はじめに
国勢調査2020の都道府県別回答状況のExcelをスクレイピングしてインターネット回答率・郵送回答率を可視化
スクレイピング
import requests
from bs4 import BeautifulSoup
import re
from urllib.parse import urljoin
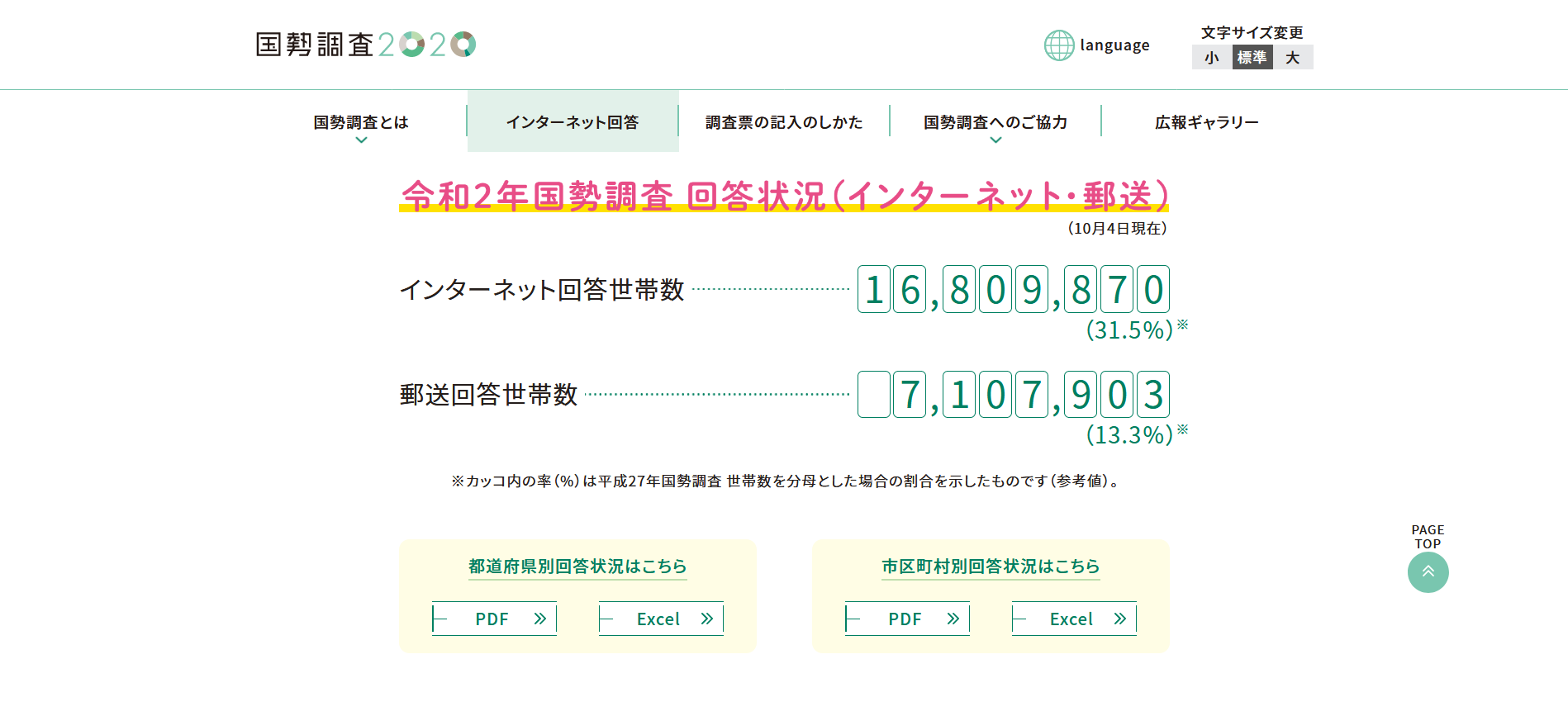
url = "https://www.kokusei2020.go.jp/internet/"
r = requests.get(url)
r.raise_for_status()
soup = BeautifulSoup(r.content, "html.parser")
links = {}
for i in soup.find_all("span", text="Excel"):
link = urljoin(url, i.find_parent("a").get("href"))
m = re.search("census_answers_(pref|city)_\d{6}.xlsx", link)
if m:
links[m.group(1)] = link
links
都道府県別
import pandas as pd
df_pref = pd.read_excel(
links["pref"],
index_col=[0, 1],
header=None,
skiprows=9,
usecols=[1, 2, 3, 4, 5, 6, 7],
names=["コード", "都道府県", "H27世帯数", "ネット", "郵送", "ネット率", "郵送率"],
)
df_pref["回答数"] = df_pref["ネット"] + df_pref["郵送"]
df_pref["ネット率"] *= 100
df_pref["郵送率"] *= 100
df_pref["回答率"] = df_pref["ネット率"] + df_pref["郵送率"]
df_pref.to_csv("pref.csv", encoding="utf_8_sig")
市町村別
df_city = pd.read_excel(
links["city"],
index_col=[0, 1, 2],
header=None,
skiprows=9,
usecols=[1, 2, 3, 4, 5, 6, 7, 8],
names=["コード", "都道府県", "市区町村", "H27世帯数", "ネット", "郵送", "ネット率", "郵送率"],
)
df_city["回答数"] = df_city["ネット"] + df_city["郵送"]
df_city["ネット率"] *= 100
df_city["郵送率"] *= 100
df_city["回答率"] = df_city["ネット率"] + df_city["郵送率"]
df_city.to_csv("city.csv", encoding="utf_8_sig")
df_city
可視化
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
import japanize_matplotlib
# 解像度
import matplotlib as mpl
mpl.rcParams["figure.dpi"] = 200
df1 = df_pref.sort_index(ascending=False).reset_index(level="コード", drop=True)
df1.loc[:, ["ネット率", "郵送率"]].plot.barh(stacked=True, figsize=(5, 10))
plt.legend(bbox_to_anchor=(1.05, 1), loc="upper left", borderaxespad=0, fontsize=8)
plt.savefig("01.png", dpi=200, bbox_inches="tight")
plt.show()
