簡単に言うと
- YouTube Liveのチャット(コメント)を分析したよ
- どの配信においても、TOPの頻出語は一定の傾向があったよ
- ついでに、コメントの出現率や関係性をプロットしたら、概ね配信の概要が分かる図ができたよ
- 技術に興味ない人、結果だけを知りたい人は背景と結果だけ見てね
背景
とある日の私
いつも通り配信を見ながら作業をする。
今日も面白いなーと思いながら、作業の片手間にコメントをする。
「こんにちは」
「草」
「すごい!」
「それは草」
「草」
「お疲れ様でした」
あれ?私、語彙力低くない?
てか、視聴者(オタク)の皆んなも語彙力死んでない?
よし!自然言語処理でオタクの語彙力を検証してみよう!
(訳: よし!コメントを分析して視聴者の語彙力を検証してみよう!)
手順
- データ収集
- 形態素解析
- 共起ネットワーク
データ収集
それでは、データを集めていきます。今回ターゲットとするのは、以下の条件を満たしているYouTubeの動画です。
- YouTube Live(生放送)のアーカイブ or プレミア公開のアーカイブ
- チャットのリプレイがオンになっているアーカイブ (アーカイブでチャットが見れる動画)
通常のコメントや、生放送のコメントの取得はYouTube APIを用いれば簡単に取得することができます。しかし、生放送アーカイブのチャットコメントの取得はAPIでサポートされていません。したがって、スクレイピングを行い、コメントを取得していきます。
Scraping
いくつかの記事を参考に、コードを書きました。ここでは、躓いたことを紹介したいと思います。
ネストが深い
スクレイピングをして、チャットコメントのみを抜き出すのが本当に面倒です。ちなみに、以下でコメントを取得することができます。(一部抜粋)
dics['continuationContents']['liveChatContinuation']['actions'][1:]['replayChatItemAction']['actions'][0]['addChatItemAction']['item']['liveChatTextMessageRenderer']['message']['runs'][0]['text']
これは面倒!それに加えて、コメント数十件ごとにURLが異なります。
for samp in dics['continuationContents']['liveChatContinuation']['actions'][1:]:
# Normal comment
try:
comment_path = samp['replayChatItemAction']['actions'][0]['addChatItemAction']['item']
comment_path = str(comment_path['liveChatTextMessageRenderer']['message']['runs'][0]['text'])+'\n'
comment_data.append(comment_path)
except:
pass
# Super Chat comment
try:
comment_path = samp['replayChatItemAction']['actions'][0]['addLiveChatTickerItemAction']['item']
comment_path = comment_path['liveChatTickerPaidMessageItemRenderer']['showItemEndpoint']['showLiveChatItemEndpoint']
