0.はじめに
本記事は、Study-AIが提供するラビット・チャレンジ(JDLA認定プログラム)のレポート記事である。今回は深層学習(day3&day4)に関するレポートを記述する。
参考文献
・ディープラーニングG検定公式テキスト、JDLA、翔泳社
・PyTorchによる物体検出、新納浩幸、オーム社
・PyTorchによる発展ディープラーニング、小川雄太郎、マイナビ
1.再帰型ニューラルネットワークの概念
概要
再帰型ニューラルネットワーク(Recurrent Neural Network:RNN)とは、時系列データの扱いを得意とするニューラルネットワークである。
時系列データとは時間的順序を追って一定間隔ごとに観察され、しかも相互に統計的依存関係が認められるデータ系列のことであり、音声データやテキスト(自然言語)データがある。
RNNは時系列データを扱うため、初期の状態と過去の時間$t−1$の状態を保持し、次の時間$t$の状態を求める再帰的構造が必要になる。それを実現しているのが$\boldsymbol{z}$にあるループ構造である。下図は左がシンプルに構造を表したものであり、右が展開したものになっている。右側の数字が時刻$t$を表している。
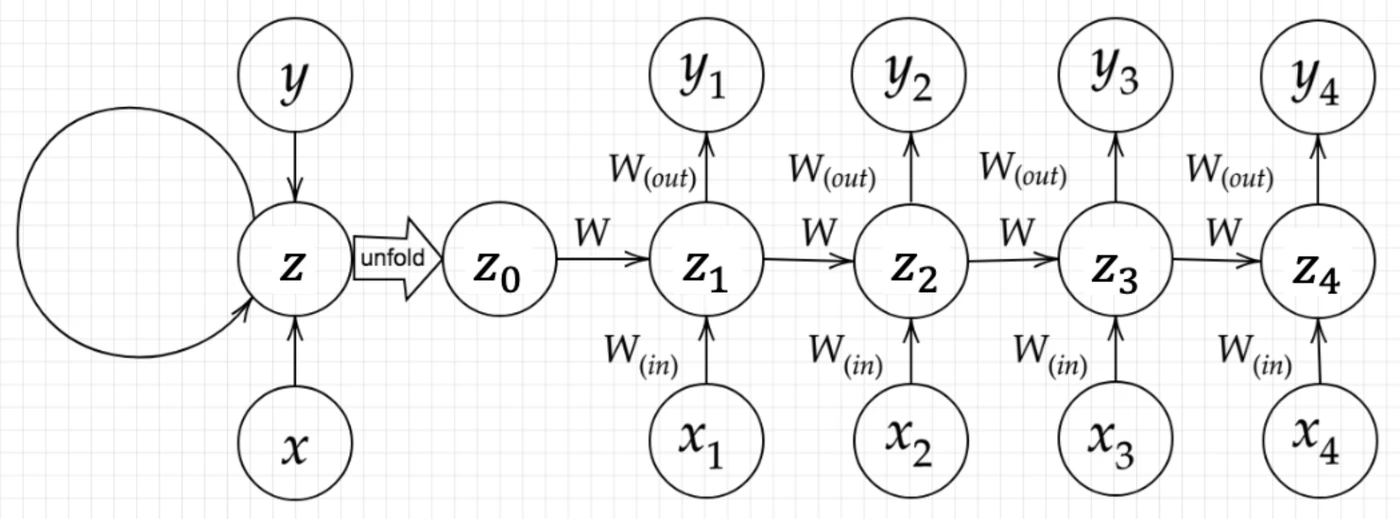
順伝播
順伝播を式で表すと次式となる。
\begin{align}
\boldsymbol{u}^t=&\boldsymbol{W}_{(in)}x^t+\boldsymbol{W}z^{t-1}+b\\
\boldsymbol{z}^t=&f(\boldsymbol{u}^t)=f\left(\boldsymbol{W}_{(in)}x^t+\boldsymbol{W}z^{t-1}+b\right)\\
\boldsymbol{v}^t=&\boldsymbol{W}_{(out)}\boldsymbol{z}^t+c\\
\boldsymbol{y}^t=&g(\boldsymbol{v}^t)=g\left(\boldsymbol{W}_{(out)}\boldsymbol{z}^t+c\right)
\end{align}
ここで、$b$、$c$はバイアス、$f(x)$、$g(x)$は活性化関数を表す。
逆伝播
RNNにおいて更新する必要があるパラメータは、$\boldsymbol{W}$系3つと、バイアス2つである。下記でそれぞれの微分値を示す。
\begin{align}
\frac{\partial E}{\partial \boldsymbol{W}_{(in)}}&=\frac{\partial E}{\partial \boldsymbol{u}^t}\left[\frac{\partial \boldsymbol{u}^t}{\partial \boldsymbol{W}_{(in)}}\right]^T=\delta^t[x^t]^T\\
\frac{\partial E}{\partial \boldsymbol{W}_{(out)}}&=\frac{\partial E}{\partial \boldsymbol{v}^t}\left[\frac{\partial \boldsymbol{v}^t}{\partial \boldsymbol{W}_{(out)}}\right]^T=\delta^{out, t}[z^t]^T\\
\frac{\partial E}{\partial \boldsymbol{W}}&=\frac{\partial E}{\partial \boldsymbol{u}^t}\left[\frac{\partial \boldsymbol{u}^t}{\partial \boldsymbol{W}}\right]^T=\delta^t[z^{t-1}]^T\\
\frac{\partial E}{\partial \boldsymbol{b}}&=\frac{\partial E}{\partial \boldsymbol{u}^t}\frac{\partial \boldsymbol{u}^t}{\partial \boldsymbol{b}}=\delta^t\\
\frac{\partial E}{\partial \boldsymbol{c}}&=\frac{\partial E}{\partial \boldsymbol{v}^t}\frac{\partial \boldsymbol{v}^t}{\partial \boldsymbol{c}}=\delta^{out,t}
\end{align}
RNNの更新は、上記のようにして得ることができた。
実装演習
下記に、バイナリの加法を学んでくれるプログラムをRNNを用いて組んだものを載せる。
import numpy as np
from common import functions
import matplotlib.pyplot as plt
def d_tanh(x):
