#0. この記事の内容#
半導体生産技術者が未経験からデータ分析業界に転職してみて3ヶ月間で感じたこととこれから生存していくために考えていることを書きます。同じ様なキャリアに踏み出そうとしている方がいれば、参考にしていただけると幸いです。ただし、現在研修中の身であり、実務についていないためデータ分析業について確度の高い情報をお伝えすることができません。また、経験や知識が浅いためデータ分析・機械学習で出来ることと出来ないことの区別がついていないかもしれません。なので、お見苦しいところがあるかもしれません。あくまで、未経験者が一歩目を踏み出した時点での感想として受け取ってください。
また、本記事は「データ分析人材のキャリア(データラーニングギルド) Advent Calendar 2019」15日目の記事になります。
(2020/7/24 追記)
この記事には転職するまでの内容を書いておりますが、
転職後1年間のことを話したLTの資料、およびインタビュー動画を以下にアップしておりますので、
良かったらご覧ください。
「この1年データ分析界隈でやったことと今後の戦略 データラーニングギルド 1周年記念LT」
[「【YouTube】30代未経験からデータサイエンティストになった方法!本人にインタビュー」]
(https://youtu.be/EVgYKqQ-2Ns)
#1. 読んで欲しい人
データ分析業界と無縁だけど、キャリアチェンジに興味のある方
メーカーの技術職(非IT)でデータ分析業へキャリアチェンジを考えている方
#2. 経歴#
大学院を卒業してからのほとんどの時間を生産技術者としてのキャリアを歩んできました。
ITやプログラミングとは無縁の人生です(笑)
理工系大学院修了(応用物理)→
大手電機メーカーで半導体製品の生産技術職(7年間)→
ベンチャー企業で半導体製品の生産技術職(2年間)→
データ分析受託、エンジニア派遣会社(3ヶ月目)
