本記事は「DMMグループ '20卒内定者 Advent Calendar 2019」24日目の記事です。
忙しい人向け
- その昔、水族館のウニを栗と入れ替える企画があった。
- 子供は気がつくが、大人は気がつかないという結果に。
- 機械学習はどんな反応をするのだろう?
- ウニと栗をCNNで学習。作成した学習器に入力として
水の中に入っている栗を与え検証。 - ウニ、栗 平均予測精度は約
mAP=80%を記録。肝心の水の中の栗は... - https://github.com/baibai25/chestnut-seaurchin-classifier
背景
とある日の研究室
御学友「水族館のウニと栗を入れ替えて、気がつくかどうかという実験があったんだよね。それ、機械学習でやったら面白そうじゃない?」
私「........ は?」
水族館のウニを栗と入れ替える
その昔、TV番組で「水族館の水槽にウニの代わりに栗が入っていても気付かない説」という検証が行われました。水族館の開園から閉園まで、誰にも栗だと気が付かれなければ立証できるという企画だったようです。1 2
興味深いのが検証結果です。大人が気が付かずにスルーするなか、多くの子供が栗だと気がついたそうです。子供は「栗」という物の本質のみを見ていたのに対し、大人は常識や環境といった追加情報から、誤った推論をしたと考えられます。
AIはどんな反応をするのだろう?
大人でも間違ってしまうウニと栗。では、ウニと栗を機械学習で学習させたら、水の中に入った栗を正しく予測することができるのでしょうか。正しく予測できれば、AIは子供と同じく、物の本質や特徴を理解できたと言えます。誤った予測をしても、環境情報(色情報や背景等)が原因で大人と同じ推論をしたと言えます。
どちらの結果になろうとも、「AIは人間と同じ推論をした」という、いかにもメディアが好きそうな結果になるわけです!(分かりやすく伝えるために大げさに書いてます。)
手順
以下が今回実施した内容です。
- データ収集
- データ拡張
- ラベリング
- 学習
- テスト
データ収集
Google 画像検索でスクレイピングをしていきます。
import argparse
from google_images_download import google_images_download
def main():
# parser
parser = argparse.ArgumentParser()
parser.add_argument('-k', '--keywords', help='Set keywords: e.g. key A, key B, key C')
parser.add_argument('-l', '--limit', help='Number of images to download')
args = parser.parse_args()
# download images
response = google_images_download.googleimagesdownload() # class instantiation
# creating list of arguments
arguments = {
'keywords': args.keywords,
'limit': args.limit,
#'print_urls':True,
'chromedriver': '/usr/bin/chromedriver'
}
paths = response.download(arguments) # passing the arguments to the function
if __name__ == '__main__':
main()
"sea urchin", "chestnut tree", "栗", "栗の木"という検索語でデータを収集しました。トゲが付いていない物や、形が悪いもの等を手動で削除しウニ: 347枚, 栗: 200枚の画像を用意しました。
データ拡張
一般的に、物体検出の学習に必要な画像枚数の目安は以下の通りです。3
- 最低:1カテゴリに対して100枚
- 基準:1カテゴリ1000枚
- 推奨:1カテゴリ5000、10000枚
現状では心もとないので、画像拡張でデータのかさ増しを行います。今回はKerasのImageDataGeneratorを用いて、画像を左右反転、上下反転、回転させデータ数をウニ: 983枚, 栗: 765枚まで増やしました。
gen = ImageDataGenerator(
horizontal_flip=True,
vertical_flip=True,
rotation_range = 90
)
ラベリング
機械学習に必要不可欠な教師データの作成を行います。以下の画像のように、検出したい物体に対してBounding Boxを得ることが目標です。そのため、物体検出のラベルは検出したい物体が写っている座標となります。

人や、動物、車などはYOLOやOpenCV等、既存の学習済みモデルを用いれば簡単に検出することができます。しかし、現状、ウニと栗を検出するライブラリは存在しません(多分)。 したがって、ウニと栗を分類するためには自前で教師データを作成し、学習させる必要があります。
余談ですが、顔の表情を検出するためには、以下の画像のように、各ポイントを教師データにする必要があります。言い方を変えれば、何千、何万枚の顔画像に対して、これらのポイント(座標)を記録する必要があります。
ラベリングって大変!

