概要
Towards 3D Human Pose Estimation in the Wild: a Weakly-supervised Approach(2017)の論文の実装を試そうとしました。学習は行っていません。また考察等に関しては自論で論文で指摘されたものではないので注意してください。
目次
Towards 3D Human Pose Estimation in the Wild: a Weakly-supervised Approach(2017)
デモの準備
デモ
リアルタイム処理
【追加】時系列を考慮したときの処理
Towards 3D Human Pose Estimation in the Wild: a Weakly-supervised Approach(2017)
実装自体はxingyizhou/pytorch-pose-hg-3dのレポジトリを用いました。
このレポジトリでは元論文とは少しモデルが違います。
元論文2Dの姿勢推定時にHourGlassを用いていましたが、この実装ではResNetを用いているそうです。
3D姿勢推定のベンチマークで一般的に使われているものはHuman3.6Mというものです。そのSOTAを以下のリンクから参考にしてください。
3D Human Pose Estimation on Human3.6M
この中で、今回の実装はAVERAGE MPJPEという評価値が64.9のWeakly Supervised Transfer Learningに値します。ここではMonocular(単眼カメラ)とは書かれていませんが、単眼カメラで撮影された映像です。
デモの準備
AnacondaでPython 3.6, PyTorch v0.4.1の仮想環境を作成。(自分はPyTocrh v1.6.0でも動きました)
作成した仮想環境を有効化し、opencv, progress, matplotlibをインストール。
conda create -n hpe3dwsa python=3.6
conda activate hpe3dwsa
conda install -c michael_wild opencv-contrib
conda install progress matplotlib
自分の環境にあったPytorchをここからダウンロードする。
レポジトリを任意の場所にクローン。
cd hoge
git clone git@github.com:xingyizhou/pytorch-pose-hg-3d.git
学習済みモデルをここからダウンロードします。
ダウンロードした学習済みモデルは/pytorch-pose-hg-3d/models/fusion_3d_var.pthとなるように移動させます。
デモ
デモは/pytorch-pose-hg-3d/src直下で下のコマンドで行うことができます。
