§ PyCaret ってなんだ?
今Twitter等でも話題になっている、PyCaretを使って予測モデルを作り、中古マンションの価格を予測するステップを紹介したいと思います。
PyCaretを使うと、最小限のPython コードで、予測モデルの作成、チューニング、予測の実施等一連の機械学習のステップが可能となります。
この記事では、これから機械学習を始めようという方に向けて、Pycaretを通して機械学習ってなんだっけ?というところを紹介しながら進めていきたいと思います。感覚的な分かりやすさを重視しますので、厳密な定義とは異なる表現もあるかもしれませんがご了承ください。
さて、このPyCaretですが、機械学習の予測モデル作成に必要となる、諸々の処理を簡単なコード一発で実行してくれる優れモノで、使ってみてなんて便利なのだろう!と驚きました。しかも、無料です!
が、しかし。そもそも機械学習のプロセスの大変さを理解しないと、ありがたみが分からないかもしれません。
§ 教師有り機械学習とは?
予測モデルを作成し、精度を高めていくというのは本当に大変な作業です。
ここではまず「教師有り機械学習」について必要な作業についておさらいをしたいと思います。
教師有り機械学習では、結果(回答)の分かっている過去のデータをもとに何らかのルール(モデル)を導き出し、そのルールにあてはめて知りたい結果を予測します。
例えば、過去の中古マンションの物件条件と価格のセットがあれば、最寄り駅がどこで、広さが何平米で、築何年で・・・という条件が分かれば価格も予測できそうです。このルールを様々なアルゴリズムを使って機械にルールを作らせる。これが機械学習ですね。
教師有り機械学習のステップはざっくり分けて以下のようになります。

① データを訓練データと検証データの分割
モデルの学習に使っていないデータでモデルの検証を行うため、データを訓練データと検証データに分割します。訓練データで評価してしまうと、それはカンニングみたいなモノですからね。通常は訓練データとモデルの精度を検証するデータを満遍なく公平に使うために分割を行い交互に入れ替えること(クロスバリデーション)を行います。
② モデルの作成(学習)とハイパーパラメータのチューニング
予測に用いるアルゴリズムを決めて訓練データを使って学習しモデルを作成し、精度を高めるためのチューニングを行います。
③ モデルの評価
訓練によって出来上がったモデルの精度を評価し、誤差がどれくらいで、使いものになるかどうかを評価します。
④ 未知の値の予測
評価が完了したら、予測モデルに結果のわからないデータを投入して予測結果を得ます。マンション物件の条件だけわかるけど、価格は分からないので予測するというイメージです。
§ 実際にPyCaretを使ってみる。
では早速Pycartを使ってこのフローを実施していきましょう。
まずは pip で pycaret をインストールしましょう。
今回はAnaconda Powershell からpip を実行しています。

まずはデータを読み込みましょう。今回も「Tableauで始めるデータサイエンス学習塾」で利用しているこちらの東京・中央線沿線の中古マンション価格データを教師データとして利用します。データ自体は以下のような内容になっています。
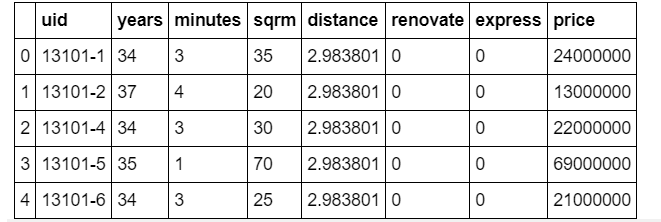
それぞれの項目の説明は以下です。
| 項目名 | 説明 | データ型 |
| uid | 物件のユニークなID | 文字列型 |
| years | 築年数 | 整数型 |
| minutes | 最寄駅からの徒歩距離(分) | 整数型 |
| sqrm | 物件の㎡数 | 整数型 |
| distance | 東京駅と最寄り駅の直線距離(都心からどれだけ離れているか?) | 浮動小数点 |
| renovate | 改装済みか否かフラグ | 整数型 ( 0 or 1 ) |
| express | 急行が止まるか否かのフラグ | 整数型 ( 0 or 1 ) |
| price | 取引価格(目的変数) | 整数型(単位:1円) |