YOLO
多くの物体検出の手法が提案されていますが、今回はYOLO (You only look once)4を使用しました。YOLOで学習するためのフォーマットは以下のようになっています。
[category number] [object center in X] [object center in Y] [object width in X] [object width in Y]
先程の犬の画像に対し、dog: 0, bicycle: 1, truck: 2というクラスを割り当てた場合、以下のような教師データを作成する必要があります。
0 0.289062 0.667535 0.255208 0.550347
1 0.449219 0.480903 0.585938 0.531250
2 0.759766 0.217882 0.277344 0.137153
ラベリングしていくよ
LabelImg5というGUIのラベリングツールを用いて、ラベルを付けていきます。

(.........何やってるんだろ私)
精神と体の痛みに耐えながら、おおよそ6時間程ですべての画像にラベルを付け終えました。1枚の画像に複数の物体があるため、ラベルの数はウニ: 1574枚, 栗: 1917枚*になりました。
*ウニのラベリングが凄く難しかったため、枚数が減ってしまいました。
*栗を先にラベリングしました。ウニは精神的に辛くて、雑になりました。無理。
学習
学習にはAlexeyAB/darknet6を使用しました。ドキュメントが細かく書かれているため、ここでは簡単に流れのみを説明します。
YOLOセットアップ
git clone https://github.com/AlexeyAB/darknet.git
cd darknet
make
wget https://pjreddie.com/media/files/darknet53.conv.74
必要に応じてMakefileを修正してください。今回は学習にGPUを、学習結果の表示にopencvを用いるため、GPU=1, OPENCV=1に変更しました。
学習の設定
データ
作成したデータ(画像と教師データ)を任意のディレクトリに移動します。以下のprocess.pyを実行しtrainingとvalidation用にデータを分けます。各画像データへのpathを記したtrain.txtとtest.txtが出力されます。
import glob, os
# Current directory
current_dir = os.path.dirname(os.path.abspath(__file__))
# Directory where the data will reside, relative to 'darknet.exe'
path_data = 'data/labeled_data/'
# Percentage of images to be used for the test set
percentage_test = 10;
# Create and/or truncate train.txt and test.txt
file_train = open('train.txt', 'w')
file_test = open('test.txt', 'w')
# Populate train.txt and test.txt
counter = 1
