山梨県の新型コロナウイルス感染症に関する統計情報をスクレイピング・データラングリング
はじめに
- 新型コロナウイルス感染症に関する統計情報(発生状況、検査状況、相談件数)からスクレイピング
- 一週間ごとにまとまっていて日別は日・件でまとまっている
手順
- 期間を開始と終了に分割、内訳を日ごとに分割、結合
- 開始と終了を日付に変換
- 日付ごとに整然化
- 日と件数に分割
- 開始・終了と日・件数を結合
- 日から日付に変換
- 日付と小計
スクレイピング
dfs = pd.read_html(
"https://www.pref.yamanashi.jp/koucho/coronavirus/info_coronavirus_data.html"
)
df0 = df.iloc[1:].set_axis(["期間", "件数", "内訳"], axis=1)
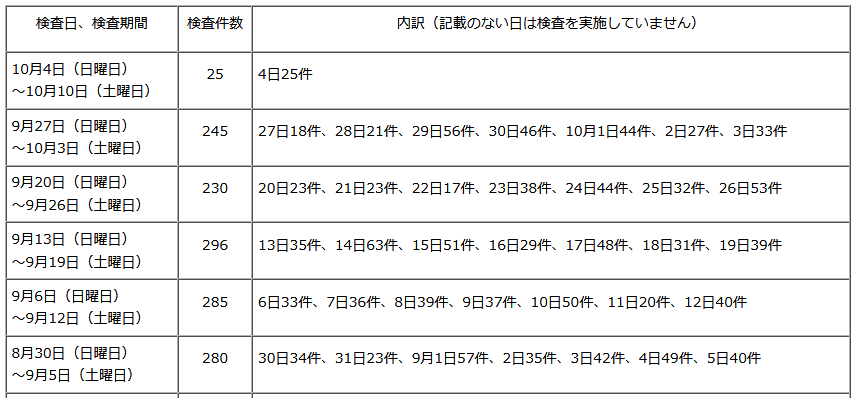
| 期間 | 件数 | 内訳 | |
|---|---|---|---|
| 1 | 10月4日(日曜日) ~10月10日(土曜日) | 25 | 4日25件 |
| 2 | 9月27日(日曜日) ~10月3日(土曜日) | 245 | 27日18件、28日21件、29日56件、30日46件、10月1日44件、2日27件、3日33件 |
| 3 | 9月20日(日曜日) ~9月26日(土曜日) | 230 | 20日23件、21日23件、22日17件、23日38件、24日44件、25日32件、26日53件 |
| 4 | 9月13日(日曜日) ~9月19日(土曜日) | 296 | 13日35件、14日63件、15日51件、16日29件、17日48件、18日31件、19日39件 |
| 5 | 9月6日(日曜日) ~9月12日(土曜日) | 285 | 6日33件、7日36件、8日39件、9日37件、10日50件、11日20件、12日40件 |
| 6 | 8月30日(日曜日) ~9月5日(土曜日) | 280 | 30日34件、31日23件、9月1日57件、2日35件、3日42件、4日49件、5日40件 |
| 7 | 8月23日(日曜日) ~8月29日(土曜日) | 371 | 23日26件、24日90件、25日54件、26日58件、27日56件、28日49件、29日38件 |
| 8 | 8月16日(日曜日) ~8月22日(土曜日) | 537 | 16日83件、17日54件、18日94件、19日108件、20日95件、21日69件、22日34件 |
| 9 | 8月9日(日曜日) ~8月15日(土曜日) | 500 | 9日68件、10日75件、11日57件、12日73件、13日77件、14日63件、15日87件 |
| 10 | 8月2日(日曜日) ~8月8日(土曜日) | 711 | 2日52件、3日43件、4日90件、5日84件、6日126件、7日141件、8日175件 |
データラングリング
期間を開始と終了に分割、内訳を日ごとに分割、結合
df1 = pd.concat(
[
df0["期間"].str.split("~", expand=True).rename(columns={0: "開始", 1: "終了"}),
df0["内訳"].str.split("、", expand=True),
],
axis=1,
)
| 開始 | 終了 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 10月4日(日曜日) | 10月10日(土曜日) | 4日25件 | ||||||
| 2 | 9月27日(日曜日) | 10月3日(土曜日) | 27日18件 | 28日21件 | 29日56件 | 30日46件 | 10月1日44件 | 2日27件 | 3日33件 |
| 3 | 9月20日(日曜日) | 9月26日(土曜日) | 20日23件 | 21日23件 | 22日17件 | 23日38件 | 24日44件 | 25日32件 | 26日53件 |
| 4 | 9月13日(日曜日) | 9月19日(土曜日) | 13日35件 | 14日63件 | 15日51件 | 16日29件 | 17日48件 | 18日31件 | 19日39件 |
| 5 | 9月6日(日曜日) | 9月12日(土曜日) | 6日33件 | 7日36件 | 8日39件 | 9日37件 | 10日50件 | 11日20件 | 12日40件 |
| 6 | 8月30日(日曜日) | 9月5日(土曜日) | 30日34件 | 31日23件 | 9月1日57件 | 2日35件 | 3日42件 | 4日49件 | 5日40件 |
| 7 | 8月23日(日曜日) | 8月29日(土曜日) | 23日26件 | 24日90件 | 25日54件 | 26日58件 | 27日56件 | 28日49件 | 29日38件 |
