課題と解決方法
2024年現在、文章を要約する方法にはさまざまな種類がある。方法論はもちろんモジュールも多く存在している。ただ、それらの手法を理解した上で使えていない方もいと思う。
そこでこの記事では文章要約の「抽出的要約」と「抽象的要約」で使われる手法とロジックの解説、コードの提示までを行う。
今回はwikipediaのデータセットにある以下の文章を要約に使う。
2010-03-02T19:00:00+0900 友を失うその前に!? ビジネススキルの意外なる盲点 『あの人と一緒に仕事がしたい』 ビジネスパーソンとして、周囲からそう思われる人間になれ! ベストセラー作家・エッセイスト・役者等さまざまな顔をもち、アタッカーズ・ビジネススクールの講師も勤める中谷彰宏氏は言います。『こんな企画を一緒にやろう!そう言ってプロジェクトを始め、ふと気が付けば全然違うことをやっていた。そんな時が、一番上手くいく。 なぜなら、最初に決めた方向性にまっすぐ進む仕事なんて、ほとんど無いのだから。“気付けば全然違うことをやっていた”それは、チームが臨機応変に荒波を乗り越えてきたという、優れた状態なのです。 一方、上手くいかない時は、荒波に揉まれて、ひとり抜け、二人抜け最後は自分ひとり。ひとりで会社に報告し、ひとりでクライアントに謝りにいく。にも関わらず、次の仕事には、誰も付いてこない。つまり仕事をやることで、大切な友人を失ってしまうのです』と続けます。それはプライベートでも同じことです。例えば、卒業旅行と言えば「どんな親友とでも、必ず喧嘩する」なんてジンクス、ありませんでしたか? 長い時間を共に過ごす海外旅行は、いつもと違う環境に疲れ、何かと本性が出てしまったり、相手のちょっとした言動が癇に障ったり。喧嘩まではいかずとも、気まずい空気のまま旅を終え「あんな奴と二度と行くか!」そう心の中で叫んだ経験を持つ方も多いはず…?自分も相手も「いい思い出を作ろう」という思いは同じ。ところが互いが思い描いているゴールや、ゴールにアプローチする前提条件や方法論が違う。これが困ったことに、ベストなものにしたいという“思い入れ”があればある程、それが裏目に出てしまう。ビジネスの場でも、思い当たる節がありませんか?再び中谷氏の言を借りると 『ところが、社内で企画を進めるメンバーを集めるとなると、皆、企画が面白い人や才能がありそうな人、営業成績が良い人等を集めたがる。 いくら才能や実績がある人が集まっても、一緒に荒波を乗り越えられなければ、その仕事は成り立たない。大事なのは極限の状態でも、意思疎通が図れること。 一緒に仕事がしたいと思う人——。それは、ビジネス・コミュニケーション力を、持ち合わせている人なのです』と話します。ビジネススキルと言えば、思考法やマーケティング等に目を向ける人は多いけれども、日常のコミュニケーションの鍛錬は、意外と見逃しがち。 4月には、新しい顧客や新しい上司、新しい部下を迎える方も多いでしょう。ライバルに埋もれ“その他大勢”になる前に、コミュニケーション力を見直しておくのが、頭ひとつ抜きん出るための、有効な手はずなのかもしれません。■関連リンク ・大前研一のアタッカーズ・ビジネススクールはこちら ・中谷彰宏氏のビジネス・コミュニケーション講座(E-アタッカーズ通信講座)こちら
■お仕事・副業検索はこちら
文章要約の2つのカテゴリー
まず、文章要約といっても【抽出的要約】と【抽象的要約】2つの大きなカテゴリに分けられる。
1. 抽出的要約
概要
利用された文章のうち、他の文章で書かれている内容を要約できる文やより強調すべき文をピックアップして表示する要約方法
具体例
元の文章:
「今日は天気が良くて、とても暖かかったです。公園でピクニックをして、友達と楽しい時間を過ごしました。」
抽出的要約:
「天気が良くて暖かかった。公園でピクニックをして楽しい時間を過ごしました。」
メリット
- 特に調整せずとも理解しやすい文章を出力できる。入力された文章をそのまま出力するため
- 処理スピードが速い。重要な情報をそのまま抜き出すため
2. 抽象的要約
概要
利用された文章をサマリー化して新たな文章を再生成する要約方法。
具体例
元の文章:
「今日は天気が良くて、とても暖かかったです。公園でピクニックをして、友達と楽しい時間を過ごしました。」
抽象的要約:
「今日は晴れて暖かく、友人と公園で楽しい一日を過ごしました。」
メリット
- 出力する文章の長さを任意で設定できる。文章を再生成するため、文章の長さを短く調整することも可能
- 要点をまとめた文章を出力できる。文章全てを踏まえて新たな抽象的な文を表示するため
抽出的要約の5つの手法
1. textrank
概要
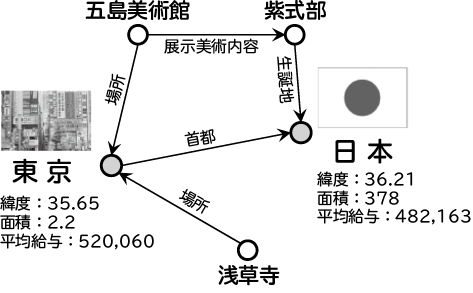
グラフベースの手法の一つ。グラフベースとは文章同士の関係性を表し、他の文章と関係性が高い文章を出力する方法。
lexrankとの違いは「類似性の高い文」をエッジで結び、最も関連性が高い文を要約として抽出する点。
参考
https://atmarkit.itmedia.co.jp/ait/spv/2112/23/news028.html
特徴
- シンプルかつ効果的で、計算コストが比較的低い
- 計算がシンプルなため、大規模なデータセットでも安定した精度を出せる
- 文章の間の「関係性」を踏まえて、サマリーを作成できる
コードサンプル
from sumy.parsers.plaintext import PlaintextParser
from sumy.nlp.tokenizers import Tokenizer
from sumy.summarizers.text_rank import TextRankSummarizer
def summarize_text(text, sentence_count=3):
parser = PlaintextParser.from_string(text, Tokenizer("japanese"))
summarizer = TextRankSummarizer()
summary = summarizer(parser.document, sentence_count)
return " ".join([str(sentence) for sentence in summary])
summary = summarize_text(article_content)
print(summary)
※グラフベースの解説は以下をご覧ください
https://qiita.com/badorisu0555/items/8313515ca25c2d2eaf31
2. lexrank
概要
textrankと同じグラフベースの手法。ただ、lexrankは「コサイン類以度」を使って、文同士の意味的な関係性の類以度をエッジとして使っている。
特徴
- 文の意味的な関係性を踏まえて、サマリーを作れる
コードサンプル
from sumy.parsers.plaintext import PlaintextParser
from sumy.nlp.tokenizers import Tokenizer
from sumy.summarizers.lex_rank import LexRankSummarizer
# PlaintextParserでテキストを解析
parser = PlaintextParser.from_string(article_content, Tokenizer("japanese"))
# LexRankサマライザーを作成
summarizer = LexRankSummarizer()
# 要約を生成
summary_lexrank = summarizer(parser.document, 2) # 2文に要約
print("LexRank 要約:")
for sentence in summary_lexrank:
print(sentence)
3. LSA(Latent Semantic Analysis)
概要
特異値分解(SVD)を用いて、文書内の隠れた意味的構造を捉える統計的手法です。文書中の概念的な関係を捉え、重要な文を抽出します。
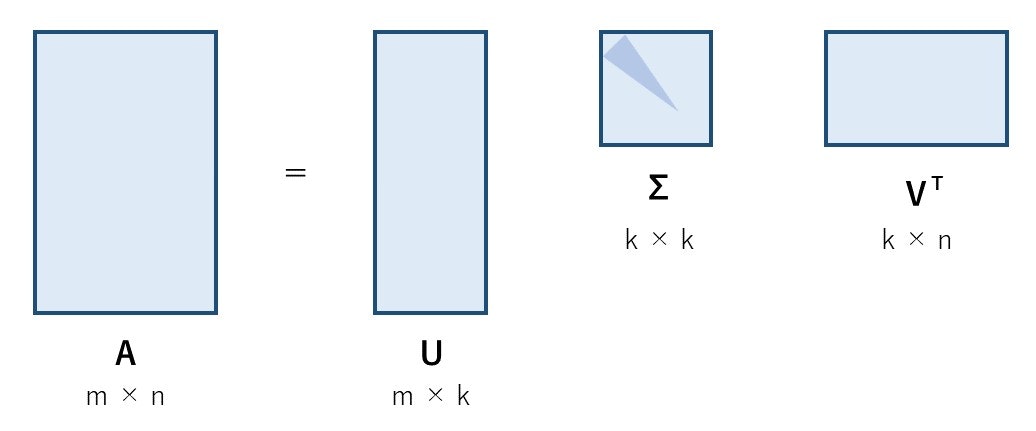
特異値分解(SVD)とは?