comment_path = str(comment_path['renderer']['liveChatPaidMessageRenderer']['message']['runs'][0]['text'])+'\n'
comment_data.append(comment_path)
except:
pass
形態素解析
取得したコメントに対し、形態素解析を行います。形態素解析及び、一般的な前処理については説明を省略します。
数値の処理
数値を全て0に置き換えました。実際に形態素解析を行うと分かりますが、形態素に分けられた数値の多くは、あまり重要な意味を持ちません。
例えば、baibai25さんが2434円スパチャしました。という文章を見てみます。
-
baibai2525には、数値としての意味はありません。ただのユーザ名です。 -
2434円今回の目的は形態素をカウントし、使用された言葉の統計を見ることです。2434円をカウントするよりも、0+円という文字列をカウントする方が妥当に思われます。
以上から、数値を置き換え、語彙数を削減しています。
流行り言葉・造語の処理
流行りの言葉や、造語、人名などは辞書に登録されていません。そのため、通常の辞書を用いて形態素解析を行うと、誤った結果となります。以下に例題を示します。
こんでろーん
こん 動詞,自立,*,*,五段・マ行,連用タ接続,こむ,コン,コン
で 助詞,接続助詞,*,*,*,*,で,デ,デ
ろ 名詞,一般,*,*,*,*,ろ,ロ,ロ
ー 名詞,一般,*,*,*,*,ー,*,*
ん 助動詞,*,*,*,不変化型,基本形,ん,ン,ン
--------------------------------------------------
タピる
タピ 名詞,一般,*,*,*,*,タピ,*,*
る 助動詞,*,*,*,文語・ル,基本形,る,ル,ル
--------------------------------------------------
リージョン
リー 名詞,固有名詞,人名,姓,*,*,リー,リー,リー
ジョン 名詞,固有名詞,人名,名,*,*,ジョン,ジョン,ジョン
- 「こんでろーん」は、私の推し、樋口楓さんが使用するあいさつです。
- 「タピる」は説明するまでも無いでしょう。クソ甘いゴムを食べる行為です。
- 「リージョン」はゲーム、Dead by Daylightに登場するキャラクターの名前です。
いずれも、辞書に登録されていないため、誤った形態素に分割されてしまいます。
そのため、使用する辞書に加え、カスタム辞書を作成しました。
Custom Dictionary
本プロジェクトでは、日本語の形態素解析器にJanomeを使用しました。採用理由は、公式HPのキャラクターが可愛かったからです。Janomeは内包辞書として、MeCabを使用しています。MeCabのドキュメントに従い、単語を追加していきます。
こんでろーん,-1,-1,10,名詞,*,*,*,*,*,こんでろーん,コンデローン,コンデローン
おつでろーん,-1,-1,10,名詞,*,*,*,*,*,おつでろーん,オツデローン,オツデローン
タピる,-1,-1,10,名詞,*,*,*,*,*,タピる,タピル,タピル
スパチャ,-1,-1,10,名詞,*,*,*,*,*,スパチャ,スパチャ,スパチャ
リージョン,-1,-1,10,名詞,*,*,*,*,*,リージョン,リージョン,リージョン
上記で作成したデータを読み込み、形態素解析を行いました。最終的には、下記のようなグラフを得ることができます。