return 1/(np.cosh(x) ** 2)
# データを用意
# 2進数の桁数
binary_dim = 8
# 最大値 + 1
largest_number = pow(2, binary_dim)
# largest_numberまで2進数を用意
binary = np.unpackbits(np.array([range(largest_number)],dtype=np.uint8).T,axis=1)
input_layer_size = 2
hidden_layer_size = 16
output_layer_size = 1
weight_init_std = 1
learning_rate = 0.1
iters_num = 10000
plot_interval = 100
# ウェイト初期化 (バイアスは簡単のため省略)
W_in = weight_init_std * np.random.randn(input_layer_size, hidden_layer_size)
W_out = weight_init_std * np.random.randn(hidden_layer_size, output_layer_size)
W = weight_init_std * np.random.randn(hidden_layer_size, hidden_layer_size)
# Xavier
# W_in = np.random.randn(input_layer_size, hidden_layer_size) / (np.sqrt(input_layer_size))
# W_out = np.random.randn(hidden_layer_size, output_layer_size) / (np.sqrt(hidden_layer_size))
# W = np.random.randn(hidden_layer_size, hidden_layer_size) / (np.sqrt(hidden_layer_size))
# He
# W_in = np.random.randn(input_layer_size, hidden_layer_size) / (np.sqrt(input_layer_size)) * np.sqrt(2)
# W_out = np.random.randn(hidden_layer_size, output_layer_size) / (np.sqrt(hidden_layer_size)) * np.sqrt(2)
# W = np.random.randn(hidden_layer_size, hidden_layer_size) / (np.sqrt(hidden_layer_size)) * np.sqrt(2)
# 勾配
W_in_grad = np.zeros_like(W_in)
W_out_grad = np.zeros_like(W_out)
W_grad = np.zeros_like(W)
u = np.zeros((hidden_layer_size, binary_dim + 1))
z = np.zeros((hidden_layer_size, binary_dim + 1))
y = np.zeros((output_layer_size, binary_dim))
delta_out = np.zeros((output_layer_size, binary_dim))
delta = np.zeros((hidden_layer_size, binary_dim + 1))
all_losses = []
for i in range(iters_num):
# A, B初期化 (a + b = d)
a_int = np.random.randint(largest_number/2)
a_bin = binary[a_int] # binary encoding
b_int = np.random.randint(largest_number/2)
b_bin = binary[b_int] # binary encoding
# 正解データ
d_int = a_int + b_int
d_bin = binary[d_int]
# 出力バイナリ
out_bin = np.zeros_like(d_bin)
# 時系列全体の誤差
all_loss = 0
# 時系列ループ
for t in range(binary_dim):
# 入力値
X = np.array([a_bin[ - t - 1], b_bin[ - t - 1]]).reshape(1, -1)
# 時刻tにおける正解データ
dd = np.array([d_bin[binary_dim - t - 1]])
u[:,t+1] = np.dot(X, W_in) + np.dot(z[:,t].reshape(1, -1), W)
