背景
index を作るのに、python SDK を使っていたが、indexer 化を試しておこうとした記録
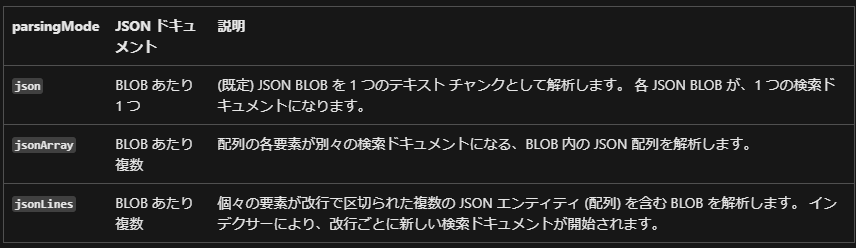
とりあえず、json ファイルなら、以下三種類の方法があって、今回は json 配列を試した。
サンプルソース
以下のような json を blob に保存しておいて、試すことにした。
sample.json
[
{ "id" : "1", "title" : "title 1" },
{ "id" : "2", "title" : "title 2" }
]
items/sample2.json
[
{ "id" : "1", "title" : "title 1 modified" },
{ "id" : "3", "title" : "title 3", "values": {
"text": "text 3",
"content": "content 3",
"count": 3
} }
]
で、以下な感じで、json ファイルを index 化できた
create jsonArray indexer
AZURE_DOCUMENTINTELLIGENCE_RESOURCE_GROUP = os.getenv("AZURE_DOCUMENTINTELLIGENCE_RESOURCE_GROUP")
AZURE_SEARCH_SERVICE = os.getenv("AZURE_SEARCH_SERVICE")
AZURE_STORAGE_ACCOUNT = os.getenv("AZURE_STORAGE_ACCOUNT")
AZURE_SUBSCRIPTION_ID = os.getenv("AZURE_SUBSCRIPTION_ID")
# Azure Cognitive Searchの設定
index_name = "json_index"
indexer_name = "json_indexer"
datasource_name = "json_datasource"
search_endpoint = f"https://{AZURE_SEARCH_SERVICE}.search.windows.net"
container_name = "content"
connection_string = f"ResourceId=/subscriptions/{AZURE_SUBSCRIPTION_ID}/resourceGroups/{AZURE_DOCUMENTINTELLIGENCE_RESOURCE_GROUP}/providers/Microsoft.Storage/storageAccounts/{AZURE_STORAGE_ACCOUNT}"
# インデックスの定義
credential = DefaultAzureCredential()
index_client = SearchIndexClient(endpoint=search_endpoint, credential=credential)
indexer_client = SearchIndexerClient(endpoint=search_endpoint, credential=credential)
fields = [
SimpleField(name="id", type=SearchFieldDataType.String, key=True),
SearchableField(name="filePath", type=SearchFieldDataType.String, retrievable=True),
SearchableField(name="fileName", type=SearchFieldDataType.String, retrievable=True),
SearchableField(name="title", type=SearchFieldDataType.String),
SearchableField(name="text", type=SearchFieldDataType.String),
SearchableField(name="count", type=SearchFieldDataType.Int64),
]
index = SearchIndex(name=index_name, fields=fields)
# データソースの定義
data_source_connection = SearchIndexerDataSourceConnection(
name=datasource_name,
type="azureblob",
container=SearchIndexerDataContainer(name=container_name),
connection_string=connection_string,
)
from azure.search.documents.indexes.models import (
FieldMapping,
SearchIndexer,
SearchIndexerDataContainer,
SearchIndexerDataSourceConnection,
)
indexer = SearchIndexer(
name=indexer_name,
data_source_name=data_source_connection.name,
target_index_name=index_name,
parameters={
"configuration": {
"dataToExtract": "contentAndMetadata",
"parsingMode": "jsonArray",
}
},
field_mappings=[
FieldMapping(source_field_name="/id", target_field_name="id"),
FieldMapping(source_field_name="/metadata_storage_path", target_field_name="filePath"),
FieldMapping(source_field_name="/metadata_storage_name", target_field_name="fileName"),
FieldMapping(source_field_name="/title", target_field_name="title"),
FieldMapping(source_field_name="/values/text", target_field_name="text"),
FieldMapping(source_field_name="/values/count", target_field_name="count"),
],
)
# クライアントの作成とインデクサーの実行
index_client.delete_index(index)
index_client.create_or_update_index(index)
indexer_client.create_or_update_data_source_connection(data_source_connection)
indexer_client.create_or_update_indexer(indexer)
indexer_client.reset_indexer(indexer.name)
indexer_client.run_indexer(indexer.name)
-
metadata_storage_pathの記載は、"/" や、"/document" は無くても動いたりするが、省略して反応しない部分もあるので、なるべくちゃんと書いた方がいいかも? -
同一 key の json 要素があった場合、2つ目以降は無視してそう。ただ、パスの上位からっぽいが、同一階層の場合、名前降順?
-
key が無いとエラーになるが、それ以外は無ければ取得しないだけ
-
metadata_* に関しては、以下参照
あとがき
次は、スキルセットの確認と、画像認識等のを試したいところ
にしても、indexer の内部動作ってどうやるのかが悩ましい