python demo.py --demo /path/to/image/or/image/folder [--gpus -1] [--load_model /path/to/model]
-
--gpu: GPUを使うかどうかを指定できる。
-0もしくは引数を用いない場合はGPUを使って処理することになる。-1の場合はCPUで処理します。 -
--load_model: 学習済みモデルのパスを指定できる。デフォルトで学習済みモデルになっているダウンロードしたものを上記の通りに移動させているならば指定しなくてもよいです。
デモの結果
お試しとして/pytorch-pose-hg-3d/images/に用意されてあるhuman3.6mの室内の画像とMP2の屋外の画像で試してみました。

Human3.6mの例 (上が2D姿勢推定で下が3D姿勢推定)

MP2の例 (上が2D姿勢推定で下が3D姿勢推定)
2D姿勢推定に関して、両方とも正確に推定出来ている。3D姿勢推定に関して、深度が一部ずれているように見えるが大まかな予測はできているようです。
デモの考察
MP2の例について注目すると、人間は結果を見て深度がずれていると判断できます。人間ならば、女性は腕立て伏せをしているのだから、腰から足にかけては結果のように歪んでいるのではなく真っ直ぐでないといけないし、左手と首と右手は一直線上にあるのが普通だと認識します。しかし機械にはそのようなことを教えていないので与えられた画像から素直に推定するためこのような結果になったと考えました。行動認識やHOI(Human-Object Interaction)も視野にいれて、制約を加えた姿勢推定をするとより良い結果になるのかもしれません。
リアルタイム処理
USBカメラを用いてリアルタイムで3D化してくれるスクリプトを書いたのでご参照を。
hanebarla/HPE3D_pytorch_hg_subfunction
このスクリプトは/pytorch-pose-hg-3d/src直下に移動させないと動かないので注意してください。
実行をやめるときはESCキーを押すと中断することができます。
import cv2
import numpy as np
import torch
import torch.utils.data
from opts import opts
from model import create_model
from utils.debugger import Debugger
from utils.image import get_affine_transform, transform_preds
from utils.eval import get_preds, get_preds_3d
image_ext = ['jpg', 'jpeg', 'png']