import でPycaret を呼び出します。今回は価格を当てる回帰モデルですので、 pycaret.regression から import を行います。
目的変数(予測したい変数)をここではマンションの価格”price” にセットして、Setup ()ファンクションを実行すると、各フィールドが数値列なのか、カテゴリ列なのかを自動判別し、相違がなければリターンキーを実行します。
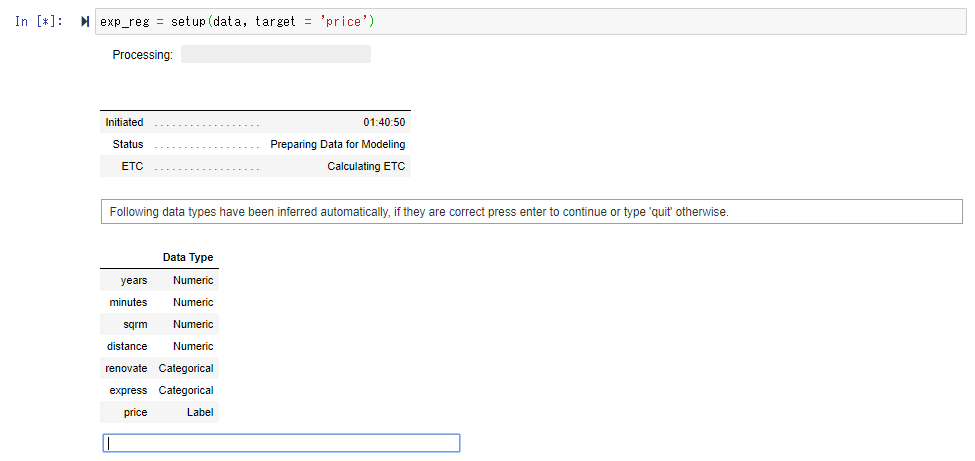
必要な前処理を実施します。


