はじめに
Splunkのユーザー会Go Japan Splunk User Group通称GOJASのMeet Upで発表したネタです。
プライベートのGmailアドレスの受信件数がある時期より増えたように感じたので、Splunkに取り込んだら何かわかるだろうかと思い分析してみました。
概要
- Gmailデータを用意する
- Splunkに取り込む準備をする
- Splunkに取り込む
- Splunkで分析する
1.Gmailデータを用意する
分析元データを用意します。手段はいくつかありますが、他人のメールデータを使うのはスーパーハカーでもない限り普通は難しいので今回は自分のメールをデータとして使います。
メールデータを1件ずつ手動で取り出すのは面倒なので、以下のサイトを参考にGAS(Google Apps Script)を使ってメール情報を一括でGoogle Spread Sheetに出力し、その後csvファイルとしてダウンロードします。
参考先サイト(いつもありがとうございます。)
[Google Apps Script]メール情報をスプレッドシートに書き出す
Google Spreadsheetで各シートをCSVとしてダウンロードするためのリンクを表示する。
[スプレッドシートのデータをGASを使って1クリックでCSVに吐き出すものを作る。]
(https://www.pnkts.net/2018/04/27/spreadsheet-gas-csv/)
※本当はデータの出力からcsvファイルダウンロードまで自動化したかったのですが技術時間がなかったので断念しました
今回は、メール受信日時,メール送信元,メール件名をデータとして出力してみます。

GAS使用時の注意点
- GASを使ってGoogle Spread Sheetにメールデータを出力する場合、一度に出力できるのが最大500件までなのでご注意ください。
2. Splunkに取り込む準備をする
先ほどcsv形式で出力したファイルをSplunkに取り込みます。が、その前に今回取り込むデータを分析する個別Appを作ります。
なお、個別Appを作らなくても分析自体はできます。しかし、今回の分析に関する設定群を1つのAppにまとめてしまうことで、後々管理が容易になります。よって、最初の段階でAppを作ってしまったほうがよいと思います。
データを取り込み、分析をするためには最低限以下の設定が必要なので、App内に定義していきます。
- インデックス定義(indexes.confで定義)※
- ソースタイプ定義(props.confで定義)
※今回のデータを取り込むインデックスはSplunkデフォルトのインデックス(main)でもよいのですが、後々のことを考えると個別のインデックスにしてしまった方がよいです。
[idx_gmail]
homePath = $SPLUNK_DB\idx_gmail\db
coldPath = $SPLUNK_DB\idx_gmail\colddb
thawedPath = $SPLUNK_DB\idx_gmail\thaweddb
[st_gmail]
CHARSET = UTF-8
TIME_PREFIX = ^
TIME_FORMAT = %a %b %d %Y %H:%M:%S %Z
MAX_TIMESTAMP_LOOKAHEAD = 40
SHOULD_LINEMERGE = false
ソースタイプ定義例の補足
TIME_FORMATアトリビュートは、データに含まれる時刻の書式を指定するパラメータです。GASで出力すると、行頭から以下のような書式で出力されるので、strftime形式で指定します。
Thu Jan 31 2019 23:00:47 GMT+0900 (JST),
Thu Jan 31 2019 20:31:13 GMT+0900 (JST),
3.Splunkに取り込む
インデックスとソースタイプを定義したら、GASで出力したcsvファイルをSplunkに取り込みます。取り込む方法は幾つかありますが、Splunkのファイルアップロード機能を使って取り込むのが手っ取り早いです。
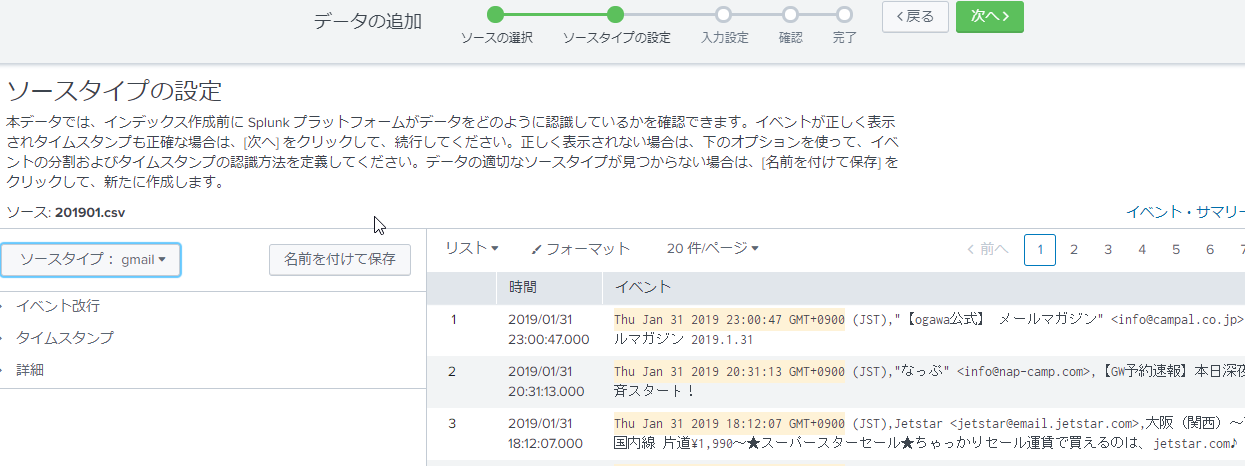
ファイルアップロード機能におけるソースタイプ設定画面で先ほど定義したソースタイプを選択し、タイムスタンプが正しく認識されていることと、1行が1つのイベントとして認識されていることを確認した後、最初に作成した個別Appで作成したインデックスにデータを取り込みます。
次の画面はファイルアップロード時におけるソースタイプの設定画面のサンプル画面になります。
4.Splunkで分析してみる
Splunkにデータを取り込んだら色々な観点で分析してみます。
時系列で分析してみる
まずは、メールの受信日時データを軸にして分析してみます。
index=idx_gmail
| timechart span=1mon count
| trendline sma2(count) as "移動平均"
| rename count as "受信件数"
このサーチ結果を縦棒グラフ(Column Chart)で表示してみますと以下のような感じで可視化することができます。※移動平均をグラフにオーバーレイさせています