| 8 | 8月16日(日曜日) | 8月22日(土曜日) | 16日83件 | 17日54件 | 18日94件 | 19日108件 | 20日95件 | 21日69件 | 22日34件 |
| 9 | 8月9日(日曜日) | 8月15日(土曜日) | 9日68件 | 10日75件 | 11日57件 | 12日73件 | 13日77件 | 14日63件 | 15日87件 |
| 10 | 8月2日(日曜日) | 8月8日(土曜日) | 2日52件 | 3日43件 | 4日90件 | 5日84件 | 6日126件 | 7日141件 | 8日175件 |
開始と終了を日付に変換
df1["開始"] = df1["開始"].str.normalize("NFKC").apply(my_parser)
df1["終了"] = df1["終了"].str.normalize("NFKC").apply(my_parser)
| 開始 | 終了 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2020-10-04 00:00:00 | 2020-10-10 00:00:00 | 4日25件 | ||||||
| 2 | 2020-09-27 00:00:00 | 2020-10-03 00:00:00 | 27日18件 | 28日21件 | 29日56件 | 30日46件 | 10月1日44件 | 2日27件 | 3日33件 |
| 3 | 2020-09-20 00:00:00 | 2020-09-26 00:00:00 | 20日23件 | 21日23件 | 22日17件 | 23日38件 | 24日44件 | 25日32件 | 26日53件 |
| 4 | 2020-09-13 00:00:00 | 2020-09-19 00:00:00 | 13日35件 | 14日63件 | 15日51件 | 16日29件 | 17日48件 | 18日31件 | 19日39件 |
| 5 | 2020-09-06 00:00:00 | 2020-09-12 00:00:00 | 6日33件 | 7日36件 | 8日39件 | 9日37件 | 10日50件 | 11日20件 | 12日40件 |
| 6 | 2020-08-30 00:00:00 | 2020-09-05 00:00:00 | 30日34件 | 31日23件 | 9月1日57件 | 2日35件 | 3日42件 | 4日49件 | 5日40件 |
| 7 | 2020-08-23 00:00:00 | 2020-08-29 00:00:00 | 23日26件 | 24日90件 | 25日54件 | 26日58件 | 27日56件 | 28日49件 | 29日38件 |
| 8 | 2020-08-16 00:00:00 | 2020-08-22 00:00:00 | 16日83件 | 17日54件 | 18日94件 | 19日108件 | 20日95件 | 21日69件 | 22日34件 |
| 9 | 2020-08-09 00:00:00 | 2020-08-15 00:00:00 | 9日68件 | 10日75件 | 11日57件 | 12日73件 | 13日77件 | 14日63件 | 15日87件 |
| 10 | 2020-08-02 00:00:00 | 2020-08-08 00:00:00 | 2日52件 | 3日43件 | 4日90件 | 5日84件 | 6日126件 | 7日141件 | 8日175件 |
日付ごとに整然化
df2 = df1.melt(id_vars=["開始", "終了"]).dropna()
| 開始 | 終了 | variable | value | |
|---|---|---|---|---|
| 0 | 2020-10-04 00:00:00 | 2020-10-10 00:00:00 | 0 | 4日25件 |
| 1 | 2020-09-27 00:00:00 | 2020-10-03 00:00:00 | 0 | 27日18件 |
| 2 | 2020-09-20 00:00:00 | 2020-09-26 00:00:00 | 0 | 20日23件 |
| 3 | 2020-09-13 00:00:00 | 2020-09-19 00:00:00 | 0 | 13日35件 |
| 4 | 2020-09-06 00:00:00 | 2020-09-12 00:00:00 | 0 | 6日33件 |
| 5 | 2020-08-30 00:00:00 | 2020-09-05 00:00:00 | 0 | 30日34件 |
| 6 | 2020-08-23 00:00:00 | 2020-08-29 00:00:00 | 0 | 23日26件 |
| 7 | 2020-08-16 00:00:00 | 2020-08-22 00:00:00 | 0 | 16日83件 |
| 8 | 2020-08-09 00:00:00 | 2020-08-15 00:00:00 | 0 | 9日68件 |