z[:,t+1] = functions.sigmoid(u[:,t+1])
# z[:,t+1] = functions.relu(u[:,t+1])
# z[:,t+1] = np.tanh(u[:,t+1])
y[:,t] = functions.sigmoid(np.dot(z[:,t+1].reshape(1, -1), W_out))
#誤差
loss = functions.mean_squared_error(dd, y[:,t])
delta_out[:,t] = functions.d_mean_squared_error(dd, y[:,t]) * functions.d_sigmoid(y[:,t])
all_loss += loss
out_bin[binary_dim - t - 1] = np.round(y[:,t])
for t in range(binary_dim)[::-1]:
X = np.array([a_bin[-t-1],b_bin[-t-1]]).reshape(1, -1)
delta[:,t] = (np.dot(delta[:,t+1].T, W.T) + np.dot(delta_out[:,t].T, W_out.T)) * functions.d_sigmoid(u[:,t+1])
# delta[:,t] = (np.dot(delta[:,t+1].T, W.T) + np.dot(delta_out[:,t].T, W_out.T)) * functions.d_relu(u[:,t+1])
# delta[:,t] = (np.dot(delta[:,t+1].T, W.T) + np.dot(delta_out[:,t].T, W_out.T)) * d_tanh(u[:,t+1])
# 勾配更新
W_out_grad += np.dot(z[:,t+1].reshape(-1,1), delta_out[:,t].reshape(-1,1))
W_grad += np.dot(z[:,t].reshape(-1,1), delta[:,t].reshape(1,-1))
W_in_grad += np.dot(X.T, delta[:,t].reshape(1,-1))
# 勾配適用
W_in -= learning_rate * W_in_grad
W_out -= learning_rate * W_out_grad
W -= learning_rate * W_grad
W_in_grad *= 0
W_out_grad *= 0
W_grad *= 0
if(i % plot_interval == 0):
all_losses.append(all_loss)
print("iters:" + str(i))
print("Loss:" + str(all_loss))
print("Pred:" + str(out_bin))
print("True:" + str(d_bin))
out_int = 0
for index,x in enumerate(reversed(out_bin)):
out_int += x * pow(2, index)
print(str(a_int) + " + " + str(b_int) + " = " + str(out_int))
print("------------")
lists = range(0, iters_num, plot_interval)
plt.plot(lists, all_losses, label="loss")
plt.show()
結果は下記のようになった。最初は全く足し算をすることができていなかったが、
徐々に正解が増えていき、最後にはしっかりと足し算を実行できるようになっていた。

全体を通して正解率の推移を見ると、下記のようになる。
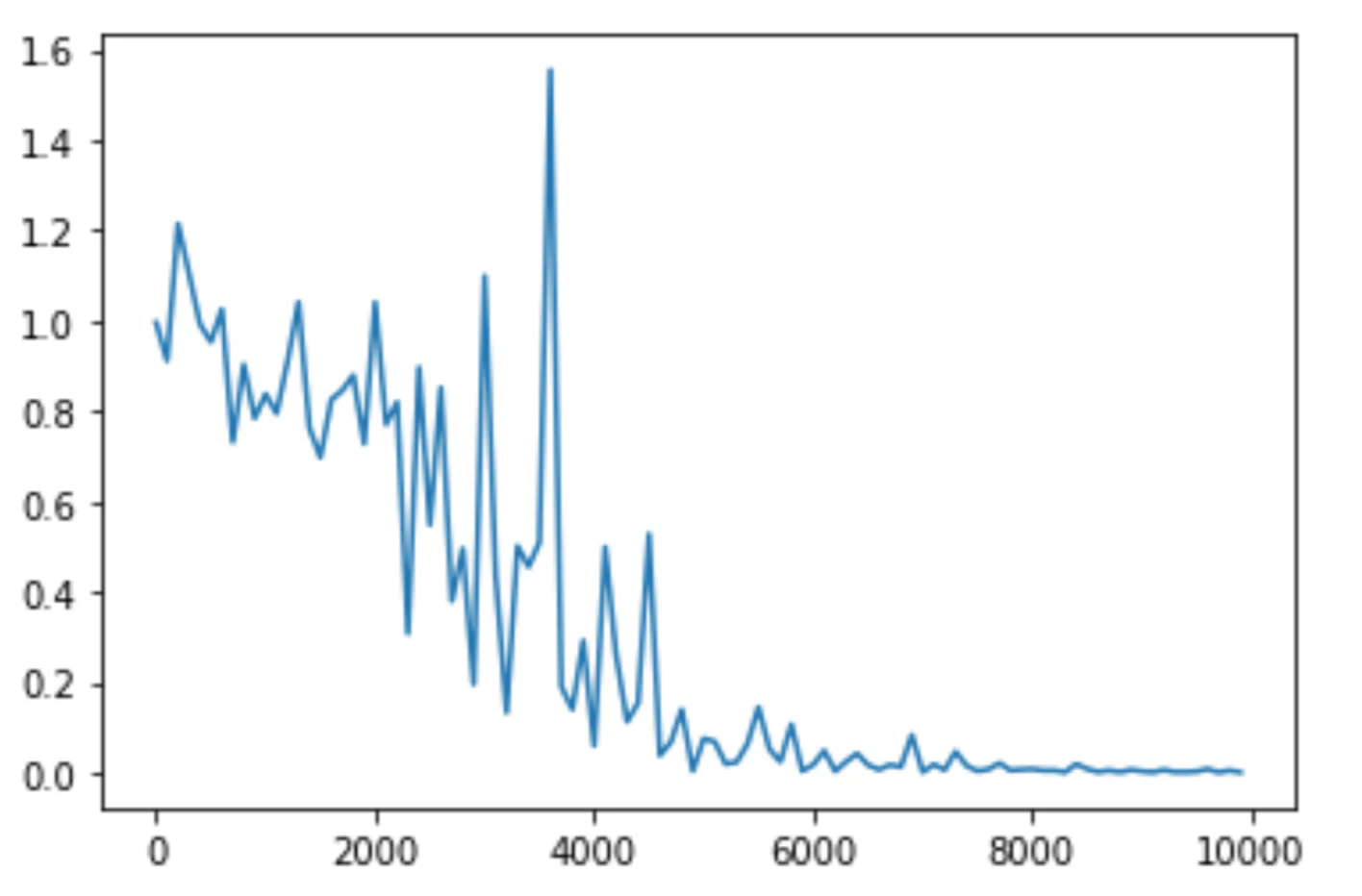
途中正解率が急激に悪くなる時もあったが、全体の傾向的には減少傾向にあり、最終的にはしっかり計算できている。
確認テスト
Q1. RNNネットワークには大きく分けて3つの重みがある。1つは入力から現在の中間層を定義する際にかけられる重み、1つは中間層から出力を定義する際にかけられる重みである。残りひとつの重みについて説明せよ。
A1. 中間層($t-1$)から中間層($t$)への重み
Q2. 連鎖律の原理を使い、下記の$dz/dx$を求めよ。
\begin{align}
z=t^2\\
t=x+y
\end{align}
A2.
$$\frac{dx}{dx}=\frac{dx}{dt}\frac{dt}{dx}=2t\times1=2(x+y)$$
Q3. 下図の$y_1$を、$x$、$z_0$、$z_1$、$w_i$、$w_o$を用いて数式で表せ。ただし、バイアスは$b$とし、活性化関数は$g(x)$とする。
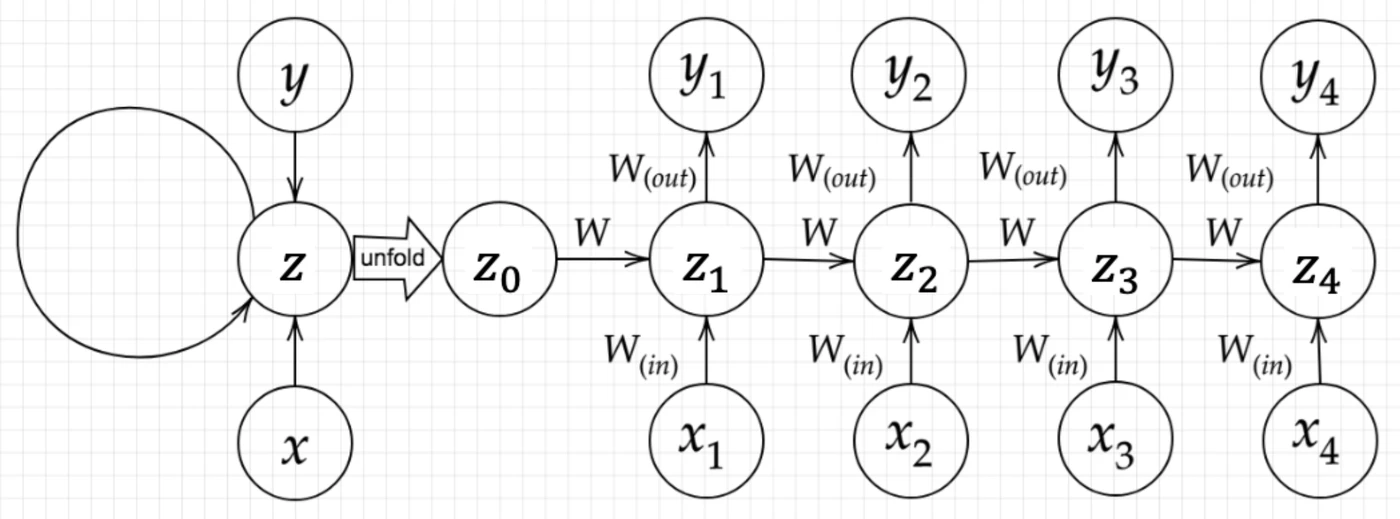
A3.
