業務でSolrを利用していますが、一から動作を見たことがあまりなかったので、自分の理解度のためにもひとつひとつ見てみたものを書いてみます。
今回はフィルターの動作をじっくり見てみました。
schema.xml の設定
あまりいじったようでもないので一般的な設定ではないでしょうか。
<fieldType name="text_ja" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="false">
<analyzer>
<tokenizer class="solr.JapaneseTokenizerFactory" mode="search" userDictionary="lang/userdict_ja.txt"/>
<!-- Reduces inflected verbs and adjectives to their base/dictionary forms (辞書形) -->
<filter class="solr.JapaneseBaseFormFilterFactory"/>
<!-- Removes tokens with certain part-of-speech tags -->
<filter class="solr.JapanesePartOfSpeechStopFilterFactory" tags="lang/stoptags_ja.txt" enablePositionIncrements="true"/>
<!-- Normalizes full-width romaji to half-width and half-width kana to full-width (Unicode NFKC subset) -->
<filter class="solr.CJKWidthFilterFactory"/>
<!-- Removes common tokens typically not useful for search, but have a negative effect on ranking -->
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ja.txt" enablePositionIncrements="true" />
<!-- Normalizes common katakana spelling variations by removing any last long sound character (U+30FC) -->
<filter class="solr.JapaneseKatakanaStemFilterFactory" minimumLength="4"/>
<!-- Lower-cases romaji characters -->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
ちなみにこちらは lucene 4.0 で動かしております。 5.x系以降などで動かす場合は、ストップ系のフィルターにある enablePositionIncrements がデフォルト動作になったようで記述不要になっているようです。
Analysis画面べんり
Admin画面のAnalysisはとても便利で、解析のチェック等もブラウザで行うことができます。例えばローカルだったら、
http://localhost:8983/solr/#/NullpoCore/analysis
とかで見ることができます。
- Field Value (Index)
- インデックスされるまでにどのように分解されるかを見守りたい文書を入力
- Field Value (Query)
- 上記の値に対して検索をかけたい文書
- Analyse Fieldname / FieldType
- text_jaとかtextみたいなやつ、もしくは特定のテキストフィールドを選びましょう
- Verbose Output