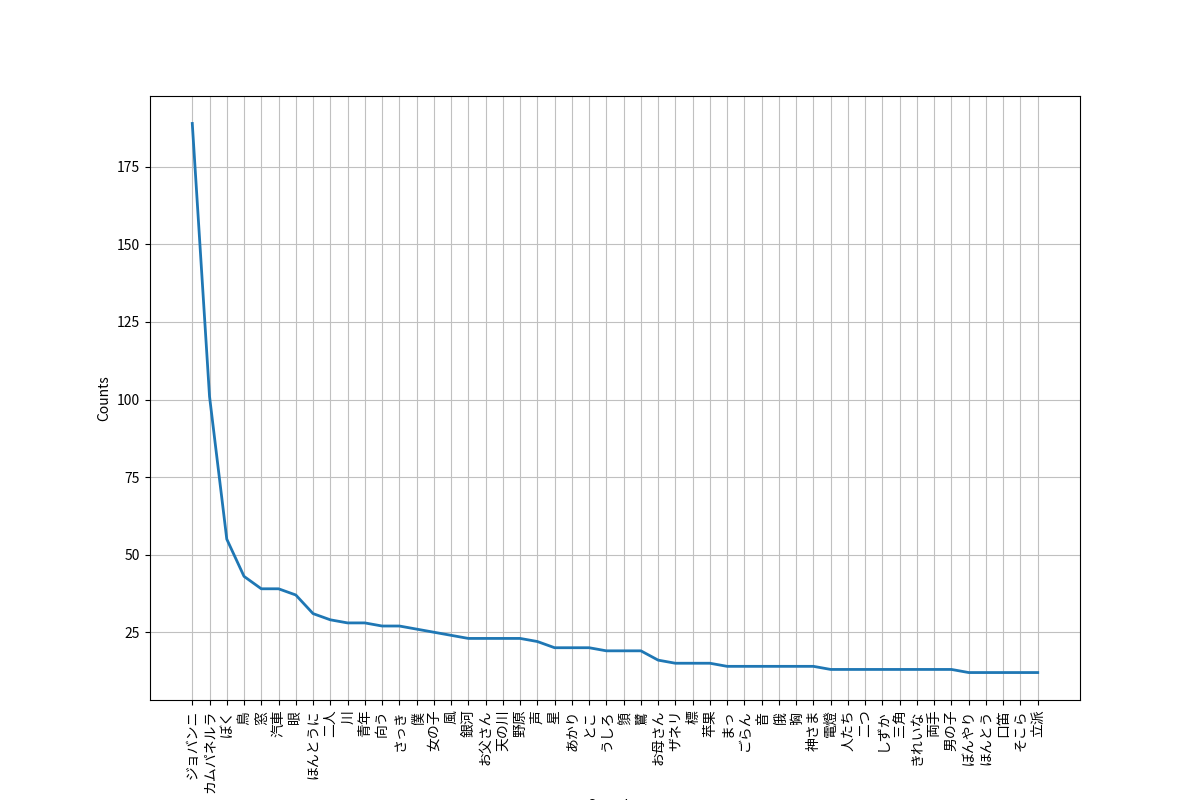
その他
- 解析精度を上げるために、新語や固有表現に強いと言われる
NEologd辞書を使用 - ひらがな一文字に分割された形態素を除外
- 英語と中国語にも対応
- 中国語も同様にカスタム辞書を作成
共起ネットワーク
コメントから、配信内における単語の出現数と出現パターン(距離)を可視化します。
流れ
- 形態素解析で得た単語リストから、単語の組み合わせを作成
- 単語間の重みを計算
- 共起ネットワークを作成
 Image: https://www.dskomei.com/entry/2019/04/07/021028
Image: https://www.dskomei.com/entry/2019/04/07/021028
単語の組み合わせを作成
出現した単語のペアを作成します。
| word1 | word2 | intersection_count | count1 | count2 |
|---|---|---|---|---|
| 午后 | 授業 | 1 | 2 | 2 |
| 午后 | 仕事 | 1 | 2 | 1 |
| ふう | 川 | 1 | 2 | 28 |
| ふう | ジョバンニ | 1 | 2 | 189 |
| 川 | われ | 1 | 28 | 3 |
単語間の重みの計算
重みを計算し、単語間の関係性の強さを求めていきます。今回はJaccard index
を使用します。
J(A, B) = \frac{|A\cap B|}{|A\cup B|} = \frac{|A\cap B|}{|A|+|B|-|A\cap B|}
| word1 | word2 | intersection_count | count1 | count2 | union_count | jaccard_coefficient |
|---|---|---|---|---|---|---|
| 午后 | 授業 | 1 | 2 | 2 | 3 | 0.333333 |
| 午后 | 仕事 | 1 | 2 | 1 | 2 | 0.500000 |
| ふう | 川 | 1 | 2 | 28 | 29 | 0.034483 |
| ふう | ジョバンニ | 1 | 2 | 189 | 190 | 0.005263 |
| 川 | われ | 1 | 28 | 3 | 30 | 0.033333 |
プロット
閾値(単語の出現回数とJaccard index)を設定しプロットします。
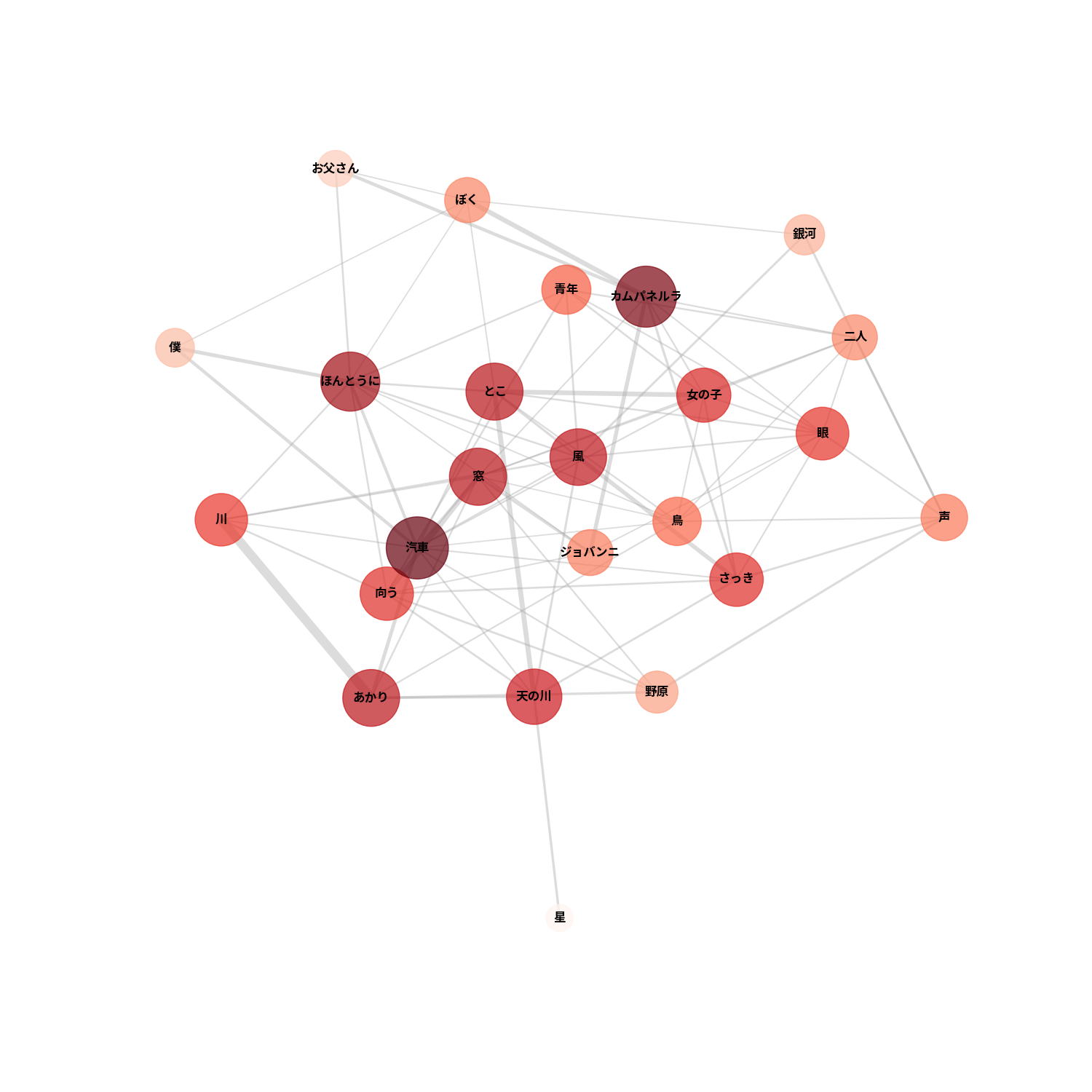
閾値を変え、詳細を見ていきます。
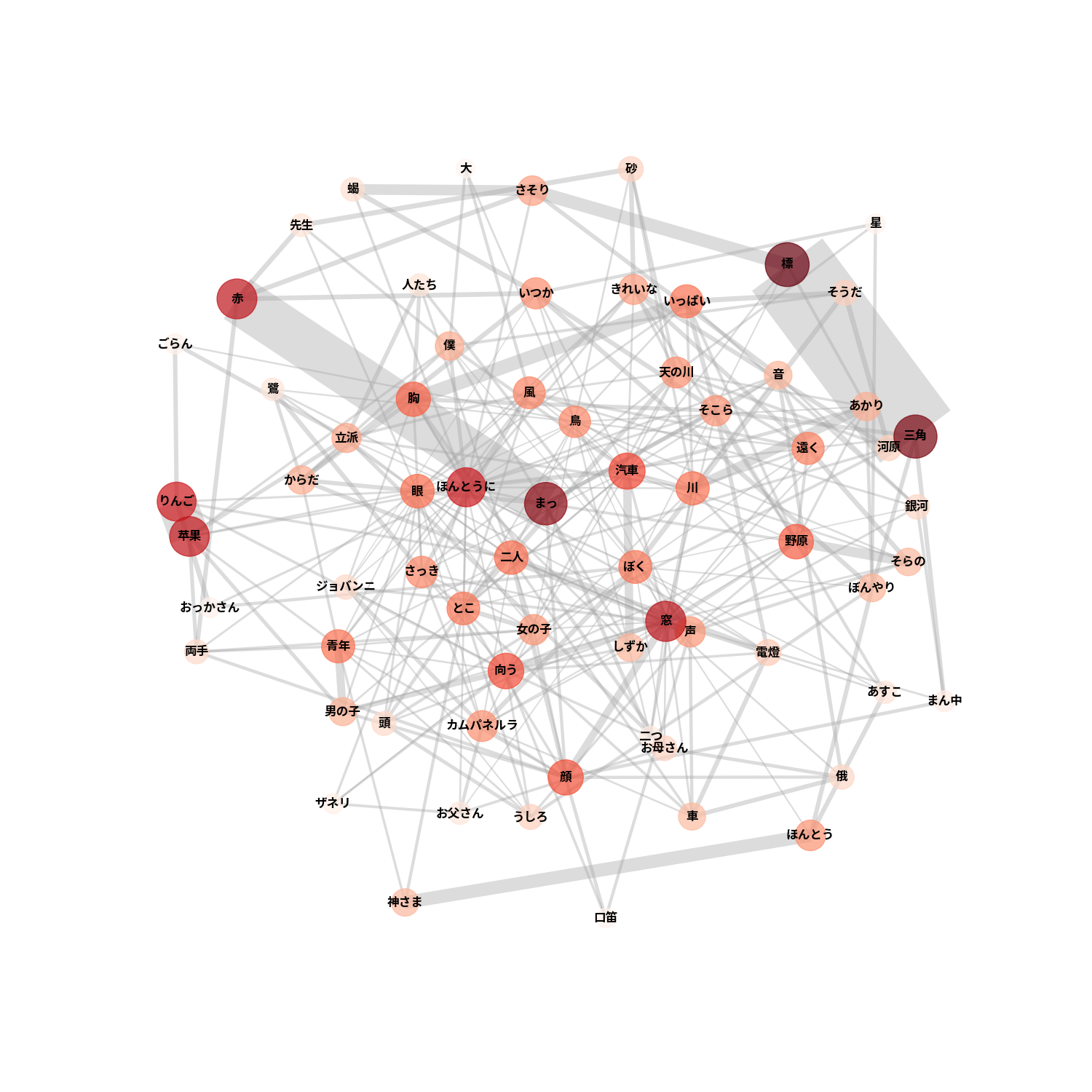
何の作品か分かりましたか?宮沢賢治の銀河鉄道の夜でした!
分析結果
検証結果を見ていきます。実験内容の都合上、主観的な評価が多くなってしまいます。そのため、複数人の有識者(オタク)で結果の考察を行いました。考察した中から、3件ご紹介したいと思います。画像が見づらい場合はクリックをして見てください。
シカになります。【deeeer simulator】
1つ目は、樋口楓さんのDEEEER Simulatorプレイ配信です。総コメント数は4017件です。
【deeeer simulator】シカになります。【シカゲー】 https://t.co/XLZbJokpXU @YouTubeさんから
— 樋口楓🍁にじさんじ所属 (@HiguchiKaede) January 21, 2020
帰宅!!40分からシカになるます!!!
