※ 本記事は先進的な技術情報を共有するための目的で作成しており、Tableau 社から正式リリース発表とは一切関与がございません。リリース前のバージョンに関する、動作、仕様はリリース時に変更となる場合がございます。ご理解の上参照頂ければ幸いです。
Tableau のバージョン2020.2から Data Modeling機能が追加されました。今回はこのData Modelingの機能と今までのジョインとの違い、データブレンドとの使い分けについて考察してみたいと思います。
Tableau 2020.2 を開き、データに接続すると、いきなり今までのとは違った接続画面が出てちょっと驚きます。 もう一つテーブルを追加すると、2つのテーブルが曲円で繋がれる画面となります。これが新しい「Data Modeling」 機能です。(曲線が「うどん」のようなのでNoodleとも呼ばれています。)

2つのテーブルを結合する際に、今までのようなベン図もなければ外部結合、内部結合の指定もありません。
Data Modeling の特徴としては
§ 詳細なジョインの定義をしなくても、必要な結合をTableauがうまく考えてくれる
§ 今までのように先に結合表を作らない
§ ユニークでない表のジョインによって発生する重複行の問題を解決してくれる
というところかと思いますが、いくつか実際のデータを見ながらどのような動きをするのか見てみましょう。
① 重複行がある場合の動き
まずは、重複行がある場合の動きについて見てみましょう。
以下のようなシンプルな二つの表があるとします。
1行だけの売上表があります。地区=東京で5月に1件の売上がありました。
【売上表】

3行の担当者表があります。地区=東京の担当者は 「東京1」と「東京2」で二人いるようです。
【担当者表】

最初に、今まで見慣れた2020.1までの動きを見ていきましょう。
地区(売上) = 地区(担当者) の条件で内部結合をします。
売上表 に 地区=東京 が1行あるのに対し、担当者表には 地区=東京 が2行あるので、
1 x 2 = 2行のレコードが生成されます。

これはリレーショナルデータベースの世界では、同じ至極当たり前のことですが、重複行が現れることでちょっとした不都合が発生します。
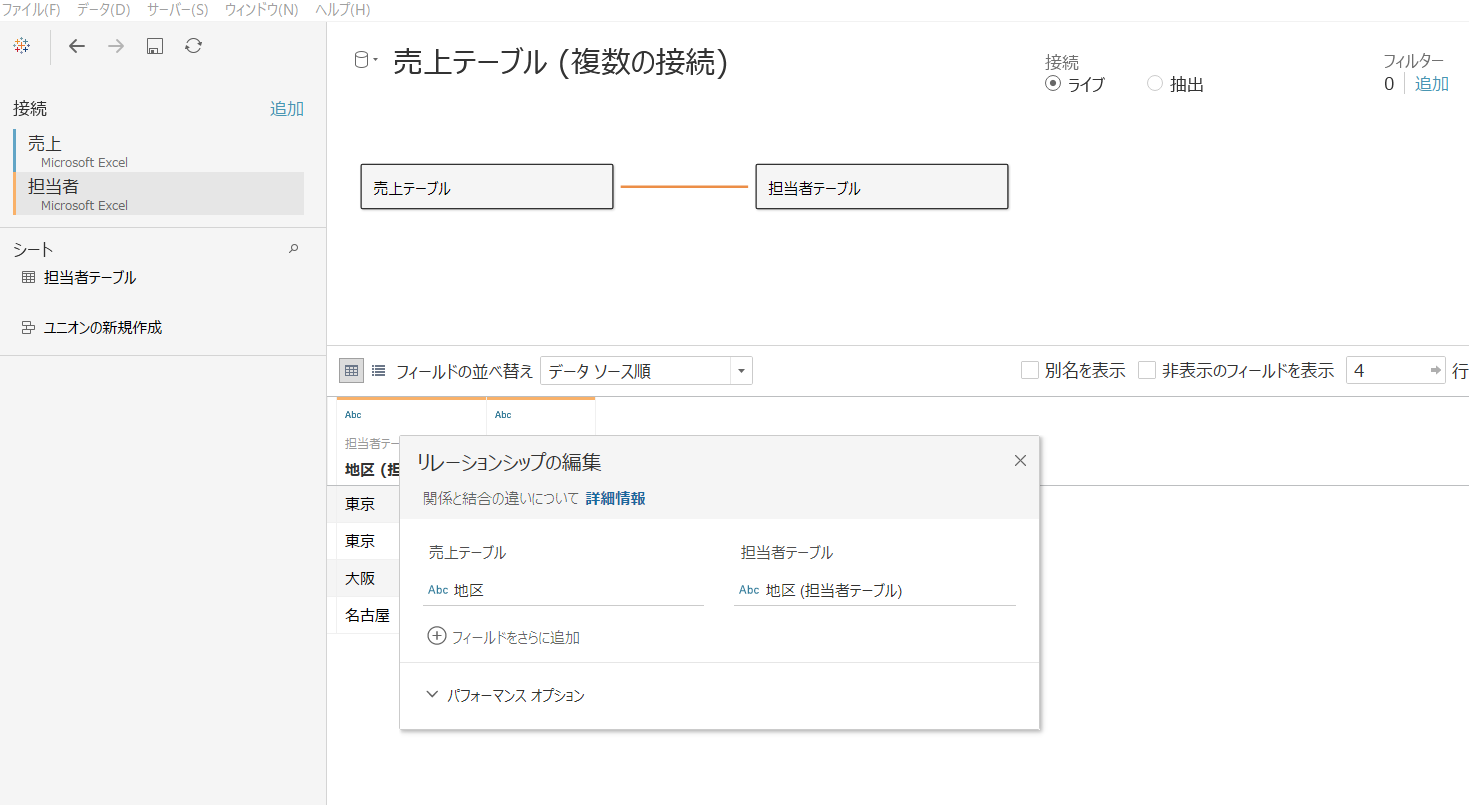
【2020.1】