任意の行列を2つの直交行列と特異値からなる内積へ分解できるという方法。つまり任意の行列をいくつかのカテゴリに分け、そのカテゴリとどれだけ合致しているか?も数値として表せる。
要約の流れ
- 「任意の行列」を作成する。例えば、行に文章、列に単語を当てはめ、値には「その文章中での単語の出現回数」を示した行列を作成
- 次に特異値分解を用いて、文章と単語の関係性から複数のカテゴリへ文章を分類分けする
特異値分解について詳しく知りたい場合には、以下をご覧ください。
- 複数の文章をいくつかのカテゴリに分けることができる。そして、そのカテゴリごとに最も類以度が高い文章を要約として出力する
特徴
低次元へ文章間の関係性を圧縮できるため、ノイズが多くても対応できる
単語の共起パターンに基づいて分類分けされるため、文章の「概念」でカテゴリ分けできる。例えば、「車」と「自動車」は同じ意味のため、同じような頻度で出力され、「同じ意味」と判断される。
参考)https://mieruca-ai.com/ai/lsa-lsi-svd/
コードサンプル
from sumy.parsers.plaintext import PlaintextParser
from sumy.nlp.tokenizers import Tokenizer
from sumy.summarizers.lsa import LsaSummarizer
# PlaintextParserでテキストを解析
parser = PlaintextParser.from_string(article_content, Tokenizer("japanese"))
# LSAサマライザーを作成
summarizer = LsaSummarizer()
# 要約を生成
summary_lsa = summarizer(parser.document, 2) # 2文に要約
print("LSA 要約:")
for sentence in summary_lsa:
print(sentence)
4. TF-IDF (Term Frequency-Inverse Document Frequency)
概要
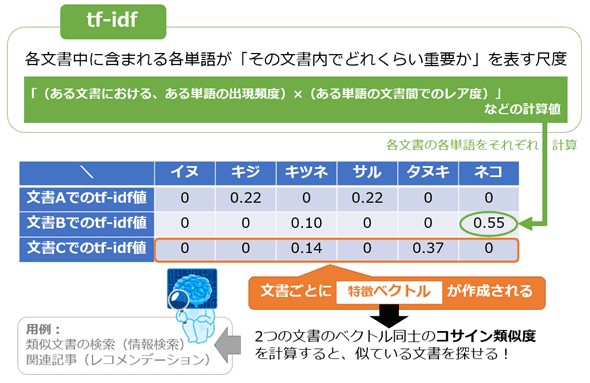
一つの文書の中での単語の出現頻度(Term Frequency)と、逆文書頻度(Inverse Document Frequency)を使って重要な文を抽出します。
逆文書頻度とは、全ての文書の中でその単語の出現する頻度がどれくらい稀かを示す指標のことです。
参考
https://atmarkit.itmedia.co.jp/ait/spv/2112/23/news028.html
要約の流れ
- tf-idfで単語のレア度を計算
- tf-idfの値の合計や平均を元に、文章全体のtf-idf値を求める
- その値が高い文章を要約文として出力する
tf-idfでは、「その文書の中では出現頻度が高いが、すべての文書の中では出現頻度が低い単語」を重要な単語としています。
※ただ「出現頻度が高い単語」は助詞などが当てはまってしまうため。
特徴
- 簡単に実装ができ、計算コストも低い
- 短い文書や、単語の頻度が重要なニュース記事や商品レビューの要約に効果的
サンプルコード
import re
from sklearn.feature_extraction.text import TfidfVectorizer
import numpy as np
# 文を句点で分割する関数
def split_into_sentences(text):
sentences = re.split(r'(?<=。)', text)
sentences = [sentence.strip() for sentence in sentences if sentence.strip()]
return sentences
# 文単位に分割
sentences = split_into_sentences(article_content)
# TF-IDFのベクトル化
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(sentences)
# 各文のTF-IDFスコアを計算
sentence_scores = np.array(tfidf_matrix.sum(axis=1)).flatten()
# スコアが高い文を選択(上位3文を選択)
top_n = 3 # 要約に含める文の数
top_sentence_indices = sentence_scores.argsort()[-top_n:][::-1] # スコアが高い文のインデックス
# 要約の生成
summary = " ".join([sentences[i] for i in top_sentence_indices])
print("要約:")
print(summary)
5. BERT Extractive Summarizer
概要
BERTなどの事前学習済み言語モデルを使用し、文のベクトル表現を生成し、各文の重要度を予測する手法です。
※BERTの詳細を解説した記事
https://aisuite.jp/column/bert/
要約の流れ
- まずは文書全体を文単位に分ける
- 分けた文をBERTに入れて、文脈をベクトル表記に変える。このベクトルが特徴量として使われる
- そして、文の重要度(類似度)をコサイン類似度などを使って計算する。このコサイン類似度が高いものは「他の文と似ている」と言える
- 重要度が高いと予測された文を選び、それを順番に出力する
特徴
- 文脈理解能力が高い。BERTは双方向のアテンションを使用して文脈を理解するため、より深い理解に基づいた要約が可能です。
- 従来の要約方法と比べて、高いパフォーマンスを発揮できる
サンプルコード
import re
from transformers import BertTokenizer, BertForSequenceClassification
import torch
# 文を句点で分割する関数
def split_into_sentences(text):
sentences = re.split(r'(?<=。)', text)
sentences = [sentence.strip() for sentence in sentences if sentence.strip()]
return sentences