頻出単語TOP50
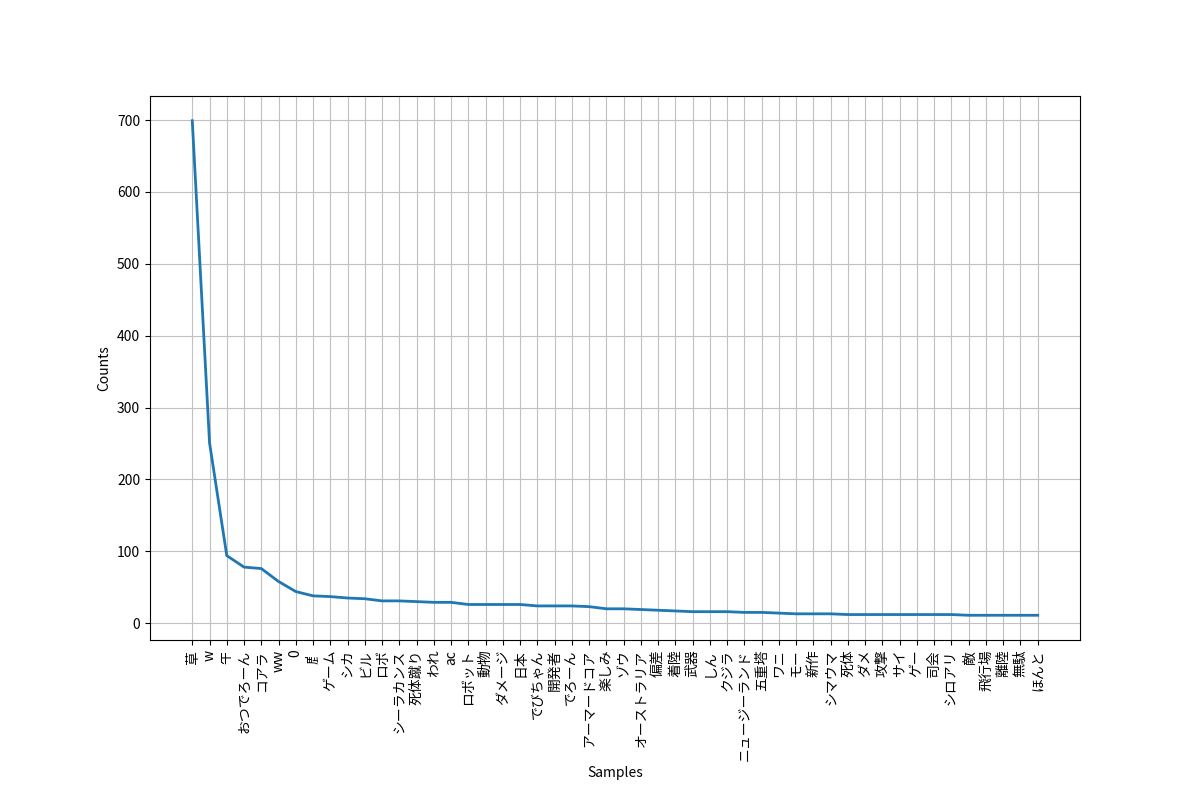 圧倒的`草`です。3位以降を見ていくと、`でろーん`や`おつでろーん`といった造語、`シカ`、`コアラ`、`アーマードコア`といった、ゲームに関連するワードが多く見受けられます。
圧倒的`草`です。3位以降を見ていくと、`でろーん`や`おつでろーん`といった造語、`シカ`、`コアラ`、`アーマードコア`といった、ゲームに関連するワードが多く見受けられます。
共起ネットワーク
出現パターンが似ている単語を線で結び、単語間の関係性を図にしました。ノード(円)の大きさと色、線の太さは、単語間の関係性の強さを表しています。分析の都合上、数値は全て0に置き換えています。
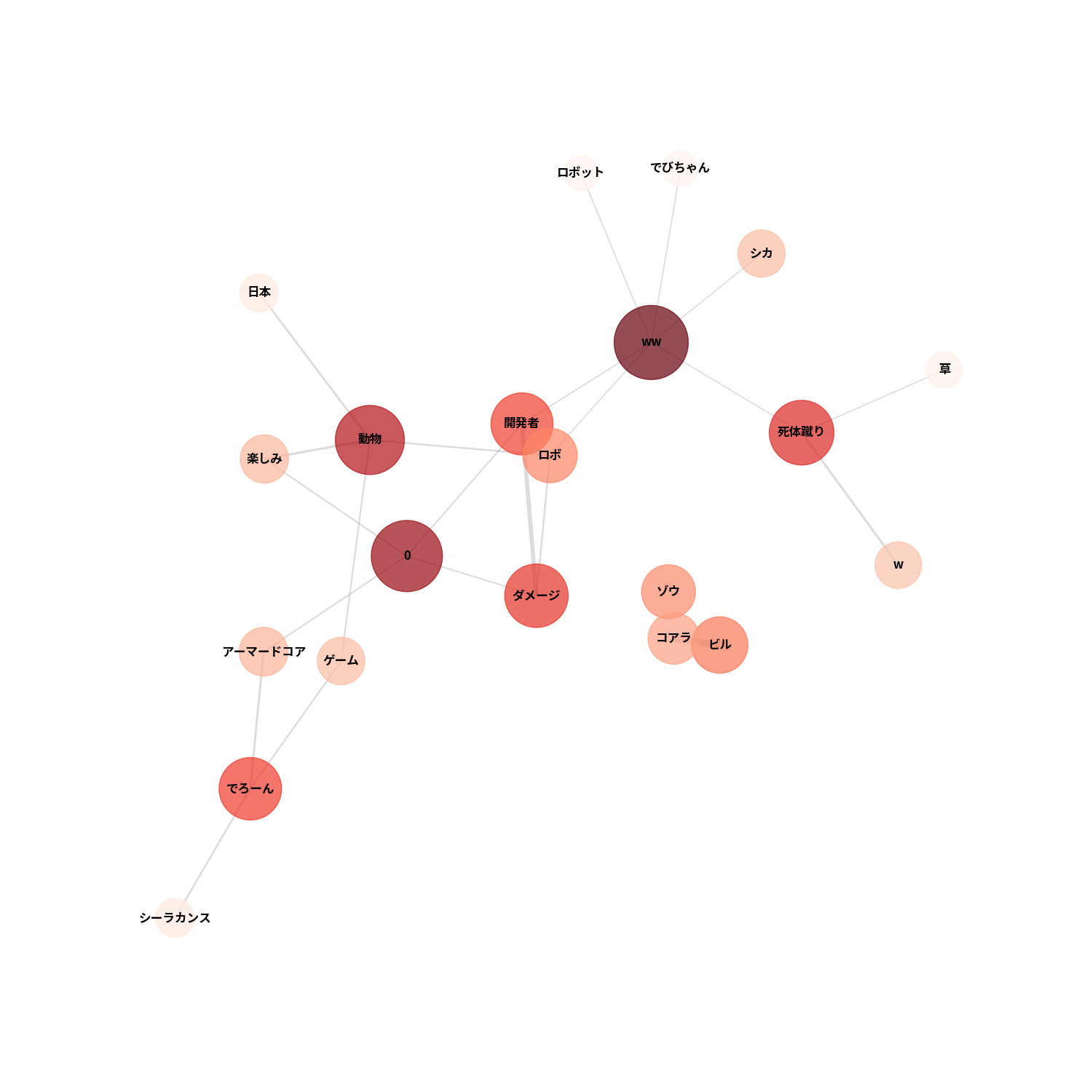
単語出現数上位だった草とwを見てみましょう。どうやら、死体蹴りという単語と共に使われたようです。画像の上部では動物という単語の色が濃くなっています。DEEEER Simulatorでは多くの動物が登場する他、動物を組み合わせたロボットも登場します。そのため、動物という単語が、他の単語と共に多く使われていたと考えることができます。実際にチャットデータを見ると、そのような文章が多くありました。
さて、パラメータを変えてもう少し詳しく見ていきましょう。
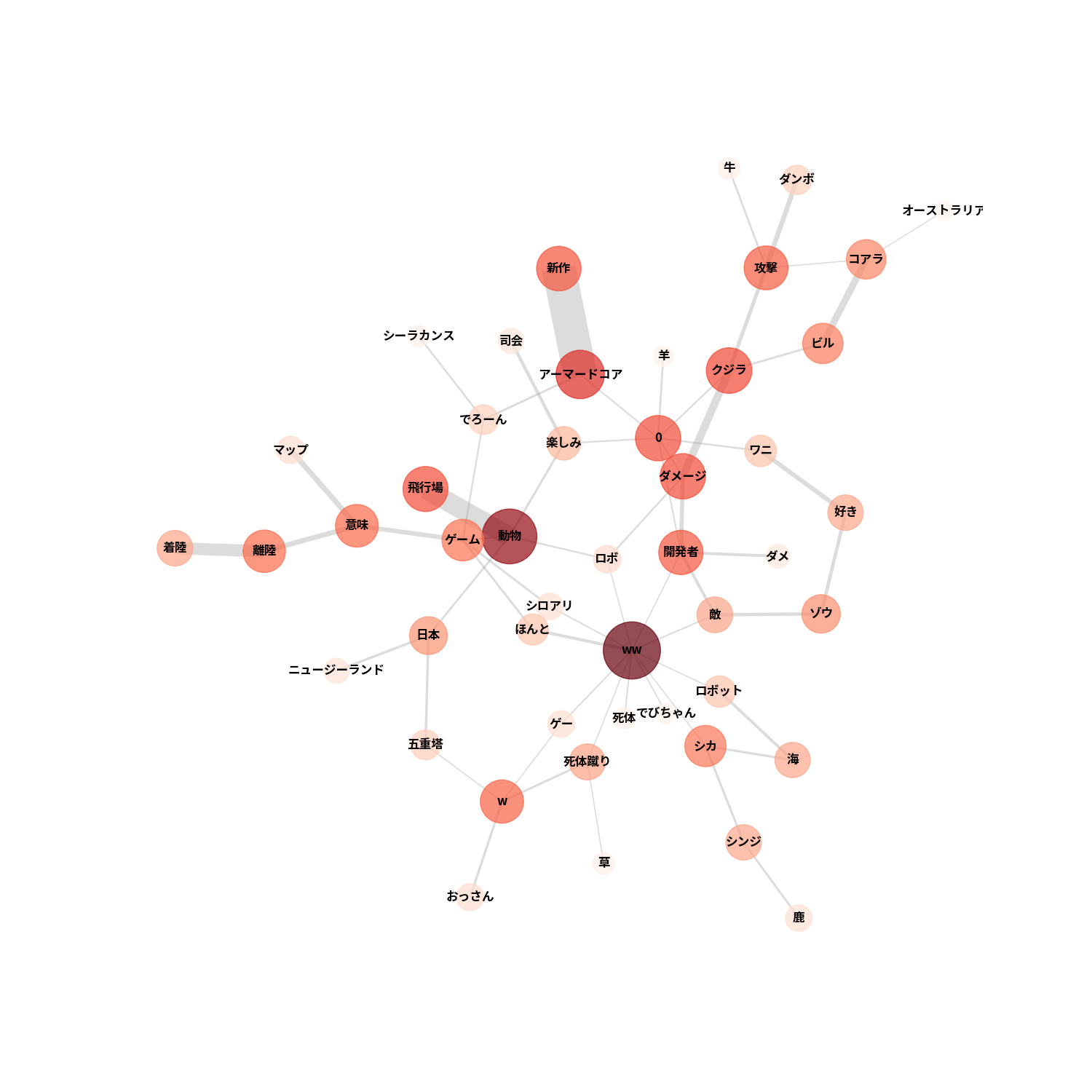
先程の図では登場しなかった単語が登場し、より詳細な繋がりが分かります。線の太さを見ると新作, アーマードコアや、動物, 飛行場、コアラ, ビル等、より詳細にDEEEER Simulatorの世界を説明できているように感じます。
【閲覧注意】健屋を喜ばせろ!第一回嘔吐プレゼン大会【緑仙/健屋花那/夢追翔/でびでび・でびる/轟京子/郡道美玲】
2つ目です。嘔吐フェチである健屋花那さんを喜ばせるために、理想の嘔吐シチュエーションを考え、演技するという緑仙さんのチャンネルで行われた企画です。DEEEER Simulator(ゲーム実況)とは異なり、複数の配信者が雑談をしながら進行していく配信です。総コメント数は10501件です。
【配信告知】
— 緑仙🐼 (@midori_2434) December 18, 2019
19日23時より第一回嘔吐プレゼン大会を開催します。