シートで、「地区」、「顧客」ごとの売上を確認すると、重複行が発生しているため売上は2倍の200円になっていることが分かります。
東京で1件、高輪さんに対する100万円が唯一の売り上げだったハズなのに、東京の担当者が2人いるために、レコードが2行になりました。
担当者が2人いるからと言って、売上が2倍になる!ということはない ですよね・・・
これはおかしな話です。
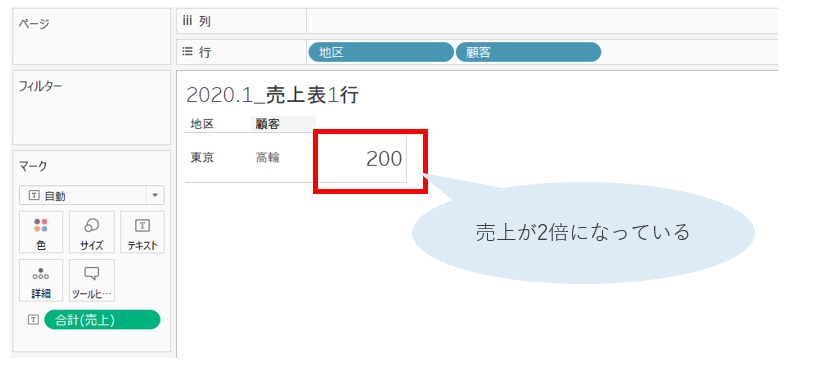
担当者を行に追加して、小計を追加してみても、担当者ごとに売上が存在して、小計が2倍の200万になっています。

同じことを、2020.2 で行ってみましょう。
売上表と担当者表の間でリレーションを貼ります。
【2020.2】

2020.2 Data Modeling では、最初から2つの表を結合した結果表を作りません。なので、それぞれの表が独立して表示されます。売上表をクリックすると、売上表のみ表示されます。

担当者テーブルをクリックすると、担当者表のみ表示されます。

では、先ほどと同じように、売上表から地区と顧客、売上を表示します。
2020.2では重複行が発生していないので、売上は100万円です。

同じく担当者を行に追加して小計を追加してみます。担当者それぞれに100万円が表記されますが、小計は本来の東京の売上である100円となっています。
事実に即した表示方法になっていますね!