\begin{align}
y_1=g\{W_{out}(x_1 W_{in}+z_0 W+b)\}
\end{align}
Q4. シグモイド関数を微分した時、入力値が0の時に最大値を取る。その値を答えよ。
A4. 1/4
2. LSTM
概要
LSTM(Long short-term memory)は、RNN(Recurrent Neural Network)の拡張として1995年に登場した、時系列データ(sequential data)に対するモデル、あるいは構造(architecture)の1種である。その名は、Long term memory(長期記憶)とShort term memory(短期記憶)という神経科学における用語から取られている。LSTMはRNNの中間層のユニットをLSTM blockと呼ばれるメモリと3つのゲートを持つブロックに置き換えることで実現されている。
入力/出力ゲート
入力ゲートと出力ゲートを追加し、それぞれのゲートへの入力値の重みを重み行列W、Uで可変可能とすることにより、CECの課題を解決。
\begin{align}
i=\sigma(\boldsymbol{W}_ih_{t-1}+\boldsymbol{U}_ix_t)\\
o=\sigma(\boldsymbol{W}_oh_{t-1}+\boldsymbol{U}_ox_t)
\end{align}
忘却ゲート
CECは過去の情報がすべて保管されているが、過去の情報が不要になった場合、削除することはできず保管され続ける。
そこで、過去の情報が不要になった場合、そのタイミングで情報を忘却する機能として、忘却ゲートが誕生した。
\begin{align}
f=\sigma(\boldsymbol{W}_fh_{t-1}+\boldsymbol{U}_fx_t)
\end{align}
メモリセル
\begin{align}
g=tanh(\boldsymbol{W}_gh_{t-1}+\boldsymbol{U}_gx_t)\\
c_t=(c_{t-1}\otimes f)\oplus(g\otimes i)
\end{align}
出力
\begin{align}
h_t=tahn(c_t)\otimes o
\end{align}
実装演習
def lstm(x, prev_h, prev_c, W, U, b):
# セルへの入力やゲートをまとめて計算し、分割
lstm_in = _activation(x.dot(W.T)) + prev_h.dot(U.T) + b)
a, i, f, o = np.hsplit(lstm_in, 4)
# 値を変換、セルへの入力:(-1, 1)、ゲート:(0, 1)
a = np.tanh(a)
input_gate = _sigmoid(i)
forget_gate = _sigmoid(f)
output_gate = _sigmoid(o)
# セルの状態を更新し、中間層の出力を計算
c = input_gate * a + forget_gate * c
h = output_gate * np.tanh(c)
return c, h
確認テスト
Q1. 以下の文章をLSTMに入力し空欄に当てはまる単語を予測したいとする。文中の「とても」という言葉は空欄の予測において無くなっても影響を及ぼさないと考えられる。このような場合、どのゲートが作用すると考えられるか?
「映画面白かったね。ところで、とてもお腹が空いたから何か〇〇〇〇。」
A1. 忘却ゲート
Q2. LSTMとCECが抱える問題について、それぞれ簡潔に述べよ。
A2. LSTMは入力、出力、忘却ゲート、CECの4つのゲートを持ち、パラメータが多くなってしまうこと。複雑で計算量が多くなってしまうこと。CECは、学習機能がなく、周りに学習能力があるゲート(入力、出力、忘却ゲート)が必要であること。
3. GRU
概要
従来のLSTMでは、パラメータが多数存在していたため、計算付加が大きかった。そこで、GRUではそのパラメータを大幅に削減し、精度は同等またはそれ以上が望めるようになった構造をしている。
- Update gate: $z_t=\sigma(\boldsymbol{W}^{(z)}x_t+\boldsymbol{U}^{(z)}h_{t-1})$
- Reset gate: $r_t=\sigma(\boldsymbol{W}^{(r)}x_t+\boldsymbol{U}^{(r)}h_{t-1})$
- State refresh: Reset gateの値が0の場合、前の状態を無視。Update gateの値が1の場合、前の状態をそのままコピーする。
実装演習
from common.np import * # import numpy as np (or import cupy as np)
from common.layers import *
from common.functions import softmax, sigmoid
class GRU:
def __init__(self, Wx, Wh, b):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)] ###
self.cache = None
def forward(self, x, h_prev):
Wx, Wh, b = self.params
H = Wh.shape[0]
Wxz, Wxr, Wxh = Wx[:, :H], Wx[:, H:2 * H], Wx[:, 2 * H:]
Whz, Whr, Whh = Wh[:, :H], Wh[:, H:2 * H], Wh[:, 2 * H:]
bz, br, bh = b[:H], b[H:2 * H], b[2 * H:]
z = sigmoid(np.dot(x, Wxz) + np.dot(h_prev, Whz) + bz)
r = sigmoid(np.dot(x, Wxr) + np.dot(h_prev, Whr) + br)
h_hat = np.tanh(np.dot(x, Wxh) + np.dot(r*h_prev, Whh) + bh)
h_next = (1-z) * h_prev + z * h_hat
self.cache = (x, h_prev, z, r, h_hat)
return h_next
def backward(self, dh_next):
Wx, Wh, b = self.params
H = Wh.shape[0]
Wxz, Wxr, Wxh = Wx[:, :H], Wx[:, H:2 * H], Wx[:, 2 * H:]
Whz, Whr, Whh = Wh[:, :H], Wh[:, H:2 * H], Wh[:, 2 * H:]
x, h_prev, z, r, h_hat = self.cache
確認テスト
Q1. LSTMとGRUの違いを簡潔に述べよ。
A1. LSTMは入力、出力、忘却ゲート、CECがある。GRUは更新ゲートとリセットゲートのみであり、パラメータ量(計算量)も小さい。
4. 双方向RNN
概要
双方向RNN(Bidirectional RNN)は、系列の最初のステップから繰り返して順方向に予想することに加えて、系列の最後のステップからの逆方向の予測も行う、RNNを双方向形に拡張したモデルである。
双方向RNNも,毎フレーム$t$において観測$\boldsymbol{x}_t$を入力して潜在変数をもとに出力$\boldsymbol{o}_t$を予測するところは通常の(単方向の)RNNと同じである一方で異なるのは、潜在変数が順方向$\boldsymbol{h}_t^{\to}$と逆方向の$\boldsymbol{h}_t^{\leftarrow}$の2種類使用される点であり、これにより双方向のコンテキストを集約しての出力の予測が可能となる。もう少し正確に言うと、順方向側はステップ1からステップ$t-1$までのコンテキストを知っており、逆方向側はステップ2からステップ$t+1$までのコンテキストを「双方向」とも学習を通じて予測できるようになる。
実装演習
def BiRNN(u, h_0, Wx, Wh, b, propagation_func=tanh, merge="concat"):
# データ設定(逆方向は、時刻を反転)
u_dr = {}
u_dr["f"] = u
u_dr["r"] = u[:, ::-1]
# 初期化
h_n, hs = {}, {}
# 順方向
h_n["f"], hs["f"] = RNN(u_dr["f"], h_0["f"], Wx["f"], Wh["f"], b["f"], propagation_func)
# 逆方向
h_n["r"], hs["r"] = RNN(u_dr["r"], h_0["r"], Wx["r"], Wh["r"], b["r"], propagation_func)
# h_n - (n, h)
# hs - (n, t, h)
if merge == "concat":
# 結合
h_n_merge = np.concatenate([h_n["f"], h_n["r"]], axis=1)
hs_merge = np.concatenate([hs["f"], hs["r"][:, ::-1]], axis=2)
elif merge == "sum":
# 合計
h_n_merge = h_n["f"] + h_n["r"]
hs_merge = hs["f"] + hs["r"][:, ::-1]
return h_n_merge, hs_merge, h_n, hs
