はじめに
camelotは点線が苦手でよく失敗するので調べてみると以下の参考の記事が見つかりました
camelotはopencvで抽出しているので点線を書き換えればいいみたいなのでハフ変換で点線を抽出し実線で上書きしてみたらうまくいきました
参考
Pythonを使えばテキストを含むPDFの解析は簡単だ・・・そんなふうに考えていた時期が俺にもありました
こちらの記事の横の点線のPDFを使わせていただきます
ハフ変換
ハフ変換で直線抽出
千葉のGo To Eatの加盟店一覧のPDF

ハフ変換で水平の直線のみ抽出

プログラム
import cv2
import numpy as np
import camelot
# パッチ作成
def my_threshold(imagename, process_background=False, blocksize=15, c=-2):
img = cv2.imread(imagename)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(gray, 50, 150, apertureSize=3)
lines = cv2.HoughLinesP(
edges, rho=1, theta=np.pi / 180, threshold=80, minLineLength=3000, maxLineGap=50
)
for line in lines:
x1, y1, x2, y2 = line[0]
# 水平の場合はy1 == y2、垂直の場合はx1 == x2のifでフィルタする
cv2.line(img, (x1, y1), (x2, y2), (0, 0, 0), 1)
if process_background:
threshold = cv2.adaptiveThreshold(
gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, blocksize, c
)
else:
threshold = cv2.adaptiveThreshold(
np.invert(gray),
255,
cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY,
blocksize,
c,
)
return img, threshold
camelot.parsers.lattice.adaptive_threshold = my_threshold
tables = camelot.read_pdf("data.pdf", pages="all")
tables[0].df
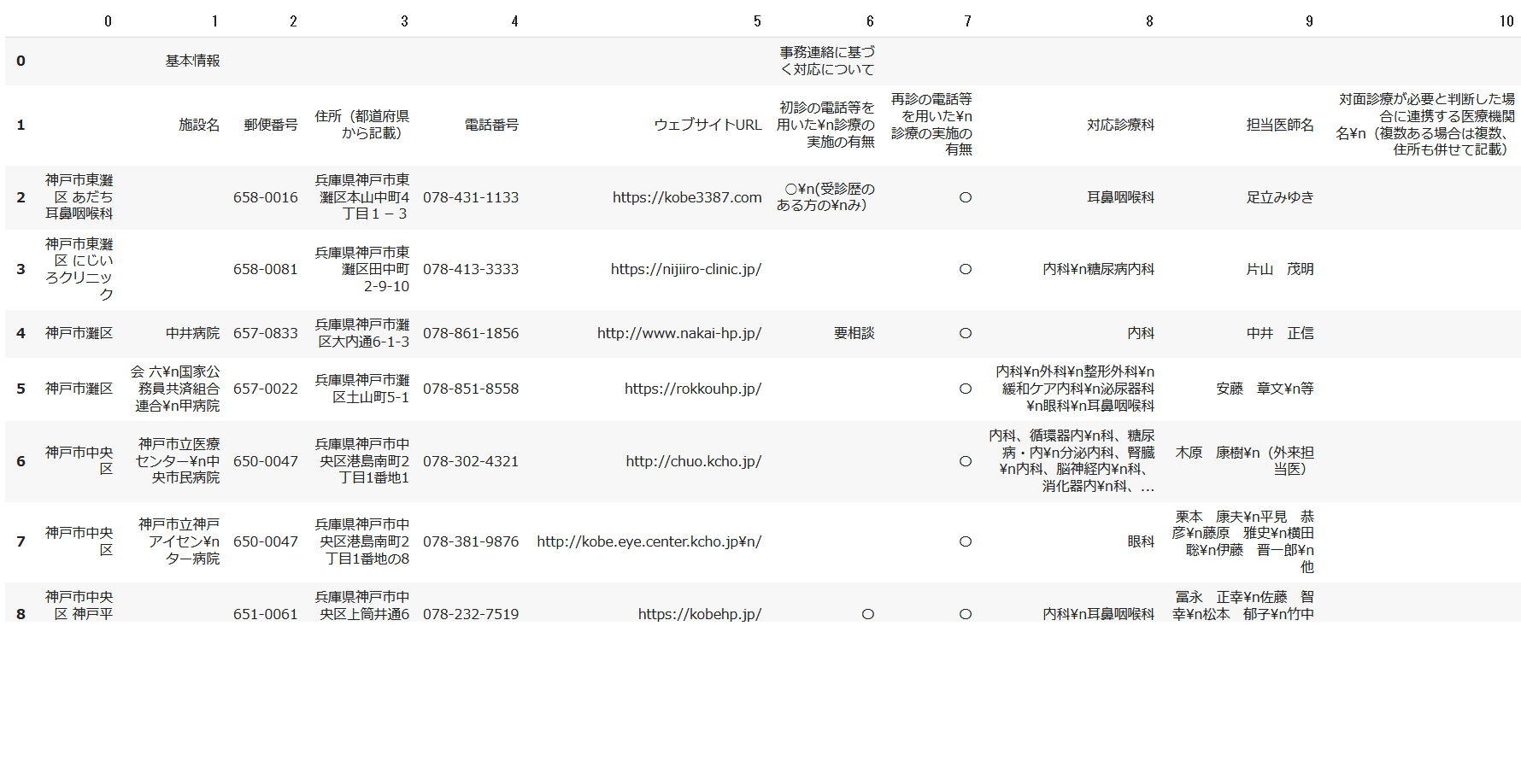
パッチ摘要前
点線部分が反応しないため縦に結合してしまっている
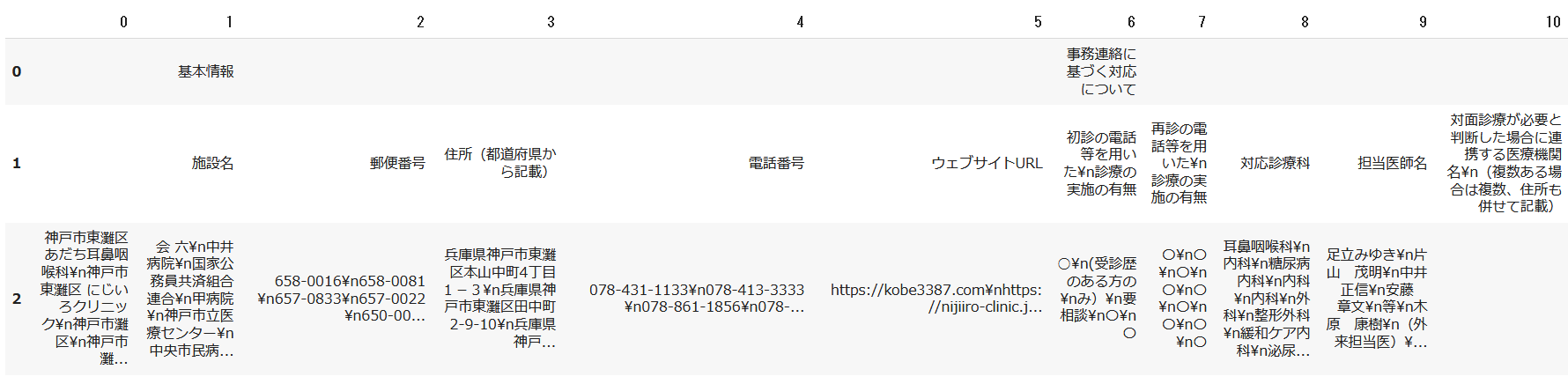
パッチ摘要後