② 外部結合の扱い方について
ここで、Data Modelingには外部結合を指定するところがないので、どのようにしているのかな?と思いました。やってみましょう。
売上表示は以下の一行があります。

担当者表には以下のように東京以外にも”大阪”、”名古屋”の地区が存在します。営業地区の定義はあるけれども、売上が立っていないので、売上表に”大阪”、”名古屋”の記録はありません。
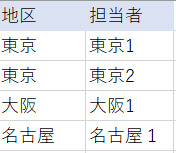
Tableau 2020.2 から接続し、 地区(売上)= 地区(担当者) でリレーションを定義します。ここで外部結合を指定したいのですが、指定するところがないので、少しタジロギます。ここを何とかうまくやってくれるのがData Modeling の機能です。

シートに移動して、担当者テーブルから「地域」、「担当者」をドラッグし、売上を表示します。
売上の立っていない大阪、名古屋についてもデータとして表示されますので、内部結合で決め打ちというわけではなく、必要に応じて外部結合をし売上の立っていない(売上表にはデータの存在しない)大阪、名古屋の地区についても地区名を表示してくれています。

ここで、売上表から購入した顧客名をドラッグすると、売上のない(顧客のいない)大阪と名古屋が消えてしまいます。
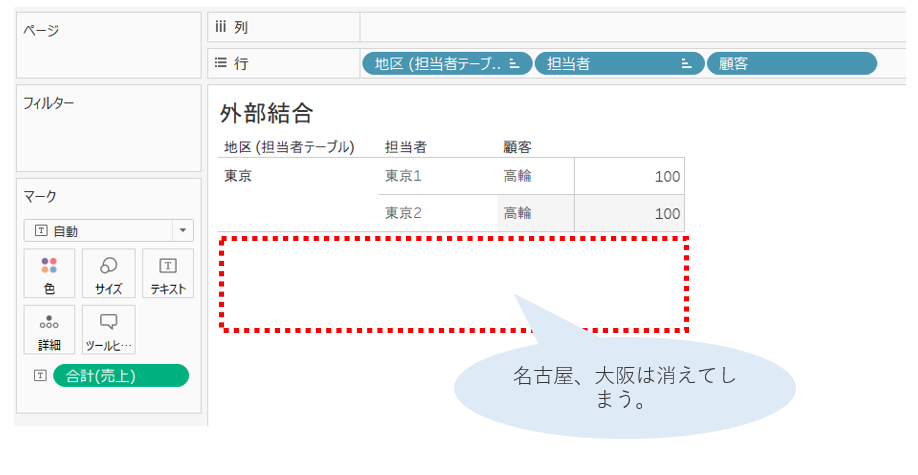
これについては、ツールバーから「分析」 → 「表のレイアウト」 → 「空の行を表示」 と設定することで、消えてしまった大阪と名古屋地区を表示することができます。
 PAGE_BREAK: PageBreak
PAGE_BREAK: PageBreak

ここで、Data Modeling のリレーション定義機能に戻って 担当者テーブルの参照整合性の指定で「すべてのレコードが一致する」を選択すると、担当者表の全ての地区が売上表に存在する(包含される)と仮定するため内部結合したのと同じ結果となり、両テーブルに存在する「東京」のデータだけが表示されます。 内部結合的な動きを期待する場合にのみ使用するようにした方が良いでしょう。


③ トランザクション表同士の結合(粒度が同じ)
「売上表」と「宣伝広告費」を比較して売上に対する宣伝広告費がどれだけの割合をしているか確認したい場合など、トランザクション表同士を結合するケースについて見てみましょう。
このような売上表があるとします。東京と大阪の売上履歴です。
【売上表】
一方、宣伝広告費表があり、地域ごと、宣伝メディアごとの費用があります。
【宣伝広告費】