mean = np.array([0.485, 0.456, 0.406], np.float32).reshape(1, 1, 3)
std = np.array([0.229, 0.224, 0.225], np.float32).reshape(1, 1, 3)
class dcam(Debugger):
def __init__(self):
self.loop_on = 1
super().__init__()
def realtime_show(self, pause=False, k=0):
max_range = np.array([self.xmax - self.xmin, self.ymax - self.ymin, self.zmax - self.zmin]).max()
Xb = 0.5 * max_range * np.mgrid[-1:2:2, -1:2:2, -1:2:2][0].flatten() + 0.5 * (self.xmax + self.xmin)
Yb = 0.5 * max_range * np.mgrid[-1:2:2, -1:2:2, -1:2:2][1].flatten() + 0.5 * (self.ymax + self.ymin)
Zb = 0.5 * max_range * np.mgrid[-1:2:2, -1:2:2, -1:2:2][2].flatten() + 0.5 * (self.zmax + self.zmin)
for xb, yb, zb in zip(Xb, Yb, Zb):
self.ax.plot([xb], [yb], [zb], 'w')
self.plt.draw()
self.plt.pause(0.1)
self.plt.cla()
def press(self, event):
if event.key == 'escape':
self.loop_on = 0
def destroy_loop(self):
self.fig.canvas.mpl_connect('key_press_event', self.press)
def is_image(file_name):
ext = file_name[file_name.rfind('.') + 1:].lower()
return ext in image_ext
def demo_image(image, model, opt):
s = max(image.shape[0], image.shape[1]) * 1.0
c = np.array([image.shape[1] / 2., image.shape[0] / 2.], dtype=np.float32)
trans_input = get_affine_transform(
c, s, 0, [opt.input_w, opt.input_h])