「嘔吐」までの流れを健屋にプレゼンし、健屋が好きだったシチュエーションを決める健屋のための企画です。
⚠この企画は、不潔な表現が多々あります。自衛宜しくお願い致します。#嘔吐プレゼン
▼待機所https://t.co/bJCd8s0uwQ pic.twitter.com/G7uLl5iDCp
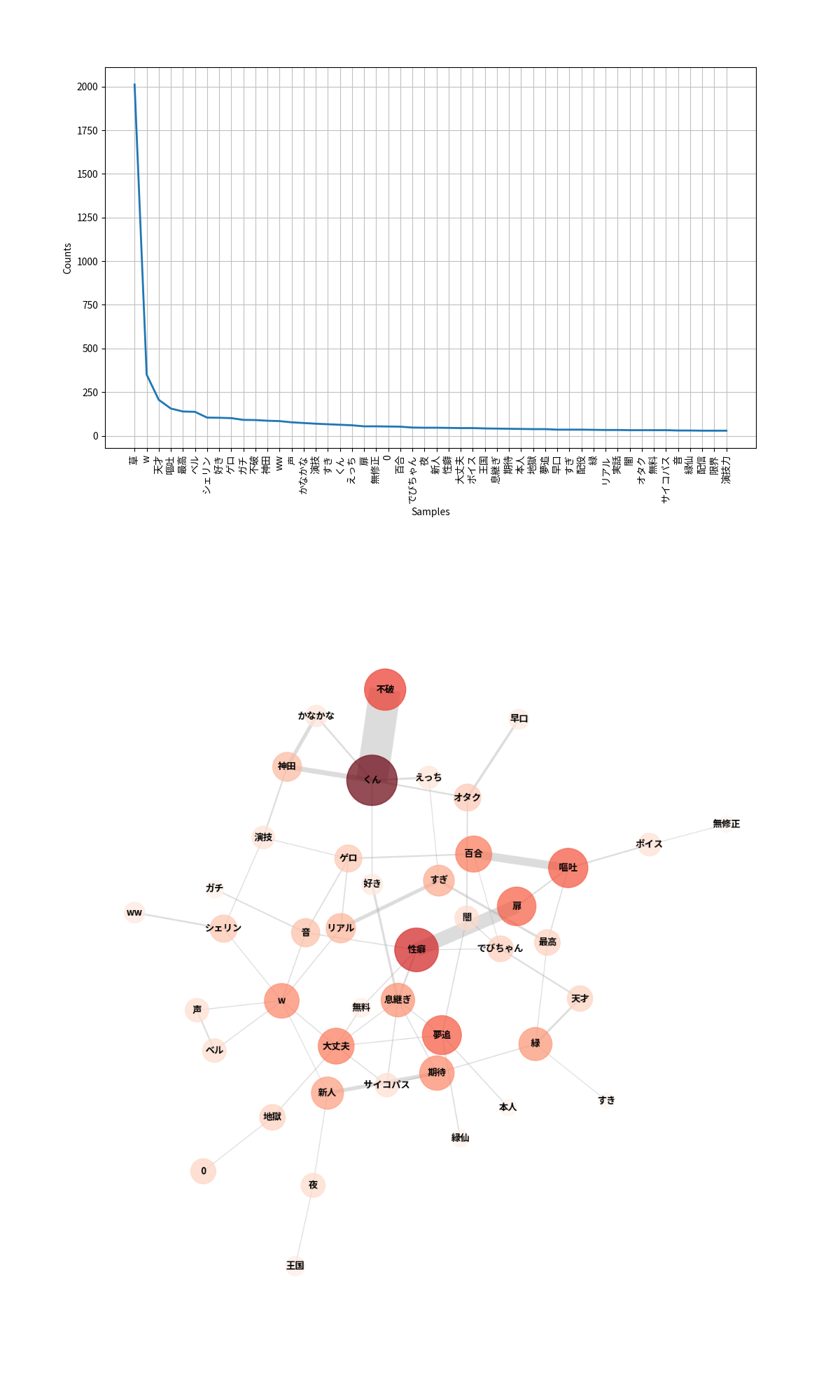
頻出単語TOP50
不動の1位と2位です。複数の配信者が登場するため、ベル(恐らくベルモンド)、シェリン、不破、神田といった人名が多く登場しています。
共起ネットワーク
頻出単語TOPに出てきた人名の多くがネットワーク上で確認できます。ネットワークの上部神田, かなかなはどちらも人名です。彼ら2人の共演に対し、多くのコメントがあったことが分かります。色の濃さとノードの大きさを見ると、性癖, 扉と嘔吐, 百合が目に付きます。
性癖, 扉については、両方のノードから繋がるでびちゃんの配信における挨拶「異界の扉が開かれた」に習い、「性癖の扉が開かれた」というコメントが多かったのでしょう。嘔吐, 百合については、竜胆尊さん、白雪巴さんが演じた百合嘔吐シチュエーションを示すものと考えられます。近くの関連ワードを見ると、最高やえっちとあることから、多くの視聴者の性癖の扉が開かれたことが予想できます。
【1周年記念&お披露目】新衣装で皆とお祝いしたいのだ!【夢月ロア】
最後は、夢月ロアさんの1周年記念&お披露目配信です。これまで解析した配信ではゲームであったり、やるテーマが決まっていました。そのため、分析結果は配信タイトルに強く関連していました。この配信は、1周年活動した感想や、新衣装の感想などを、配信者と視聴者が話しながら進める、完全な雑談配信になります。総コメント数は12794件です。
17日の22時はここで祝うのだ🌖
— 夢月ロア🌖 (@yuzuki_roa) January 16, 2020
新衣装で皆の前でるのどきどきするのだ…🙈
【1周年記念&お披露目】新衣装で皆とお祝いしたいのだ!【夢月ロア】 https://t.co/iSeTieGdBB @YouTubeより pic.twitter.com/g7YJglwIP4
この実験のみ、専用のプログラムを作り検証を行いました。理由としては、夢月ロアさんの口癖です。夢月ロアさんは、「うーん」や「えー」といった、いわゆる感動詞として「お!」や「お?」、「お!?」を使います。それに伴い、多くの視聴者もコメントで「お」というコメントをします。ひらがな1文字は意味のない言葉として除外してきましたが、今回だけは例外で「お」をカウントしています。