| 9 | 2020-08-02 00:00:00 | 2020-08-08 00:00:00 | 0 | 2日52件 |
日と件数に分割
df3 = (
df2["value"]
.str.extract("([0-9,]+)[日件]([0-9,]+)件", expand=True)
.rename(columns={0: "日", 1: "小計"})
.astype(int)
)
| 日 | 小計 | |
|---|---|---|
| 0 | 4 | 25 |
| 1 | 27 | 18 |
| 2 | 20 | 23 |
| 3 | 13 | 35 |
| 4 | 6 | 33 |
| 5 | 30 | 34 |
| 6 | 23 | 26 |
| 7 | 16 | 83 |
| 8 | 9 | 68 |
| 9 | 2 | 52 |
開始・終了と日・件数を結合
df4 = pd.concat([df2, df3], axis=1)
| 開始 | 終了 | variable | value | 日 | 小計 | |
|---|---|---|---|---|---|---|
| 0 | 2020-10-04 00:00:00 | 2020-10-10 00:00:00 | 0 | 4日25件 | 4 | 25 |
| 1 | 2020-09-27 00:00:00 | 2020-10-03 00:00:00 | 0 | 27日18件 | 27 | 18 |
| 2 | 2020-09-20 00:00:00 | 2020-09-26 00:00:00 | 0 | 20日23件 | 20 | 23 |
| 3 | 2020-09-13 00:00:00 | 2020-09-19 00:00:00 | 0 | 13日35件 | 13 | 35 |
| 4 | 2020-09-06 00:00:00 | 2020-09-12 00:00:00 | 0 | 6日33件 | 6 | 33 |
| 5 | 2020-08-30 00:00:00 | 2020-09-05 00:00:00 | 0 | 30日34件 | 30 | 34 |
| 6 | 2020-08-23 00:00:00 | 2020-08-29 00:00:00 | 0 | 23日26件 | 23 | 26 |
| 7 | 2020-08-16 00:00:00 | 2020-08-22 00:00:00 | 0 | 16日83件 | 16 | 83 |
| 8 | 2020-08-09 00:00:00 | 2020-08-15 00:00:00 | 0 | 9日68件 | 9 | 68 |
| 9 | 2020-08-02 00:00:00 | 2020-08-08 00:00:00 | 0 | 2日52件 | 2 | 52 |
日から日付に変換
- 終了の日と日を比較し、大きければ開始日の日を置換、小さければ終了の日を置換し日付を作成
df4["日付"] = df4.apply(
lambda x: x["開始"].replace(day=x["日"])
if x["終了"].day < x["日"]
else x["終了"].replace(day=x["日"]),
axis=1,
)
| 開始 | 終了 | variable | value | 日 | 小計 | 日付 | |
|---|---|---|---|---|---|---|---|
| 0 | 2020-10-04 00:00:00 | 2020-10-10 00:00:00 | 0 | 4日25件 | 4 | 25 | 2020-10-04 00:00:00 |
| 1 | 2020-09-27 00:00:00 | 2020-10-03 00:00:00 | 0 | 27日18件 | 27 | 18 | 2020-09-27 00:00:00 |
| 2 | 2020-09-20 00:00:00 | 2020-09-26 00:00:00 | 0 | 20日23件 | 20 | 23 | 2020-09-20 00:00:00 |
| 3 | 2020-09-13 00:00:00 | 2020-09-19 00:00:00 | 0 | 13日35件 | 13 | 35 | 2020-09-13 00:00:00 |
| 4 | 2020-09-06 00:00:00 | 2020-09-12 00:00:00 | 0 | 6日33件 | 6 | 33 | 2020-09-06 00:00:00 |
| 5 | 2020-08-30 00:00:00 | 2020-09-05 00:00:00 | 0 | 30日34件 | 30 | 34 | 2020-08-30 00:00:00 |
| 6 | 2020-08-23 00:00:00 | 2020-08-29 00:00:00 | 0 | 23日26件 | 23 | 26 | 2020-08-23 00:00:00 |
