はじめに
これから機械学習で試して遊びたいことがあるので、その予習編として、機械学習を最低限やるためにはどんな感じでどう書けば何がどう出てくるのか、前処理要らずのirisデータを使って超~基本の大枠だけ整理しておく。
コードの流れ
-
データセットの読み込み
load_iris()関数を使用 -
データの分割
train_test_split()関数を用いて、データを訓練セットとテストセットに分割 -
モデルの訓練
DecisionTreeClassifier()を使って決定木モデルを作成し、訓練セットで訓練 -
予測と評価
テストセットで予測を行い、accuracy_score()を使って精度を評価 -
可視化
plot_tree()を使って、決定木を可視化
必要なライブラリのインストール
すでにinstall済みであればスキップでOK。
pip install numpy pandas scikit-learn matplotlib
本編
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
# Irisデータセットの読み込み
iris = load_iris()
X, y = iris.data, iris.target
# データを訓練セットとテストセットに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 決定木分類器の作成と訓練
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
# テストセットで予測
y_pred = clf.predict(X_test)
# 精度の評価
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
# 決定木の可視化
plt.figure(figsize=(12, 8))
plot_tree(clf, filled=True, feature_names=iris.feature_names, class_names=iris.target_names)
plt.show()
出力されるもの
Accuracy: 1.00
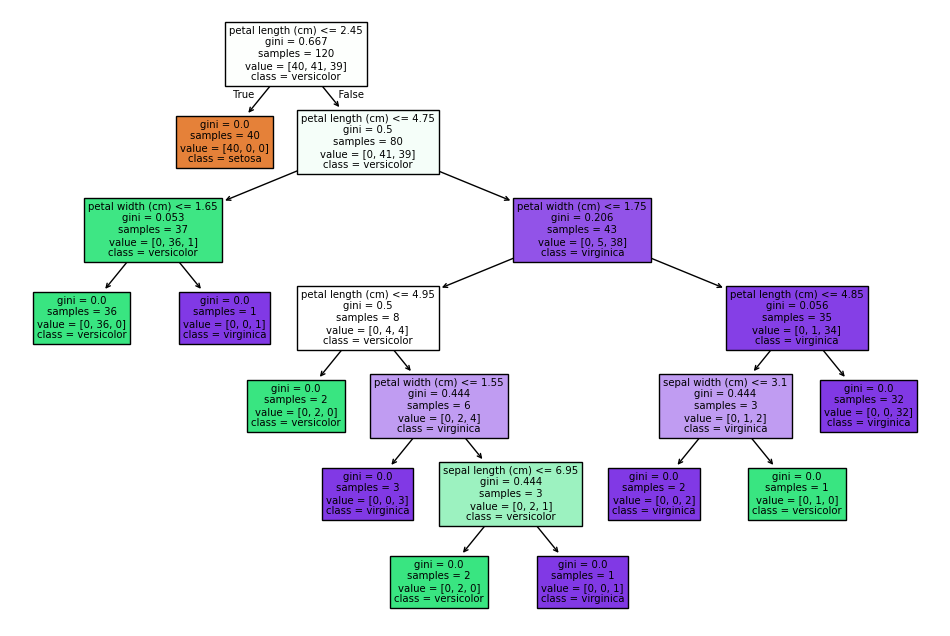
で、これはなに?
Irisデータセットを使って決定木分類器を訓練し、その性能を評価し、決定木の構造を可視化した。
これで最終的にわかることは以下の通り:
-
モデルの精度:
-
accuracy_scoreを使って、テストセットに対するモデルの予測精度を計算している。print(f"Accuracy: {accuracy:.2f}")で表示される精度は、モデルがテストデータをどれだけ正確に分類できたかを示している。 -
この値は0から1の範囲で表され、1に近いほどモデルの予測が正確であることを示す。数字のザックリしたイメージは下記の通り。
- 0.90以: 非常に高い精度。モデルがデータを非常によく理解してくれていてえらい。
- 0.80 - 0.90: 高精度。基本的にはこのあたりなら十分。
- 0.70 - 0.80: 中程度の精度。改善の余地はあるが、ある程度の予測能力はある。
- 0.60 - 0.70: 低精度。モデルの改善が必要。
- 0.50以下: ダメ!
-
-
決定木の構造:
- 決定木がどのようにデータを分類しているか、どの特徴が重要であるか、どの条件で分岐しているかを視覚的に理解できる。決定木の構造を視覚的に確認することで、モデルがどのように意思決定を行っているかを具体的に把握できる。
-
Irisデータセットの分類:
- Irisデータセットは、3種類のアヤメの花(Setosa、Versicolor、Virginica)を特徴量(花弁の長さと幅、萼片の長さと幅)に基づいて分類するための標準的なデータセットである。このコードでは、決定木を使ってこれらの花の種類を分類する方法を示している。
まとめ
大枠はこんな感じ。あとは実際使いたいデータや内容をいい感じにあてていけばヨシ。
コード自体はそんなに難しいわけではないので、元データと、自分が何をしたいのかを理解することが最も重要そう。