# BERTSUM用に日本語のBERTモデルをロード
model_name = 'cl-tohoku/bert-base-japanese' # 日本語対応BERTモデル
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name)
# 文単位に分割
sentences = split_into_sentences(article_content)
# 各文をBERTに入力するためにトークン化
inputs = tokenizer(sentences, return_tensors='pt', padding=True, truncation=True, max_length=512)
# BERTで予測
with torch.no_grad():
outputs = model(**inputs)
predictions = torch.argmax(outputs.logits, dim=-1)
# 要約の生成(抽出的要約のため、上位の文を選択するなどの戦略が必要)
summary_sentences = [sentences[i] for i in predictions.tolist() if i == 1] # ラベル1が要約に含めるべき文
summary = " ".join(summary_sentences)
print("要約:")
print(summary)
抽象的要約の2つの手法
6. T5(Text-to-Text Transfer Transformer)
概要
あらゆる自然言語処理タスクを「テキスト生成問題」として扱うトランスフォーマーモデル。入力と出力をすべてテキスト形式で表現するため、翻訳、要約、質問応答、分類といった異なるタスクにも同じモデルで汎用的に対応できる。
特徴
- タスクの種類を区別するために、「summarize:」や「translate English to French:」といった命令文が入力に付加される。ただ、それ以外に必要な処理はなく汎用性が高い
要約の流れ
- トークナイザー(単語へIDを割り当てるツール)の読み込みをして、IDへ変換する
- 事前学習済みのモデルを読み込み、そのモデルに対してトークナイズされた入力を与える
- 埋め込みによってトークンをベクトルする
- トランスフォーマー層などで内部処理を行い、文脈などを読み取れるようにする
- そして、テキストの生成を行う
サンプルコード
from transformers import T5ForConditionalGeneration, T5Tokenizer
# 日本語T5の事前学習済みモデルとトークナイザーをロード
model = T5ForConditionalGeneration.from_pretrained("cl-tohoku/t5-base-japanese")
tokenizer = T5Tokenizer.from_pretrained("cl-tohoku/t5-base-japanese")
# テキストをトークン化し、モデルが処理できる形式に変換
inputs = tokenizer.encode("要約: " + article_content, return_tensors="pt", max_length=512, truncation=True)
# 要約を生成
summary_ids = model.generate(inputs, max_length=150, min_length=40, length_penalty=2.0, num_beams=4, early_stopping=True)
# トークンを文章にデコード
summary = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
# 要約結果を出力
print(summary)
7. BART(Bidirectional and Auto-Regressive Transformers)
概要
エンコーダーとデコーダーでできているトランスフォーマーが使われたモデル。事前学習で入力にノイズを追加し、それを元に戻すタスクを学ぶことで、精度の高い要約が可能に。
特徴
- エンコーダー部分で双方向の情報を学び、デコーダー部分では自己回帰的に出力を生成する。双方向の情報から出力するため、文脈を正確に読み取れ、正しい要約になりやすい
- テキストの一部をマスクしたり、並べ替えたりしてノイズを付与し、元のテキストを復元するように学習する
要約の流れ
こちらはT5と大きく変わらないため、省略とします!
異なる点といえば、モデルの事前学習方法です。文章中の単語をマスキングして、入る単語を学習させるだけでなく、削除した単語の予測・連続してマスキングされた単語の予測・文章の順番シャッフルなど、さまざまな事前学習を行っています。
参考)
https://data-analytics.fun/2021/03/19/understanding-bart/
サンプルコード
from transformers import BartForConditionalGeneration, BartTokenizer
# 日本語BARTの事前学習済みモデルとトークナイザーをロード
model = BartForConditionalGeneration.from_pretrained("cl-tohoku/bart-base-japanese")
tokenizer = BartTokenizer.from_pretrained("cl-tohoku/bart-base-japanese")
# テキストをトークン化し、モデルが処理できる形式に変換
inputs = tokenizer.encode(article_content, return_tensors="pt", max_length=1024, truncation=True)
# 要約を生成
summary_ids = model.generate(inputs, max_length=150, min_length=40, length_penalty=2.0, num_beams=4, early_stopping=True)
# トークンを文章にデコード
summary = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
# 要約結果を出力
print(summary)
以上になります!最後までご覧いただきありがとうございました
気になる点や間違っている箇所があれば、ぜひご指摘頂けますと幸いです!