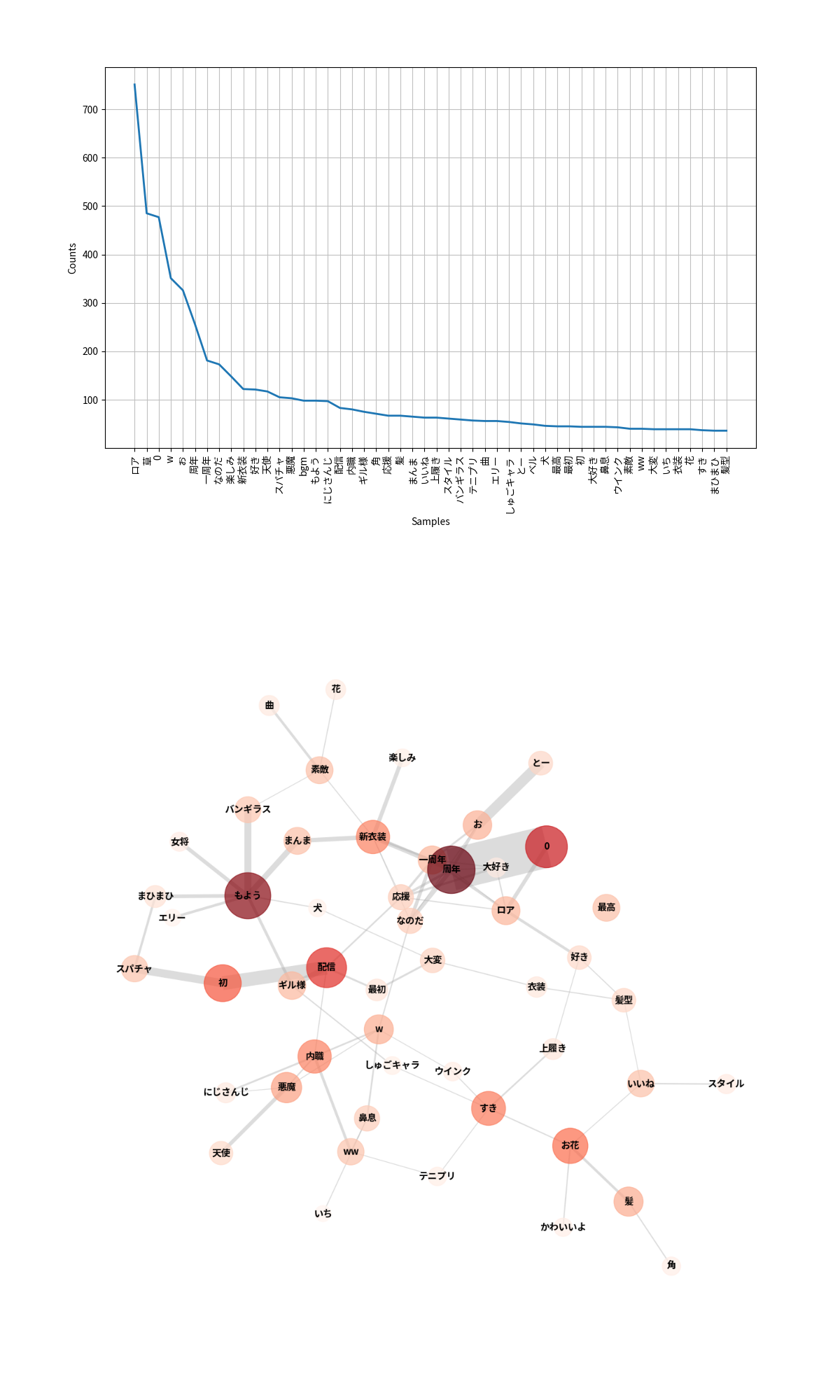
頻出単語TOP50
なんと草を抜き、ロアが1位を獲得しました。3位には0がランクインしています。上記でも説明したように、分析の都合上、数値は全て0に置き換えています。ネットワーク図を見ると分かりますが1周年という単語が起因しています。また、8位のなのだは夢月ロアさんの口癖です。これまでの分析結果とは異なり、視聴者がいかに配信者のことを応援しているかが分かります。
共起ネットワーク
頻出単語TOP50でも説明したように、周年, 0に強い結びつきがあることから、1周年というコメントが多かったことが予想できます。また、左下を見ると、バンギラス, まひまひ, エリー, 女将, ギル様といった同じ事務所に所属する方がコメントや、スーパーチャットをしたことが予測できます。これまでの分析では配信タイトルに関連した単語が多くコメントされる傾向にありましたが、配信者の口癖、同事務所の方の名前が出るなど、異なった結果を得ることができました。
- 技術に興味がある人向け
for line in data:
tmp = []
malist = t.tokenize(line)
for word in malist:
base, part = word.surface, word.part_of_speech
# extract Meishi ^ not stop word
if '名詞' in part and base not in stop_word:
hiragana = re_hiragana.fullmatch(base)
# Roa chan
if hiragana!=None and base=='お' or base=='お ' or base=='お ' or base=='お ':
base = 'お'
tmp.append(base)
tokens.append(base)
continue
# Hiragana (one character) or 'ー'
if hiragana!=None and len(hiragana[0])==1 or base=='ー':
continue
tmp.append(base)