index_test = round(100 / percentage_test)
for pathAndFilename in glob.iglob(os.path.join(current_dir, "*.jpg")):
title, ext = os.path.splitext(os.path.basename(pathAndFilename))
if counter == index_test:
counter = 1
file_test.write(path_data + title + '.jpg' + "\n")
else:
file_train.write(path_data + title + '.jpg' + "\n")
counter = counter + 1
custom objectsの設定
ラベリングの際に説明した通り、今回は自ら学習をする必要があります。そのため、custom objectsの設定を行います。主に、3つのファイルを作成する必要があります。
-
/darknet/cfgに以下を作成foo.names: クラス名を定義foo.nameskuri uni -
foo.data: クラス数、必要ファィルへのpathを定義foo.dataclasses=2 train = data/labeled_data/train.txt valid = data/labeled_data/test.txt names = cfg/foo.names backup = data/backup -
foo.cfg: 学習パラメータの設定(yolov3.cfgをコピーし修正)
- classes=2
- filters=(classes + 5)x3
- その他、
batchやsubdivisions等、環境に応じて変更する - ドキュメントを参考に、学習環境に応じて変更してください
実行
./darknet detector train cfg/foo.data cfg/foo.cfg darknet53.conv.74 -map
結果
約7000 iteration時の結果です。
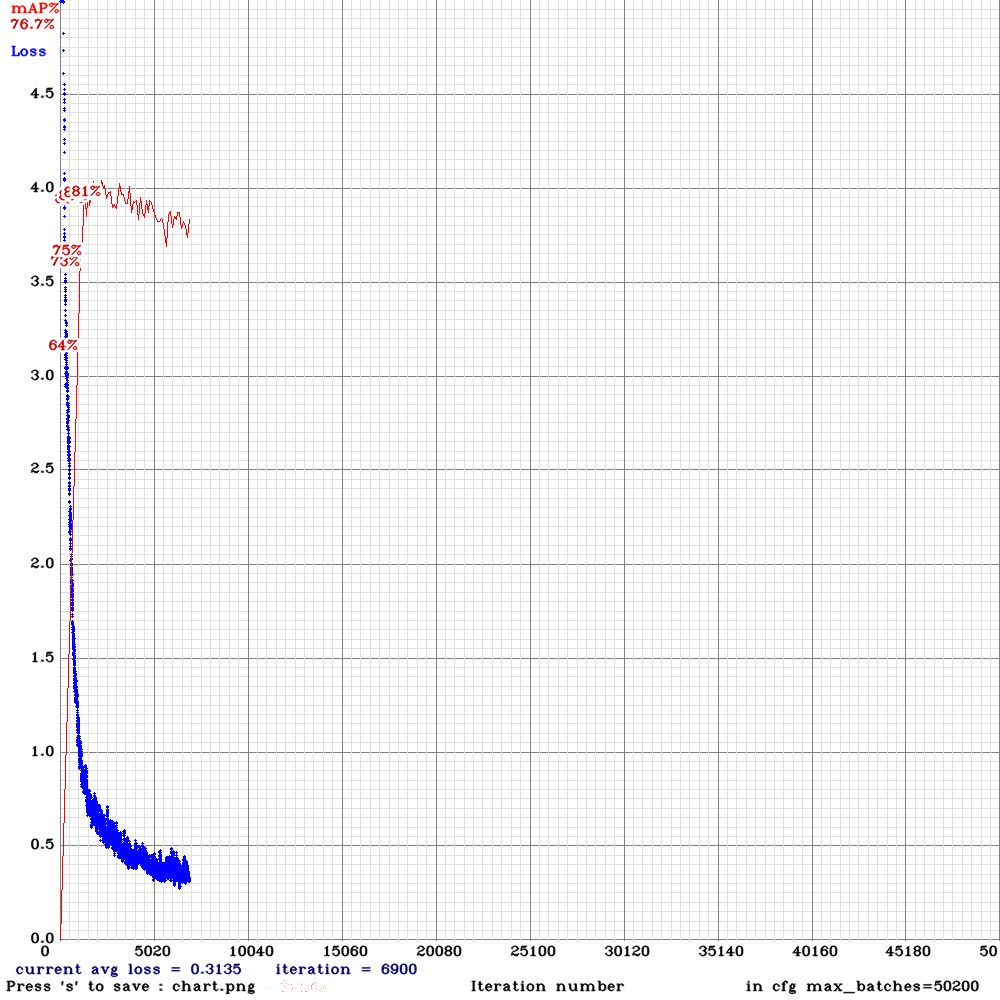
赤線がmAP(Mean Average Precision)、青線がlossを示しています。lossは下がり続けていますが、mAPが81%を記録してから徐々に低下していることから、過学習が発生していることが分かります。保存したweightをロードして詳細を確認していきます。
./darknet detector map cfg/foo.data cfg/foo.cfg data/backup/foo.weights
6000 iteration
detections_count = 771, unique_truth_count = 350
class_id = 0, name = kuri, ap = 70.03% (TP = 144, FP = 57)
class_id = 1, name = uni, ap = 81.51% (TP = 108, FP = 31)
for conf_thresh = 0.25, precision = 0.74, recall = 0.72, F1-score = 0.73
for conf_thresh = 0.25, TP = 252, FP = 88, FN = 98, average IoU = 57.06 %