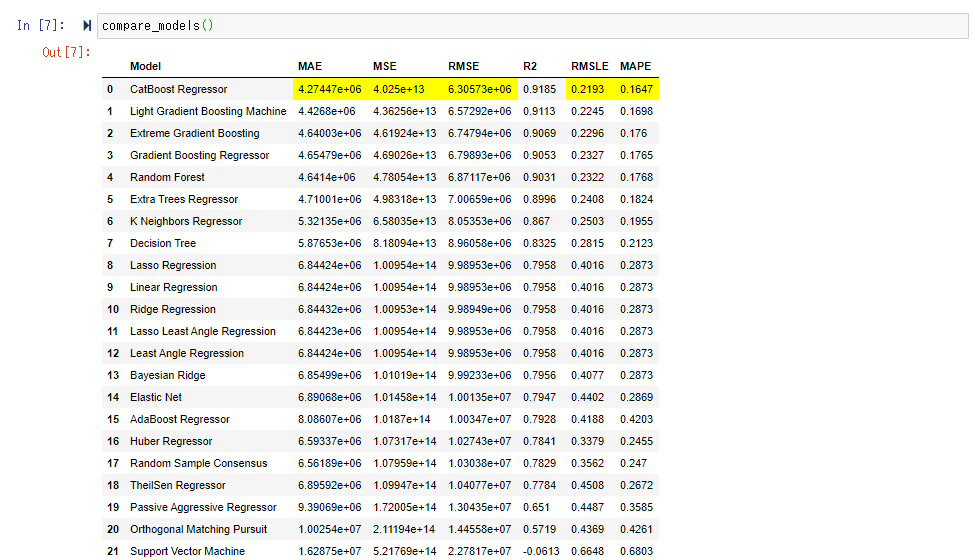
compare_model() で各種のモデルを評価、比較し誤差の少ない順番に並べます。内部的にはクロスバリデーション(偏りなく、満遍なく教師データと検証データを入れ替える)を実施しており、デフォルトではFold=10(データを10分割して、訓練データと検証データを入れ替えている)それぞれの平均のスコアを表示しています。
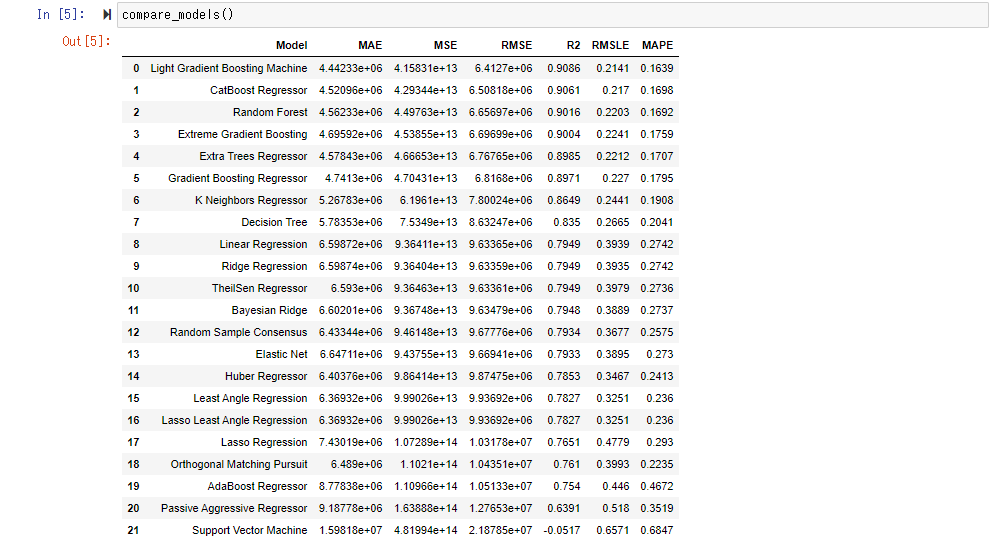
今回は「CatBoost Regressor」のスコアが良かったようです。RMSEは 630万ということですので、マンションあたりの誤差平均は630万程度とざっくり理解してもよいかもしれません。
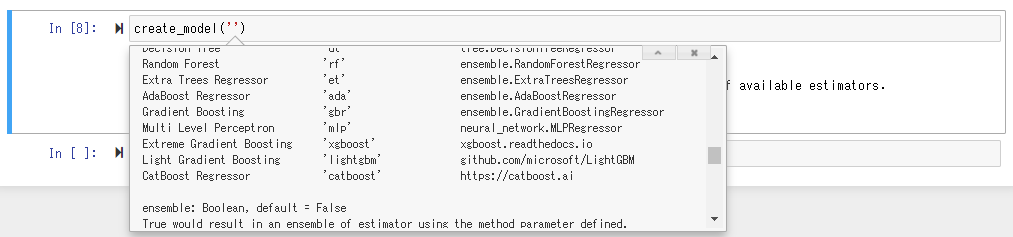
実際に訓練されたモデルを利用するために、 create_model()ファンクションを実行します。Shift+Tabで引数に何を入れれば良いかのガイドが出ますが、ここでは最もスコアの良かった「CatBoost Regressor」を指定します。
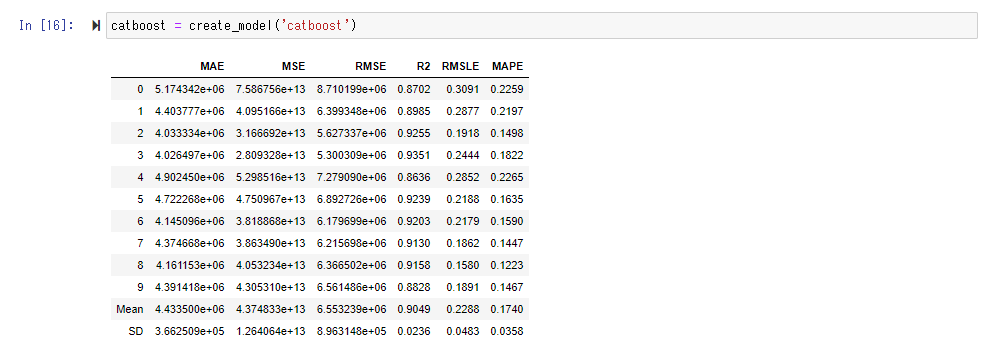
tune_model() によってモデルを作成すると、ハイパーパラメータ(学習する前にあらかじめ決める、モデルの動作に関する初期設定パラメータ)はデフォルトのままです。事前設定された範囲の中から適切なハイパーパラメータを探します。ここではベストなパラメータの探索方法としてRandom Searchが利用されているようです。