次に、メールの受信件数を時間帯と曜日ごとに集計してみます。
index=idx_gmail
| eval date_hour=substr("00"+date_hour,-2)
| eval date_wday=case(
date_wday="monday","1 mon",
date_wday="tuesday","2 tue",
date_wday="wednesday","3 wed",
date_wday="thursday","4 thu",
date_wday="friday","5 fri",
date_wday="saturday","6 sat",
date_wday="sunday","7 sun"
)
| chart count over date_hour by date_wday
このサーチ結果を縦棒グラフ(Column Chart)の積み上げ形式で表示すると以下のような感じで可視化できます。この例では昼12時台と18時台に多くメールを受け取っていることが判ります。
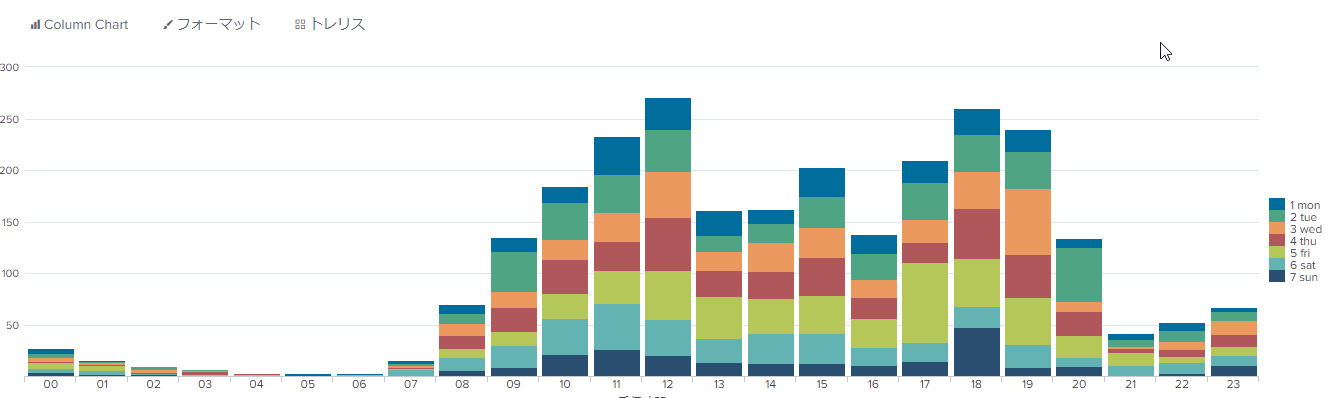
次のサーチは先ほどのサーチと同じように受信件数を時間帯と曜日ごとに集計するサーチですが、結果の表示方法を変えています。
index=idx_gmail
| eval date_hour=substr("00"+date_hour,-2)
| eval date_wday=case(
date_wday="monday","1 mon",
date_wday="tuesday","2 tue",
date_wday="wednesday","3 wed",
date_wday="thursday","4 thu",
date_wday="friday","5 fri",
date_wday="saturday","6 sat",
date_wday="sunday","7 sun"
)
| chart count over date_hour by date_wday
| transpose 0 header_field=date_hour
| rename date_wday as "曜日"
このサーチ結果をヒートマップで表示すると、先ほどの積み上げグラフに比べ、どの曜日の何時ごろにメールを受け取っているかが視覚的に判るようになります。