IoU threshold = 50 %, used Area-Under-Curve for each unique Recall
mean average precision (mAP@0.50) = 0.757670, or 75.77 %
Best iteration
detections_count = 1247, unique_truth_count = 350
class_id = 0, name = kuri, ap = 76.59% (TP = 159, FP = 86)
class_id = 1, name = uni, ap = 85.10% (TP = 120, FP = 34)
for conf_thresh = 0.25, precision = 0.70, recall = 0.80, F1-score = 0.74
for conf_thresh = 0.25, TP = 279, FP = 120, FN = 71, average IoU = 52.86 %
IoU threshold = 50 %, used Area-Under-Curve for each unique Recall
mean average precision (mAP@0.50) = 0.808458, or 80.85 %
考察
Best iterationを見るとmAP=80.85%です。各クラスの精度を見ると栗: ap=76.59%, ウニ: ap=85.10%です。栗のデータ数の方が多いのにも関わらず、精度は80%を下回りました。考えられる原因としては、データが挙げられます。
栗のデータセットの傾向として、以下のような類似した画像が多く見受けられました。
- 同じような形
- 同じような画像サイズ
- 同じような色
類似した特徴量だけでは汎化性能が低下してしまいます。そのため、精度向上にはデータ収集・選定の改善が必要です。対象的に、ウニの予測精度は良好な結果となりました。ウニのデータは栗とは対象的に、
- 低解像度から高解像度まで、様々なサイズの画像がある
- 背景が海中 or 陸
- ウニの種類、成長段階によって色が異なる
といった、多種多様な画像が見受けられました。
また、Background ClutterやMotion Blurといった、物体検出・トラッキングにおける問題点等の影響も考えられます。
パラメータの変更
テストデータの割合を10%から30%に変更し、max_batches=6000, steps=4800,5400で再度学習しました。
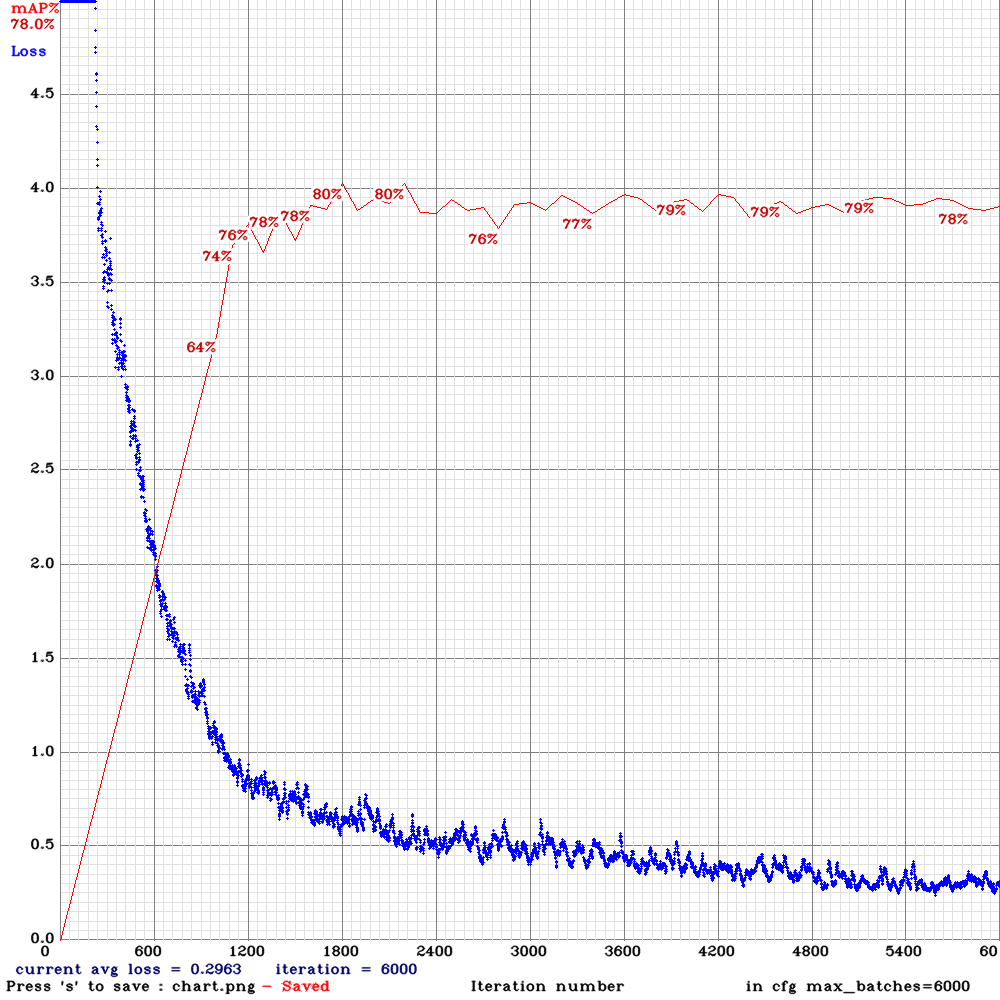
detections_count = 4697, unique_truth_count = 1134
class_id = 0, name = kuri, ap = 76.46% (TP = 467, FP = 250)
class_id = 1, name = uni, ap = 84.45% (TP = 486, FP = 246)
for conf_thresh = 0.25, precision = 0.66, recall = 0.84, F1-score = 0.74
for conf_thresh = 0.25, TP = 953, FP = 496, FN = 181, average IoU = 48.65 %
