背景
Curl アプリを自動化しようとした。
で、当初 OCR を使って、テキスト認識で入力自動化しようとしたが、上手く動かなかったので、
諦めて 画像認識で対処した。
が・・ふと「半角空白が日本語文字の間にある」ことを思い出したので備忘録
結論
Windows OCR で 日本語認識する場合、文字と文字の間に半角空白が挿入される。
よって、「検索するテキスト」 には、半角空白を挟んでいかないと見つからない
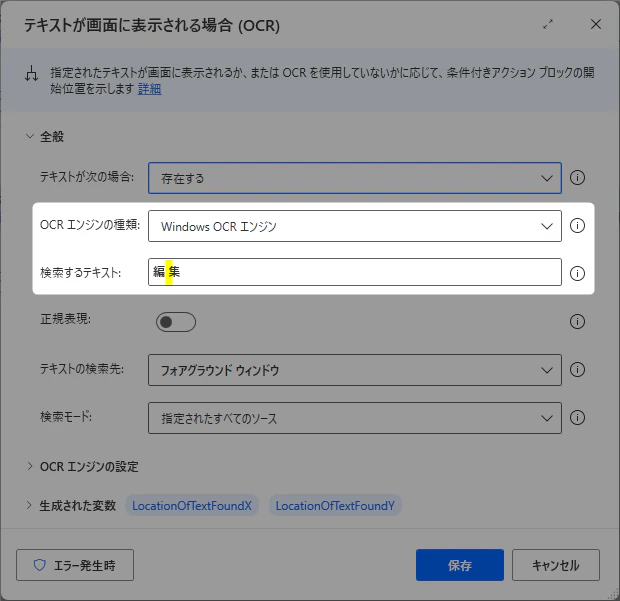
テキスト抽出して再利用する場合は、Trim() すればいいので気付きやすいが、以下二つの場合は、テキスト検索なので気付かないことが多い・・ ![]()
実際の認識
以下を認識させると、

こんな感じで、一文字ずつ、半角空白 を挟んでくる・・
ー 織 ー shlmakuma (default) 方 イ ル 編 集 デ バ ッ グ ッ - ル 表 示 ヘ ル プ
① こ の フ ロ - で power Fx ( プ レ ビ ュ - ) を 用 で き ま す 。 讎 細 情 毆
テキスト認識が駄目な場合の対処
画像取得をして、以下で認識させれば、検出座標からの操作って意味ではほぼ同じ。
ただ、相対座標操作が結構面倒なので、図でイメージしないと操作しにくい ![]()
あとがき
これらのおかげで、基本どんなアプリでも自動化可能なのは助かる。
会社のアプリはいつも糞UXで困る ![]()