なお、この表示形式にした場合、曜日と時間ごとの件数はわかりますが、一方で、積み上げグラフ表示で判った「時間ごとの総件数」が判りづらくなります。見たい内容によって最適な視覚エフェクトを使うのが重要です。
送信元で分析してみる
今度はメールの送信元情報を分析してみます。
index=idx_gmail
| rex field=_raw "^[^,]+,\"?(?P<from>[^\"<,]+)"
| top limit=10 from
このサーチ結果を円グラフ(Pie Chart)で表示すると、送信元の割合を視覚的に確認することができます。

楽天カードさんから届くメールが多いことが判ります。
※サーチ文の補足
2行目のrexコマンドは、正規表現を使ってGmailデータ(文字列)からメール送信元に該当する文字列をfromフィールドとして抽出しています。この正規表現を使ったフィールド抽出設定は、予め「フィールド抽出」定義としてソースタイプごとに設定することができます。

次のサーチはメール送信元の月別トップ10を分析するサーチになります。
index=idx_gmail
| rex field=_raw "^[^,]+,\"?(?P<from>[^\"<,]+)"
| eval date_mon = strftime(_time,"%m")
| stats count as cnt by date_mon from
| sort date_mon - cnt
| streamstats count as rank by date_mon
| where rank<=10
この結果をトレリスで表示することで月ごとの送信元トップ10を可視化することができます。

今度はメールの送信元ドメインのトップ10をサーチします。
index=idx_gmail
| rex field=_raw "@(?P<from_domain>[^>]+)"
| top limit=10 from_domain
このサーチ結果をそのまま統計情報で表示すると以下のように表示されます。

送信元分析の最後はメール送信元のTLDを分析してみます。
index=idx_gmail
| rex field=_raw "(?P<from_tld>\.[^\.]+(?=>,))"
| top limit=10 from_tld
この結果を表示してみます。

どうやらほとんどjpドメインから届いていることがわかりました。
メールタイトルで分析してみる
最後はメールタイトルを分析してみます。
| rex field=_raw "^(?:[^,]+,){2}(?P<subject>.+)"
| top limit=50 subject