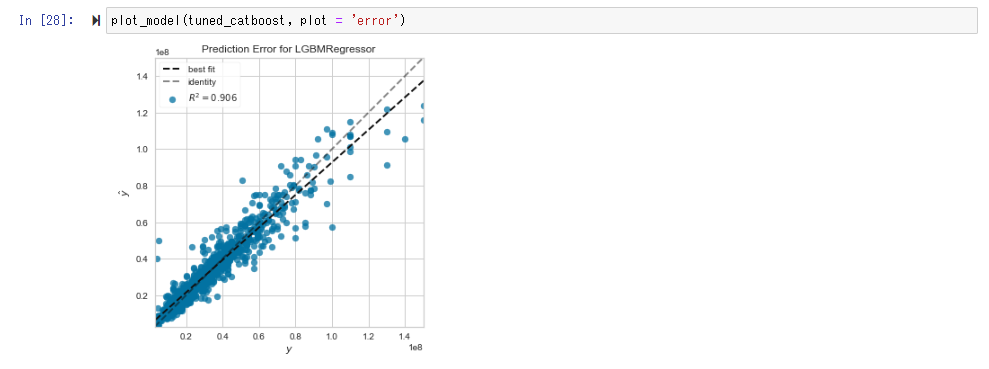
plot_model()によりモデルの精度を可視化して確認します。

Error Plot では予測と実測がイコールになる場合、分布が y=x の直線の付近に近づきます。
Feature Importance Plot では、どの変数が予測に強く関与しているかを確認します。今回の場合、築年数(years) 、平米数(sqrm)、distance(東京駅から最寄り駅までの直線距離)、minutes(最寄駅からの徒歩分数) の順で影響が強いことが分かります。

最後にfinalize_model()を実行し、モデルを確定します。ここでprint すると最適化されたハイパーパラメータを確認することができます。

ここで、学習済みのモデルができたので、モデル作成に使われるハズのない、Web上の不動産ページからスクレイピングしてきたマンション価格情報を準備し、”data_unseen”という名前のデータフレームに入れます。
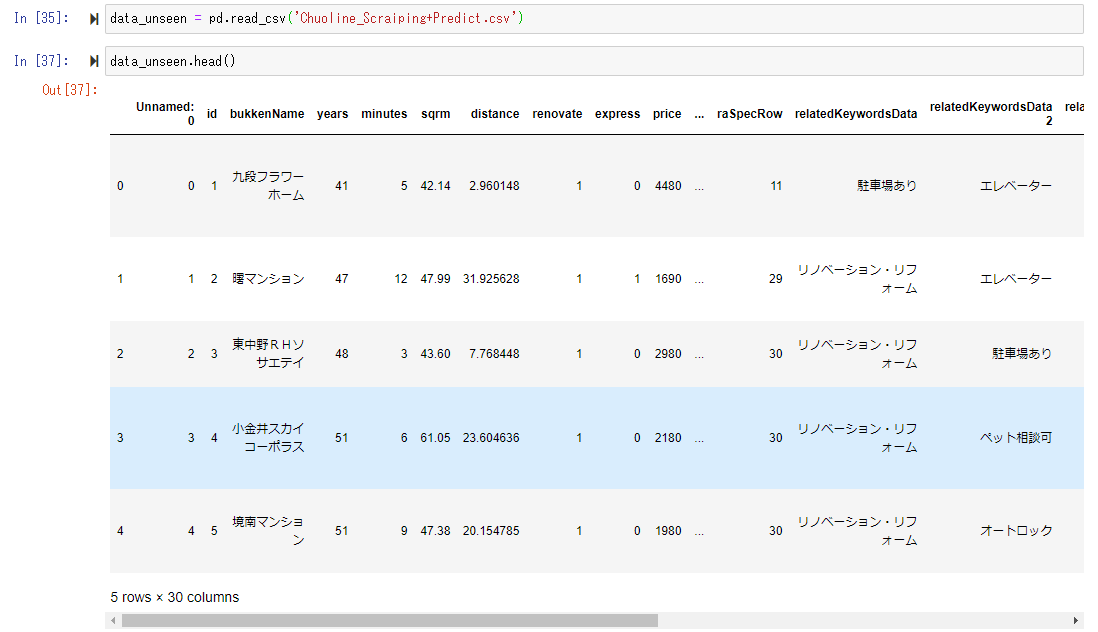
この”unseen_data” を、今作成した予測モデルに投入し、価格の予測を行わせてみます。
この操作は非常に簡単で、説明変数を学習データと同じ形で切り出し、predict_model()ファンクションを使って予測値を算出します。
以下、予測値が”Label”として追加されているのが分かります。本来は未知のデータについて、目的変数である”price”は分からないのですが、今回は既にWebで公開されているマンションの価格があるので、”price”はデータに入っています。(ただし、公開情報は単位が1万円となっています。)このWebに公開されている”price” と予測モデルが予測した予測値である”Label"を比べると、割とイイ感じの値が出ていることが感覚的に見れます。(大体、2千万~4千万で東京のマンション価格のレンジになっているようです。)