| 7 | 2020-08-16 00:00:00 | 2020-08-22 00:00:00 | 0 | 16日83件 | 16 | 83 | 2020-08-16 00:00:00 |
| 8 | 2020-08-09 00:00:00 | 2020-08-15 00:00:00 | 0 | 9日68件 | 9 | 68 | 2020-08-09 00:00:00 |
| 9 | 2020-08-02 00:00:00 | 2020-08-08 00:00:00 | 0 | 2日52件 | 2 | 52 | 2020-08-02 00:00:00 |
日付と小計
df = pd.DataFrame(
{"小計": df4.set_index("日付")["小計"].sort_index().asfreq("D", fill_value=0)}
)
| 日付 | 小計 |
|---|---|
| 2020-02-02 00:00:00 | 1 |
| 2020-02-03 00:00:00 | 2 |
| 2020-02-04 00:00:00 | 1 |
| 2020-02-05 00:00:00 | 1 |
| 2020-02-06 00:00:00 | 0 |
| 2020-02-07 00:00:00 | 0 |
| 2020-02-08 00:00:00 | 0 |
| 2020-02-09 00:00:00 | 0 |
| 2020-02-10 00:00:00 | 0 |
| 2020-02-11 00:00:00 | 1 |
import datetime
import re
import pandas as pd
def my_parser(s):
y = dt_now.year
m, d = map(int, re.findall("(\d{1,2})", s))
return pd.Timestamp(year=y, month=m, day=d)
def df_conv(df):
df0 = df.iloc[1:].set_axis(["期間", "件数", "内訳"], axis=1)
# 期間を開始日と終了日に分割、内訳を日ごとに分割、結合
df1 = pd.concat(
[
df0["期間"].str.split("~", expand=True).rename(columns={0: "開始", 1: "終了"}),
df0["内訳"].str.split("、", expand=True),
],
axis=1,
)
# 日付に変換
df1["開始"] = df1["開始"].str.normalize("NFKC").apply(my_parser)
df1["終了"] = df1["終了"].str.normalize("NFKC").apply(my_parser)
# 日付ごとに整然化
df2 = df1.melt(id_vars=["開始", "終了"]).dropna()
# 日と件数に分割
df3 = (
df2["value"]
.str.extract("([0-9,]+)[日件]([0-9,]+)件", expand=True)
.rename(columns={0: "日", 1: "小計"})
.astype(int)
)
# 開始・終了と日・件数を結合
df4 = pd.concat([df2, df3], axis=1)
# 日から日付に変換
df4["日付"] = df4.apply(
lambda x: x["開始"].replace(day=x["日"])
if x["終了"].day < x["日"]
else x["終了"].replace(day=x["日"]),
axis=1,
)
# 日付と小計
df = pd.DataFrame(
{"小計": df4.set_index("日付")["小計"].sort_index().asfreq("D", fill_value=0)}
)
return df
JST = datetime.timezone(datetime.timedelta(hours=+9))
dt_now = datetime.datetime.now(JST)
dfs = pd.read_html(
"https://www.pref.yamanashi.jp/koucho/coronavirus/info_coronavirus_data.html"
)
len(dfs)
# 県衛生環境研究所における疑似症例の検査状況
df1 = df_conv(dfs[1])
df1.to_csv("pcr.csv", encoding="utf_8_sig")
# 帰国者・接触者相談センター
df2 = df_conv(dfs[2])
df2.to_csv("soudan.csv", encoding="utf_8_sig")
# 新型コロナウイルス感染症専用相談ダイヤル
df3 = df_conv(dfs[3])
df3.to_csv("dial.csv", encoding="utf_8_sig")