メールタイトルの傾向より、似たような文言が使われているタイトルが多いので、括弧記号やコロン:を区切り文字としてタイトルを区切ってみます。
index=idx_gmail
| rex field=_raw "^(?:[^,]+,){2}(?P<subject>.+)"
| rex field=subject max_match=100 "(?P<word>(【[^】]+】|.+(-\s)|『[^』]+』|「[^」]+」|[^\【\「\[\((:]+|\([^\)]+\)|([^)]+)|\[[^\]]+\]))"
| mvexpand word
| eval word=trim(word)
| where NOT (word="" OR
word LIKE "【%" OR
word LIKE "『%"
word LIKE "「%" OR
word LIKE "(%" OR
word LIKE "[%" OR
word LIKE "(%" OR
)
| stats count by word
| sort - count
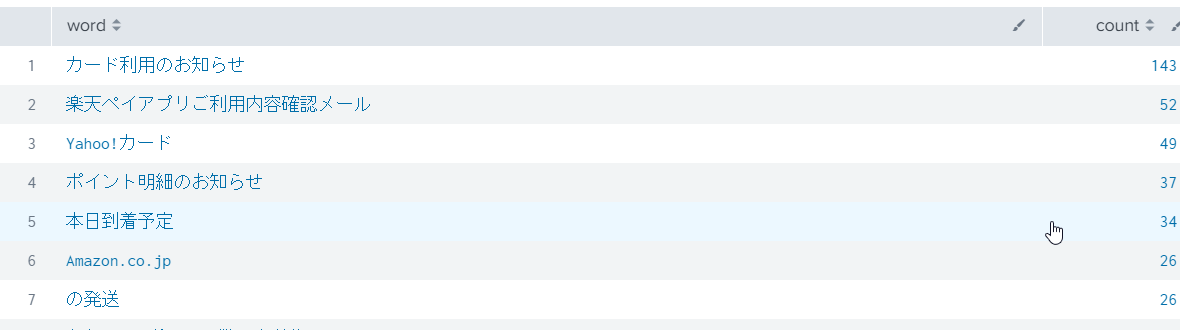
ある程度はうまく区切れましたが、癖があるタイトルはうまく区切れなかったりするようです。

形態素解析してみる
先ほどの分析例でメールタイトルをある程度の単語に区切ることができましたが、今度は本格的に形態素解析を行ってみます。
Splunk自体に形態素解析機能はないのですが、代わりにカスタムコマンドと呼ばれる外部連携機能を使って形態素解析ライブラリと連携してみます。今回はMecabを使って形態素解析をしてみます。
Mecabを呼び出すカスタムコマンドの実装については以下のサイトを参考にさせていただきました。ありがとうございます。
Splunk で MeCab を使った形態素解析をする
index=idx_gmail
| rex field=_raw "^(?:[^,]+,){2}(?P<text>.+)"
| run mecab
| makemv mecab
| mvexpand mecab
| eval len=len(mecab),isnum=if(isnum(mecab),1,0)
| search len>1 AND isnum=0
| stats count by mecab
| sort - count
サーチ結果を表形式で表示してみます。

おわりに
今回メールのログではなくメールそのものをSplunkに取り込んで分析してみましたが、ログでなくとも色んな観点で分析することができました。
Splunkはログに限らず、テキストデータであれば何でも取り込めるのが強みだと思います。
また、取り込むデータから何を情報/キーワードとして抽出するかを事前に定義(設計)する必要もありません。このあたりがデータベースなどとの違いであり、Splunkのメリットだと思います。
Splunkで何をしたらいいかわからない・・・という方も、まずはデータを取り込んでみて、それから色々サーチしてみてはいかがでしょうか。課題解決につながるような原因や、まったく気づかなかった傾向や相関がみえてくるかもしれません。
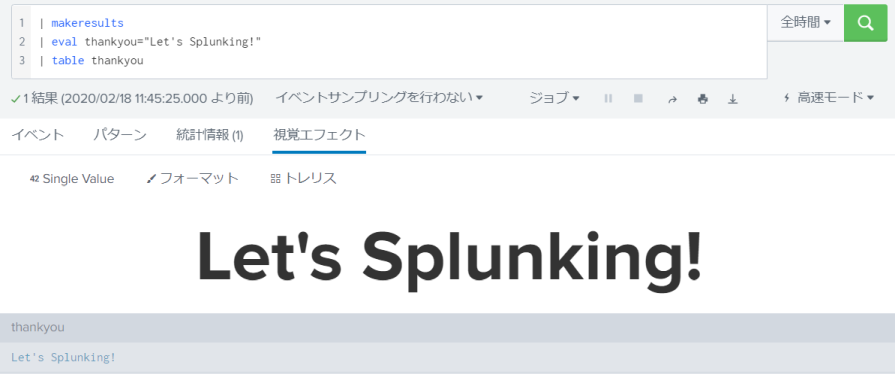
| makeresults
| eval thankyou="Let's Splunking!"
| table thankyou
ここまで読んでいただき、ありがとうございました。