tokens.append(base)
name.append(tmp)
多言語処理
多言語のコメントからなる配信も解析しました。行ったことは、以下の3点です。
- コメントの言語判定
- 日本語、英語、中国語の分析
- 可視化
言語知識が乏しいので、今回は日本語、英語、中国語の3カ国語のみ分析をしました。
【ホラー実況】シエラと一緒に「P.T.」【親子放送】
日本語、英語、中国語を流暢に話すOverideaのホラーゲーム配信です。総コメント数は4876件です。
シエラのホラーゲーム実況もうすぐ始まりますよ〜!😰😰😰😰
— シエラ(Cierra)🦋Overidea所属❄️ (@CierraRunis) July 8, 2018
み、見に来てくださいね!!!(震え声
my P.T. livestream with Overidea HQ is starting soon!!!!! aaaaaaaaaaaAAAAAAAA
LINK: https://t.co/RLud6V5BFx pic.twitter.com/OWW5iBzuPI

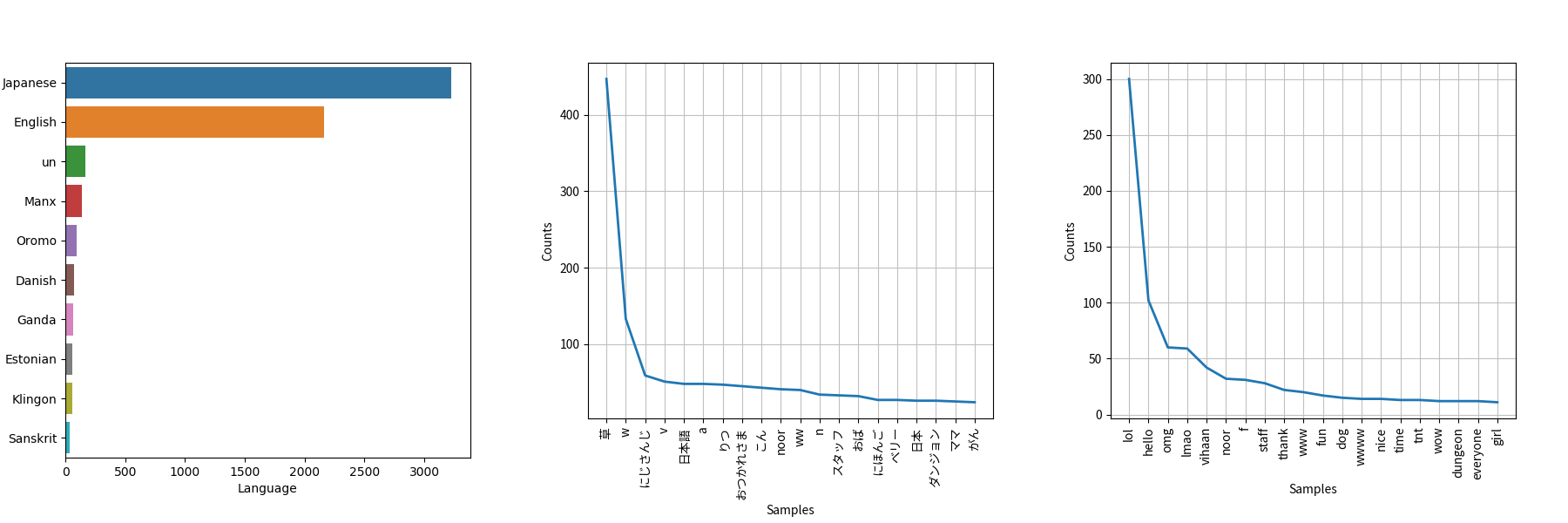
 コメントの言語を調べると、多い順に日本語、中国語、英語でした。多少の検出ミスはありましたが、概ね正しく言語を検出することができました。日本語と中国語の頻出度を見ると、共に配信者である`キョウカ, 京华`と`シエラ, 谢拉`がトップにランクインしています。また、中国語の`b站`(bilibili動画)や、英語の`lol, lmao`といったスラングなど、言語毎に特有の言葉が出現しています。
コメントの言語を調べると、多い順に日本語、中国語、英語でした。多少の検出ミスはありましたが、概ね正しく言語を検出することができました。日本語と中国語の頻出度を見ると、共に配信者である`キョウカ, 京华`と`シエラ, 谢拉`がトップにランクインしています。また、中国語の`b站`(bilibili動画)や、英語の`lol, lmao`といったスラングなど、言語毎に特有の言葉が出現しています。
【#NIJISANJI_Day】Relay Streaming! 【NIJISANJI IN】
日本、韓国、中国、インドネシア、インドの5ヶ国からなる、大規模コラボ配信のインド視点です。総コメント数は6551件です。
[NIJISANJI DAY RELAY STREAM START!]