def BiRNN_back(dh_n_merge, dhs_merge, u, hs, h_0, Wx, Wh, b, propagation_func=tanh, merge="concat"):
# データ設定(逆方向は、時刻を反転)
u_dr = {}
u_dr["f"] = u
u_dr["r"] = u[:, ::-1]
h = Wh["f"].shape[0]
# dh_n - (n, h*2)(concatの場合)、(n, h)(sumの場合)
# dhs - (n, t, h)
dh_n, dhs = {}, {}
if merge == "concat":
# 結合
dh_n["f"] = dh_n_merge[:, :h]
dh_n["r"] = dh_n_merge[:, h:]
dhs["f"] = dhs_merge[:, :, :h]
dhs["r"] = dhs_merge[:, :, h:][:, ::-1]
elif merge == "sum":
# 合計
dh_n["f"] = dh_n_merge
dh_n["r"] = dh_n_merge
dhs["f"] = dhs_merge
dhs["r"] = dhs_merge[:, ::-1]
# 初期化
du = {}
dWx, dWh, db = {}, {}, {}
dh_0 = {}
# 順方向
du["f"], dWx["f"], dWh["f"], db["f"], dh_0["f"] = RNN_back(dh_n["f"], dhs["f"], u_dr["f"], hs["f"], h_0["f"], Wx["f"], Wh["f"], b["f"], propagation_func)
# 逆方向
du["r"], dWx["r"], dWh["r"], db["r"], dh_0["r"] = RNN_back(dh_n["r"], dhs["r"], u_dr["r"], hs["r"], h_0["r"], Wx["r"], Wh["r"], b["r"], propagation_func)
# du - (n, t, d)
du_merge = du["f"] + du["r"][:, ::-1]
return du_merge, dWx, dWh, db, dh_0
5. Seq2Seq
概要
Seq2Seqとは、あるシーケンス(たとえば英語の文章)を受け取り、別のシーケンス(たとえば日本語の文章)に変換するモデルである。例えば、以下のように英文を日本語に変換(翻訳)するようなタスクで利用することができる。
What's you name? --> あなたの名前は何ですか?
Seq2Seqは、翻訳以外にも以下のようなタスクで活用することができる。
・文章の要約(長文の文章を要約する)
・対話の生成(ある対話文章に対する応答を自動的に生成する)
仕組みの詳細
Seq2Seqでは通常RNN層(今回はLSTMを利用)を利用する。また、入力を圧縮するencoderと出力を展開するdecoderからなるニューラルネットワークモデルを定義する。
Encoder
Encoderには各時刻ごとに時系列データ(文章など)が入力される。EncoderのRNNレイヤ(上図ではLSTM)では、入力シーケンスを処理した結果として内部状態を返す。EncoderのRNNの出力結果は破棄し、内部状態だけをDecoder側で利用する。
Decoder
Decoderでは、ターゲットとなるシーケンスの前の文字が与えられた場合、ターゲットシーケンスの次の文字を予測するように訓練する。訓練では、Decoderへの入力を対話文における返答としてあらかじめ用意する。ある時刻におけるDecoderの出力が次の時刻における入力に近づくように学習させる(このことを教師強制と言う)。
実装演習
import random
import torch
import torch.nn as nn
from torch import optim
import torch.nn.functional as F
SOS_token = 0
EOS_token = 1
device = "cuda" # torch.device("cuda" if torch.cuda.is_available() else "cpu")
class Lang:
def __init__( self, filename ):
self.filename = filename
self.word2index = {}
self.word2count = {}
self.sentences = []
self.index2word = { 0: "SOS", 1: "EOS" }
self.n_words = 2 # Count SOS and EOS
with open( self.filename ) as fd:
for i, line in enumerate( fd.readlines() ):
line = line.strip()
self.sentences.append( line )
self.allow_list = [ True ] * len( self.sentences )
self.target_sentences = self.sentences[ :: ]
def get_sentences( self ):
return self.sentences[ :: ]
def get_sentence( self, index ):
return self.sentences[ index ]
def choice( self ):
while True:
index = random.randint( 0, len( self.allow_list ) - 1 )
if self.allow_list[ index ]:
break
return self.sentences[ index ], index
def get_allow_list( self, max_length ):
allow_list = []
for sentence in self.sentences:
if len( sentence.split() ) < max_length:
allow_list.append( True )
else:
allow_list.append( False )
return allow_list
def load_file( self, allow_list = [] ):
if allow_list:
self.allow_list = [x and y for (x,y) in zip( self.allow_list, allow_list ) ]
self.target_sentences = []
for i, sentence in enumerate( self.sentences ):
if self.allow_list[ i ]:
self.addSentence( sentence )
self.target_sentences.append( sentence )
def addSentence( self, sentence ):
for word in sentence.split():
self.addWord(word)
def addWord( self, word ):
if word not in self.word2index:
self.word2index[ word ] = self.n_words
self.word2count[ word ] = 1
self.index2word[ self.n_words ] = word
self.n_words += 1
else:
self.word2count[word] += 1
def tensorFromSentence( lang, sentence ):
indexes = [ lang.word2index[ word ] for word in sentence.split(' ') ]
indexes.append( EOS_token )
return torch.tensor( indexes, dtype=torch.long ).to( device ).view(-1, 1)
def tensorsFromPair( input_lang, output_lang ):
input_sentence, index = input_lang.choice()
output_sentence = output_lang.get_sentence( index )
input_tensor = tensorFromSentence( input_lang, input_sentence )
output_tensor = tensorFromSentence( output_lang, output_sentence )
return (input_tensor, output_tensor)
class Encoder( nn.Module ):
def __init__( self, input_size, embedding_size, hidden_size ):
super().__init__()
self.hidden_size = hidden_size
# 単語をベクトル化する。1単語はembedding_sie次元のベクトルとなる
self.embedding = nn.Embedding( input_size, embedding_size )
