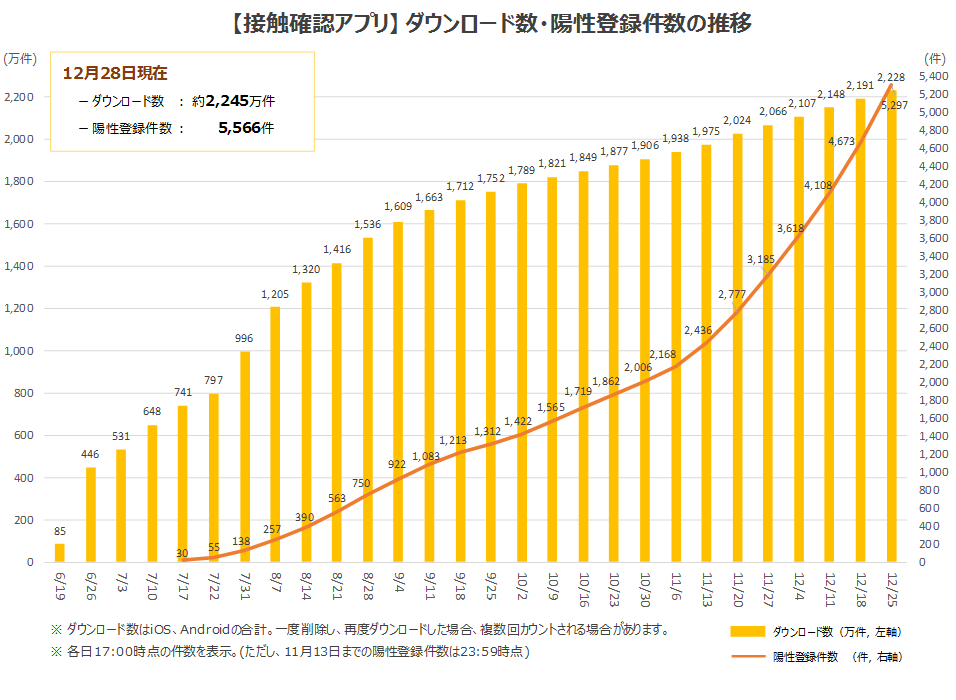
厚生労働省の新型コロナウイルス接触確認アプリ(COCOA) COVID-19 Contact-Confirming Applicationのグラフの左上のダウンロード数と陽性登録件数をスクレイピング
プログラム
スクレイピング
import base64
import requests
from bs4 import BeautifulSoup
url = "https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/cocoa_00138.html"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"
}
r = requests.get(url, headers=headers)
r.raise_for_status()
soup = BeautifulSoup(r.content, "lxml")
img_tag = soup.select('div.m-grid > div.m-grid__col1 > img[src^="data:image/png;base64"]')[1]
img_b64 = img_tag.get("src").replace("data:image/png;base64,", "")
png = base64.b64decode(img_b64)
画像を保存
import pathlib
import datetime
# 今日の日付
dt_today = datetime.date.today()
# 日付を文字列に変換
s_today = dt_today.strftime("%Y%m%d")
# PATH指定
p = pathlib.Path(f"../getIMG_pool/cocoa_info{s_today}.png")
p.parent.mkdir(parents=True, exist_ok=True)
with p.open(mode="wb") as fw:
fw.write(png)
png_path = str(p)
OCR
tesseract-ocrをインストール
!add-apt-repository ppa:alex-p/tesseract-ocr -y
!apt update
!apt install tesseract-ocr
!apt install libtesseract-dev
!tesseract -v
!apt install tesseract-ocr-jpn tesseract-ocr-jpn-vert
!apt install tesseract-ocr-script-jpan tesseract-ocr-script-jpan-vert
!tesseract --list-langs
!pip install pytesseract

画像から文字を抽出
import pytesseract
import cv2
import numpy as np
from google.colab.patches import cv2_imshow
# グレースケールで読み込み
img = cv2.imread(png_path, 0)
# 画像切り抜き
img_crop = img[55:150, 55:300]
# リサイズ1.2倍
height, width = img_crop.shape
imgx12 = cv2.resize(img_crop, (int(width * 1.2), int(height * 1.2)))
# 画像を確認
cv2_imshow(imgx12)
txt = (
pytesseract.image_to_string(imgx12, lang="jpn", config="--psm 6")
.strip()
.replace(",", "")
.replace(".", "")
).splitlines()
print(txt)
# ['12月28日現在', 'ーダウンロード数 : 約2245万件', 'ー陽性登録件数 : 5566件']
文字抽出
import re
# 更新日
m = re.search("(\d{1,2})月(\d{1,2})日", txt[0])
dt_update = dt_today
if m:
year = dt_today.year
month, day = map(int, m.group(1, 2))
dt_update = datetime.date(year, month, day)
if dt_today < dt_update:
dt_update = datetime.date(year - 1, month, day)
def str2num(s: str) -> int:
m = re.search("(\d+)(万)?件", s)
n = 0
if m:
n = int(m.group(1))
if m.group(2) == "万":
n = n * 10000
return n
# ダウンロード数
download_cnt = str2num(txt[1])
# 陽性登録件数
patients_cnt = str2num(txt[2])
print(dt_update, download_cnt, patients_cnt)