IoU threshold = 50 %, used Area-Under-Curve for each unique Recall
mean average precision (mAP@0.50) = 0.804545, or 80.45 %
特に大きな変化はありませんが、検出数を示すdetections_countが1247から4697と、大幅に増えました。テストデータを増やしたため、汎化性能が向上したと考えられます。
(画像左: テストデータ10%, 画像右: テストデータ30%)

本題
ウニと栗の分類器の作成は終わりました。ここからが本題です。水の中の栗を入力したら、一体全体、どのような結果になるのでしょうか?
トゲトゲのままの栗を探しに行く
検証に使うデータとしては、栗の中身が見えず、完全にトゲトゲな状態の栗を使うことが理想です。
よし!探しに行くぞ!!!!.....................
12月 東北は雪だった
電子の海で見つけた画像で試す
 ネットの海は広大ですね... 本当にありがたい...[^7]
それでは、この画像でテストをしていきます。結果は...
ネットの海は広大ですね... 本当にありがたい...[^7]
それでは、この画像でテストをしていきます。結果は...
uni: 100%, uni: 31%, kuri: 92%

栗が31%の確率でウニと判定されていますが、ちゃんと検出できています!
やったね!
募集
テストデータが1枚では検証が不十分です。そのため、本プロジェクトを遂行するために協力してくださる方を募集しております。内容は以下の通りです。
- 水の中に入っている栗の画像を送ってくれる方
- 可能な限り、栗はトゲトゲにまとわれており、ウニらしい凛々しい栗であること
- 報酬
- Special Thanksにお名前を掲載いたします
- それ以外、何もありません
まとめ
- 世界一無駄な検出器を作成することができた
- ウニも栗も、機械学習で分類するものではない
- どちらも見た目は同じ
- おいしい
∴ ウニと栗は本質的に同じ

Special Thanks
記事の最後に、本プロジェクトに貢献してくださった皆様に感謝申し上げます。
kuziomi: アイディアの提案、Object Detectionに関するアドバイス
atomiyama: 記事構成、タイトルに関するアドバイス
GitHub
-
水族館のウニは栗と入れ替えても全然気づかれないことが判明, http://netgeek.biz/archives/61307 ↩
-
【検証】水族館でウニの代わりに栗を入れてもバレないのか, https://twicolle-plus.com/articles/5354 ↩
-
【物体検出】vol.3 :YOLOv3の独自モデル学習の勘所, https://www.nakasha.co.jp/future/ai/yolov3train.html ↩
-
YOLO: Real-Time Object Detection, https://pjreddie.com/darknet/yolo/ ↩
-
tzutalin/labelImg, https://github.com/tzutalin/labelImg ↩
-
AlexeyAB/darknet, https://github.com/AlexeyAB/darknet ↩