# GRUに依る実装.
self.gru = nn.GRU( embedding_size, hidden_size )
def initHidden( self ):
return torch.zeros( 1, 1, self.hidden_size ).to( device )
def forward( self, _input, hidden ):
# 単語のベクトル化
embedded = self.embedding( _input ).view( 1, 1, -1 )
# ベクトル化したデータをGRUに噛ませる。通常のSeq2Seqでは出力outは使われることはない。
# ただしSeq2Seq + Attentionをする場合にはoutの値を使うことになるので、リターンする
out, new_hidden = self.gru( embedded, hidden )
return out, new_hidden
class Decoder( nn.Module ):
def __init__( self, hidden_size, embedding_size, output_size ):
super().__init__()
self.hidden_size = hidden_size
# 単語をベクトル化する。1単語はembedding_sie次元のベクトルとなる
self.embedding = nn.Embedding( output_size, embedding_size )
# GRUによる実装(RNN素子の一種)
self.gru = nn.GRU( embedding_size, hidden_size )
# 全結合して1層のネットワークにする
self.linear = nn.Linear( hidden_size, output_size )
# softmaxのLogバージョン。dim=1で行方向を確率変換する(dim=0で列方向となる)
self.softmax = nn.LogSoftmax( dim = 1 )
def forward( self, _input, hidden ):
# 単語のベクトル化。GRUの入力に合わせ三次元テンソルにして渡す。
embedded = self.embedding( _input ).view( 1, 1, -1 )
# relu活性化関数に突っ込む( 3次元のテンソル)
relu_embedded = F.relu( embedded )
# GRU関数( 入力は3次元のテンソル )
gru_output, hidden = self.gru( relu_embedded, hidden )
# softmax関数の適用。outputは3次元のテンソルなので2次元のテンソルを渡す
result = self.softmax( self.linear( gru_output[ 0 ] ) )
return result, hidden
def initHidden( self ):
return torch.zeros( 1, 1, self.hidden_size ).to( device )
def main():
n_iters = 75000
learning_rate = 0.01 * 0.8
embedding_size = 256
hidden_size = 256
max_length = 30
input_lang = Lang( 'jpn.txt' )
output_lang = Lang( 'eng.txt')
# 英単語数がmax_lengthより多い場合は計算しない。(時間がかかるため。)
allow_list = [x and y for (x,y) in zip( input_lang.get_allow_list( max_length ), output_lang.get_allow_list( max_length ) ) ]
# allow_listに従って、英語、日本語のファイルをロードする
input_lang.load_file( allow_list )
output_lang.load_file( allow_list )
# Encoder & Decoderの定義
encoder = Encoder( input_lang.n_words, embedding_size, hidden_size ).to( device )
decoder = Decoder( hidden_size, embedding_size, output_lang.n_words ).to( device )
# Optimizerの設定
encoder_optimizer = optim.SGD( encoder.parameters(), lr=learning_rate )
decoder_optimizer = optim.SGD( decoder.parameters(), lr=learning_rate )
# 学習用のペアデータの作成. He is a dog, 彼は犬だ みたいなペアをエポック数分用意する
training_pairs = [ tensorsFromPair( input_lang, output_lang ) for i in range( n_iters ) ]
# LOSS関数
criterion = nn.NLLLoss()
for epoch in range( 1, n_iters + 1):
# 学習用のペア単語の取り出し。
input_tensor, output_tensor = training_pairs[ epoch - 1 ]
#初期化
encoder_hidden = encoder.initHidden()
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
input_length = input_tensor.size(0)
output_length = output_tensor.size(0)
# Encoder phese
for i in range( input_length ):
encoder_output, encoder_hidden = encoder( input_tensor[ i ], encoder_hidden )
# Decoder phese
loss = 0
decoder_input = torch.tensor( [ [ SOS_token ] ] ).to( device )
decoder_hidden = encoder_hidden
for i in range( output_length ):
decoder_output, decoder_hidden = decoder( decoder_input, decoder_hidden )
# 次の入力野取り出し
decoder_input = output_tensor[ i ]
# 学習では一定の確率(ここでは50%)で、自身が前に出力した単語を次の入力とする。
if random.random() < 0.5:
# 確率が最も高い単語を抽出
topv, topi = decoder_output.topk( 1 )
# 確率が一番高かった単語を次段の入力とする
decoder_input = topi.squeeze().detach()
# Loss関数
loss += criterion( decoder_output, output_tensor[ i ] )
# EOSに当たった場合は終わる。
if decoder_input.item() == EOS_token: break
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
# 進捗状況の表示
if epoch % 50 == 0:
print( "[epoch num %d (%d)] [ loss: %f]" % ( epoch, n_iters, loss.item() / output_length ) )
確認テスト
Q1. seq2seqについて説明しているものは?
A1. RNNを用いたEncoder-Decoderモデルの一種であり、機械翻訳などのモデルに使われる。
Q2. seq2seqとHRED、HREDとVHREDの違いを簡潔に述べよ。
A2. seq2seqは、一文の一問一答に対して処理できるモデルである。HREDは一問一答ではなく、今までの会話の文脈から答えを導き出せるようにしたモデル。VHREDは、HREDよりもバリエーションのある回答、豊かな回答を道美出せるようにしたモデルである。
6. Word2Vec
概要
分散表現の登場などの進展はあったものの、その処理の難しさや膨大な計算量を理由に、なお実践が難しいままだった自然言語処理。そこに更なる技術的進展をもたらし、自然言語処理を現実のものとしたツールが、当時Googleに在籍していたトマス・ミコロフ氏により提案された「Word2Vec」だった。