東京の5月の売上は(100+200+300)=600万円、広告費は(30+40+50)=120万円 となりますので、東京地区での売上に対する宣伝広告費は 120/600 = 20 % と分かりますね。
では、これを2020.2のData Modelingを使って計算してみましょう。
売上表と宣伝表を
日付(売上) = 日付(宣伝費)
地区(売上) = 地区(宣伝費) でリレーションを貼ります。

ここで、「日付」 と 「地区」 ごとの 売上 と 宣伝費用を並べて表示します。
東京については 売上=600万円、宣伝費=120万円 ですから正しく比較できています。
宣伝費用の割合は、東京では20.00% となります。今までのジョインでは重複行が発生してしまっていたところが、うまく処理できているようです。

④ トランザクション表同士の結合(粒度が異なる)
それでは、売上表と、宣伝費で日付の粒度が異なる場合はどうでしょうか。
売上表は日単位で売上が計上されます。このようにレコード記録の粒度が異なる場合に、ひと月の売上とかかった宣伝費用を集約してから比較したいというケースもあります。

一方、宣伝費は月単位(全て2020/5/1の日付)で計上されています。
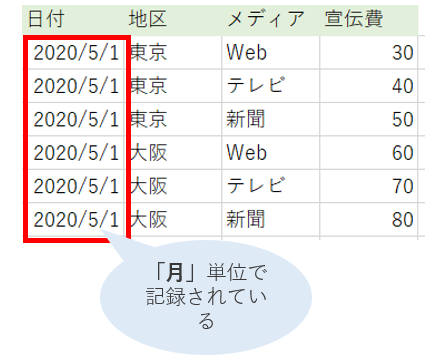
先に答え合わせのために検算しておくと、東京の5月の売上は(100+200+300)= 600 万円
一方東京の5月の宣伝費用は (30+40+50) = 120 万円 となります。売上に対する宣伝費用は 120 / 600 = 20.00% となりますね。
さすがに、このように粒度が違う2つの表を集計したから結合するという場合にはData Modeling以外の別の工夫が必要です。
Data Modelingも集計してから結合するとう機能ではないので、日付のレベルは合わせないといけません。売上日が 2020/05/02 だった場合、 宣伝費が計上される 2020/05/01 とは結合できないのですね。(違う日付ですから。)
※ 現在はData Modelingの機能で結合条件に計算式を用いることができないようです。日付レベルを月のレベルに揃えてからリレーションが張れるようになると良いですね。
このように集計してから結合するといった場合はデータブレンドの機能を利用すると良いでしょう。
たとえば以下のようにします。
売上については、日付を 「年月」のレベルに切る詰めるために、詳細=年/月としてカスタム日付を作成します。