inp = cv2.warpAffine(image, trans_input, (opt.input_w, opt.input_h),
flags=cv2.INTER_LINEAR)
inp = (inp / 255. - mean) / std
inp = inp.transpose(2, 0, 1)[np.newaxis, ...].astype(np.float32)
inp = torch.from_numpy(inp).to(opt.device)
out = model(inp)[-1]
pred = get_preds(out['hm'].detach().cpu().numpy())[0]
pred = transform_preds(pred, c, s, (opt.output_w, opt.output_h))
pred_3d = get_preds_3d(out['hm'].detach().cpu().numpy(),
out['depth'].detach().cpu().numpy())[0]
return image, pred, pred_3d
def main(opt):
camera = cv2.VideoCapture(0)
opt.heads['depth'] = opt.num_output
if opt.load_model == '':
opt.load_model = '../models/fusion_3d_var.pth'
if opt.gpus[0] >= 0:
opt.device = torch.device('cuda:{}'.format(opt.gpus[0]))
else:
opt.device = torch.device('cpu')
model, _, _ = create_model(opt)
model = model.to(opt.device)
model.eval()
debugger = dcam()
k = 0
while debugger.loop_on:
ret, frame = camera.read()
image, pred, pred_3d = demo_image(frame, model, opt)
debugger.add_img(image)
debugger.add_point_2d(pred, (255, 0, 0))
debugger.add_point_3d(pred_3d, 'b')
debugger.realtime_show(k)
debugger.destroy_loop()
debugger.show_all_imgs()
k = cv2.waitKey(10)
if k == 27:
debugger.loop_on = 0
cv2.destroyAllWindows()