#3. なぜキャリアチェンジしようと考えたか#
今年の8月にデータ分析受託とエンジニア派遣を行っている会社に転職しました。
理由は、今後データ分析や機械学習が製造現場を大きく変えることが予想され、生産技術✖️データ分析の掛け算で市場価値を上げたかったためです。大手メーカーを中心に、データ分析や機械学習を使った製造現場の生産性向上の取り組みが活発化しています。今後、労働人口減少やベテランの退職に伴ってこの流れは加速していくものと予想します(ただし、ある程度規模の大きい企業に限定されそう)。私が生産技術職として働いていた時に、データ分析や機械学習に興味を持つきっかけとなった事例を紹介します。
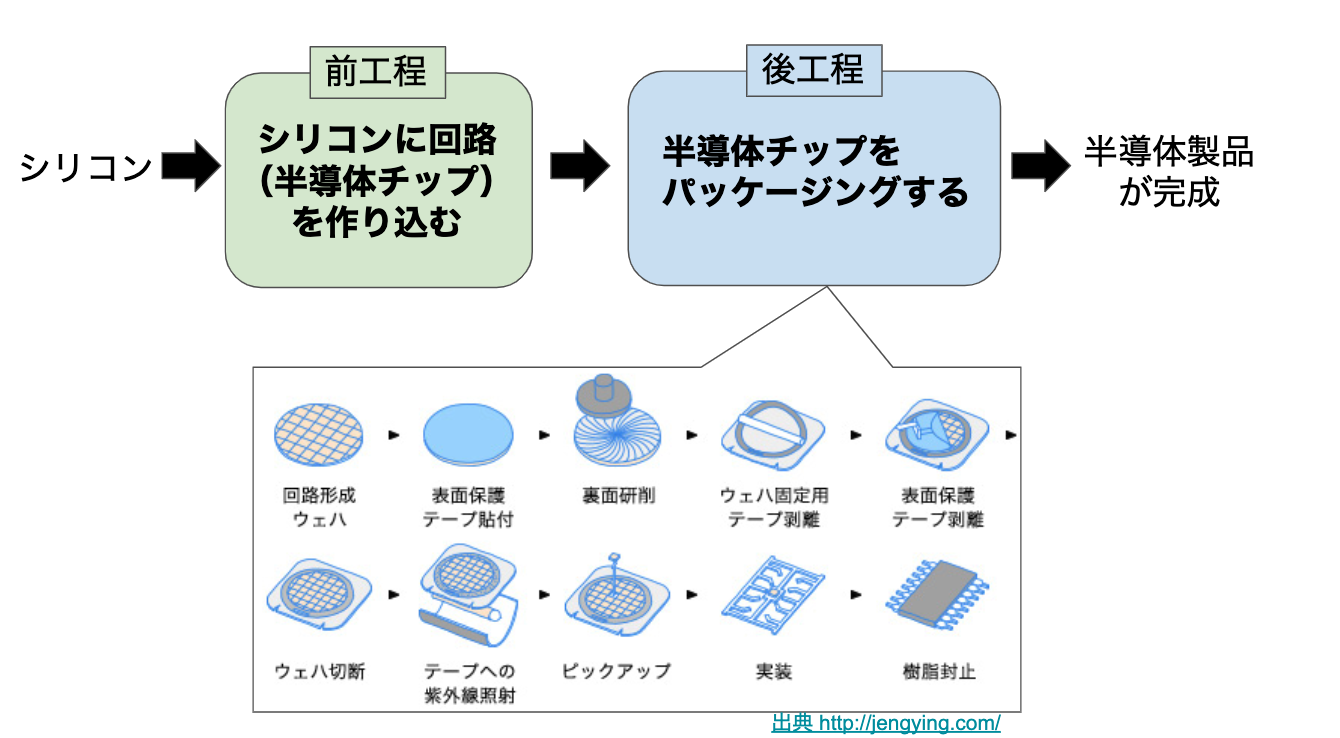
半導体製造には大きく分けて「前工程」と「後工程」があり、私が担当していたのは後工程です。シリコンから半導体チップを作る工程が「前工程」、半導体チップを半導体製品に組み込む工程が「後工程」です。この記事を読んでいる人のほとんどは馴染みないと思います(笑)。後工程の主たるプロセスは、金属ワイヤーでチップと電極を繋いだり、基板にチップを半田付けしたり、樹脂でチップを固めて保護したりです。求められる知識は多岐に渡り、材料物性(無機、有機)、材料力学、冶金学、信頼性工学などを使って仕事を進めます。ノウハウが物を言う領域なので、日本がまだ強い分野です。
生産技術者の仕事は主に4つです。
A. 新たな工法の開発
研究開発を終えた工法を量産で使えるか検証する
B. 量産準備
製造装置選定、製造条件決め、作業要領書作成、凛儀通す
C. 既存製品の不良率低減
アイデアを色々試して、とにかく不良率を下げる
D. トラブル対応
原因調査と対策、スピードが求められる
A、Bは新製品を作るための仕事で、Cは既存製品のコストを下げる仕事です。Dは不良多発や装置トラブルなどの異常事態に対処する仕事です。これが一番キツイです(体力的にも、精神的にも)。B、Dの中で現職に興味を持った事例を記載します。