- 結果を細かく表示するかどうか
試しに適当な文書を入力してみましょう。
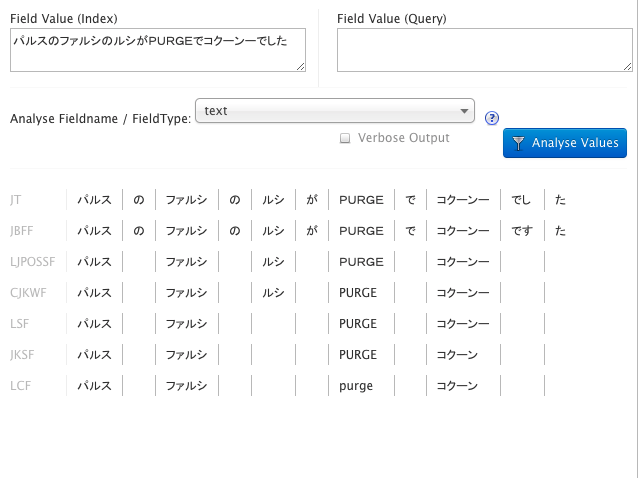
各フィルターの動作
それぞれ変化がある箇所はこんな感じです。
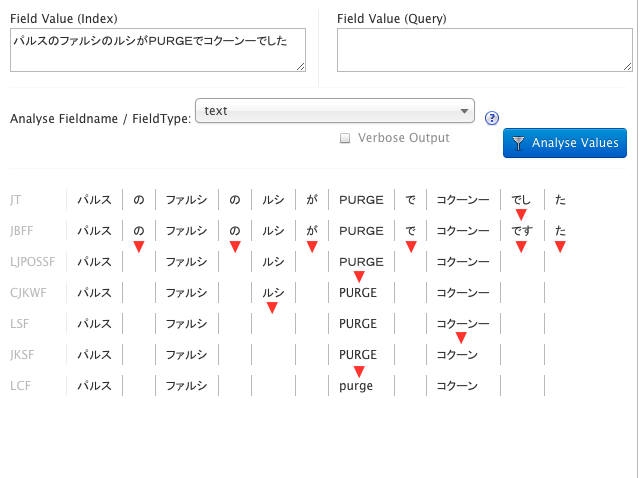
JapaneseTokenizerFactory (JT)
入力された文書を形態素解析してくれます。
カスタムしたユーザ辞書はこのパラメータで指定されているファイルに配置します。
Solr検索を利用するサイト上の固有名詞や一般的でない専門用語などを記述しておくと捗るでしょう。
JapaneseBaseFormFilterFactory (JBFF)
活用形などで終わりが変化する品詞を基本形に戻してくれるフィルターです。
表記ブレがあってもなんとなく検索に引っかかってくれるのはこの子のおかげでもあります。
JapanesePartOfSpeechStopFilterFactory (LJPOSSF)
インデックスに利用したくない特定の品詞などを取り除いてくれるフィルターです。
パラメータで指定の設定ファイルに品詞を記述します。
助詞や接続詞、記号などを取り除く設定が一般的でしょうか。
CJKWidthFilterFactory (CJKWF)
全角ローマ字を半角ローマ字にします。
StopFilterFactory (LSF)
インデックスに利用したくない単語を取り除いてくれるフィルターです。
パラメータで指定されているファイルに単語を書き連ねます。
一般的には差別表現やアダルトワードなどを記述するのではないかと思われますが、それらがおもむろに羅列されているファイルをふと開いてしまうといろいろと惨事です。
サンプルでは"ルシ"が登録されています。
JapaneseKatakanaStemFilterFactory (JSSF)
カタカナの最後の伸ばし音を取り除いてくれます。
サーバー?ユーザー?みたいなのも丸めてくれる感じです。
LowerCaseFilterFactory (LCF)
ローマ字を全部小文字にしてくれます。
-- こうして最後に生き残った猛者がインデックスとして登録されます。
(余談)設定の変更を反映させるとき
schema.xml+付随の設定ファイルの変更
この辺の設定に関してはサービスのリリース前はもちろんリリース後も調整されていく場面も多いと思いますが、schema.xmlに関しては、実ファイルの変更後にRELOADを行うだけで無停止で反映させることができるためわりと気が楽ではないかとおもいます。
逆にファイルの変更後にRELOADを忘れたりすると、変更は反映されずにそのままなところにご注意を。
Admin画面でスキーマブラウザを見ると反映されていないのは確認できますが、ファイルブラウザから見ると実ファイルを見てるだけなので変わっていたりもします。
solrconfig.xmlの変更
この記事とは関係ないですが、こちらのファイルを変更した場合はRELOADすると一見設定は反映されているように思えてSELECTも発行することはできますが、新規にSearcherが開けなくなってcommitができなくなることがあります。
インデックスの更新
フィルターの動作やユーザ辞書等を替えた場合、すでに作成されたインデックスに影響を及ぼすわけではないため、検索結果に影響を及ぼすことがあります。
例えば一般的ではない専門用語などが意図せず品詞分解されてしまっていて、それを単語(名詞)として新規に登録した場合は、以前のフィルターにより作成されたインデックスには分解されて保存されてるままなため、新しいフィルターを通ってきた単語としては引っかからなくなってしまう場合があります。その場合はフィルター更新後にインデックスを再度作り直す必要があります。
とってもわかりやすく図に表すとこんな感じです。
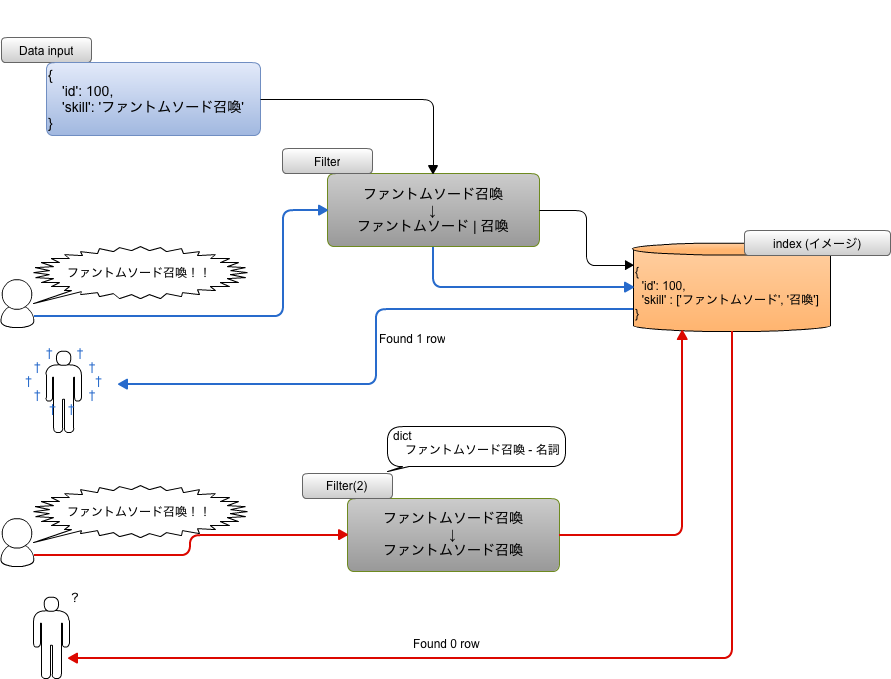
これで安心していろいろ受け継いでいけますね。