camera.release()
if __name__ == '__main__':
opt = opts().parse()
main(opt)
dcamクラスは2次元推定した結果と3次元推定した結果をそれぞれ描画するためにあるクラスです。demo_img関数は入力画像とモデル、その他設定を入力とし、その入力画像と2次元推定したキーポイント(関節位置)と3次元推定したキーポイントを返す関数です。
デモは次のコマンドで動かせます。オプション等は最初のデモと同じ。
python camera_demo.py [--gpus -1] [--load_model /path/to/model]
リアルタイム処理の結果
3D姿勢のみ掲載します。
以下にデモの様子の動画のリンクを載せます。
デモの結果
また、その中でも3D姿勢の様子を以下に示します
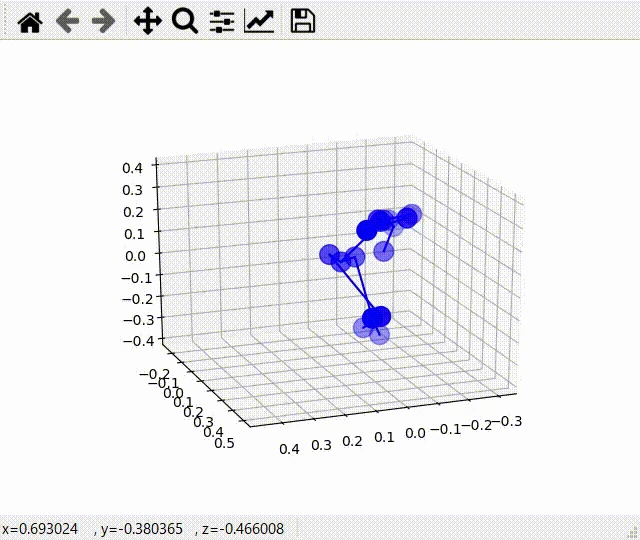
最初と最後は被写体はカメラ外から入ったり出て行ったりしています。
全身が映ったのが次の図のときの様子です。
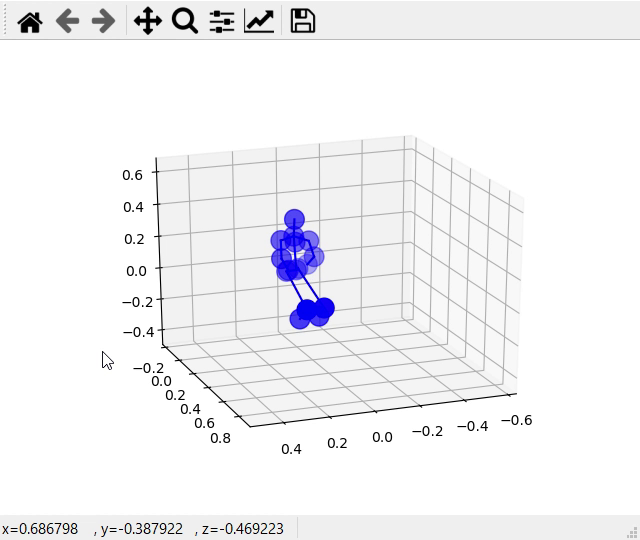
そして次の図では手を広げるという動作を行ったときの様子です。上の図と下の図は比較的正確に推定出来ています。
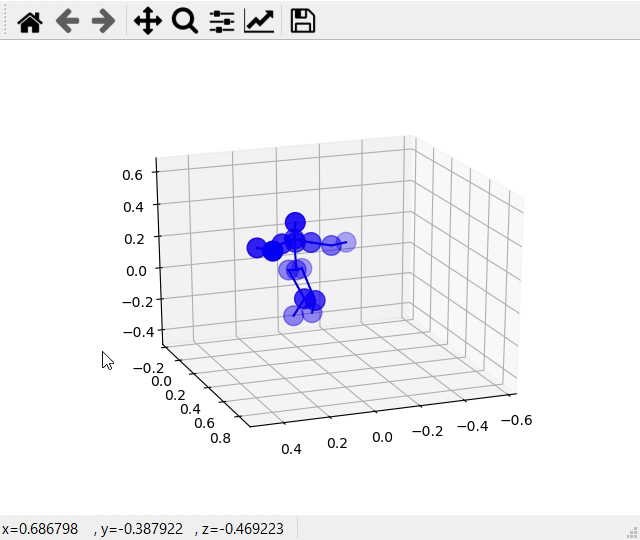
次の図ではカメラに近づいていくときの図です。この図では下半身は正確にカメラに向かって移動している様子が分かるが、上半身は移動していません。
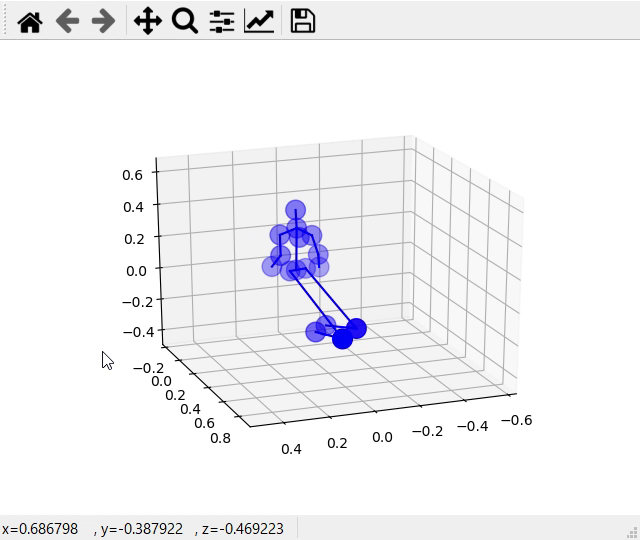
リアルタイム処理の考察
結果でも述べたようにカメラ外に体の一部が出てしまうと正確に推定することができていないことが分かりました。これは撮影環境依存だと考えられます。今回のモデルはいわゆるbottom-up式、つまり初めに画像の中から最も特定の体の部位らしいものを推定しそれを繋げる手法であるため、画像の中に体っぽいものが含まれてしまうと誤った推測になってしまいます。簡素な部屋等で用いるのがよいと思われます。
また結果の一番最後の図についてだが、人の足が伸びていることが問題である。この問題は一つ前のデモと似たような問題だと考えられる。人間は人の足など伸びたりしないと分かっているので今回の結果のようには推測しない。
そしてもう一つ、人がカメラ外から入ってきたり出て行ったりするとき、推定場所が飛び飛びになっています。人間(生きている)は体の部位を瞬時にあちこちに移動させたり出来ていません。つまり機械は、人間が時間に関して連続であることが分かっていないということです。この問題を解決するために前後のフレームを参照するということが考えられます。実際にビデオから姿勢推定を行っている研究もありました。
【追加】時系列の条件を加えた場合