###[B. 量産準備] 製造条件て機械学習で絞り込めるんじゃない?###
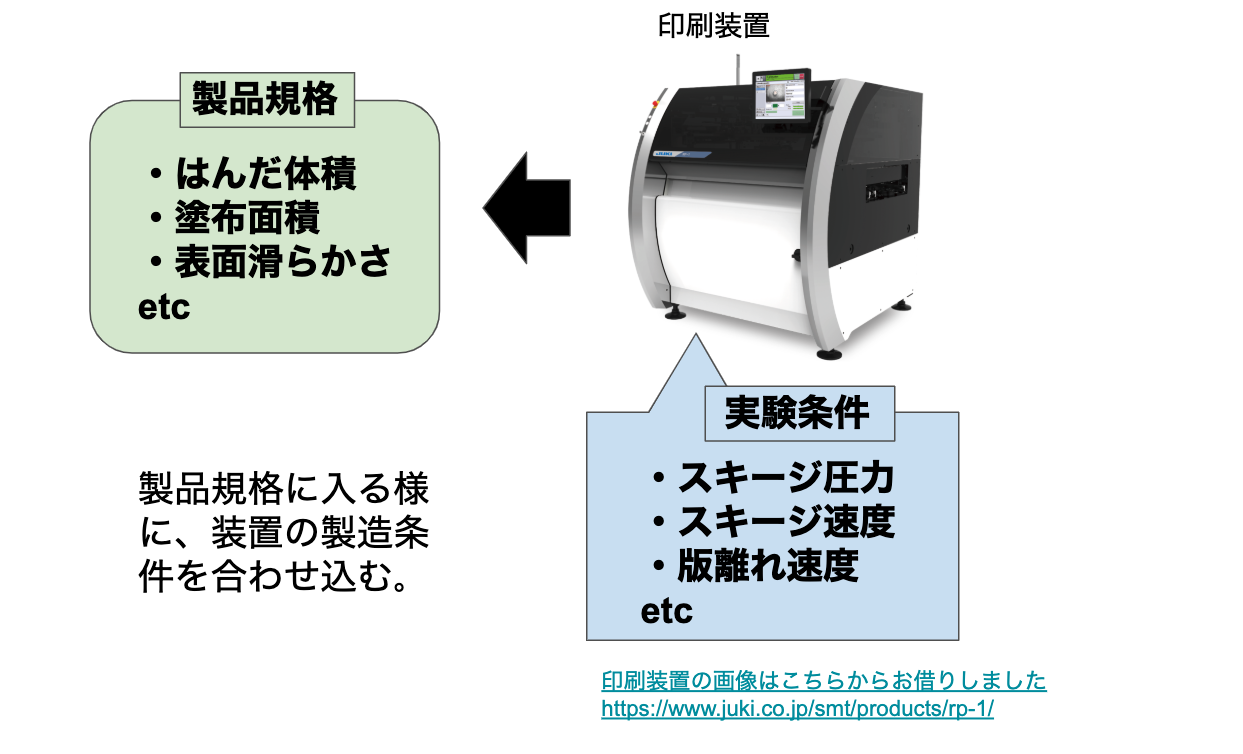
私が担当していた工程に、基板に半田ペーストを印刷する工程がありました。半田の体積や面積が製品規格に入るように製造条件(装置の設定値)を決める仕事です。その際、十分な工程能力を確保できるよう、条件を決めます。実験計画法を用いてなるべく効率的に実験しますが、影響するパラメーターが多く、(装置状態、はんだの粘性や、温度、湿度等)結構な回数の実験が必要になります。影響すると思われる全てのパラメーターの上下限値を見極めます。逆に言うと、規格を外す閾値を見極めるわけです。
この時、パラメーターから出来栄えをシミュレーションして実験条件を決めるということはしません。なぜなら、実験してしまった方が早いですし、NGとなる条件を含めてエビデンスを残さないといけないためです。この作業(下図、青線内)て自動化できるのではないかと思いました。やっていることは、
1.出来栄えに影響しそうなパラメーターを洗い出す(自動化できない)
↓
2.実験計画法により実験条件を決める(自動化できる)
↓
3.出来栄えと条件を付き合わせて、量産条件を絞り込んでいく(自動化できる)
↓
4.想定外の結果になったら、原因を推定して条件を再考する(自動化できない)
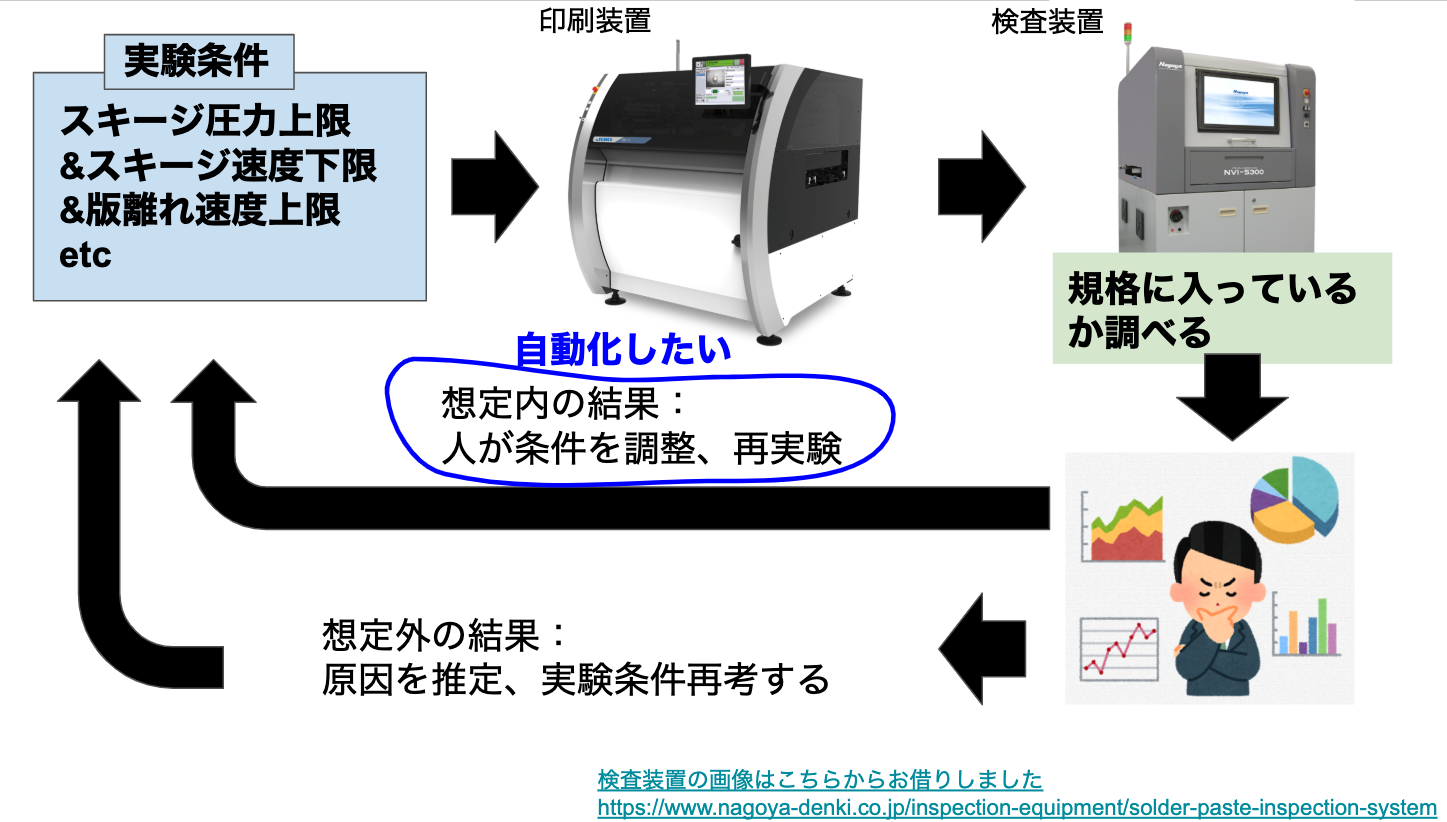
上記2,3はパラメーターを説明変数、出来栄えを目的変数とした最適化問題なので機械学習で代替できるのでは?と考えました。4の場合は、把握できてないパラメーターがあるということなので1からやり直します。自動化することで、現状人にしかできない[A. 新たな工法の開発](#3. なぜキャリアチェンジしようと考えたか)に使える時間が増えるというメリットがあります。自動化した後のイメージは以下です。