Word2Vecの特徴は、2層のニューラルネットワークのみで構成されるシンプルな構造をとっている点にある。この構造のシンプルさにより、大規模データによる分散表現学習が現実的な計算量で可能となり、分散表現での自然言語処理が飛躍的に進む契機となった。
Word2Vecには、skip-gram法(Continuous Skip-Gram Model)とCBOW(Continuous Bag-of-Words Model)のふたつのモデルが内包されている。以下ではそれぞれの手法を解説している。
Skip-Gram法
skip-gram法で行われる学習は教師あり学習である。入力として中心語を与え、その周辺語の予測を出力する。この学習を通じて、ネットワークにある単語の周囲に、どのような単語が現れる可能性が高いのかを学習させる。
CBOW
skip-gram法が中心語から周辺語を予測するのに対し、CBOWは周辺の単語から中心語を予測するという逆の手法をとる。CBOWもskip-gramと同様に、学習手法は教師あり学習である。この場合の入力は周辺語、出力は中心語となる。
実装演習
# 改良版CBOWの実装
class CBOW:
# 初期化メソッドの定義
def __init__(self, vocab_size, hidden_size, window_size, corpus):
V, H = vocab_size, hidden_size
# 重みを初期化
W_in = 0.01 * np.random.randn(V, H).astype('f')
W_out = 0.01 * np.random.randn(V, H).astype('f')
# 入力層を作成
self.in_layers = []
for i in range(2 * window_size):
layer = Embedding(W_in)
self.in_layers.append(layer)
# 出力・損失層を作成
self.ns_loss = NegativeSamplingLoss(W_out, corpus, power=0.75, sample_size=5)
# レイヤをまとめる
layers = self.in_layers + [self.ns_loss]
# 重みと勾配をまとめる
self.params = [] # 重み
self.grads = [] # 勾配
for layer in layers:
self.params += layer.params
self.grads += layer.grads
# 分散表現を保存
self.word_vecs = W_in
# 順伝播メソッドの定義
def forward(self, contexts, target):
# 中間層のニューロンを計算
h = 0
for i, layer in enumerate(self.in_layers):
h += layer.forward(contexts[:, i])
h *= 1 / len(self.in_layers)
# 損失を計算
loss = self.ns_loss.forward(h, target)
return loss
# 逆伝播メソッドの定義
def backward(self, dout=1):
# 出力層の勾配を計算
dout = self.ns_loss.backward(dout)
# 入力層の勾配を計算
dout *= 1 / len(self.in_layers)
for layer in self.in_layers:
layer.backward(dout)
return None
7. Attention Mechanism
概要
seq2seqの問題は、長い文章への対応が難しい。seq2seqでは、2単語でも、100単語でも、固定次元ベクトルの中に入力しなければならない。
そこで、文章が長くなるほどそのシーケンスの内部表現の次元も大きくなっていく仕組みが必要になる。
Attention Mechanismとは、「入力と出力のどの単語が関連しているのか」の関連度を学習する仕組みである。
実装演習
class SimpleAttention(tf.keras.models.Model):
'''
Attention の説明をするための、 Multi-head ではない単純な Attention です
'''
def __init__(self, depth: int, *args, **kwargs):
'''
コンストラクタです。
:param depth: 隠れ層及び出力の次元
'''
super().__init__(*args, **kwargs)
self.depth = depth
self.q_dense_layer = tf.keras.layers.Dense(depth, use_bias=False, name='q_dense_layer')
self.k_dense_layer = tf.keras.layers.Dense(depth, use_bias=False, name='k_dense_layer')
self.v_dense_layer = tf.keras.layers.Dense(depth, use_bias=False, name='v_dense_layer')
self.output_dense_layer = tf.keras.layers.Dense(depth, use_bias=False, name='output_dense_layer')
def call(self, input: tf.Tensor, memory: tf.Tensor) -> tf.Tensor:
'''
モデルの実行を行います。
:param input: query のテンソル
:param memory: query に情報を与える memory のテンソル
'''
q = self.q_dense_layer(input) # [batch_size, q_length, depth]
k = self.k_dense_layer(memory) # [batch_size, m_length, depth]
v = self.v_dense_layer(memory)
# ここで q と k の内積を取ることで、query と key の関連度のようなものを計算します。
logit = tf.matmul(q, k, transpose_b=True) # [batch_size, q_length, k_length]
# softmax を取ることで正規化します
attention_weight = tf.nn.softmax(logit, name='attention_weight')
# 重みに従って value から情報を引いてきます
attention_output = tf.matmul(attention_weight, v) # [batch_size, q_length, depth]
return self.output_dense_layer(attention_output)
確認テスト
Q1. RNNとWord2Vec、seq2seqとAttentionの違いを簡潔に述べよ。
A1. RNNは時系列データを処理するのに適したニューラルネットワークのこと。word2vecは単語の分散表現ベクトルを得る手法。seq2seqは、ある1つの時系列データから別の時系列データを得る手法。attentionは時系列データの中身に対して重要度などの重みをつける手法。
8. 強化学習
概要
強化学習とは、長期的に報酬を最大化できるように環境の中で行動を選択できるエージェントを作ることを目標とする機械学習の一分野のことである。行動の結果として与えられる報酬を元に、行動を決定する原理を改善、学習していく仕組みである。
下記でいくつかの語句を説明する。
価値関数
価値を表す関数としては、状態価値関数と行動価値関数の二種類がある。
状態価値関数:ある状態の価値に注目する場合
行動価値関数:状態と価値を組み合わせた価値に注目する場合
方策関数
方策ベースの強化学習手法において、ある状態でどのような行動をとるのかの確立を与える関数のこと。この方策を最大化するように学習を行う。
Q学習
行動価値関数を行動するごとに更新することにより学習を進める方法である。
9. AlphaGo
概要
AlphaGo Lee
PolicyNetにて、エージェントがどこに打つかを決定するモデル($19\times19$の出力)。その際、ValueNet(1次元の出力)からこのまま勝てるか勝てないか、勝率を$-1\sim1$で表したものを参考にしながら予測していく。このAlphaGoには、様々な機械学習の手法が使われている。
・PolicyNetの教師あり学習
・PolicyNetの強化学習
・ValueNetの学習
・RollOutの教師あり学習:NNではなく線形の方策関数を用いた(計算速度を向上させるため)。探索中に高速に着手確率を出すために使用される
・モンテカルロ木探索
AlphaGo Zero
