、DynamoDB StreamsとLambdaの紐付き(トリガー)を無効化して、再度有効化すれば良さそうですが、
今回対象のトリガーの読み取り位置が水平トリムなので、処理済みレコードを再度処理してしまわないかが懸念でした。
(トリガー無効・有効化時にLambdaは処理済みレコードを保持してくれてるのか)
これについては、やってみたところ保持してくれるみたいです。
というわけで、今回の構成では単純にLambdaトリガーを無効化し、再度有効化すれば良いことがわかりました。
おわりに
最初、読み取り開始位置の水平トリムと最新の違いが分かりませんでした。
Streamもトリガーも新しく作ったまっさらの状態では、どちらも同じ挙動をするからです。
既存のStreamに新しくトリガーをつける場合や今回のようなトリガー無効・有効の時に初めて違いが出ます。
分かり辛い。。
参考
スクリプト
Dynamo DBStreamsの動きを確認する時に使ったPythonスクリプト
import boto3
def list_dynamodb_streams(shard_iterator_type='TRIM_HORIZON'):
# DynamoDB client
dynamodb = boto3.client('dynamodb')
# 最新のStreamArn
latest_stream_arn = dynamodb.describe_table(TableName=TABLE_NAME)['Table']['LatestStreamArn']
print(latest_stream_arn)
# DynamoDB Streams client
dynamodb_streams = boto3.client('dynamodbstreams')
# shard一覧
shards = dynamodb_streams.describe_stream(StreamArn=latest_stream_arn)['StreamDescription']['Shards']
# 生きてるshardが対象
shard_ids = []
for shard in shards:
if 'EndingSequenceNumber' not in shard['SequenceNumberRange']:
shard_ids.append(shard['ShardId'])
# 最終結果
result = []
# shard毎に処理する
for shard_id in shard_ids:
print(" " + shard_id)
# shardイテレータ
shard_iterator = dynamodb_streams.get_shard_iterator(StreamArn=latest_stream_arn,
ShardId=shard_id,
ShardIteratorType=shard_iterator_type,
)['ShardIterator']
# shardからレコードを読み取る
while True:
data = dynamodb_streams.get_records(ShardIterator=shard_iterator)
# 読み取ったレコードと次のイテレータ
records = data['Records']
shard_iterator = data['NextShardIterator'] if 'NextShardIterator' in data else ""
print(" " + shard_iterator)
# 次のshardイテレータがない時は次のshardへ
if shard_iterator == "":
print(" shard_iterator is null")
break
# レコードが無くなったら次のshardへ
if len(records) == 0:
print(" record length is 0")
break
print(" save records")
# レコード情報を保存
for record in records:
result.append((shard_ids.index(shard_id), record['eventName'], record['dynamodb']['Keys']['id']['S']))
# 結果出力
for res in result:
print(res)
print("Done")
if __name__ == '__main__':
TABLE_NAME = 'xxxxxxxxxxxxx'
boto3.setup_default_session(profile_name='zzzzzzzz')
list_dynamodb_streams(shard_iterator_type='TRIM_HORIZON')
参考文献