###[D. トラブル対応] 原因調査てIoT活用で時短できるんじゃない?###
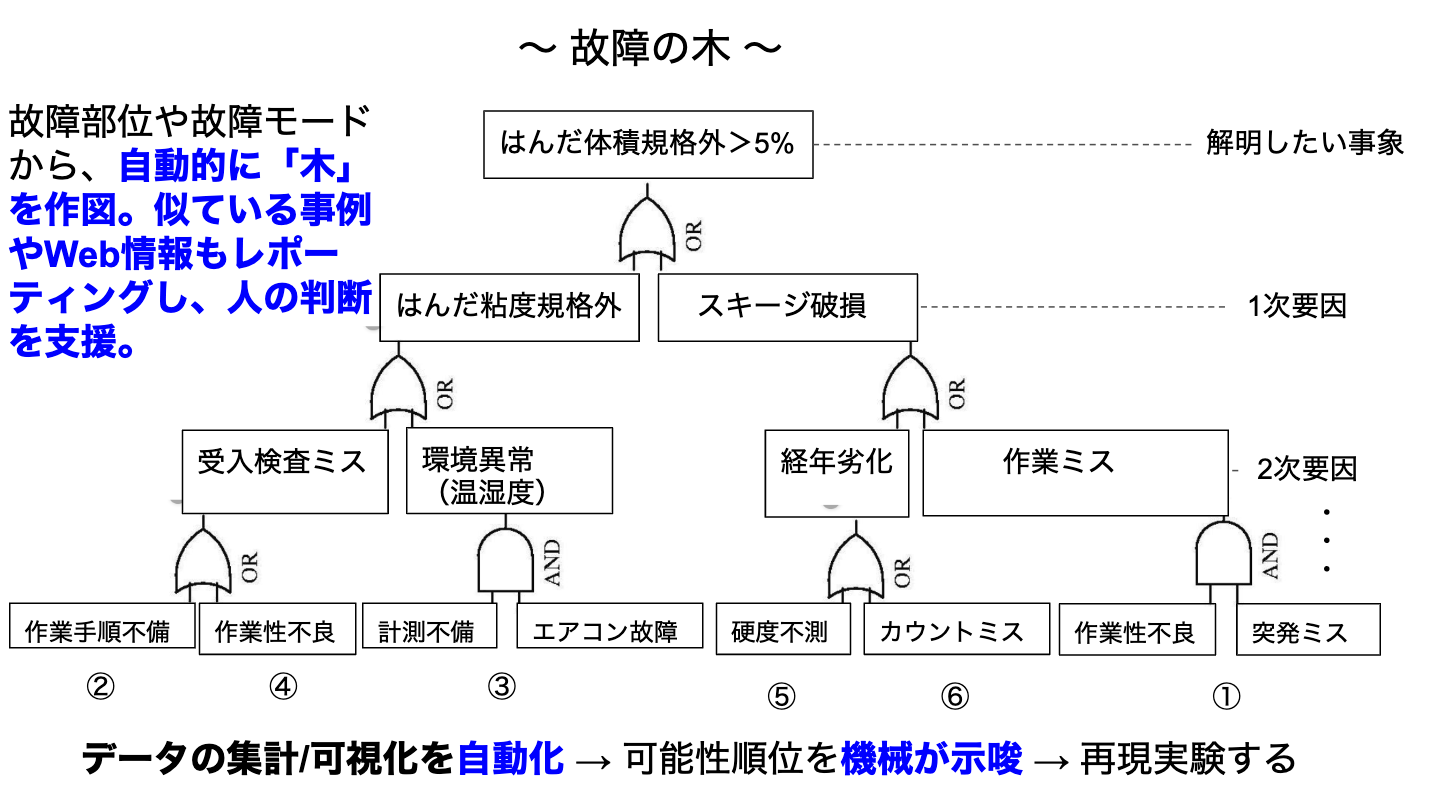
この業務は時間との戦い(納期が迫る→営業からのプレッシャー、ラインが遊ぶ→コストが嵩む)になるため、データ分析や機械学習に最も助けてもらいたい仕事です。製造ラインで異常事態(不良多発や装置トラブル)が起こると、ラインを休止し原因調査と対策を施す必要があります。原因調査の方法として、信頼性工学に基づくFTA(故障の木解析)という方法が用いられます。これは、故障という親事象からスタートして、その事例が起こる要因は何か、またその要因が起こる要因は何か、、、を繰り返し自問自答します。そうすることで、背後にある本質的な要因に辿り着こうというものです。異常が発生すると緊急会議が開かれ、皆で意見を出し合います。5次要因くらいまで洗い出した後、その中で可能性の順位を決めます(過去事例と経験から)。上位の要因から、不良が再現できるか確認していきます。再現できれば、その要因を潰す対策を打ちます。このフローを早く回す必要がありますが、要因を検証するためのデータで定常的に集計していないものは現場へデータを取りに行くことになります(装置ログが多かったです、、)。そして、担当者が急いでデータを集計、可視化し、会議再会という流れになります。慌て振りが目に浮かびます(笑)この時間の使い方はもったいないです。
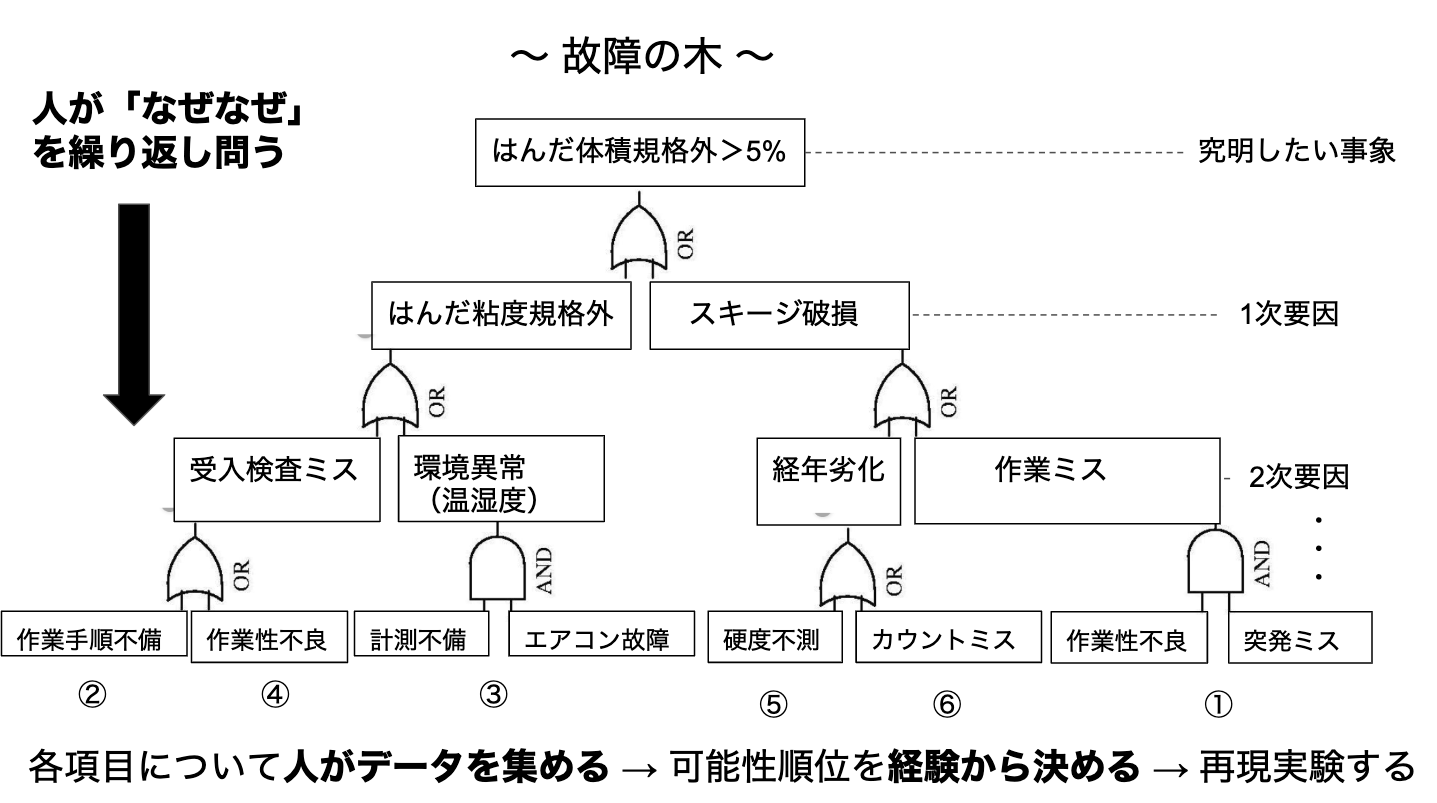
こういう切羽詰まった状況でこそ、IoTやBIツールを活用してデータの集計/可視化を自動化したいです(少なくとも過去に不良要因となった項目は)。また、故障箇所や故障モード、過去事例から故障の木作図までを自動化できないかと考えています(自問自答はかなりハードル高そうですが、、)。これができれば、可能性順位を決めるまでの時間が大幅に短縮でき、原因特定までの時間を大きく短縮できると思います。社内の過去事例やWeb情報から順位を示唆することもできるかもしれません。
