序論「永遠の疑惑:MtGアリーナの先攻後攻比率」
Magic: The Gatheringというカードゲームがとても好きで、面白いカードを見つけては変なデッキを組んで回すというのが趣味になっています。
とはいっても格調高い紙プレイヤーではなく、デジタル版のMtGアリーナというソフトで遊んでいるのですが、このMtGアリーナというのがちょっと曲者ソフトなのです。
運営のアプデの度に新たなバグが生まれる、AI発展期の今日に作られたとは思えないクソザコAI、マッチングの不具合等、怪しい部分が多い。そんな信用の無さからユーザー間でまことしやかにささやかれているのが後攻率の異常な偏りや、異常な土地事故率の存在。
人間、悪いときの記憶ばかり残るせいでこういう陰謀論が生まれるわけですが、しかしちゃんと数字で確認しないと納得できないというもの。というわけで負けが込んで熱くなった自分は後攻率の検証に着手したのでした。
Untapped ggでは後攻率のデータが分からない?
MtGアリーナにはUntapped ggという便利なサポートツールがあるのですが、どうもこれでは全体の後攻率は分からないっぽい…
仕方ないのでMtGアリーナが出力するログファイルをちょこっとパースすることに(手動でいちいち先攻後攻をメモするのは面倒なのです)
実際に書いたやーつ
筆者はwindowsのプログラミングには疎いので、さくっとUbuntu on Windowsでpythonスクリプトを書く。解析すべきログファイルはC:\Program Files\Wizards of the Coast\MTGA\MTGA_Data\Logs\Logs以下にある。
そして書いたコードはこんな感じ。ログファイルを読み込んで、先攻後攻数をcsvファイルに吐く。ザ・プログラミング弱者なコードなのは許してほしい。
import os
import sys
import csv
check_newest_only = True
log_dir = "/mnt/c/Program Files/Wizards of the Coast/MTGA/MTGA_Data/Logs/Logs"
log_files = os.listdir(log_dir)
if check_newest_only:
max_timestamp = -1
newest_fname = None
for f in log_files:
timestamp_info = f.split('-')
mm = timestamp_info[1][1:-1]
dd = timestamp_info[2]
yy = timestamp_info[3].split(' ')[0]
tm = timestamp_info[3].split(' ')[1].split('.')
timestamp_str = yy + mm + dd + tm[0] + tm[1] + tm[2]
if int(timestamp_str) > max_timestamp:
max_timestamp = int(timestamp_str)
newest_fname = f
if newest_fname:
log_files = [newest_fname]
matchend_str = 'MatchReady end'
seatid_str = 'systemSeatIds'
turninfo_str = '"turnInfo": { "phase": "Phase_Beginning", "step": "Step_Upkeep", "turnNumber": 1, "activePlayer": '
match_info_list = []
for f in log_files:
log_open = open(log_dir + "/" + f, 'r')
fname_info_list = f.split('-')
m = fname_info_list[1]
d = fname_info_list[2]
y = fname_info_list[3].split(' ')[0]
match_flag = False
seatid_flag = False
systemSeatId = 0
while True:
data = log_open.readline()
if data == '':
break
idx = data.find(matchend_str)
if idx != -1:
match_flag = True
seatid_flag = False
match_time = data[idx + len(matchend_str): -1]
match_time = y + "-" + m + "-" + d + "-" + match_time
elif match_flag:
if not seatid_flag:
seatid_idx = data.find(seatid_str)
if seatid_idx != -1:
seatid_flag = True
systemSeatId = data[seatid_idx + len(seatid_str + '": [ ')]
else:
turninfo_idx = data.find(turninfo_str)
if turninfo_idx != -1:
active_player_id = data[turninfo_idx + len(turninfo_str)]
match_flag = False
seatid_flag = False
match_info_list.append([match_time, active_player_id, systemSeatId])
log_open.close()
draw_cnt = 0
play_cnt = 0
for info in match_info_list:
print(info[2] + " Time:" + info[0], end=' ')
if info[1] == info[2]:
print("Play")
play_cnt = play_cnt + 1
else:
print("Draw")
draw_cnt = draw_cnt + 1
print("Play: " + str(play_cnt) + ", Draw: " + str(draw_cnt))
if check_newest_only:
result_dict = {}
with open("playdrawdata.csv") as f:
reader = csv.reader(f)
for row in reader:
result_dict[row[0]] = row[1]
with open("playdrawdata.csv", 'a') as f:
writer = csv.writer(f)
for info in match_info_list:
if not (info[0] in result_dict):
info_str = [info[0]]
onplay_flag = 0
if info[1] == info[2]:
onplay_flag = 1
info_str.append(onplay_flag)
writer.writerow(info_str)
else:
with open('playdrawdata.csv', 'w') as f:
writer = csv.writer(f)
for info in match_info_list:
info_str = [info[0]]
onplay_flag = 0
if info[1] == info[2]:
onplay_flag = 1
info_str.append(onplay_flag)
writer.writerow(info_str)
このスクリプトの要点
やってることはパースとも言えないような至極シンプルな文字列検索のごり押し。
- "MatchReady end"という文字列を探す。ログファイルに記録されている試合の数だけこの文字列があり、見つかった場所以降が試合情報を記載してある領域。
- "systemSeatIds"という文字列を探す。この文字列の直後に1 or 2が記載されており、これがその試合における自プレイヤーに割り当てられたID。
- '"turnInfo": { "phase": "Phase_Beginning", "step": "Step_Upkeep", "turnNumber": 1, "activePlayer": 'という文字列を探す。この文字列の直後にある数字が先攻のプレイヤーID。これと自プレイヤーのIDを比較することで先攻か後攻か分かる。
もっと簡潔に先攻後攻情報を抜き出せる部分があるんじゃないのって気もするけど動いたのでヨシ!
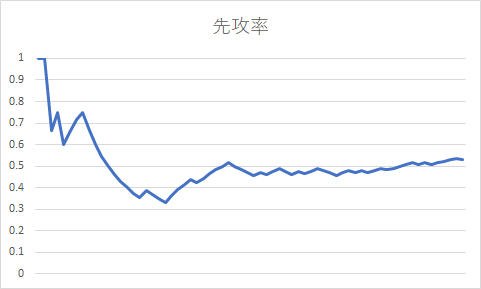
で、集計してみた結果は…
ログファイルからは70戦弱のデータが取れたので、グラフにしてみたのがこちら。試行回数は少ないけども…あんまり偏ってない。やたら後攻引く気がするのは気のせいっぽい。むしろ先攻の方が多いじゃんという結果でした。