このデータをCSVに落とすことができるので、CSVに落としてからTaleauに接続して可視化をします。
ここでWeb上の公表価格”price” と予測モデルが算出した”Label"を比べると、予測より実際の価格のほうが安い「お買い得物件」やその逆に実際の価格が高い物件が見つかるかもしれません。 (以下、Tableau での予測価格の利用方法については、こちらのリンクと同じ内容です。)
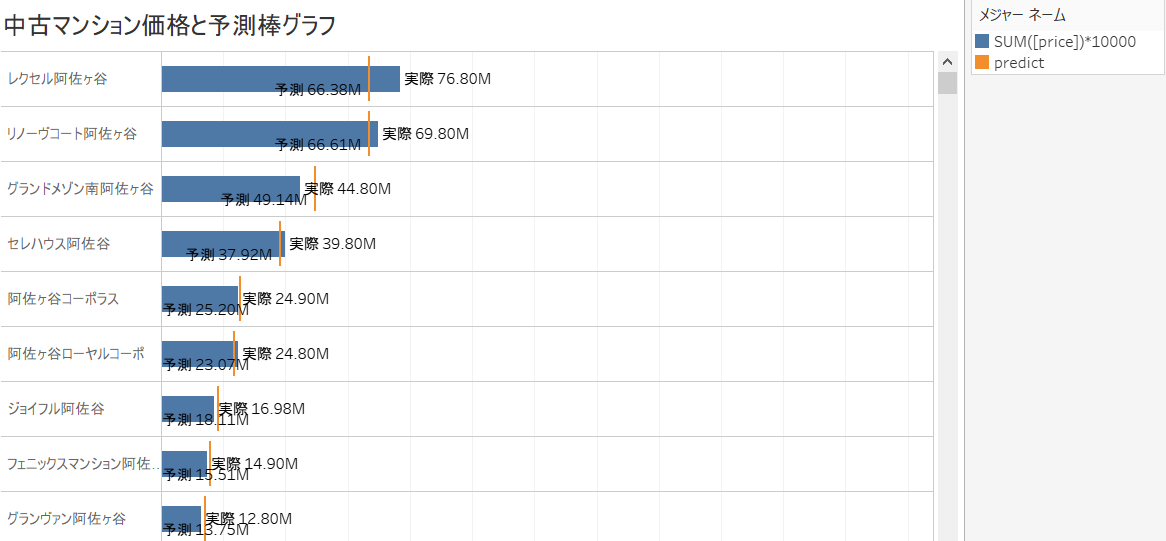
お買い得度を以下のように計算フィールドとして定義し、予測価格の方が掲示価格より高い場合、実際には「思ったより安い!」のでお買い得度が高くなり、逆に予測価格が掲示価格より低い場合、実際のは「思ったより高い!」のでお買い得度が低くなるようにします。

これを駅ごとに箱ひげ図を書いて可視化すると以下のようになります。
四谷はレンジが広すぎて当てにならない、吉祥寺はお買い得が低い、西国分寺はお買い得度が高い・・・といった発見があります。
これによって、東京駅から最寄り駅までの距離(いかに都心に近いか)という説明変数の他にも、「最寄り駅の人気度」などのあらたな要素を考慮しなければ説明が付かないといった示唆も得られるのかもしれません。(※注: 実際のお買い得かどうかは個人の価値観によるもので、一概に判断できないという前提で記事を執筆しております。)