乱文になりましたが、以上がデータ分析や機械学習に興味を持ったきっかけです。
半導体製造には膨大な工程が存在するため、効率化できる事例がたくさんあると感じています。
#4. 今年やったことを振り返る
今年やったことを以下にまとめました。
まず、大きなところで言うと転職しました。[3.](#3. なぜキャリアチェンジしようと考えたか)で記載した内容に取り組める環境ではなかったので転職を決意しました。30代未経験からの異職種への転職はかなり迷いましたが。。
転職してからは、会社での研修とデータラーニングギルドを活動の幹としています。データラーニングギルドに参加したのは、会社での研修内容だけでは知識や経験のインプット/アウトプットが足りないので、実務につけるようキャッチアップするためです。
| 時期 | やったこと |
| 1〜5月 前職 |
昼:生産技術 夜:統計勉強、 Python(プログラミングスクール) |
| 6、7月 転職活動と引継ぎ |
データ分析受託1社採、 メーカー2社(AI、データ分析部門)面接落、 書類落ち数多 |
| 8月 退職、引越し、入社 |
京都から東京へ 後は何していたか記憶が曖昧 |
| 9月 自習 |
・統計勉強 ・線形代数勉強 ・データラーニングギルド参加 |
10月〜現在 研修 |
・CRISP-DM概論@会社 ・Rを使って基礎的な多変量解析手法 @会社 ・データラーニングギルドslackコンペ参加 ・統計検定2級取得 |
#5. なぜそのようなことに取り組んだのか?
自走している内容だけ書きます。会社で受けている研修は、方針に従っているだけなので(笑)
###統計、線形代数の勉強###