— NIJISANJI India [Official Staff Account] (@NIJISANJI_india) February 2, 2020
Starting at 20:30 IST! (24:00 JPT)
Get ready for the final leg of the relay featuring: @Aadya_VTuber @Vihaan_VTuber & @Noor_VTuber
Watch now: https://t.co/KLPHFALeu6#NIJISANJI_Day #NIJISANJI_IN pic.twitter.com/BgQnNVxUjJ
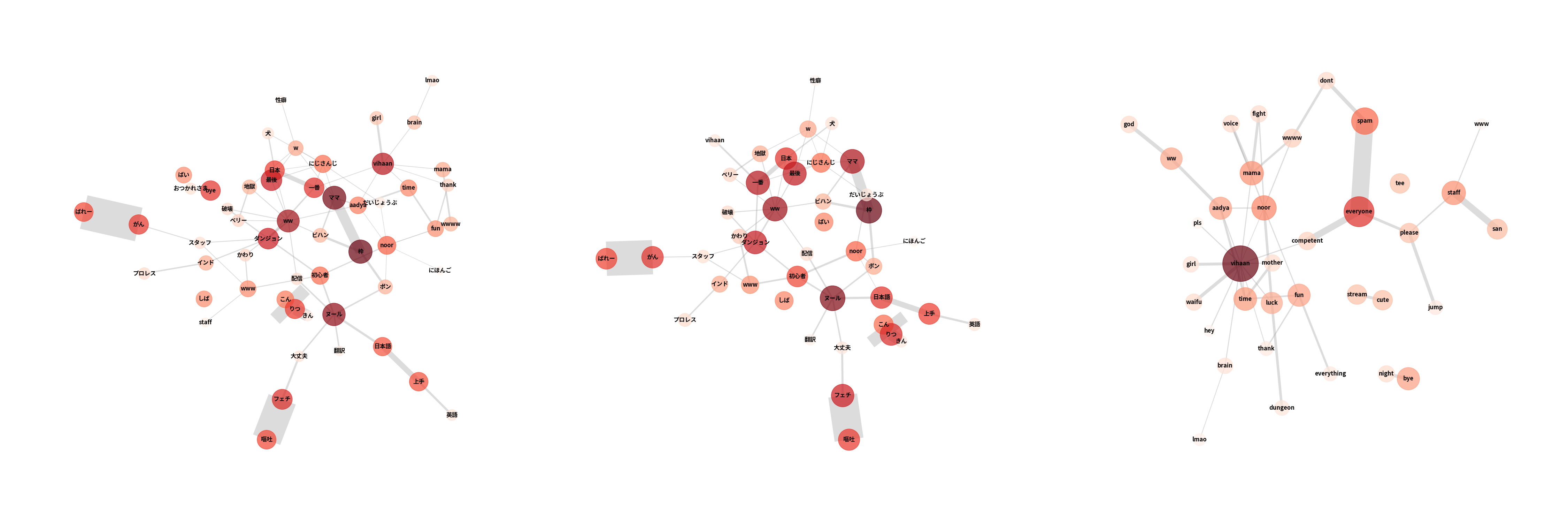 ネットワークの結果を見ると、言語毎に異なった反応が見受けられます。日本語の結果を見ると、日本語が上手な`Noor`さんの名前が多く挙げられています。対して、英語の解析結果ではゲーム内ですぐに物を壊す`Vihaan`さんを中心に、`Noor`さん、`Aadya`さんの名前が挙がっています。
ネットワークの結果を見ると、言語毎に異なった反応が見受けられます。日本語の結果を見ると、日本語が上手な`Noor`さんの名前が多く挙げられています。対して、英語の解析結果ではゲーム内ですぐに物を壊す`Vihaan`さんを中心に、`Noor`さん、`Aadya`さんの名前が挙がっています。
また、英語の出現度を見るとfという言葉がランクインしています。よくインドネシアの配信で見かける言葉で、ドンマイ!みたいな意味合いです。Call of Duty: Advanced Warfareが元ネタのミームらしく、インドネシア他、様々な国でよく使われるそうです。世界的なコラボ配信のため、様々な国の方が視聴していることが分かります。
まとめ
本記事で紹介した動画以外でも実験を行いました。それらの結果も踏まえ、まとめをしていきます。
- 圧倒的な
草- 本来の意味である笑いを表す
w以外にも、面白いという意味だったり、茶化す際に使われたり、多くの意味を持った便利な言葉であることから多用されていると考えられます。
- 本来の意味である笑いを表す
- シンプルなネットワーク図程、ファンの意見は一致している
- 歌ってみた等のプレミアム公開を見ると、
かっこいい, 最高, 綺麗, ありがとうといったシンプルな単語が多く使われている印象を持ちました。いわゆる限界化です。
- 歌ってみた等のプレミアム公開を見ると、
- ゲーム実況系は、ゲーム内の専門用語が多い
- 雑談系は複雑になるが、何の話題を話しているか予想できる
- 言語によって感想やコメントの傾向は若干異なるものの、大体
草
さて、いかがだったでしょうか。少しでも面白いと思っていただけたのならば幸いです。記事が読みづらい?それはそうでしょう。だって私はオタクで、限界化すると語彙力が低いのだから。
Future work
- 多言語対応
- 盛り上がった場面の推定
- 確かコメントされた時間を取得できる
- time windowを設定し、コメントが盛り上がった場面を抽出する
- その区間の解析をすれば、何で盛り上がったか推定できるかもしれない
Notice
データの扱いについて
著作権法47条の7に基づき、本プロジェクトにおけるデータの使用及び分析は違法ではないと考えています。(詳しくないけど、多分大丈夫。)しかしながら、配信者の意見を尊重し、配信者または、所属事務所の申し出があれば該当部分を削除致します。また作成したコードはデータを除き、Githubにて公開しています。自由にお使い下さい。
Special Thanks
本記事の執筆に当たり、以下4名の方にアドバイスをいただきました。記事の最後とはなりましたが、感謝申し上げます。
-
sarazhaosining: 実験結果の考察、プログラムの改善点の指摘、中国語に関するアドバイス -
SzkSsk: 実験結果の考察、プログラムの改善点の指摘 -
deviswitchlol: プログラミングに関するアドバイス、NLPに関するアドバイス -
Sweater: 辞書に関するアドバイス
Github
Ref.
ライブラリ等の公式ドキュメントは省略致します。
以下、順不同
- PythonでYouTube Liveのアーカイブからチャット(コメント)を取得する, http://watagassy.hatenablog.com/entry/2018/10/06/002628
- PythonでYouTube Liveのアーカイブからチャット(コメント)を取得する(改訂版), http://watagassy.hatenablog.com/entry/2018/10/08/132939
- Janomeのユーザー辞書を作る(python,自然言語処理,エネルギー基本計画), http://eneprog.blogspot.com/2018/08/janomepython.html
- Pythonを使って文章から共起ネットワークを作る, https://www.dskomei.com/entry/2019/04/07/021028
- Pythonで共起ネットワークを作成する, https://irukanobox.blogspot.com/2019/10/python.html
- nltk を用いたバイグラムの処理, http://yoshihikomuto.hatenablog.jp/entry/2012/12/18/043725