今回は時系列を考慮する際に、LSTMまたは3DCNNを用いました。そのモデルの概形は下のグラフのようになりました。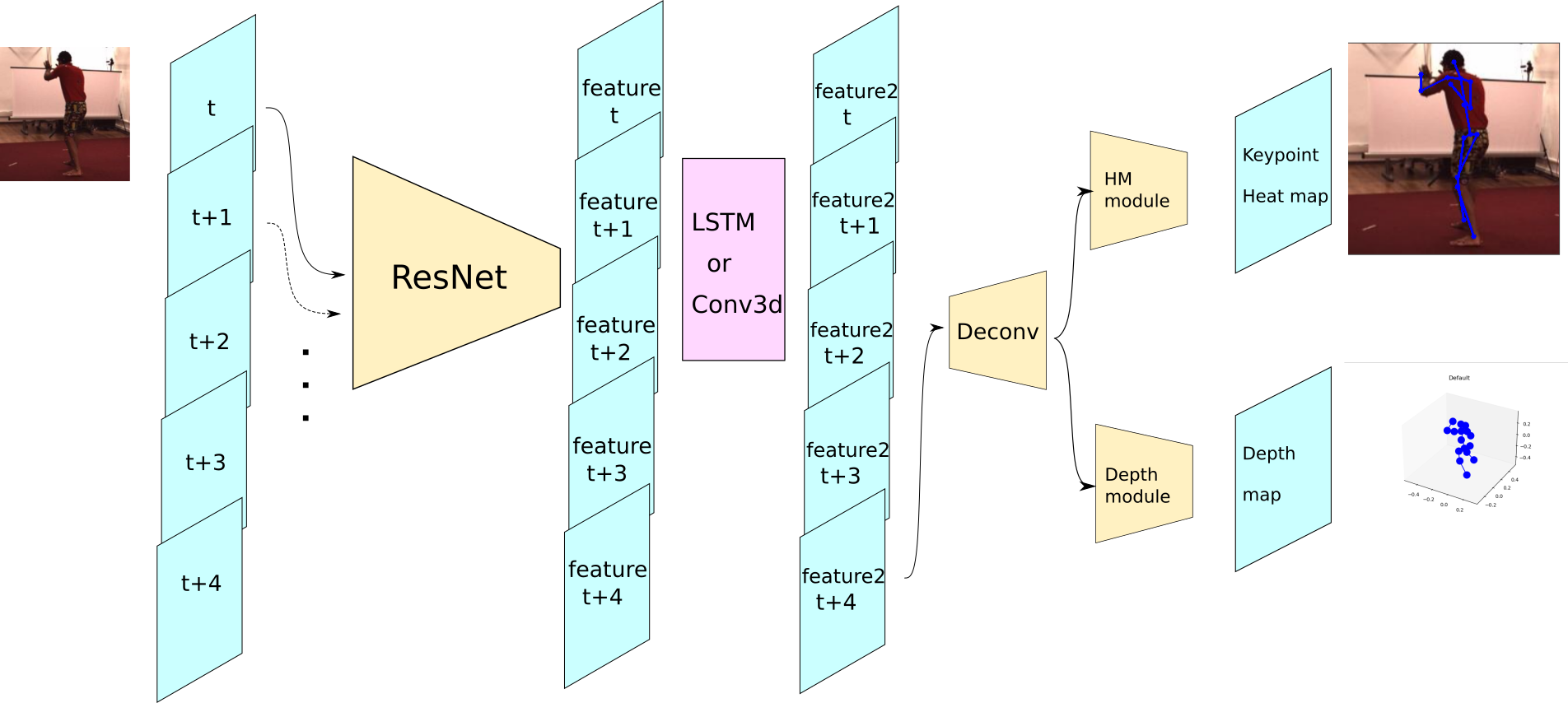
LSTMと3DCNNは画像中央あたりのピンク色で示した部分で適用しました。LSTMに関してはResNetで得られた特徴マップをflattenさせています。
また、このデモ等のスクリプトはhanebarla/pytorch-pose-hg-3dにあります。
学習済みモデルはこのGoogleDriveからダウンロードして解凍してください。解凍した後はレポジトリのmodelディレクトリ内に移動させてください。
それぞれのデモはsrcディレクトリ直下で以下のコマンドで実行できます。
python lstm_demo.py --task lstm --load_model ../models/model_lstm.pth
python lstm_demo.py --task conv3d --load_model ../models/model_conv3d.pth
LSTMを用いたときの結果
以下Google Driveのリンクにデモの様子を動画として示します。
LSTM
時系列を用いない場合に比べてフレームレートが明らかに下がっています。また、直立時の膝の深度は時系列を用いなかった場合に比べて誤差は少なくなっているのが観測できました。
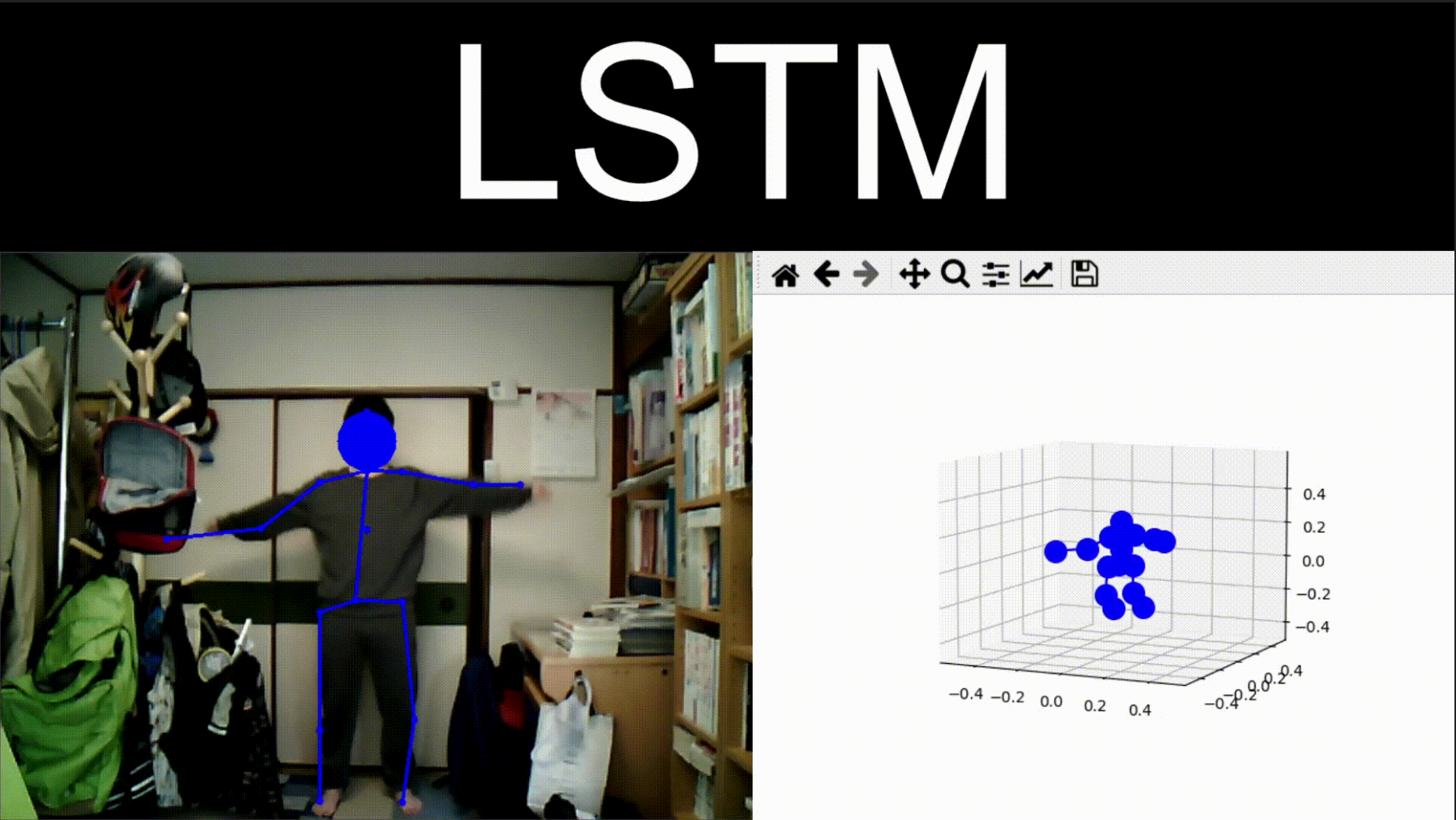
Conv3dを用いたときの結果
以下Google Driveのリンクにデモの様子を動画として示します。
Conv3D
この場合もLSTMと同様にフレームレートが下がり、深度の誤差も少なくなっていそうです。さらに、2次元姿勢推定においてLSTMより少し精度が上がっていると思われます。

時系列を用いた実験の考察
今回の追加の実験で精度が上がったのは、もちろん時系列を加えたということもあるが、層が増えたからでもあると考えられます。ただ時系列を加えただけでは膝の部分の深度が正しくなるとは思わないからです。時系列を加えただけではより前のフレームの予測結果に近いものになると思いました。層が増えて精度が良くなることは、LSTMよりConv3dの方が精度が良かったという理由付けにもなると思います。
まとめ
2017年の時点で上記のように推定できてるのが分かった。近年ではVR関係が盛り上がっているっぽいのでこの分野の研究も加速的に増えているのではないかと思っている。今度は実際に最近のモデルを学習させてやってみようかなぁと考えている。特に、SOTAの上位はほとんどはマルチビュー(複数のカメラ)であるので、そのデモも見てみたいものです。
(この記事は研究室インターンで取り組みました:https://kojima-r.github.io/kojima/)