恥ずかしながら今までちゃんと統計を勉強したことがなかったので、時間がある今のタイミングで勉強しました。統計検定2級のレベルは高くないですが、このレベルは前提として話が進むので初学者の目標としては良いと思います。知識の有無が問題なので、検定自体は受けなくても良いと思います。私は資格手当てが出るんで受けました(笑)。線形代数に関しては、機械学習で必要になるので勉強し始めました。最近、ゼロから作るDeep Learningを読み始めましたが、バリバリ行列計算が出てくるので、やはり機械学習周辺は基礎的な数学知識があった方が理解がスムーズです。
###プログラミング###
Qiitaの別記事でも書きましたが、TechAcademyというプログラミングスクールでPythonを受講しました。今から思えば、あえて自腹を切って受ける必要なかったかもしれません。転職の面接で話しましたが、プラスになったか分かりません(マイナスにはなっていないでしょうが)。ギルド長も言っているように、プログラミングの前に科学的思考力を強化するのに時間を使うべきだったかもしれません。今は優先度下げています。
###データラーニングギルドへの参加###
前述しましたが、会社の研修だけで実務をこなせる力を付けるのは厳しいと感じているので、実践力強化のために参加しました。分析コンペなどを活用して成長する目的です。情報収集の場としても非常に有用と感じています。転職して思うのは、生産技術界隈に比べてこの業界の技術進歩が非常に早いと言うことです。意識してキャッチアップしないと死活問題になりそうです。生産技術の世界だと、新技術が出てきても、量産適用されるまでには数年以上かかるのが普通です。しかし、データ分析業界では、新しい技術の台頭と既存技術の置き換えが非常に早く、どの技術習得に力を入れるか悩ましいです。そのような点も経験者に質問・相談できます。自走できる人にとってはかなり有用なコミュニティだと思います。
#6. 今後どのような方向性でキャリアを構築して行こうと考えているのか?