同じように、宣伝費用でも日付を「年月」レベルに合わせるために、詳細=年/月としてカスタム日付を作成します。
データ → リレーションシップの編集で
地区(売上) = 地区(宣伝費)
日付(年/月)(売上)= 日付(年/月)(宣伝費) のリレーションシップを貼ります。
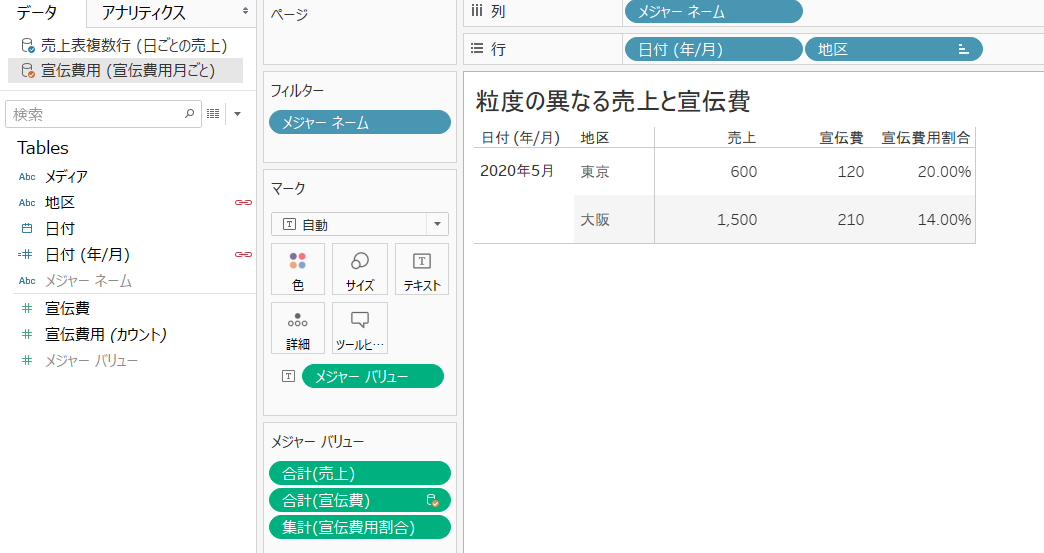
これは、同じ地区、同じ月で切り詰めた年/月 で集計した値同士を、集計してから突き合わせるということになります。

以下のように、売上を月で集計してから宣伝費用と結合するため、5月という月の単位で売上と宣伝費用を比較できるようになりました。
5月の売上が 600万 で宣伝費が120万ですから、売上に対する宣伝費用の割合は 20.00%となります。 計算は合っていますね。
このようにデータブレンド機能は、「集約してから」結合する際に威力を発揮するのですが、先に利用した方がプライマリデータベース、後から利用した方がセカンダリデータソース、プライマリデータソースを外部結合とする等のTableau オリジナルのルールがあるので、注意しなければなりません。
【参考】データブレンドとは

きちんと外部結合、内部結合の方式を意識し、集計のレベルを設計したい場合はTableau Prep Builderを使ってフロー化した方が良いでしょう。データ生成はフローを実行しタイミングとなりますので、バッチ処理となりますが、前処理を分離して利用する前に完了して置くことで可視化のパフォーマンス向上も期待できます。
【参考】Tableau Prep Builderのフロー定義

ちなみに、Data Modelingの箱(論理モデル)をクリックするとその中身(物理モデル)を定義することができます。
こちらが論理モデルを構成する物理モデルを開いたところです。

マスター表がキーに対してユニークと分かっていて、トランザクション表とマスター表の定義が明確な場合、この物理モデルの中できちんと定義して置くのが良いでしょう。今まで通りの動きを期待する場合はこちらのの物理モデルを使うという方法があります。
このように、Data Modeling では複雑なデータ結合の構造(物理レイヤー)を論理レイヤーで一つの箱と表現しラッパーのように隠ぺいして整理するという効果も期待できます。
【参考】データモデルにおける「論理レイヤー」と「物理レイヤー」

以上、要件に合わせた使い分けは以下のようになりそうです。
| 利用シーン | 対応する方法 |
| * キーについてユニークなマスタ表への結合 | 今まで通りのジョインでも全く問題ない |
| * キーでユニークにすることができないマスター表への結合
* 集計の粒度が同一のトランザクション表同士の結合 |
Data Modeling の活用によりTableauの自動化が期待できる |
| * 集計の粒度が異なるトランザクション表同士の結合 | データブレンドを利用して集計してから結合 |
| * きちんと結合方式の設計をしてフロー化する、前処理が複雑、バッチ処理でも良い。 | Tableau Prep Builderを利用する |
今後、よりBIツールがスマートになり、先回りで気を利かしてデータの前準備をしてくれる機能開発の先駆けとなりそうなです。
一方で、やはりマスター表のデータの持ち方として、キーに対してユニークにデータを持たなければおかしなことになるという感覚はデータを扱う際に依然として必要であり、データの持ち方もキレイに保つ心がけも同時に必要になるのではないかと考えます。
以上、参考になれば幸いです。
参考資料