教師あり学習を一切なくし、最低限のルールのみを与えて、あとは報酬が最大になるようにゼロから学習させたモデルである。AlphaGo Zeroは3日でAlphaGo Leeの強さを超えた。人間の経験則を教えないで学ばせた方が、未知の手が生み出されて良いことを示唆している。
AlphaGo Leeと比較したAlphaGo Zeroの特徴
・教師あり学習を一切行わず、強化学習のみで作成した
・特徴入力からヒューリスティックな要素を排除し、石の配置のみにした
・PolicyNetとValueNetを1つのネットワークに統合した
・Residual Netを導入した(途中でショートカットするルートと、順に進むルートを分岐させている)
・モンテカルロ木探索からRollOutシミュレーションをなくした
10. 軽量化・高速化技術
軽量化や高速化が重要視されている背景は、深層学習が多くのデータ・パラメータ調整のために多くの時間を使用するため、高速な計算が求められている背景がある。それを解決する手法を紹介する。
高速化の概要
分散深層学習
複数の計算資源を使用し、並列的にニューラルネットを構成することで、効率の良い学習を行える。データ並列化、モデル並列化、GPUによる高速技術が不可欠である。
データ並列
親モデルを各計算資源に子モデルとしてコピーする。データを分割し、各計算資源にそれぞれ計算させ、最終的にデータをマージする手法。同期型と非同期型がある。
・処理スピードは随時計算できる非同期型の方が早い。
・非同期型は最新モデルのパラメータを利用できないので、学習が不安定になりやすい。同期型の方が精度が良くなる。
モデル並列化
親モデルを分割し各計算資源に分割し、それぞれのモデルを学習させる。全てのデータで学習が終わった後で一つのモデルに復元する手法。データ並列化は1台のPCでGPUを用いて学習させることが多い(誤差関数を求めるために出力をマージする必要があるため、同じPC内の方が効率が良い)。また、モデルのパラメータ数が多いほど、スピードアップの効率も向上する。
GPUによる高速化の開発環境
・CUDA
GPU上で並列コンピューティングを行うためのプラットフォーム。DeepLearningように提供されている。
・OpenCL
オープンな並列コンピューティングのプラットフォーム。
軽量化の概要
量子化
通常のパラメータの64bit浮動小数店を32bitなどの下位の精度に落とすことでメモリと演算処理の削減を行う手法。あまり精度を落としすぎると、計算結果が悪くなってしまうと思うが、16bitの精度でも多くの場合ではまともな計算結果が返ってくることが知られている(経験則)。
蒸留
規模の大きな既知のモデルの知識を使い、そのノウハウを軽量なモデルへ継承させる手法。
・教師モデル
予測精度の高い、複雑なモデルやアンサンブルされたモデル。
・生徒モデル
教師モデルを元に作られる軽量なモデル
プルーニング
ネットワークが大きくなると大量のパラメータの全てのニューロンが計算精度に寄与しているわけではない。そのため、役に立っていないニューロンを消すことにより、高速・軽量化をすることがでる。ニューロンの消し方は、重みが閾値以下のニューロンを選択して削除、などがある。
11. 応用モデル
概要
E資格ではモデルの特徴を問われる問題が多い。そのため、シラバスを見て書いてあるモデルの特徴をつかむのが重要である。下記でいくつかのモデルを紹介する。
MobileNet
画像認識モデルで、高速化・軽量化が適用されたもの。畳み込みの演算方法を工夫している。通常の畳み込みの計算量は$O(H\times W\times K\times K\times C\times M)$だが、
・Depthwise combolutionでは、フィルタを2次元にすることで計算量の削減を実現する($O(H\times W\times K\times K\times C)$)入力のチャネル数と出力のチャネル数が一致するのが特徴。
・Pointwise convolutionでは、フィルタのサイズを$1\times1$にすることで、計算量が$O(H\times W\times M\times C)$となる。
DenseNet
画像認識のモデルである。特徴はDense Blockという部分があるのが特徴である。このブロックを通るたびに、画像のチャネルがどんどん増えていく。具体的には、前スライドで計算した出力に入力特徴マップを足し合わせる。チャネル数が増えすぎても困るので、畳み込み層とプーリング層でチャネル数を減らす動作を行う。
※ResNetと似ているが、DenseNetではジャンプが複数の出力先に足されるのに対し、ResNetではジャンプもととジャンプ先が1対1になっている。
Batch Norm
レイヤー間を流れるデータの分布を、ミニバッチ単位で平均0、分散1になるように正規化する手法。Batch Normalizationはニューラルネットワークにおいて学習時間の短縮や初期値への依存低減、過学習の抑制などの効果がある。問題点として、Batch sizeが小さい条件下では、学習が収束しないことがあり、代わりにLayerNormなどの正規化手法が使われることが多い。
Layer Norm
BatchNormとLayerNormでは、正規化の仕方が違っている。BatchNormは複数の同チャネルごとに正規化するが、LayerNormでは画像ごとに正規化を行う。入力データのスケールや、重み行列のスケール・シフトに対してロバストになることが知られている。
Instance Norm
Instance Normは一画像の一チャネルごとに正規化する手法。
WaveNet
音声波形を生成する深層学習モデルである。この手法では、時系列データに対して畳み込みを適用する。
12. Transformer
概要
Attentionを利用することでより精度が高まった一方で、以前としてRNNなどを併用することで生じている問題は解決されないままだった。理由は時系列を逐次的に処理するため、データを並列処理できず、計算の高速化が困難であったからである。高速化を目指した過程でAttention付きCNNも考案されたが、長文の依存関係モデルを構築することが難しいという問題が生じ、結局抜本的な解決には至らなかった。
それらの問題を乗り越えたのがTransformerである。RNNやCNNなどを利用することを一切やめ、完全にAttention層だけを用いて構築することで、TransformerはRNNやAttention付きSeq2seqなどが抱えていた「高速化できない」という問題や「精度の高い依存関係モデルを構築できない」という問題を解決することに成功した。
特徴
①RNNやCNNを使わずAttention層のみで構築されていること
Self-Attention層とTarget-Source‐Attention層のみで構築することにより、RNNを併用する場合と比べて、並列計算が可能になり計算が高速化された。CNNを併用する場合と比べて、長文の為の深いモデル構築が不要となった。
②PositionalEncoding層を採用している
RNNなどを利用しないことで失われてしまうはずの文脈情報を、入力する単語データに「文全体における単語の位置情報」を埋め込むことで保持することに成功した。
③Attention層におけるQuery-Key-Valueモデルを採用している
初期のAttentionにおける単純なSource-Target型から改良され、より単語同士の照応関係(アライメントという)を正確に反映することができるようになったことで精度が改善された。
13. 物体検知・セグメンテーション
概要
R-CNN
位置検出と物体判別(合わせて物体検知)をクリアするための仕組みに、R-CNNと呼ばれるネットワークがある。関心領域の切り出しにCNNではない従来手法(HOGなどの非CNN手法)を用いている。関心領域の切り出しの後に、領域ごとに個別にCNNを呼び出す2段階のモデルで、物体検知を実現している。関心領域の切り出しと切り出した領域の物体認識を同時に行うことが可能になった、高速R-CNNもある。
SSD
R-CNNではバウンディングボックスを色々と動かしてそのたびにCNNによる演算を行っていたので、1枚の画像から物体検出を行うのにかなりの処理時間がかかってた。一方でSSDでは"Single Shot"という名前が暗示しているように、1度のCNN演算で物体の「領域候補検出」と「クラス分類」の両方を行うことができる。これにより物体検出処理の高速化、CNNを関心領域の切り出しにも使うことによる精度向上を可能にした。
セマンティックセグメンテーション
R-CNNのような矩形の領域を切り出すのではなく、より詳細な領域分割を得るモデルである。物体認識においては、領域分割を詳細に(ピクセル単位で)行う。通常のCNNは出力層のユニット数が識別すべきカテゴリ数だったが、セマンティックセグメンテーションでは入力画像の画素数だけ出力層が必要になる。すなわち、各画像がそれぞれどのカテゴリーに属するのかを出力する必要があるため、出力層には入力画像の縦ピクセル数$\times$入力画像の横ピクセル数$\times$分類のカテゴリ数の出力ニューロンが必要になる。