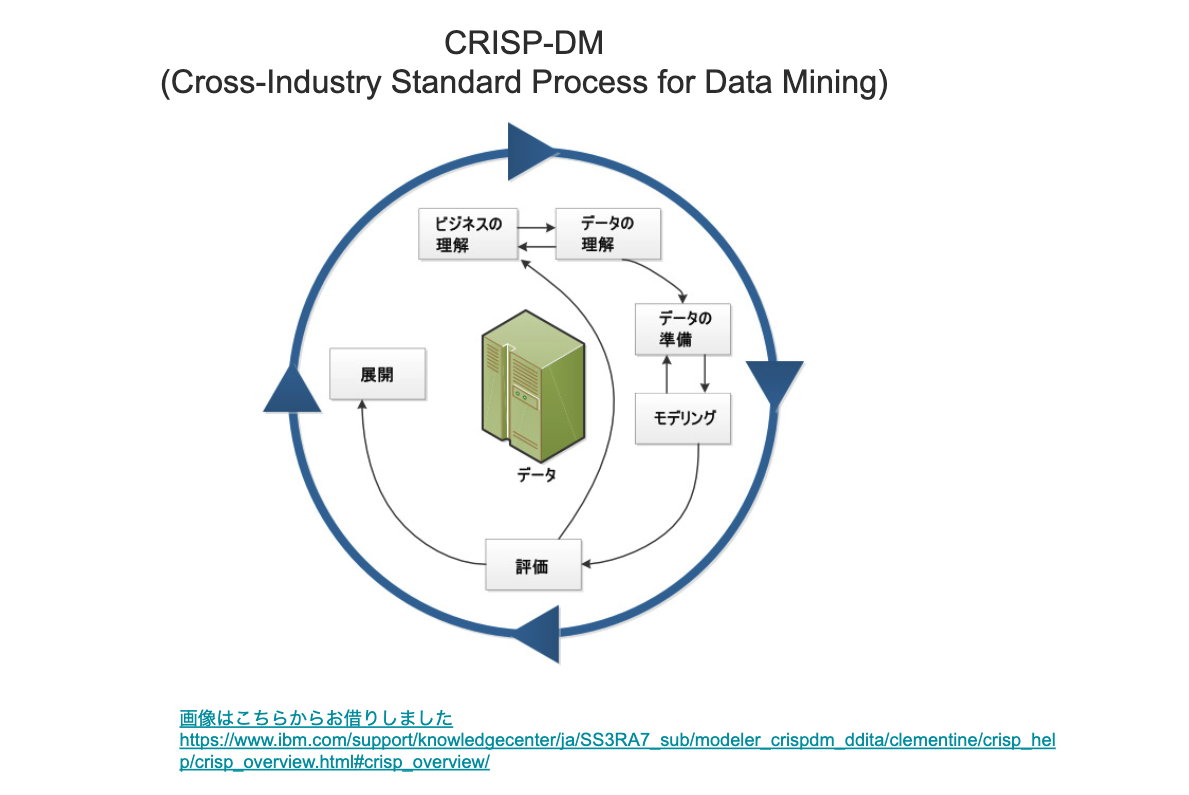
転職した当初は、「データ分析や機械学習が使える生産技術者」を目指していました。しかし、今は「製造業においてデータ分析や機械学習活用を指南できる人間」を目指しています。このように考えが変わった理由をCRISP-DMを例に説明したいと思います。CRISP-DMはデータ分析の業界横断型の標準プロセスで、下記の図のように「ビジネスの理解→データの理解→データの準備→モデル構築→評価→展開」のフローからなります。
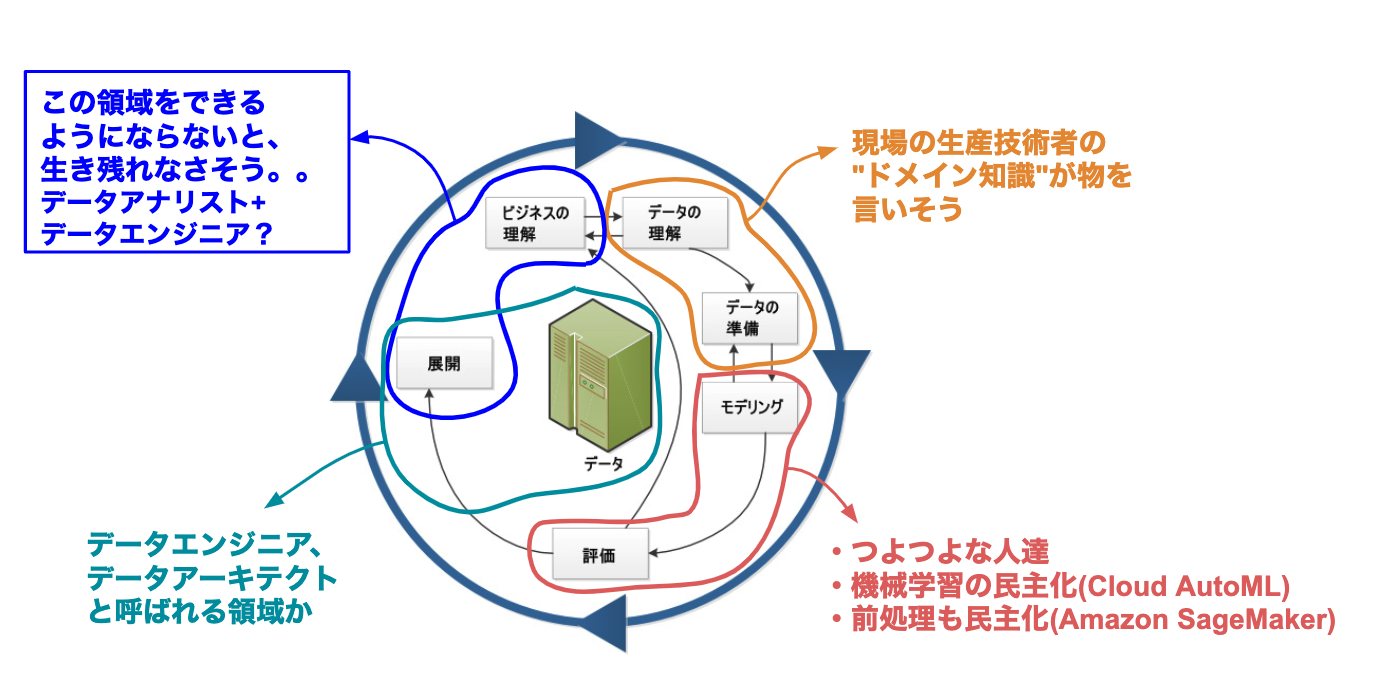
データ分析を生業にするにはどの領域もできることが望ましいのですが、最終的にどこで勝負するかと言うイメージは持っておいた方が良いと思いました。消極的理由で悲しいですが、まず分が悪いと感じている領域とその理由を書きます。
###「データの理解」→生え抜きの生産技術者に勝てない###
データ分析で製造ラインの生産性を上げるためのは、製造ライン特有のドメイン知識が必要になります。例えば、設備のクセや作業者のクセなど、データから原因を推定するためのベースとなる知識です。これは、永く現場で働かないと見えてこない部分が大きいと思います。私は既に生産技術職を辞めているので、今後製造業案件を担当することになってもその現場でのドメイン知識で生産技術者に勝ることはないと思います(元職場の案件を担当したら、、)。また、異常検知の案件では、正常/異常の閾値を決める必要がありますが、これも現場のドメイン知識が物を言うと思います。
###「データの準備」→生え抜きの生産技術者に勝てない###
また、データの準備に関しても、製造現場でデータ取りするには製造部門の協力が必須であり、信頼関係が物を言います。このような関係はすぐに築けるものではなく、そのラインで長く働く生産技術者が適任と思われます。ただし、その現場にはノウハウがない計測技術を身に付けられれば、案件獲得できるかもしれません。
###「モデリング、評価」→つよつよな人達やAutoMLに勝てない###
この領域は、KagglerやコンピューターサイエンスのPh.D.など、つよつよな方達が躍動する領域なので、今からここで戦うのはかなり部が悪いです(笑)。また、昨今のAutoMLの進歩から、スキルがコモディティ化する要素も多いのではと感じています。ただし、どんな手法があるか知らないと調べることもできないので、今はここの知識を増やすことに時間を割いています。不要と言うことではなく、あくまで私が最後に柱にする領域ではないと言うことです。
消去法になりますが、