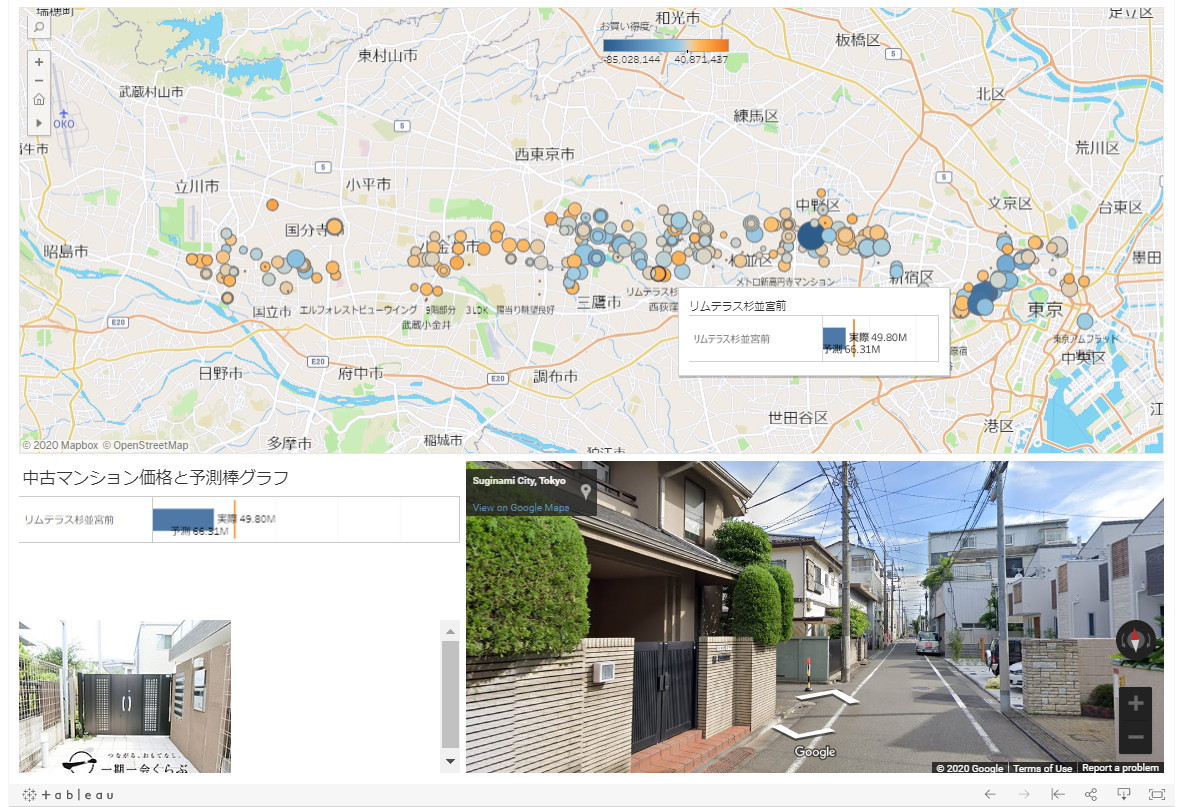
また、さらなるデータ活用の発展形として、スクレイピングしたデータから緯度経度をジオコーディングし、お買い得物件を地図上にマッピングします。以下、オレンジ色は物件がお買い得、青色はお買い得ではないとことを意味し、丸の大きさは物件の価格です。地図上の物件のポイントをクリックすると、その物件の画像情報、Google Street Viewと連携して周辺の街の様子を確認することができます。もちろんここでは掲載していませんが、掲載Webページとリンクしてダッシュボード内に物件情報を表示することも可能となります。
以上、PyCaretを使うと、機械学習でモデル作成に本来必要となるプロセスを丸っと実行してくれるため、Pythonのコーディングやデバッグの必要をほとんどすることなくお手軽に予想モデルの作成とハイパーパラメータのチューニングが(無料で)できてしまうというのは衝撃でした。
更に精度を求めてPythonでチューニングを行うとしても、Pycaretで起点としての当たりをつけることで、大幅に初期ワークロードは削減できるのではないでしょうか。
ただ、やはり最低限のPandasの知識や、機械学習の流れとして何を実施しているのか基本的なお作法は理解する必要はあるようです。
また、誤差をTableau等で可視化し、ドメイン知識と照合して新しい説明変数を加えるための考察をしたり、予測結果をインタラクティブなダッシュボードで活用することで、予測データの価値を倍増させることができるのではないでしょうか。
PyCaret には今回取り上げた回帰(Regression)について、アンサンブルの他にも、分類、クラスタリング、異常検知、自然言語処理、アソシエーション分析ができるようですので、こちらも今後使ってみた実用例を追加していければと思います。
Classification
Regression
Clustering
Anomaly Detection
Natural Language Processing
Association Rule Mining
是非、皆様も試してみてください。
参考文献:
Qiita記事:
GBDT系の機械学習モデルのパラメータチューニング奮闘記 ~ CatBoost vs LightGBM vs XGBoost vs Random Forests ~ その1(@KYOROさん)