残った「ビジネスの理解、展開」を将来的に柱にしたいと考えています。
私の心中を可視化すると以下のようになります(笑)。
とは言え、他の領域についても圧倒的に知識が足りていないので、今注力している「モデリング、評価」の領域から外側に向かって能力を伸ばしていきたいと考えています。
そのために、来年は以下を意識して活動するつもりです。計画具体化はこれからになります、、
1.科学的思考力の強化
これは、CRISP-DMの全ての領域で必要になると思われます。数学を勉強することで、一部補ている気がしますが、効率的に強化していく手法を模索中です。
2.分析コンペへの参加
引き続き、Kaggleやデータラーニングギルド内のコンペに参加することで、実践的なスキルを身に付けたいです。
3.分析案件にアサインされるよう動く(できれば製造業案件)
これはもうマストと言うか。アサインされないと話にならないので、研修頑張ります![]()
4.データエンジニア、データアーキテクト領域のスキルアップ
これは、CRISP-DMの「展開」を柱にすることを目指しての活動です。これについても、どうやって鍛えていくか模索中です。スキルがないと案件にアサインされないが、アサインされないとスキルも獲得できない悩ましさがあります。
5.数学の勉強
研修期間が終わっても、引き続き行っていくつもりです。科学的思考力を鍛えることと、機械学習のアルゴリズム理解をスムーズにするためです。アルゴリズムが一定レベル以上理解できていれば、客先で説明を求められた時にも、上手く要約できそうです。
#7. 結局、キャリアチェンジして良かったのか?
現時点で、良かった点と後悔している点が半々と言ったところです(笑)
良かった点としては、
・分析案件に多くの引き合いがあり、需要が伸びていくと感じられる
・日々技術が進歩しており、また世間から注目度が高い職種なので非常にエキサイティング
・データラーニングギルドのようなコミュニティで実務(会社での業務)以外でもスキルを伸ばせる環境が整いつつある
後悔している点としては、
・実務につけるレベルと現状とのギャップが大きい(想像していましたが、想像以上に)
・走る方向を常に模索する必要があり、ぼやっとしていられない(だから面白いとも言える)
・将来のキャリアパスがまだはっきりイメージできない(生産技術職と比較しての意)
もし、今年4月頃にデータラーニングギルドで情報収集できていたら、まだ前職を辞めていなかったかもしれません。私と同じような考えを持っている方がいれば、しっかり実務者から情報収集してから賽を投げることをおすすめします。
乱文、長文になりましたが、キャリア選択の参考になれば幸いです。